前の記事で、機能的かつ言語指向のプログラミング手法を使用して、仮想スタックマシン用のプログラムエグゼキューターを構築する方法について説明しました。 言語の数学的構造は、セミグループとモノイドの概念に基づいて、その翻訳者の実装の基本構造を示唆しました。 このアプローチにより、美しく拡張可能な実装を構築し、拍手を打つことができましたが、聴衆からの最初の質問は演壇を降りて再びEmacsに登りました。

簡単なテストを実施し、スタックのみを使用する単純なタスクで仮想マシンがスマートに動作し、「メモリ」(ランダムアクセスの配列)を使用すると大きな問題が発生することを確認しました。 プログラムのアーキテクチャの基本原則を変更せずにそれらを解決し、プログラムの千倍の高速化を達成した方法について、この記事で説明します。
Haskellは、特別なニッチを持つ独特の言語です。 その作成と開発の主な目標は、lingua francaが関数型プログラミングのアイデアを表現およびテストする必要性でした。 これは、その最も顕著な機能を正当化します:怠iness、最大限の純度、型の強調、およびそれらの操作。 これは、日常の開発用ではなく、産業用プログラミング用でも、広く使用するためでもありません。 ネットワーク業界やデータ処理で大規模プロジェクトを作成するために実際に使用されているという事実は、必要に応じて開発者の善意、概念実証です。 しかし、これまでのところ、Haskellで書かれた最も重要で広く使用されている驚くほど強力な製品は... ghcコンパイラです。 そして、これはその目的の観点から完全に正当化されます-コンピュータサイエンスの分野の研究のためのツールになること。 サイモン・ペイトン・ジョンソンによって宣言された原則:「どんな犠牲を払っても成功を避ける」は、言語がそのような道具であり続けるために必要です。 Haskellは、半導体技術やナノ材料を開発している研究センターの研究室にある無菌室のようなものです。 働くことはひどく不便であり、日常の実践では行動の自由も制限しますが、これらの不便さなしに、制限を妥協せずに遵守しなければ、後に産業発展の基礎となる微妙な効果を観察して研究することはできません。 同時に、産業界では、最も必要な量だけ無菌性が必要になり、これらの実験の結果は、ガジェットの形でポケットに表示されます。 星や銀河を研究するのは、それらから直接利益を得ることを期待するからではなく、これらの非実用的な物体の規模で、量子効果や相対論的効果が観測可能になり、研究されるようになったためです。 そのため、「間違った」線、計算の非実用的な怠inessさ、いくつかの型推論アルゴリズムの剛性、非常に急な入力曲線により、最終的には膝やオペレーティングシステムでスマートアプリケーションを簡単に作成できません。 しかし、レンズ、モナド、コンビナトリアル解析、モノイドの広範な使用、自動定理証明の方法、宣言型機能パッケージマネージャー、線形型および従属型が実際の世界に近づいています。 これにより、Python、Scala、Kotlin、F#、Rustなどの言語で、無菌状態の低いアプリケーションが見つかります。 しかし、関数型プログラミングの原則を教えるためにこれらの素晴らしい言語を使用することはありません。学生を研究室に連れて行き、明るくきれいな例でどのように機能するかを示します。大きくてわかりにくいが、非常に高速なマシン。 コーヒーメーカーを普及させるために電子顕微鏡に入れようとする試みに対する保護は、すべての犠牲を払って回避することです。 そして、言語がよりクールな競技会では、Haskellは常に通常のノミネートから外れます。
しかし、その人は弱く、悪魔も私の中に住んでいるので、他人の前で「私の好きな言語」を比較、評価、擁護します。 だから、このアイデアが私のために働くかどうかを見るという唯一の目的で、モノイダル構成に基づいて積み重ねられたマシンのエレガントな実装を書いた後、私は実装が見事に、しかしひどく非効率的であることに気づいたことにすぐに動揺しました! まるで本気で真剣な仕事に使ったり、PythonやJavaの仮想マシンが提供されているのと同じ市場でスタックドマシンを販売したりするようなものです。 しかし、それを気にして、会話全体が始まった子豚についての記事はそのようなおいしい数字を与えます:子豚の数百ミリ秒、Pythonの秒...そして私の美しいモノイドは1時間で同じタスクに対処できません! 私は成功しなければなりません! 私の顕微鏡は、研究所の廊下にあるコーヒーメーカーと同じくらいエスプレッソを醸造します! クリスタルパレスは分散して宇宙に打ち上げることができます!
