最初の部分では、ディープラーニングによるドメイン適応の方法に慣れました。 主なデータセットと、不一致ベースおよび敵対ベースの非生成的アプローチについて説明しました。 これらのメソッドは、いくつかのタスクに適しています。 今回は、最も複雑で有望な敵対的手法を分析します。生成モデル、およびVisDAデータセットで最適な結果を示すアルゴリズム(合成データから実際の写真への適応)。

生成モデル
このアプローチの中心にあるのは、GANが必要な分布からデータを生成する機能です。 このプロパティのおかげで、適切な量の合成データを取得し、トレーニングに使用できます。 生成モデルファミリーのメソッドの主なアイデアは、ターゲットドメインの代表に可能な限り類似したソースドメインを使用してデータを生成することです。 したがって、新しい合成データには、取得元の元のドメインの代表と同じラベルが付けられます。 次に、ターゲットドメインのモデルは、この生成されたデータで単純にトレーニングされます。
ICML-2018で導入されたCyCADAメソッド:サイクル整合性のある敵対領域適応 ( コード )は、生成モデルファミリーの代表的なメンバーです。 GANとドメイン適応からのいくつかの成功したアプローチを組み合わせています。 この重要な部分は、 CycleGANの記事で最初に紹介された、サイクルの一貫性の損失の使用です。 サイクル整合性損失の考え方は、ソースからターゲットドメインへの生成によって得られたイメージとそれに続く逆変換が、初期イメージに近いはずだということです。 さらに、CyCADAには、ピクセルレベルおよびベクター表現のレベルでの適応、および生成された画像の構造を保存するためのセマンティック損失が含まれます。
