
むかしむかし、空が青かったとき、草はより緑で、恐竜は地球を歩き回っていました...いや、恐竜を忘れてください。 まあ、一般的に、昔々、標準的なWebプログラミングから気をそらして、もっとクレイジーなことをするという考えが浮かびました。 もちろん、何でも可能でしたが、選択はあなた自身の通訳を書くことにかかっていました。 私に言えることは... 自分のプログラミング言語を決して書かないでください 。 しかし、私はこれらすべてからいくつかの経験を得たので、共有することにしました。 まさに基礎-レクサーから始めましょう。
まえがき
動物がどのような「レクサー」であるかを理解する前に、YaPが何でできているかを理解する価値があります。
現代の世界では、各コンパイラ/インタプリタ/トランスパイラ/その他のようなもの(タイプを区別せずに、さらに「コンパイラ」と呼びます)は2つの部分に分かれています。 賢い叔父の用語では、そのような部分は「フロントエンド」と「バックエンド」と呼ばれます。 いいえ、これは、Webを操作するときに使用するものではなく、HTMLを使用してJSで記述されたものではありません。 でも...わかりました。
最初のフロントエンドのタスクは、 テキストを取得してAST (抽象構文ツリー)に変換し、途中で構文(および場合によってはセマンティクス)をチェックすることです。 2番目のバックエンドのタスクは、すべてを機能させることです。 コードがインタープリター内でアセンブルされる場合、ASTは仮想プロセッサー(仮想マシン)の命令セットを作成し、コンパイラーの場合は実際のプロセッサーの命令セットを作成します。 生活の中で、すべてが非常に複雑であり、そのように実装されない場合があります。 たとえば、GCCコンパイラの場合、すべてが混同されますが、Clangはすでにより標準的であり、LLVMはコンパイラの「バックエンド」の典型的な代表です。
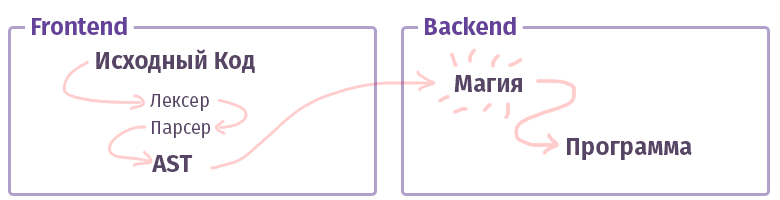
それでは、フロントエンドと呼ばれる部分を理解しましょう。
字句解析
字句解析器および字句解析の段階のタスクは、入力として多数の文字を取得し、それらをいくつかのカテゴリ(「トークン」)にグループ化することです。 したがって、字句解析は「トークン化」とも呼ばれます。 これは、既存のすべてのコンパイラーが作成するテキスト処理の最初の段階です。
このようなもの:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens)); // array(4) { // [0] => string(5) "class" // [1] => string(7) "Example" // [2] => string(1) "{" // [3] => string(1) "}" // }
ちなみに、ここでは、生活を楽にするためのツールをすでに書いています。 テキストの解析に使用したのと同じpreg関数は、このタスクに非常に適しています。 ただし、この問題にはさらに便利なツールがあります。
- ニキータ・ポポフによって書かれたフレキシー 。
- Hoaは、Lexer + Parser + Grammarで構成されるツールキットです。
- Anthony Ferraraによって書かれたPort Yaccは包括的なツールキットでもあり、よく知られたPopov PHPパーサーが書かれており、コード分析を使用するツールに適用できます。
- Railt Lexer PHP 7.1以降の実装
- Parleは、PCRE式の限定セットを許可するPHPの拡張機能です(lookaheadおよびその他の構文構成はありません)。
- 最後に、標準のPHP関数token_get_allは 、PHPの字句解析を直接目的としています。
さて、トークンでテキストを分割できるギズモがたくさんあることは明らかです。Doctrinelexerのような何かを忘れてしまったかもしれません。 しかし、次は何ですか?