しかし、あなたはあきらめる準備ができていますか、数学者の天使は私に尋ねますか? 宮殿建築の純度と透明性は? プログラムから他のソリューションへの準同型性が提供する柔軟性と拡張性? 悪魔と天使はどちらも頑固であり、私も私に生きさせている賢明な道教徒は、私たちが両方に合った道を取り、可能な限りそれに従うことを示唆しました。 ただし、勝者を特定することを目的とするのではなく、パス自体を知り、それがどの程度進んでいるかを調べ、新しい経験を得るために。 そして、私は最適化の無駄な悲しみと喜びを知っていました。
始める前に、効果の観点からの言語の比較は無意味であると付け加えます。 翻訳者(通訳者またはコンパイラ)、または言語を使用するプログラマのパフォーマンスを比較する必要があります。 最終的に、Cプログラムが最速であるという主張は、たとえばBASICで完全なCインタプリタを書くことで簡単に論破できます。 そのため、Haskellとjavascriptを比較するのではなく、 ghc
によってコンパイルされたghc
によって実行されたプログラムと、たとえば特定のブラウザーで実行されたプログラムのパフォーマンスを比較しています。 豚の用語はすべて、積み重ねられた機械に関する刺激的な記事に由来しています。 記事に付随するすべてのHaskellコードは、 リポジトリで調べることができます 。
快適地帯を離れる
開始位置は、 EDSLの形式でのモノイダルスタックマシンの実装です。これは、2ダースのプリミティブを組み合わせて仮想スタックマシンのプログラムをレンダリングできる小さなシンプルな言語です。 彼が2番目の記事に入ったらすぐに、彼にmonopig
という名前をmonopig
ます。 スタックマシンの言語は、連結操作と空の操作を1つの単位としてモノイドを形成するという事実に基づいています。 したがって、彼自身は機械の状態のモノイド変換の形で構築されました。 状態には、スタック、ベクトル形式のメモリ(要素へのランダムアクセスを提供する構造)、緊急停止フラグ、およびデバッグ情報を蓄積するためのモノイダルバッテリが含まれます。 この構造全体が、操作から操作への内部準同型のチェーンに沿って送信され、計算プロセスを実行します。 プログラムコードの同型構造は 、プログラムが形成する構造から構築され、それから、引数とメモリの数の観点からプログラムの要件を表す他の有用な構造に準同型変換されます。 構築の最終段階は、クレイズリーカテゴリでのモノイド変換の作成でした。これにより、任意のモナドに計算を浸すことができます。 そのため、マシンには入出力とあいまいな計算の機能がありました。 この実装から始めます。 彼女のコードはここにあります 。
エラトステネスのふるいの素朴な実装でプログラムの有効性をテストします。これは、メモリ(配列)をゼロと1で満たし、素数をゼロで表します。 アルゴリズムの手続きコードをjavascript
で提供します。
var memSize = 65536; var arr = []; for (var i = 0; i < memSize; i++) arr.push(0); function sieve() { var n = 2; while (n*n < memSize) { if (!arr[n]) { var k = n; while (k < memSize) { k+=n; arr[k] = 1; } } n++; } }
アルゴリズムはすぐに最適化されます。 すでに満たされているメモリセルを悪用することはありません。 私の数学者の天使は、 PorosenokVM
プロジェクトの例からの本当に素朴なバージョンには同意しませんでした。この最適化にはスタック言語の5つの命令しか必要ないからです。 アルゴリズムがmonopig
変換される方法はmonopig
です。
sieve = push 2 <> while (dup <> dup <> mul <> push memSize <> lt) (dup <> get <> branch mempty fill <> inc) <> pop fill = dup <> dup <> add <> while (dup <> push memSize <> lt) (dup <> push 1 <> swap <> put <> exch <> add) <> pop
そして、 monopig
と同じ型を使用して、このアルゴリズムの同等の実装を慣用的なHaskell上でどのように書くことができるかを以下に示します。