させて そして -ターゲットドメインとソースドメインのネットワーク、それぞれ そして -ターゲットおよびソースドメイン、 -ソースドメインのマークアップ、 そして -ソースからターゲットドメインへのジェネレータ、およびその逆 そして -ターゲットドメインとソースドメインにそれぞれ属することの識別。 次に、CyCADAで最小化される損失関数は、6つの損失関数の合計になります(損失数を含むトレーニングスキームを以下に示します)。
- -モデル分類 ソースドメインから生成されたデータと擬似ラベル。
- -発電機トレーニングの敵対的損失 。
- -発電機トレーニングの敵対的損失 。
- (サイクル一貫性の損失)- -から得られる画像を保証する損失 そして 近くになります。
- -ベクトル表現の敵対的損失 そして 生成されたデータについて(ADDAで使用されるものと同様)。
- (意味的な一貫性の損失)- 損失、という事実の責任 から取得した画像と同様に機能します 両方から 。
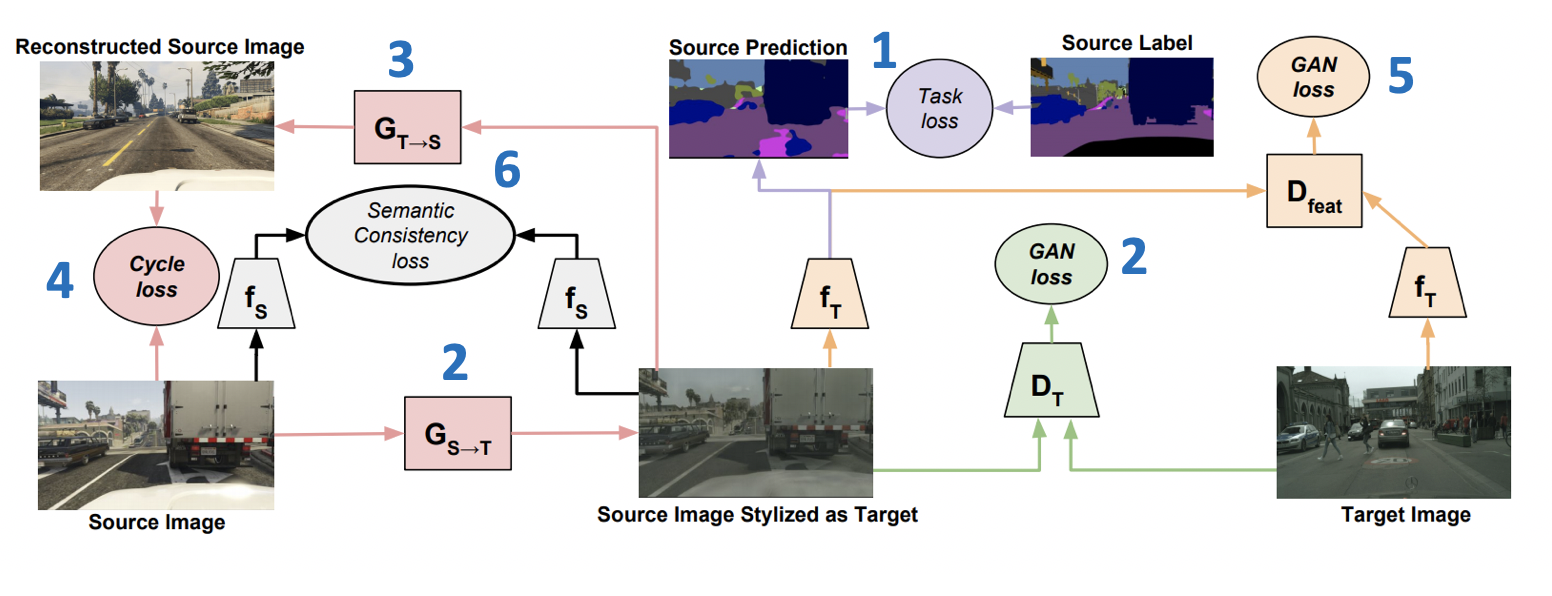
CyCADAの結果:
- USPSデジタルドメインのペア-> MNIST:95.7%。
- セグメンテーションGTA 5->都市景観のタスク:平均IoU = 39.5%。
アプローチの一部として、 Generateative Adversarial Networks ( code ) を使用して 、 Adaptive To Adapt:Domainsを使用してこのようなジェネレーターをトレーニングします 出力で元のドメインに近い画像が生成されるようにします。 そのような ターゲットドメインからのデータを変換し、ソースドメインのマークアップされたデータでトレーニングされた分類子を適用できます。
そのようなジェネレータをトレーニングするために、著者は修正された弁別器を使用します 記事AC-GANから 。 この特徴 彼は、入力がソースドメインから来た場合は1、それ以外の場合は0だけでなく、回答が肯定的な場合、入力データをソースドメインのクラスで分類するという事実から成ります。
