こんにちはさまよう。 私たちは、私たちの思考の旅人であり、私たちの状態の分析者として、どこが良いか、そうでない場合はどこか、正確にどこにいるかを理解する必要があり、読者の注意をこれに向けたいと思います。
どのように思考の連鎖を順番にまとめるのですか?各ステップの結論を想定して、制御の流れとメモリ内の細胞の状態を制御しますか? または、単に問題ステートメントを記述して、どの特定のタスクを解決したいかをプログラムに伝えれば、すべてのプログラムをコンパイルするにはこれで十分です。 コーディングをシステムの内部状態を変更するコマンドのストリームに変えるのではなく、ソートの概念として原則を表現するために、そこに隠されているアルゴリズムの種類を想像する必要はないため、ソートされたデータを取得するだけです。 アメリカの大統領がバブルに言及できるのは何の理由でもありません。彼はプログラミングで何かを理解したという考えを表現しています。 彼は並べ替えアルゴリズムがあり、デスクトップ上のテーブルのデータは、それ自体では、魔法のような方法でアルファベット順に並べることができないことを発見しました。
私の考えを表現する宣言的な方法、そしてそれらの間の一連のコマンドと遷移ですべてを表現するこのアイデアは古くて時代遅れに思えます。このレベルの進化では、まだ次のコマンドについて考えることができるので、モニターと音声認識があります...論理的な言語でプログラムを表現すると、より理解しやすくなり、これを行うことができるようです テクノロジーでは、80年代に賭けが行われました。
まあ、紹介は引きずられて....
手始めに、クイックソートメカニズムの再評価を試みます。 リストをソートするには、リストを2つのサブリストに分割し、ソートされた1つのサブリストを別のソート済みサブリストと結合する必要があります 。
分割操作では、リストを2つのサブリストに変換できる必要があります。1つには基本的でない要素がすべて含まれ、2つ目のリストには大きな要素のみが含まれます。 これを表現すると、次の2行のみがErlangに書き込まれます。
qsort([])->[]; qsort([H|T])->qsort([X||X<-T,X<H])++[H|qsort([X||X<-T,X>=H])].
これらは、私が興味を持っている思考プロセスの結果の表現です。
命令的なソートは、説明がより困難です。 このようなプログラミング方法には本当に利点がありますか。Cプレースプレース、少なくともFortranはありますが、それを呼び出さないでください。 それは、javascript、およびすべての言語の新しい標準におけるラムダ関数のすべての傾向が、アルゴリズム性の不便さの確認だからです。
あるアプローチと別のアプローチの利点を検証するための実験を行って、それらをテストします。 並べ替えの定義の宣言型レコードとそのアルゴリズムレコードをパフォーマンスの観点から比較し、プログラムをより正確に定式化する方法を結論付けることができることを示します。 Haskellや断面で自分を表現するのはそれほど流行していないため、これは単に時代遅れのアプローチとして、アルゴリズムとコマンドのフローを通じてプログラミングを棚に押し上げるでしょう。 そして、妖精のシャープだけがプログラムを明確でコンパクトな外観にすることができるのではないでしょうか?
Pythonにはいくつかのパラダイムがあり、これはC ++ではなく、もはやLispではないため、Pythonを使用してデモンストレーションします。 別のパラダイムで明確なプログラムを書くことができます。
並べ替え1
def qsort(S): if S==[]:return [] H,T=S[0],S[1:] return qsort([X for X in T if X<T])+[H]+qsort([X for X in T if X>=T])
単語は次のように話すことができます: 並べ替えは最初の要素をベースとして、次にすべての小さな要素が並べ替えられ、並べ替えられる前にすべての大きな要素に接続されます 。
または、そのような式は、近くの要素の並べ替えの不器用な形式で書かれた並べ替えよりも速く動作するかもしれません。 これをもっと簡潔に表現することはできますか? バブルでソートする原理を大声で定式化して、米国大統領に伝えてみてください。彼はこれらの神聖なデータを入手し、アルゴリズムについて学び、それを次のようにレイアウトしたからです: リストをソートするには、いくつかの要素を取り、それらを比較し、最初の要素が2番目の要素よりも大きい場合、それらを交換し、再配置する必要があります。次に、順列が終了するまで、リストの最初からそのような要素のペアの検索を繰り返す必要があります 。
はい、バブルの並べ替えの原理はクイックソートバージョンよりも長く聞こえますが、2番目の利点はレコードの簡潔さだけでなく、その速度にもあります。アルゴリズムによって定式化された同じクイックソートの表現は、宣言的に表現されたバージョンよりも高速ですか? プログラミング教育についての見方を変える必要があるかもしれませんが、日本人がどのようにプロローグの教えと関連する考え方を学校で紹介しようとしたかが必要です。 体系的に思考の表現のアルゴリズム言語から遠ざかることができます。
並べ替え2
これを再現するには、 文献に目を向ける必要がありました 。これはHoarの声明であり、Pythonに変換しようとしています。
def quicksort(A, lo, hi): if lo < hi: p = partition(A, lo, hi) quicksort(A, lo, p - 1) quicksort(A, p + 1, hi) return A def partition(A, lo, hi): pivot = A[lo] i = lo - 1 j = hi + 1 while True do: i= i + 1 while A[i] < pivot do : j= j - 1 while A[j] > pivot if i >= j: return j A[i],A[j]=A[j],A[i]
ここには無限のサイクルが必要だ、彼はそこにゴー・ザットを挿入しただろうという考えを賞賛します)、ジョーカーがいました。
分析
それでは、長いリストを作成して両方の方法でソートし、考えをより速く、より効率的に表現する方法を理解しましょう。 どのアプローチが簡単ですか?
