シングルスレッドのパラダイムからマルチスレッドへの移行のように、分散システムへの移行には、内部での動作、注意を払う必要のあるものの一種の没入感と理解が必要です。
プロジェクトを分散システムに移行したり、そのシステムでプロジェクトを開始したりする際に直面する問題の1つは、選択する製品です。
私たちは、この種のシステムの開発において「犬を食べた」企業として、クライアントが分散ストレージシステムに関してバランスのとれた意思決定を行えるよう支援します。 また、シンプルな言語の基本原則に焦点を当てた幅広い視聴者向けに一連のウェビナーをリリースしています。特定の食べ物の好みは、選択を容易にするための重要な機能のマッピングに役立ちます。
この記事は、分散システムにおける一貫性とACID保証に関する資料に基づいています。
それは何で、なぜ必要なのですか?
「 データの 整合性 ( データの整合性 )は、データの整合性、データの整合性、および内部の整合性です。」( Wikipedia )
一貫性とは、アプリケーションがいつでも、技術的に適切な正しいバージョンのデータを使用していることを確認でき、意思決定の際にそれを使用できることを意味します。
分散システムでは、異なるノード間のネットワーク交換、個々のノードの障害の可能性、および検証に役立つ単一メモリの不足に関連する一連の新しい課題が発生するため、一貫性の確保がより困難かつ高価になります。
たとえば、銀行取引を提供する4つのノードA、B、C、Dのシステムがあり、ノードCとDがAとBから分離されている場合(たとえば、ネットワークの問題のため)、私は今ではない可能性が高いトランザクションの一部にアクセスできます。 この状況でどのように行動しますか? システムが異なれば、アプローチも異なります。

最上位レベルには、CAP定理で表現される2つの主要な方向があります。
「 CAP定理 ( Brewerの定理とも呼ばれます)は、分散コンピューティングの実装では、次の3つのプロパティのうち2つ以下しか提供できないというヒューリスティックなステートメントです。
- データの一貫性(一貫性)-ある時点でのすべてのコンピューティングノードで、データは互いに矛盾しません。
- 可用性(Eng。可用性)-分散システムへの要求はすべて正しい応答で終了しますが、システムのすべてのノードの回答が一致することを保証するものではありません。
- パーティショントレランス-分散システムをいくつかの隔離されたセクションに分割しても、各セクションからの誤った応答は発生しません。
( ウィキペディア )
CAP定理が一貫性について話すとき、それはレコードと読み値の線形化を含む、かなり厳密な定義を意味し、個々の値を書き込むとき一貫性のみを規定します。 ( マーティン・クレップマン )
CAPの定理によれば、ネットワークの問題に抵抗する場合は、一般的に一貫性とアクセシビリティのどちらを犠牲にするかを選択する必要があります。 この定理の拡張版であるPACELC( Wikipedia )もあります。これは、ネットワークの問題がなくても、応答速度と一貫性のどちらかを選択する必要があるという事実についても説明しています。
そして、一見、古典的なDBMSの世界のネイティブですが、選択は明白であり、一貫性が私たちが持っている最も重要なことであるように見えますが、これは常にそうではなく、異なる選択をした多くのNoSQL DBMSの爆発的な成長を明確に示していますそれにもかかわらず、彼らは巨大なユーザーベースを得ました。 最終的な一貫性が有名なApache Cassandraは、良い例です。
これは、これが私たちが何かを犠牲にしていることを意味する選択であり、常にそれを犠牲にする準備ができていないという事実のためです。
多くの場合、分散システムの一貫性の問題は、この一貫性を放棄するだけで解決されます。
しかし、この一貫性の拒否がいつ受け入れられるのか、それがビジネス上の重要な要件であるのかを理解することが必要であり、重要です。
たとえば、ユーザーセッションの保存を担当するコンポーネントを設計する場合、ここではおそらく、一貫性はそれほど重要ではなく、問題のある場合にのみ発生するデータ損失は重要ではありません-非常にまれです。 最悪の事態は、ユーザーがログインする必要があることです。多くのビジネスでは、これは財務パフォーマンスにほとんど影響しません。
センサーからのデータストリームの分析を行う場合、多くの場合、特に最終的にデータを見る場合、一部のデータを失い、短期間ダウンサンプリングすることはまったく重要ではありません。
しかし、銀行システムを作る場合、現金取引の一貫性は私のビジネスにとって重要です。 クライアントがシステムにいたにもかかわらず、期限内に支払いが行われなかったためにクライアントのローンにペナルティが発生した場合、これは非常に悪いです。 クライアントが私のクレジットカードからすべてのお金を数回引き出すことができるのと同様に、トランザクション時にネットワークの問題があり、引き出し情報がクラスターの一部に届かなかったためです。
オンラインストアで高価な商品を購入する場合、Webページでの成功レポートにもかかわらず、注文が忘れられることは望ましくありません。
しかし、一貫性を選択すると、アクセシビリティが犠牲になります。 そして、多くの場合、これは予想されることであり、最も可能性が高いのは、あなたがこの問題に何度も遭遇したことです。
オンラインストアのバスケットに「後で試してください。分散DBMSは利用できません」と表示されている方が、成功を報告して注文を忘れる場合よりも優れています。 銀行のサービスが利用できないために取引を拒否される方が、成功を打ち負かした後、ローンを支払ったことを忘れたという事実のために銀行で手続きを行うよりも良いです。
最後に、拡張されたPACELCの定理を見ると、一貫性を選択するシステムの通常の操作の場合でも、低レイテンシを犠牲にして、潜在的に最大レベルの最大パフォーマンスを得ることができることがわかります。
したがって、「なぜこれが必要なのか?」という質問に答えます:タスクが最新の完全なデータを保持することが重要である場合は、代替手段により、インシデントの期間またはそのパフォーマンスが低下するため、サービスが一時的に利用できなくなるよりも大きな損失が発生します。
これを提供するには?