示す 画像のベクトル表現を生成する畳み込みネットワークのように、 -から派生したベクトルで機能する分類器 。 学習および推論アルゴリズム:
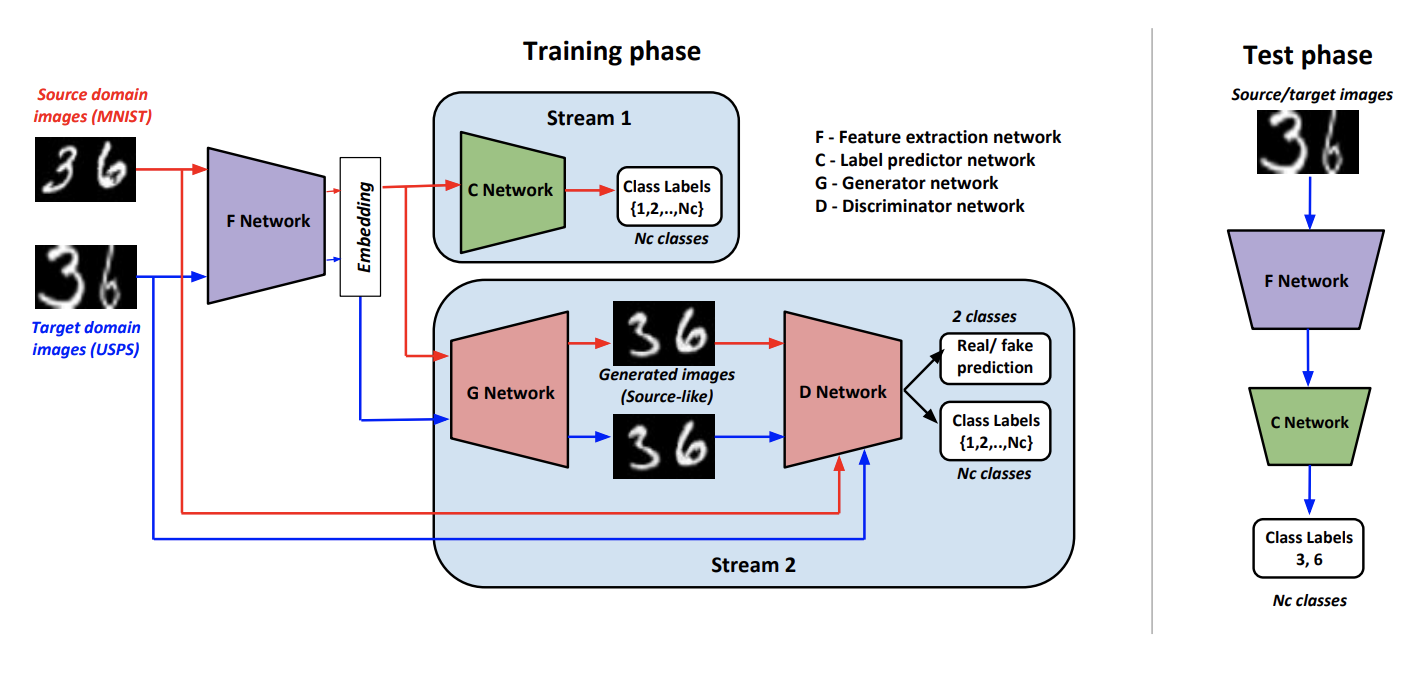
トレーニング手順は、いくつかのコンポーネントで構成されています。
- 弁別器 から受信したすべてのドメインを決定することを学ぶ データ、およびソースドメインの場合、上記のように分類損失が追加されます。
- ソースドメインからのデータ 敵対的損失と分類損失の組み合わせを使用して、ソースドメインに類似した結果を生成するようにトレーニングされ、正しく分類されます。 。
- そして ソースドメインのデータを分類する方法を学びます。 また 別の分類損失の助けを借りて、分類の質を高めるために変更されます 。
- 敵対的損失の使用 「チート」することを学ぶ ターゲットドメインからのデータ。
- 著者は、に提出する前に、経験的に結論しました からベクトルを連結することは理にかなっています 通常のノイズとワンホットクラスベクトル( ターゲットデータ用)。
ベンチマークでのメソッドの結果:
- USPSデジタルドメイン-> MNIST:90.8%。
- Officeデータセットでは、AmazonドメインとWebcamドメインのペアの平均適応品質は86.5%です。
- VisDAデータセットでは、不明なクラスのない12のカテゴリの平均品質値は76.7%です。
「 ソースからターゲットへ、そしてその逆:対称双方向適応GAN ( コード )」の記事でSBADA-GANモデルが導入されました。これはCyCADAと非常に似ており、CyCADAなどのターゲット機能は6つのコンポーネントで構成されます。 著者の表記で そして -ソースドメインからターゲットへのジェネレーター、およびその逆 そして -ソースドメインとターゲットドメインで生成されたものから実際のデータを区別する弁別器、 そして -ソースドメインからのデータおよびターゲットドメインに変換されたバージョンでトレーニングされた分類子。