乱数のリストを別の問題として作成すると、次のように表現できます。
def qsort(S): if S==[]:return [] H,T=S[0],S[1:] return qsort([X for X in T if X<H])+[H]+qsort([X for X in T if X>=H]) import random def test(len): list=[random.randint(-100, 100) for r in range(0,len)] from time import monotonic start = monotonic() slist=qsort(list) print('qsort='+str(monotonic() - start)) ##print(slist)
得られた測定値は次のとおりです。
>>> test(10000) qsort=0.046999999998661224 >>> test(10000) qsort=0.0629999999946449 >>> test(10000) qsort=0.046999999998661224 >>> test(100000) qsort=4.0789999999979045 >>> test(100000) qsort=3.6560000000026776 >>> test(100000) qsort=3.7340000000040163 >>>
次に、アルゴリズムの定式化でこれを繰り返します。
def quicksort(A, lo, hi): if lo < hi: p = partition(A, lo, hi) quicksort(A, lo, p ) quicksort(A, p + 1, hi) return A def partition(A, lo, hi): pivot = A[lo] i = lo-1 j = hi+1 while True: while True: i=i+1 if(A[i]>=pivot) or (i>=hi): break while True: j=j-1 if(A[j]<=pivot) or (j<=lo): break if i >= j: return max(j,lo) A[i],A[j]=A[j],A[i] import random def test(len): list=[random.randint(-100, 100) for r in range(0,len)] from time import monotonic start = monotonic() slist=quicksort(list,0,len-1) print('quicksort='+str(monotonic() - start))
アルゴリズムの元の例を古代のソースからウィキペディアに変換する作業をしなければなりませんでした。 そのため、サポート要素を取得し、サブアレイ内の要素を配置して、すべてが左に、右にますます少なくなるようにする必要があります。 これを行うには、左の要素と右の要素を交換します。 インデックスで除算された参照要素の各サブリストに対してこれを繰り返します。 変更するものがなければ、終了します。
合計
同じリストで時間差がどうなるかを見てみましょう。このリストは、2つの方法で順番にソートされます。 100回の実験を実行し、グラフを作成します。
import random def test(len): t1,t2=[],[] for n in range(1,100): list=[random.randint(-100, 100) for r in range(0,len)] list2=list[:] from time import monotonic start = monotonic() slist=qsort(list) t1+=[monotonic() - start] #print('qsort='+str(monotonic() - start)) start = monotonic() slist=quicksort(list2,0,len-1) t2+=[monotonic() - start] #print('quicksort='+str(monotonic() - start)) import matplotlib.pyplot as plt fig = plt.figure() ax = fig.add_subplot(111) ax.plot(range(1,100),t1,label='qsort') ax.plot(range(1,100),t2,label='quicksort') ax.legend() ax.grid(True) plt.show() test(10000)
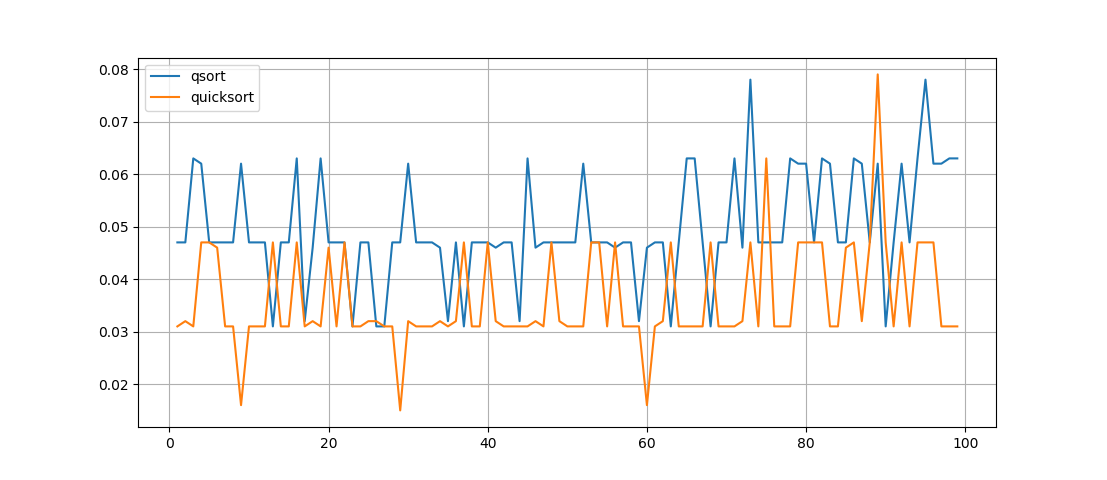
ここで見られるもの-quicksort()関数はより高速に動作しますが、その記録はそれほど明白ではありませんが、関数は再帰的ですが、実行される順列の動作を理解することはまったく簡単ではありません。
さて、ソート思考のどの表現がより意識的ですか?
パフォーマンスにわずかな違いがありますが、コードのボリュームと複雑さにはこのような違いがあります。
命令型言語を学習するには真実で十分かもしれませんが、あなたにとってより魅力的なものは何ですか?
PS。 そして、ここにプロローグがあります:
qsort([],[]). qsort([H|T],Res):- findall(X,(member(X,T),X<H),L1), findall(X,(member(X,T),X>=H),L2), qsort(L1,S1), qsort(L2,S2), append(S1,[H|S2],Res).