レクサーの種類
そしていつものように、すべてが見た目ほど単純ではありません。 レクサーには少なくとも2つの異なるカテゴリがあります。 ルールをずらす通常のオプションがありますが、それはすでにすべてをトークンに分割しています。 その構成は、上記で示した例と大差ありません。 ただし、 multistateと呼ばれる別のオプションがあります。 そのようなレクサーは理解するのが少し難しいので、もう少し話をしたいと思います。
マルチステートレクサーのタスクは、以前の状態に応じてさまざまなトークンを表示することです。 たとえば、PHPでは、このような「遷移」状態は、<?Php +?>タグ、内部行、コメント、およびHEREDOC / NOWDOC構成要素を使用して形成されます。
上記の4つのトークンを使用した例を覚えていますか? これらの状態を理解するために、少し変更しましょう。
class Example { // class Example {} }
この場合、PCREの幅広い機能を備えていない最も単純なレクサーがある場合、次のトークンのセットを取得します。
var_dump(lex(...)); // array(9) { // [0] => string(5) "class" // [1] => string(7) "Example" // [2] => string(1) "{" // [3] => string(2) "//" // [4] => string(5) "class" // [5] => string(7) "Example" // [6] => string(1) "{" // [7] => string(1) "}" // [8] => string(1) "}" //}
ご覧のように、要素3〜5について完全に平凡なコメントを取得しました。コメントは非常に予期せず取られ、トークンに分割されましたが、全体として考慮されるべきでした。
もちろん、PCRE機能では、単純な規則 " // [^ \ n] * \ n "の助けを借りて、そのようなトークンを破ることができますが、そうでない場合はどうでしょうか。 さて、それとも手でそれを切り裂きたいですか? 要するに、マルチステートレクサーの場合、すべてのトークンはグループNo1に属し、「 // 」トークンが見つかるとすぐにグループNo2に移行する必要があると言えます。 そして、トークン " \ n "が見つかった場合、2番目のグループ内で逆の遷移-最初のグループに戻る遷移。
このようなもの:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2' // 2 ], 'group-2' => [ "\n" => 'group-1', // 1 '.*' ] ];
このHEREDOC構文が変数補間をサポートしていることを考えると、PCREのすべての機能を備えていても、このケースのレギュラーを書くことは非常に問題があるため、HEREDOCの解析方法が明らかになっていると思います。 組み込みのtoken_get_all関数を使用して、このようなものを解析してみてください(注> 12トークン):
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__)));
さて、私たちは練習を始める準備ができているようです。
練習する
そのようなことのためにPHPにあるものを思い出しましょう。 もちろん、preg_match! さあ降りて preg_matchベースのアルゴリズムは、 HoaおよびこのPhelxyの実装に実装されています 。 そのタスクは非常に簡単です。
- ソーステキストとレギュラーの配列が手元にあります。
- 適切なものが見つかるまで一致します。
- ピースを見つけたらすぐに、テキストから切り取り、さらに一致させます。
コード形式では、次のようになります。
コードシート