SBADA-GANは、CyCADAと同様に、CycleGAN、一貫性の損失、およびターゲットドメインで生成されたデータの擬似ラベルの概念を使用して、対応する用語からターゲット関数を構成します。 SBADA-GANの機能は次のとおりです。
- 画像+ノイズは、ジェネレーターへの入力に供給されます。
- このテストでは、変換に基づくターゲットモデルとソースモデルの予測の線形結合を使用します 。
SBADA-GANトレーニングスキーム:
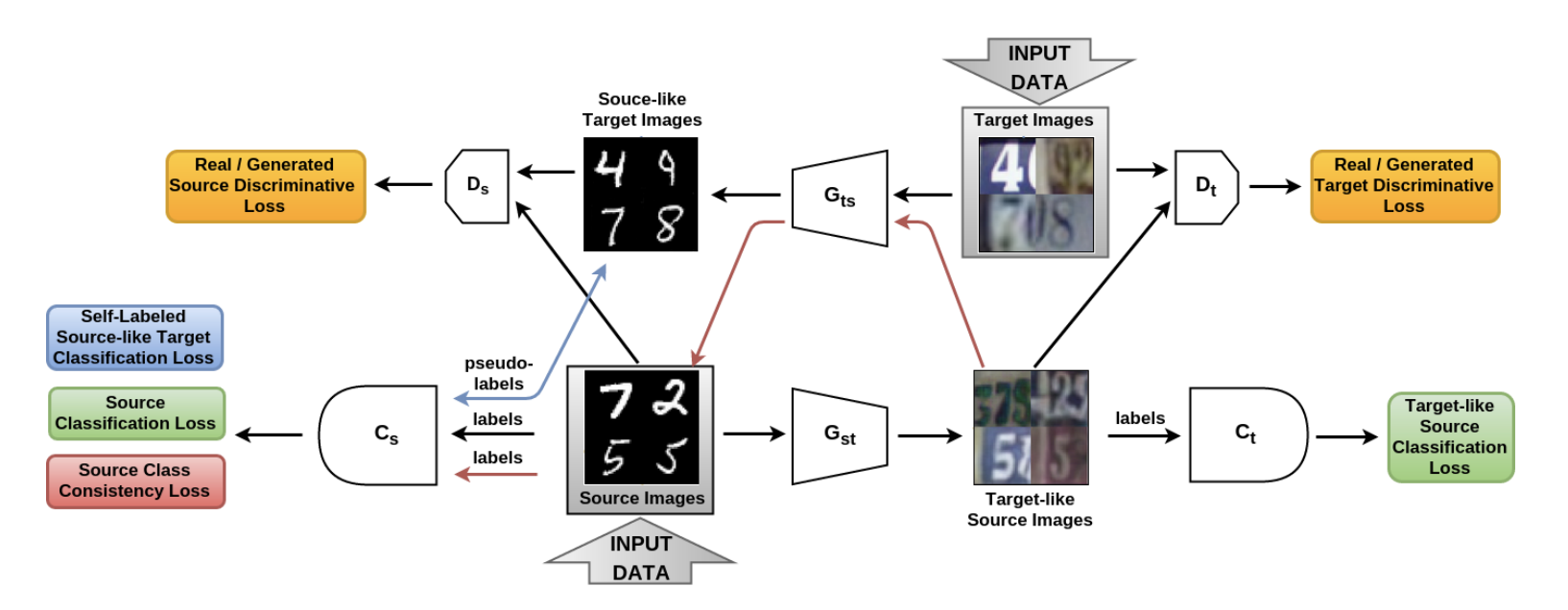
SBADA-GANの著者は、CyCADAの著者よりも多くの実験を行い、次の結果を得ました。
- USPS-> MNISTドメイン:95.0%。
- MNIST-> SVHNドメイン:61.1%。
- 道路標識でSynth Signs-> GTSRB:97.7%。
生成モデルのファミリーから、次のような重要な記事を検討することは理にかなっています。
視覚領域適応チャレンジ
ワークショップの一環として、ECCVおよびICCV会議はVisual Domain Adaptation Challengeドメイン適応コンテストを開催します。 その中で、参加者は分類器を合成データで訓練し、ImageNetからの未割り当てデータに適応させるよう招待されます。
視覚領域適応のための自己集合 ( コード )で提示されたアルゴリズムは、VisDA-2017で受賞しました。 この方法は、自己集合の考え方に基づいています。教師ネットワーク(教師モデル)と学生ネットワークがあります。 各反復で、入力イメージはこれらの両方のネットワークを介して実行されます。 生徒は、分類損失と一貫性損失の合計を使用してトレーニングされます。