sieve' :: Int -> Vector Int -> Vector Int sieve' km | k*k < memSize = sieve' (k+1) $ if m ! k == 0 then fill' k (2*k) m else m | otherwise = m fill' :: Int -> Int -> Vector Int -> Vector Int fill' knm | n < memSize = fill' k (n+k) $ m // [(n,1)] | otherwise = m
Data.Vector
タイプとそれを操作するツールを使用しますが、Haskellでの日常的な作業にはあまり一般的ではありません。 式m ! k
m ! k
はベクトルm
のk
番目の要素を返し、 m // [(n,1)]
-番号n
要素をm // [(n,1)]
設定します。Haskellで働いていても、助けが必要なため、ここに書いています。ほぼ毎日。 実際のところ、機能実装でのランダムアクセスを備えた構造は非効率的であり、この理由から愛されていません。
子豚に関する記事で指定された競合条件に従って、アルゴリズムは100回実行されます。 特定のコンピューターを削除するために、これら3つのプログラムの実行速度を比較し、Chromeで実行されたjavascript
プログラムのパフォーマンスを参照してみましょう。
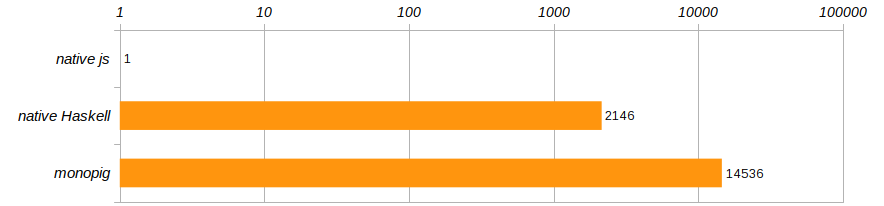
ホラーホラー!!! monopig
はmonopig
スローダウンするだけでなく、ネイティブバージョンはそれほど良くありません! もちろん、Haskellはクールですが、ブラウザで実行されているプログラムに劣りませんか?! コーチが教えてくれるように、あなたはそのように生きることはできません。Haskellが提供する快適ゾーンを離れる時です!
怠lazを克服する
正しくしましょう。 これを行うには、 -rtsopts
フラグをmonopig
して-rtsopts
プログラムをコンパイルし、実行時の統計を-rtsopts
、エラトステネスシーブを1回実行する必要があるものを確認します。
$ ghc -O -rtsopts ./Monopig4.hs [1 of 1] Compiling Main ( Monopig4.hs, Monopig4.o ) Linking Monopig4 ... $ ./Monopig4 -RTS -sstderr "Ok" 68,243,040,608 bytes allocated in the heap 6,471,530,040 bytes copied during GC 2,950,952 bytes maximum residency (30667 sample(s)) 42,264 bytes maximum slop 15 MB total memory in use (7 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 99408 colls, 0 par 2.758s 2.718s 0.0000s 0.0015s Gen 1 30667 colls, 0 par 57.654s 57.777s 0.0019s 0.0133s INIT time 0.000s ( 0.000s elapsed) MUT time 29.008s ( 29.111s elapsed) GC time 60.411s ( 60.495s elapsed) <-- ! EXIT time 0.000s ( 0.000s elapsed) Total time 89.423s ( 89.607s elapsed) %GC time 67.6% (67.5% elapsed) Alloc rate 2,352,591,525 bytes per MUT second Productivity 32.4% of total user, 32.4% of total elapsed
最後の行は、プログラムが生産的なコンピューティングに従事したのは3分の1に過ぎなかったことを示しています。 残りの時間、ガベージコレクターはメモリから実行され、遅延計算のためにクリーンアップされました。 小児期に怠は良くないと何度も言われました! ここで、Haskellの主な機能は、数十億の遅延ベクトルおよびスタック変換を作成しようとして、私たちに損害を与えました。
この時点で数学の天使は指を持ち上げて、アロンゾ教会の時代以来、計算戦略が結果に影響を与えないという定理があるという事実について喜んで語っています。これは、効率の理由から自由に選択できることを意味します。 計算を厳密に変更することはまったく難しくありません!
