こんにちは、マキシムです。システム管理者です。 3年前、同僚と私は製品をマイクロサービスに移行し始め、Openstackをプラットフォームとして使用することを決定し、テスト回路を自動化する際に多くの明らかな熊手に直面しました。 この投稿では、OpenStackのセットアップの微妙な点について説明します。これは、検索エンジンの結果の5ページ目にはほとんど見られません(または、最初のページに簡単に見つかります)。
コアの負荷:それは-それになりました
NAT
場合によっては、デュアルスタックを使用します。 これは、仮想マシンがIPv2とIPv6の2つのアドレスを一度に受信するときです。 最初に、「フローティング」v4アドレスがNATを介して内部ネットワークに割り当てられ、マシンがBGPを介してv6を受信したことを確認しましたが、これにはいくつかの問題があります。
NAT-ネットワーク内の追加ノード。これがなくても、通常の負荷分散を監視する必要があります。 ネットワーク上にNATが出現すると、ほとんどの場合デバッグが困難になります。ホスト上に1つのIP、データベース内にもう1つのIPがあり、リクエストを追跡することが難しくなります。 一括検索が開始され、ソリューションはまだOpenStack内にあります。
それでも、NATはプロジェクト間のアクセスの通常のセグメント化を許可していません。 すべてのプロジェクトには独自のサブネットがあり、フローティングIPは絶えず移行します。NATでは、これを管理することは明らかに不可能になります。 一部のインストールでは、NAT 1 in 1(内部アドレスは外部アドレスと変わらない)の使用について説明しますが、外部サービスとの相互作用のチェーンに不要なリンクが残っています。 私たちにとって最良のオプションはBGPネットワークであるという結論に達しました。
シンプルなほど良い
さまざまな自動化ツールを試しましたが、Ansibleに決めました。 これは優れたツールですが、標準の機能(追加のモジュールを考慮しても)は、いくつかの困難な状況では十分ではない場合があります。
たとえば、Ansibleモジュールでは、どのサブネットアドレスから割り当てるかを指定できません。 つまり、ネットワークを指定できますが、特定のアドレスプールを設定することはできません。 ここでは、フローティングIPを作成するシェルコマンドが役立ちます。
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NET
欠落している機能の別の例:デュアルスタックのため、v4とv6の2つのポートを持つルーターを適切に作成できません。 これは、bashスクリプトが便利な場所です。
#! /bin/bash # $1 - router_name # $2 - router_project # $3 - router_network # echo "${@:4}" - private subnet lists FIXED4_SUBNET="subnet-bgp-nexthop-v4" FIXED6_SUBNET="subnet-bgp-nexthop-v6" openstack --os-project-name $2 router show $1 if [ $? -eq 0 ] then