分類損失は、よく知られているクラスラベルとの通常の相互エントロピーであり、一貫性損失は、教師と生徒の予測の平均平方差(平方差)です。 教師ネットワークの重みは、学生ネットワークの重みの指数移動平均として計算されます。 このトレーニング手順を以下に示します。
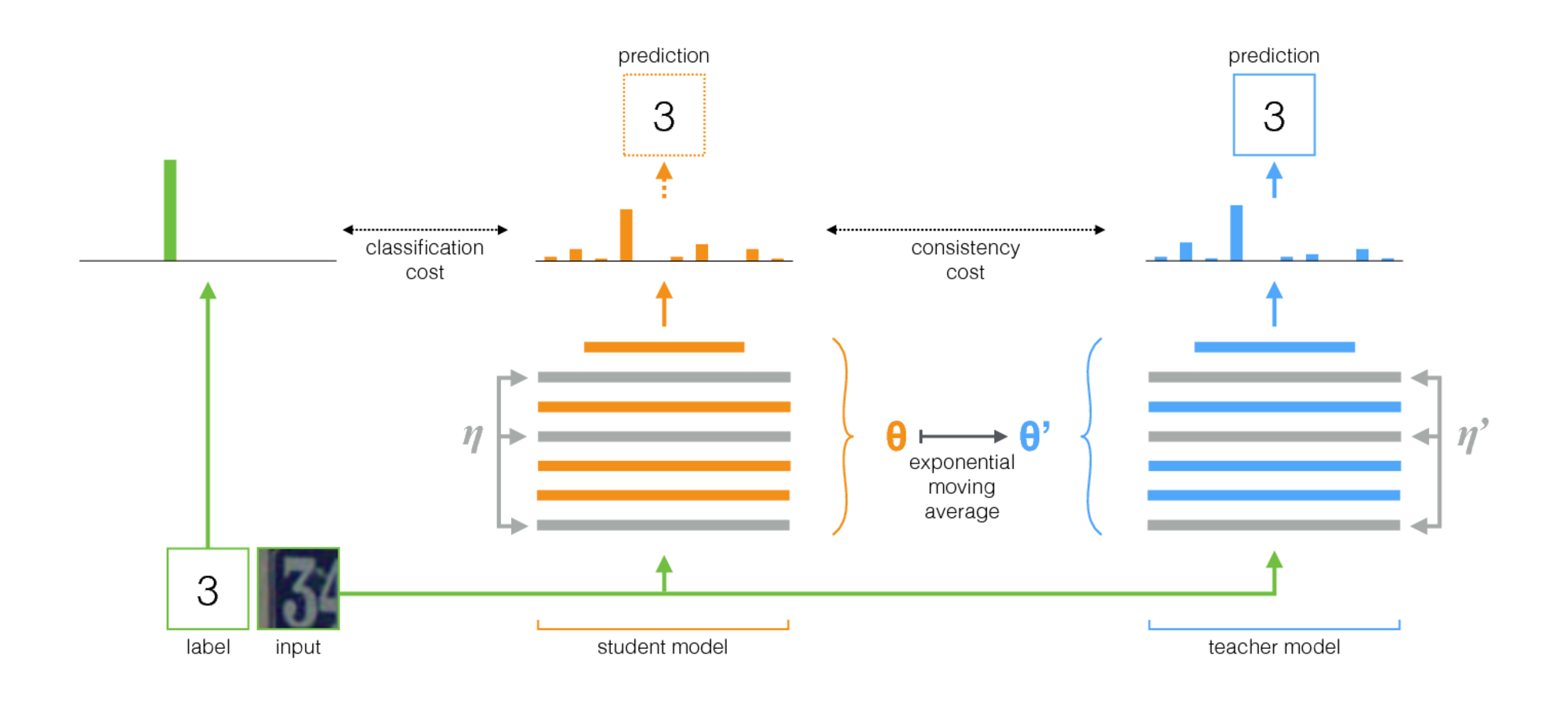
ドメイン適応のためのこのメソッドのアプリケーションの重要な機能は次のとおりです。
- トレーニングバッチでは、ソースドメインからのデータが混在しています クラスラベル付き およびターゲットドメインからのデータ タグなし。
- ニューラルネットワークへの入力の前に、ガウスノイズ、アフィン変換など、さまざまな強力な増強が入力画像に適用されます。
- 両方のネットワークは、強力な正則化方法(ドロップアウトなど)を使用しました。
- -学生ネットワーク出力、 -教師ネットワーク。 入力がターゲットドメインからのものである場合は、 そして 、クロスエントロピー損失= 0。
- 学習の持続可能性のために、信頼しきい値が使用されます。教師の予測がしきい値(0.9)より小さい場合、一貫性損失損失= 0です。
説明されている手順のスキーム:

メインデータセットでは、アルゴリズムが高いパフォーマンスを達成しました。 確かに、著者は各タスクに対して一連の拡張機能を個別に選択しました。
- USPS-> MNIST:99.54%。
- MNIST-> SVHN:97.0%。
- シンセ番号-> SVHN:97.11%。
- 道路標識のシンセ標識-> GTSRB:99.37%。
- VisDAデータセットでは、Unknownクラスのない12のカテゴリの平均品質値は92.8%です。 この結果は、5つのモデルのアンサンブルとテスト時間の拡張を使用して得られたことに注意することが重要です。