スタックおよびメモリのタイプの宣言で、これらのフィールドを厳密にします。
data VM a = VM { stack :: !Stack , status :: Maybe String , memory :: !Memory , journal :: !a }
他のものは変更せず、すぐに結果を確認します。
$ ./Monopig41 +RTS -sstderr "Ok" 68,244,819,008 bytes allocated in the heap 7,386,896 bytes copied during GC 528,088 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 16 MB total memory in use (14 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 129923 colls, 0 par 0.666s 0.654s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.001s 0.001s 0.0006s 0.0007s INIT time 0.000s ( 0.000s elapsed) MUT time 13.029s ( 13.048s elapsed) GC time 0.667s ( 0.655s elapsed) EXIT time 0.001s ( 0.001s elapsed) Total time 13.700s ( 13.704s elapsed) %GC time 4.9% (4.8% elapsed) Alloc rate 5,238,049,412 bytes per MUT second Productivity 95.1% of total user, 95.1% of total elapsed
生産性が大幅に向上しました。 データの不変性により、合計メモリコストは依然として印象的でしたが、最も重要なことは、データの遅延を制限したことで、ガベージコレクターが遅延する機会があり、作業の5%だけが残っていることです。 評価に新しいエントリを入力します。

さて、厳密な計算により、Haskellのネイティブコードの速度に近づき、仮想マシンなしでは恥ずかしく遅くなります。 これは、不変ベクトルを使用するオーバーヘッドが、スタックされたマシンを維持するコストを大幅に上回ることを意味します。 これは、メモリの不変性に別れを告げる時が来たことを意味します。
人生を変える
Data.Vector
型Data.Vector
適切ですが、それを使用して、コンピューティングプロセスの純度を維持するために、コピーに多くの時間を費やします。 これをData.Vector.Unpacked
タイプに置き換えると、少なくとも構造体のパッケージングは節約されますが、これにより画像が根本的に変わることはありません。 正しい解決策は、マシンの状態からメモリを削除し、Claysleyカテゴリを使用して外部ベクトルへのアクセスを提供することです。 さらに、純粋なベクトルとともに、いわゆる可変(可変)ベクトルData.Vector.Mutable
使用できます。
適切なモジュールを接続し、クリーンで機能的なプログラムで可変データを処理する方法を考えます。
import Control.Monad.Primitive import qualified Data.Vector.Unboxed as V import qualified Data.Vector.Unboxed.Mutable as M
これらのダーティタイプは、純粋な大衆から隔離されることになっています。 それらは、 PrimMonad
クラスのモナド( ST
またはIO
含む)に含まれており、クリーンプログラムは、貴重な羊皮紙にクリスタル関数型言語で記述されたアクションの指示を注意深く挿入します。 したがって、これらの汚れた動物の行動は厳密に正統的なシナリオによって決定され、危険ではありません。 私たちのマシンのすべてのプログラムがメモリを使用するわけではないので、アーキテクチャ全体をIO
モナドに没頭させる必要はありません。 monopig
言語のクリーンなサブセットとともに、メモリへのアクセスを提供する4つの命令を作成します。これらの命令のみが危険な領域にアクセスできます。
クリーンマシンの種類は短くなっています。
data VM a = VM { stack :: !Stack , status :: Maybe String , journal :: !a }
プログラムの設計者とプログラム自体はこの変更にほとんど気付かないでしょうが、そのタイプは変わります。 さらに、シグニチャーを簡素化するために、いくつかのタイプの同義語を定義することは理にかなっています。
type Memory m = M.MVector (PrimState m) Int type Logger ma = Memory m -> Code -> VM a -> m (VM a) type Program' ma = Logger ma -> Memory m -> Program ma
コンストラクタには、メモリアクセスを表す別の引数があります。 実行者、特に計算ログを保持している人は、変数ベクトルの状態を尋ねる必要があるため、大幅に変わります。 完全なコードはリポジトリで確認および調査できますが、ここで最も興味深いのは、メモリを操作するための基本コンポーネントの実装であり、これがどのように行われるかを示します。