<?php class SimpleLexer { /** * @var array<string> */ private $tokens = []; /** * @param array<string> $tokens */ public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } /** * @param string $sources * @return iterable&\Traversable<string> * @throws RuntimeException */ public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } /** * @param string $sources * @param int $offset * @return array<string,string> * @throws RuntimeException */ private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } }
コードシートを使用する
$lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; }
このアプローチは非常に簡単であり、キーボードを数回押すだけでnext()メソッドの領域でレクサーを変更し、状態間の遷移を追加して、このマスターベーションをプリミティブなマルチステートレクサーに変えることができます。 $ this-> tokens領域で、 $ this-> tokens [$ this-> state]のようなものを追加するだけです。
ただし、プリミティビズム自体に加えて、別の欠点があります。判明する可能性があるため、致命的ではありませんが、それでも...このような実装は非常に遅いです。 私が偶然所有者であることが判明したi7 7600kでは、同様のアルゴリズムが1秒あたり約400トークンを処理し、そのバリエーション(つまり、コンストラクターに渡した定義)が増加します-ロシアの大統領を変える速度に遅くなる可能性があります...ごめんなさい もちろん、 非常にゆっくりと動作することを伝えたかったのです。
さて、何ができますか? まず、何が間違っているのかを理解できます。 実際のところ、言語の範囲内でpreg_matchを呼び出すたびに、PCREと呼ばれるJITを持つコンパイラーが増加します(そして、PHP 7.3ではPCRE2が既にあります)。 彼が正規表現自体を解析し、それらのパーサーを収集するたびに、テキストを解析してトークンを作成します。 少し奇妙でトートロジカルに聞こえます。 しかし、要するに、各トークンは1からN個のレギュラーのコンパイルを必要とします。Nはこれらのトークンの定義の数です。 同時に、トークンの正規表現が生成されるコンストラクターで適用された「 S 」フラグと「 \ G 」を使用した最適化でも役に立たないことは注目に値します。
この状況から抜け出す方法は1つしかありません。このすべてのテキストを1つのパスで解析する必要があります。 1つのpreg_match関数を実行するだけです。 次の2つの問題を解決します。
- 正規表現N1の結果がトークンN2に対応することを示す方法 つまり たとえば、「 \ w + 」がT_CONSTであることを示す方法。
- 結果としてトークンのシーケンスを決定する方法。 ご存知のように、 preg_matchまたはpreg_match_allの結果には、すべてが混同されます。 また、4番目の引数として渡されたフラグを使用しても、状況は変わりません。
ここで、一時停止して少し考えることができます。 まあかどうか。
最初の問題の解決策はPCREグループと呼ばれ、「サブマスク」とも呼ばれます。 ルールの使用: " (?<T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) "トークンを名前と比較することで、1回のパスですべてのトークンを取得できます。 一致の結果、ペア「 [TOKEN_NAME => TOKEN_VALUE] 」で構成される連想配列が形成されます。
2つ目はもう少し複雑です。 ただし、ここでは、戦術的なトリックを適用して、 preg_replace_callback関数を使用できます。 その特徴は、2番目の引数として渡された匿名が、最初から最後まで、各トークンに対して厳密に連続して呼び出されることです。