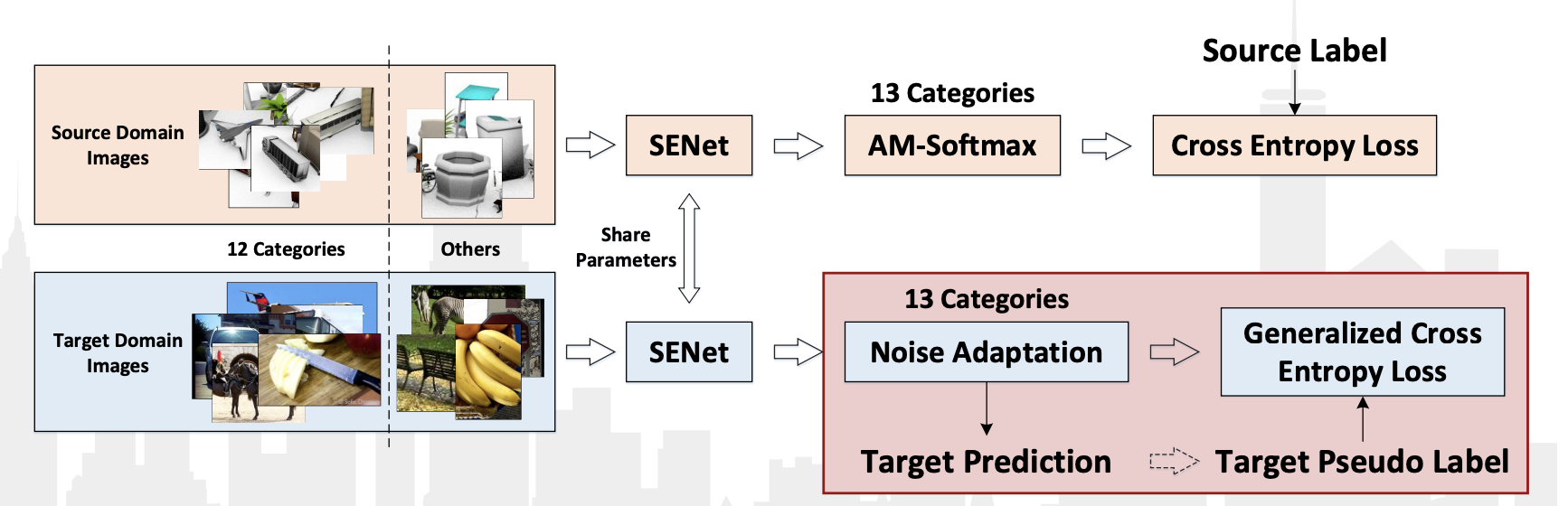
今年、VisDA-2018大会がECCV-2018カンファレンスの一環として開催されました。 今回は、13番目のクラス:Unknownを追加しました。これは、12のクラスに分類されなかったすべてのものを取得しました。 さらに、これらの12のクラスに属するオブジェクトを検出するための別のコンテストが開催されました。 両方のカテゴリーで、中国チームのJD AI Researchが優勝しました。 分類コンテストで、彼らは92.3%の結果(13のカテゴリでの品質の平均値)を達成しました。 その方法の詳細な説明を含む出版物はありません。 ワークショップからのプレゼンテーションのみがあります。
それらのアルゴリズムの特徴に注目することができます:
- ターゲットドメインからのデータに擬似ラベルを使用し、ソースドメインからのデータとともにそれらの分類子を再トレーニングします。
- 畳み込みネットワークSE-ResNeXt-101、AM-Softmaxおよびノイズ適応層を使用して、ターゲットドメインからのデータの一般化されたクロスエントロピー損失。
プレゼンテーションのアルゴリズム図:
おわりに
ほとんどの場合、敵対者ベースのアプローチに基づいた適応方法について説明しました。 ただし、最後の2回のVisDAコンテストでは、それに関係のないアルゴリズムで、擬似ラベルのトレーニングとより古典的なディープラーニングメソッドの修正を使用したアルゴリズムが勝ちました。 私の意見では、これは、GANに基づく方法はまだ開発の初期段階にあり、非常に不安定であるという事実によるものです。 しかし、毎年、GANの作業を改善する新しい結果が増えています。 さらに、ドメイン適応の分野での科学界の関心の焦点は、主に敵対ベースの方法に焦点を合わせており、新しい記事は主にこのアプローチを研究しています。 したがって、GANに関連付けられたアルゴリズムは、適応問題で徐々に最前線に立つ可能性があります。