geti :: PrimMonad m => Int -> Program' ma geti i = programM (GETI i) $ \mem -> \s -> if (0 <= i && i < memSize) then \vm -> do x <- M.unsafeRead mem i setStack (x:s) vm else err "index out of range" puti :: PrimMonad m => Int -> Program' ma puti i = programM (PUTI i) $ \mem -> \case (x:s) -> if (0 <= i && i < memSize) then \vm -> do M.unsafeWrite mem ix setStack s vm else err "index out of range" _ -> err "expected an element" get :: PrimMonad m => Program' ma get = programM (GET) $ \m -> \case (i:s) -> \vm -> do x <- M.read mi setStack (x:s) vm _ -> err "expected an element" put :: PrimMonad m => Program' ma put = programM (PUT) $ \m -> \case (i:x:s) -> \vm -> M.write mix >> setStack s vm _ -> err "expected two elemets"
puti
およびgeti
インデックスはプログラム作成の段階で既知であり、誤った値を事前に除去できるため、オプティマイザーデーモンはすぐにメモリ内の許容インデックス値のチェックをもう少し節約することを提案しました。 put
およびget
コマンドの動的に定義されたインデックスはセキュリティを保証せず、数学者のエンジェルはそれらへの危険な呼び出しを許可しませんでした。
メモリを個別の引数に入れることに関するこのすべての騒ぎは複雑に思えます。 しかし、データは場所によって変更されることを非常に明確に示しています。データは外部にある必要があります。 ピザ配達人を無菌検査室に連れて行こうとしていることを思い出させてください。 純粋な機能は何をすべきかを知っていますが、これらのオブジェクトは決して一流の市民になることはなく、実験室でピザを準備する価値はありません。
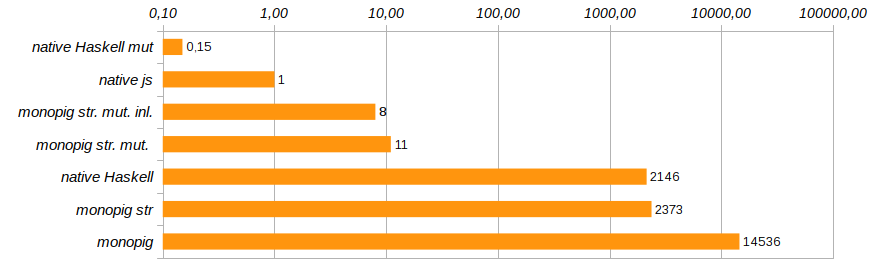
これらの変更で購入したものを確認しましょう。
$ ./Monopig5 +RTS -sstderr "Ok" 9,169,192,928 bytes allocated in the heap 2,006,680 bytes copied during GC 529,608 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 2 MB total memory in use (0 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 17693 colls, 0 par 0.094s 0.093s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.000s 0.000s 0.0002s 0.0003s INIT time 0.000s ( 0.000s elapsed) MUT time 7.228s ( 7.232s elapsed) GC time 0.094s ( 0.093s elapsed) EXIT time 0.000s ( 0.000s elapsed) Total time 7.325s ( 7.326s elapsed) %GC time 1.3% (1.3% elapsed) Alloc rate 1,268,570,828 bytes per MUT second Productivity 98.7% of total user, 98.7% of total elapsed
これはすでに進行中です! メモリ使用量は8倍に削減され、プログラムの実行速度は180倍に増加し、ガベージコレクターはほぼ完全に作業なしで残りました。

溶液はmonopig st。に見えました。 mut。 、これはjs
のネイティブソリューションよりも10倍遅いですが、Haskellのネイティブソリューションとは異なり、可変ベクトルを使用しています。 彼のコードは次のとおりです。
fill' :: Int -> Int -> Memory IO -> IO (Memory IO) fill' knm | n > memSize-k = return m | otherwise = M.unsafeWrite mn 1 >> fill' k (n+k) m sieve' :: Int -> Memory IO -> IO (Memory IO) sieve' km | k*k < memSize = do x <- M.unsafeRead mk if x == 0 then fill' k (2*k) m >>= sieve' (k+1) else sieve' (k+1) m | otherwise = return m
次のように始まります
main = do m <- M.replicate memSize 0 stimes 100 (sieve' 2 m >> return ()) print "Ok"