苦労しないように、実装は次のとおりです。
コードの別のフラップ
class PregReplaceLexer { /** * @var array<string> */ private $tokens = []; /** * @param array<string> $tokens */ public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } /** * @param string $sources * @return iterable&\Traversable<string,string> */ public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } /** * @return string */ private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } }
そして、その使用法は以前のバージョンと変わりません。 同時に、作業速度は毎秒400から57,000トークンに増加します。 私の実装で適用したのはこのアルゴリズムで、Hoaソースコードの書き換えを取り上げました。 ところで、Parleを使用する場合、1秒間に最大600,000トークンを圧縮できます。 全体像は次のようになります(PHP 7.1でXDebugがオンになっているため、数値は低くなりますが、比率は大まかに表すことができます)。
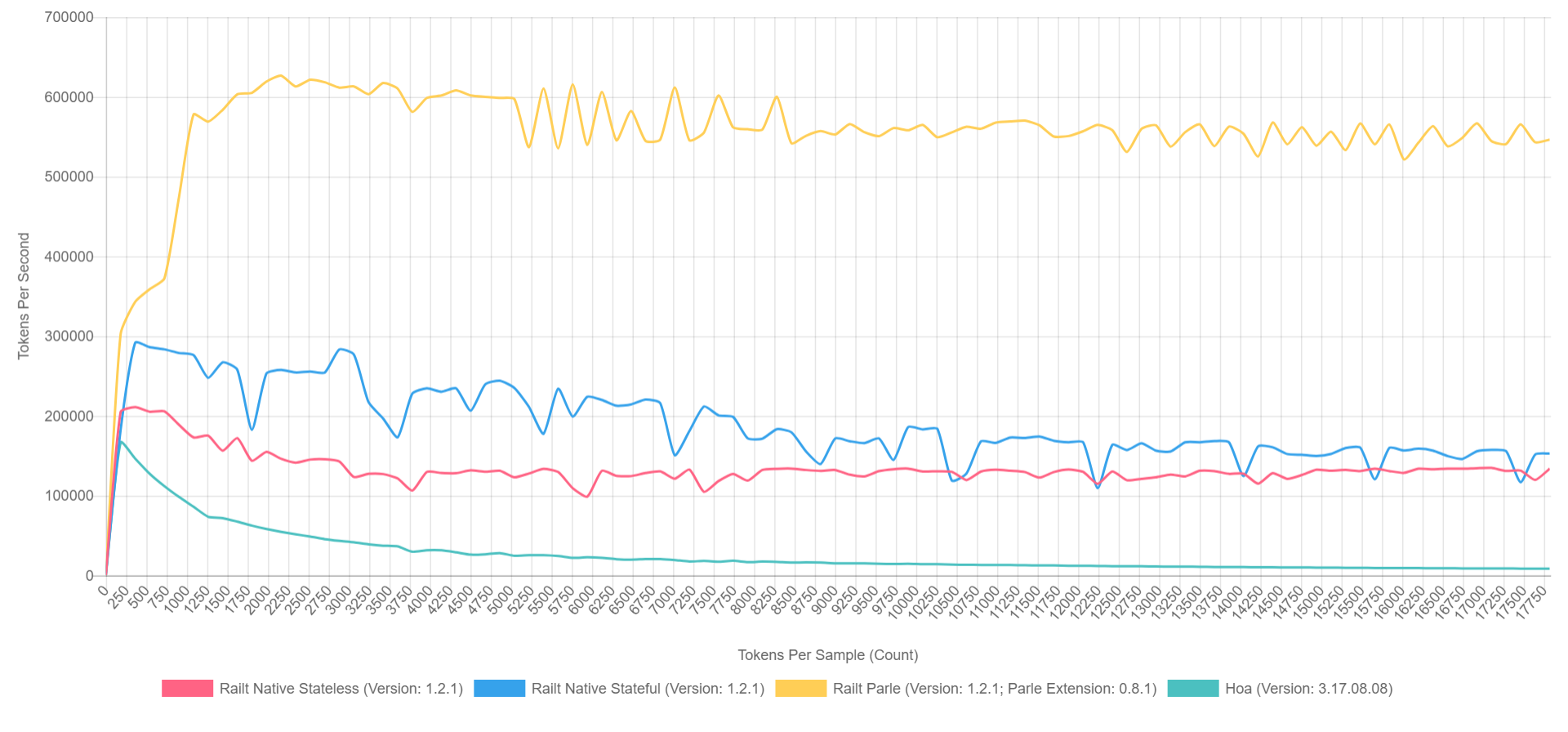
- 黄色はParleのネイティブ拡張です。
- 青-preg_replace_callbackを事前に組み立てられたレギュラーで実装します。
- 赤-すべて同じですが、 preg_replace_callbackの呼び出し中に生成された規則性を持ちます。
- グリーン-preg_matchによる実装。
なんで?
もちろん、これはすべて素晴らしいことですが、せっかちな人たちは「誰がこれを必要としているのですか?」という質問を切望しています。 「fig-fig-and-site-ready」の原則が支配するPHPの抽象的な世界では、そのようなライブラリは必要ありませんが、正直に言うと。 しかし、エコシステム全体について話すと、 symfony / yamlやDoctrineなどの有名なライブラリを思い出すことができます。 Symfonyのアノテーションは、PHP内の同じサブ言語であり、字句解析と構文解析を別々に行う必要があります。 さらに、PHPで書かれたあまり知られていないCoffeeScript、Less、およびScss / Sassトランスパイラーがまだあります。 さて、またはYayとそれに基づいた前処理 。 phpmdやphpcsなどのコード分析ツールについても言及しません。 また、phpDocumentnorやSamiなどのドキュメントジェネレーターは非常に簡単です。 これらの各プロジェクトは、ある程度、テキスト/コードの解析の最初の段階で字句解析を使用します。
これはプロジェクトの完全なリストではなく、おそらく私の話が新しい何かを発見し、それを補充するのに役立つことを願っています。
あとがき
パーサーとコンパイラーの主題に興味がある人がいるなら、このトピックに関する興味深いレポートがいくつかあります。特に、JetBrainsの人々からです。
映像
また、もちろん、YouTubeで見られるAndrei Breslavのスピーチ( abreslav )のほとんどは、視聴することをお勧めします。
まあ、読書のファンにとって、私にとって個人的に非常に有用なリソースがあります。
ポストポスト台本。 この叙事詩の広大さのどこかに封印されているなら、あなたに都合の良い形で作者に安全に知らせることができます。
おまけとして、 単純なPHPのlexerの例を挙げたいと思います。今ではそれほど怖くはないようです。 私はだまされていますが、目は常連から出血しています。 =)
よろしくお願いします!