しかし、非敵対的アプローチの研究も進行中です。 この分野の興味深い記事は次のとおりです。
不一致に基づく方法は「歴史的」として分類できますが、MMD、疑似ラベル、メトリック学習など、多くのアイデアが最新の方法で使用されています。 さらに、単純な適応の問題では、トレーニングの相対的な容易さと結果のより良い解釈のために、これらの方法を適用することが理にかなっている場合があります。
結論として、ドメイン適応の方法はまだ応用分野での応用を模索していますが、適応の使用を必要とする有望なタスクがますます増えていることに注意してください。 たとえば、ドメイン適応は自動運転車モジュールのトレーニングで積極的に使用されています 。自動操縦を訓練するために都市の路上で実際のデータを収集するのは高価で長いため、特に自動運転車は合成データを使用します(SYNTHIAおよびGTA 5データベースが例として使用されます)。 カメラが車から「見る」もののセグメンテーションの問題を解決します。
Computer Visionでの詳細なトレーニングに基づいて高品質のモデルを取得することは、トレーニング用の大きなラベル付きデータセットの可用性に大きく基づいています。 ほとんどの場合、マークアップには多くの時間とお金が必要です。これにより、モデルの開発サイクルが大幅に増加し、その結果、モデルに基づいた製品が開発されます。
ドメイン適応の方法は、この問題を解決することを目的としており、多くの応用問題や人工知能全般の突破口になる可能性があります。 あるドメインから別のドメインに知識を移転することは、本当に困難で興味深い作業であり、現在活発に研究されています。 タスクのデータ不足に悩まされ、データをエミュレートしたり、同様のドメインを見つけたりできる場合は、ドメイン適応方法を試すことをお勧めします!