そして今、Haskellはついに彼がおもちゃの言語ではないことを示しています。 あなたはそれを賢く使用する必要があります。 ところで、上記のコードは、タイプIO ()
がプログラムの順次実行(>>)
の操作でセミグループを形成し、 stimes
の助けを借りてテスト問題の計算を100回繰り返したという事実を使用しています。
これで、関数配列がそんなに嫌いなのはなぜか、そしてなぜ彼らと一緒に作業するのか誰も覚えていないのは明らかです。
コマンドの一部を特別なゾーンに入れると、同型の合法性に疑問が生じます プログラム 。 結局のところ、コードを同時に純粋なプログラムとモナドなものに変えることはできません。これにより、型システムはそうすることができません。 ただし、型クラスはこの同型が存在するのに十分な柔軟性を備えています。 準同型写像 このプログラムは現在、言語のさまざまなサブセットのいくつかの準同型に分割されています。 これがどのように行われるかは、プログラムの[コード]()全体で確認できます。
止まらないで
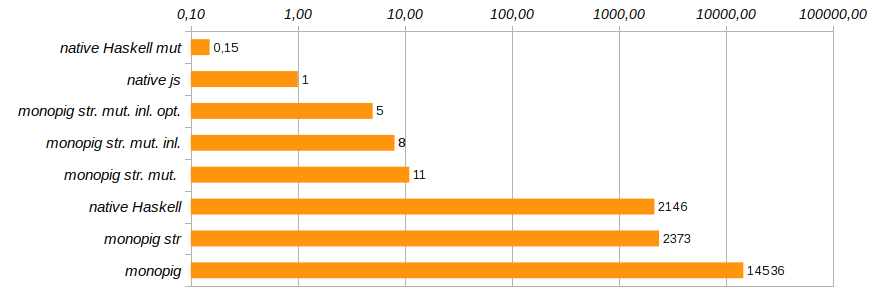
不要な関数呼び出しをなくし、 {-# INLINE #-}
プラグマを使用してコードを直接埋め込むと、プログラムの生産性がわずかに変わります。 このメソッドは、再帰関数には適していませんが、基本的なコンポーネントおよびセッター関数には適しています。 テストプログラムの実行時間をさらに25% 短縮します( Monopig51.hsを参照)。
次の妥当なステップは、ログツールが不要な場合は削除することです。 プログラムを表す内部準同型の形成の段階で、起動時に決定する外部引数を使用します。 スマートコンストラクターprogram
およびprogramM
は、引数ロガーがない可能性があることを警告できます。 この場合、コンバータコードには余分なものは含まれていません。機能とマシンのステータスの確認のみです。
program code f = programM code (const f) programM code f (Just logger) mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> logger mem code =<< f mem (stack vm) vm _ -> return vm programM code f _ mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> f mem (stack vm) vm _ -> return vm
現在、実行中の関数は、 none
スタブを使用せnone
、 Maybe (Logger ma)
タイプMaybe (Logger ma)
を使用して、ロギングの有無を明示的に示す必要があります。 ロギングがあるかどうかにかかわらず、プログラムコンポーネントは実行の前に「最後の瞬間」を見つけるので、なぜこれが機能するのですか? プログラムの構成を作成する段階で、不要なコードを縫い付けませんか? Haskellは怠zyな言語であり、ここで私たちの手に渡ります。 最終コードが特定のタスク用に最適化されるのは、実行前です。 この最適化により、プログラムの実行時間がさらに40%短縮されました( Monopig52.hsを参照)。
これで、モノイドの子豚を加速する作業を完了します。 彼はすでに天使と悪魔の両方が落ち着くことができるように十分に速く走っています。 もちろん、これはCではなく、まだクリーンリストをスタックとして使用していますが、それを配列に置き換えると、コードが徹底的にシャベルになり、基本的なコマンドの定義でエレガントなテンプレートの使用が拒否されます。 最小限の変更で、主にタイプのレベルで対処したかったのです。
ロギングにはいくつかの問題が残っています。 単純なステップ数のカウントやスタックの使用はうまく機能します(ログフィールドを厳密にしました)が、それらのペアリングは既にメモリを消費し始めているので、 seq
を使用してキックに悩まさなければなりません。 しかし、最初の数百のタスクをデバッグできる場合、誰が140億のステップを記録しますか? したがって、加速のために加速に時間を費やすことはありません。
計算を最適化する方法の1つとして、子豚に関する記事にそれを追加するだけです。トレースの提供:コードの線形セクションの割り当て、メインコマンドディスパッチサイクル( switch
ブロック)をバイパスして計算を実行できるトレース 。 この場合、プログラムコンポーネントのモノイド構成は、EDSコンポーネントからのプログラムの形成中、またはfromCode
準同型がfromCode
いるときに、そのようなトレースを作成します。 この最適化方法は、いわば、建設によって無料で提供されます。
Haskellエコシステムには、 Conduits
やPipes
ストリームなどのConduits
高速なソリューションが数多くあり、優れたString
置換やblaze-htmlなどの軽快なXMLクリエーターがありますattoparsec
パーサーは、LL(∞)文法の組み合わせ分析の標準です。 これはすべて通常の操作に必要です。 しかし、これらの決定につながる研究がさらに必要です。 Haskellはこれまでも現在も、一般の人々が必要としない特定の要件を満たす研究ツールです。 私はカムチャッカで、Mi-4ヘリコプターのエースが議論でマッチ箱を閉じ、空中にぶら下がっている間に車輪で着陸装置を押す方法を見ました。 これは実行できますが、クールですが必要ではありません。
しかし、それにもかかわらず、これはクールです!!