したがって、最初に決定する必要があるのは、CAP定理のどこにいるのか、インシデントの場合に一貫性または可用性を確保することです。
次に、どのレベルで変更を加えるかを理解する必要があります。 おそらく、MongoDBが有効であり、有効であるため、単一のオブジェクトに影響する十分なアトミックレコードがあるだけです(本格的なトランザクションの追加サポートでこれを拡張します)。 CAP定理は、複数のオブジェクトを含む書き込み操作の一貫性については何も言っていないことを思い出してください:システムはCPである可能性があり(つまり、アクセシビリティの一貫性を好む)、同時にアトミックな単一レコードのみを提供します。
これでは不十分な場合、本格的な分散ACIDトランザクションの概念に取り組み始めます。
分散ACIDトランザクションの勇敢な新しい世界に移行するときでさえ、しばしば何かを犠牲にしなければならないことに注意してください。 たとえば、多くの分散ストレージシステムには分散トランザクションがありますが、単一のパーティション内のみです。 または、たとえば、システムは必要なレベルで「I」部分をサポートしない場合があります。これは、分離なしで、または分離レベルの数が不十分です。
多くの場合、これらの制限は、実装を簡素化するため、または生産性を向上させるためなど、何らかの理由で行われました。 多数のケースで十分なので、それ自体を短所と見なさないでください。
これらの制限が特定のシナリオの問題であるかどうかを理解する必要があります。 そうでない場合は、選択肢が増え、たとえばパフォーマンスインジケータやシステムが耐障害性を提供する能力などに、より大きな重みを付けることができます。 最後に、多くのシステムでは、これらのパラメーターは、構成に応じてCPまたはAPになるまで調整できることを忘れてはなりません。
当社の製品がCPを目指す場合、通常、データ選択に対する定足数アプローチ、またはレコードの主な所有者である専用ノードがあり、すべてのデータ変更はそれらを通過し、ネットワークの問題の場合、これらのマスターノードが提供できない場合答えは、外部のアクセスしやすいコンポーネント(ZooKeeperクラスターなど)がどのクラスターセグメントがメインのものであり、現在のバージョンのデータを含み、リクエストを効率的に処理できる場合、原則としてデータを取得または調停できないと考えられています 秒。
最後に、CPだけでなく、本格的な分散ACIDトランザクションのサポートに関心がある場合、単一の真実のソースがよく使用されます。たとえば、実際にはノードがキャッシュとしてのみ機能する集中ディスクストレージが使用されます。コミット時間、またはマルチフェーズコミットプロトコルが適用されます。
最初のシングルドライブアプローチは、実装を簡素化し、分散トランザクションのレイテンシを低くしますが、その代わりに、大容量の記録ボリュームを使用した負荷のスケーラビリティが非常に制限されます。
2番目のアプローチでは、スケーリングの自由度が大幅に向上し、2段階( Wikipedia )と3段階( Wikipedia )のコミットプロトコルに分かれています。
Apache Igniteなどを使用する2フェーズコミットの例を考えてみましょう。
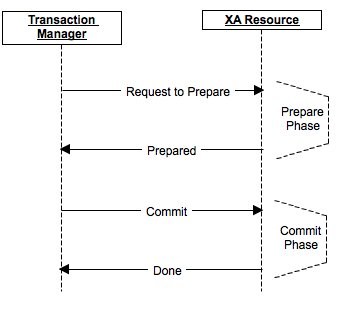

コミット手順は、準備とコミットの2つのフェーズに分かれています。
準備フェーズでは、コミットの準備に関するメッセージが準備され、必要に応じて各参加者がロックを行い、実際のコミットまでのすべての操作を実行し、製品で想定されている場合はレプリカに準備を送信します。 参加者の少なくとも1人がなんらかの理由で拒否で応答したか、利用できないことが判明した場合-データは実際には変更されなかったため、コミットはありませんでした。 参加者は変更をロールバックし、ロックを解除して元の状態に戻ります。
コミットフェーズでは、実際のコミットの実行がクラスターノードに送信されます。 何らかの理由でノードの一部が使用不可であるかエラーで応答した場合、その時点までにデータがREDOログに入力され(準備が成功したため)、いずれの場合でもコミットは少なくとも保留状態で完了できます。
最後に、コーディネーターが失敗すると、準備段階でコミットがキャンセルされ、コミット段階で新しいコーディネーターを選択できます。すべてのノードが準備を完了すると、コミット段階が完了したことを確認および確認できます。
異なる製品には、独自の実装および最適化機能があります。 そのため、たとえば、一部の製品では、2フェーズコミットを1フェーズコミットに減らすことができ、パフォーマンスが大幅に向上します。
結論
重要な結論:分散ストレージシステムはかなり発展した市場であり、その製品は高いデータ整合性を提供できます。
さらに、このカテゴリの製品は、一貫性スケールの異なるポイントにあります。トランザクション性のない完全なAP製品から、本格的なACIDトランザクションを追加で提供するCP製品までです。 一部の製品は、何らかの方法で構成できます。
必要なものを選択するときは、ケースのニーズを考慮に入れ、どのような犠牲と妥協をするのかをよく理解する必要があります。無料では何も起こりません。
この側から製品を評価するときは、次のことに注意する価値があります。
- それらがCAP定理のどこにあるか。
- 分散ACIDトランザクションをサポートしていますか?
- 分散トランザクションにどのような制限を課していますか(たとえば、単一のパーティション内でのみなど)。
- 分散トランザクションを使用する便利さと効率性、製品の他のコンポーネントへの統合。