echo "router is exist" exit 0 fi openstack --os-project-name $2 router create --project $2 $1 for subnet in "${@:4}"; do openstack --os-project-name $2 router add subnet $1 $subnet done openstack --os-project-name $2 router set $1 --external-gateway $3 --fixed-ip subnet=$FIXED4_SUBNET --fixed-ip subnet=$FIXED6_SUBNET
このスクリプトはルーターを作成し、v4およびv6サブネットを追加して、外部ゲートウェイを割り当てます。
再試行
理解できない状況では-再起動します。 もう一度試してください。インスタンス、ルーター、またはDNSレコードを作成してください。問題が何であるかをすぐに理解できるとは限らないためです。 再試行はサービスの低下を遅らせる可能性があり、この時点で落ち着いて神経を使わずに問題を解決できます。
上記のすべてのヒントは、Terraform、Puppet、その他すべてで実際にうまく機能します。
すべてにその場所があります
大規模なサービス(OpenStackも例外ではありません)は、お互いの作業を妨げる可能性のある多くの小規模なサービスを組み合わせています。 以下に例を示します。
ネットワークエージェントNeutron-L2-agentは、OpenStackのネットワーク接続を担当します。 他のすべてのエージェントが部分的にコントローラー上にある場合、L2はその特異性により、どこにでも存在します。
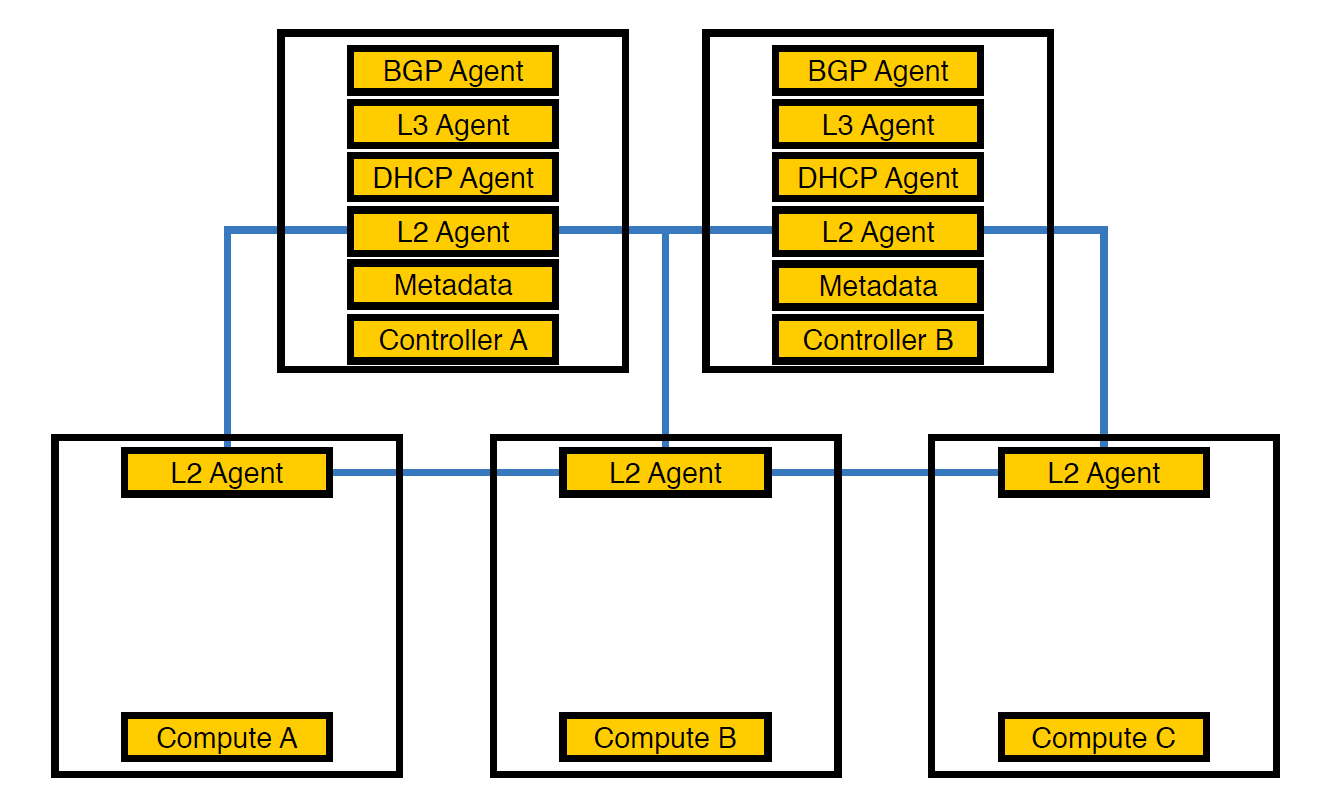
当初は、スキームの数が50を超えるまでインフラストラクチャのようでした。
この時点で、エージェントがこのように配置されているため、コントローラーが負荷に対処できないことに気付き、エージェントを計算ノードに転送しました。 これらはコントローラーよりも強力で、さらにコントローラーはすべての処理を処理する必要はありません。実行中のノードにタスクを与える必要があり、ノードはそれを実行します。

計算ノードへのエージェントの転送
ただし、このような配置は仮想マシンのパフォーマンスに悪影響を及ぼすため、これでは十分ではありませんでした。 物理あたり14個の仮想コアの密度で、1つのネットワークエージェントがストリームのロードを開始すると、複数の仮想マシンに一度に影響を与える可能性があります。
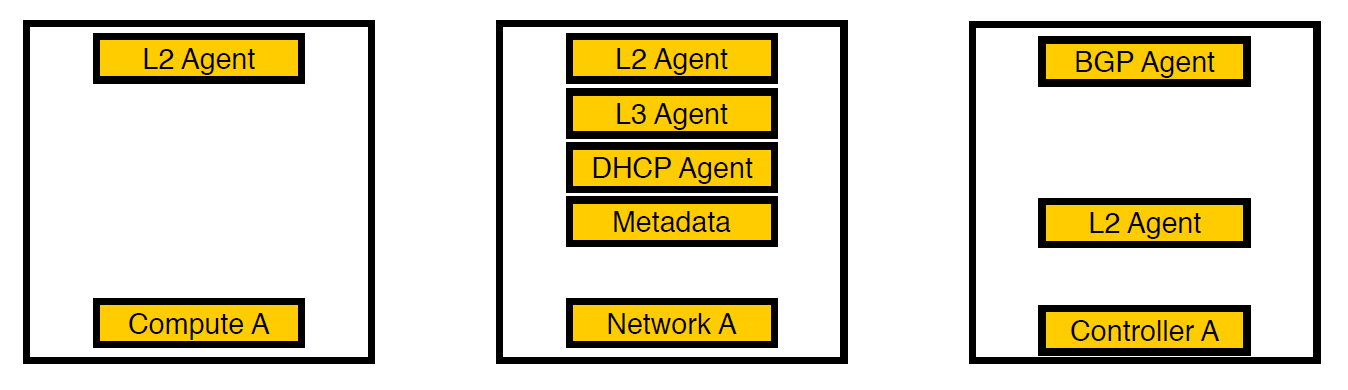
3回目の反復。 選択したノードが表示されました。
別のネットワークノードでエージェントを考えて実行しました。 現在、仮想マシンのサービスのみが計算ノードに残り、すべてのエージェントがネットワークノードで動作し、v6ネットワークを処理するbgpエージェントのみがコントローラーに残ります(1つのbgpエージェントは1種類のネットワークのみに対応できるため)。 L2はどこにも残りました。これがないと、上で書いたように、ネットワークに接続性がなくなるからです。
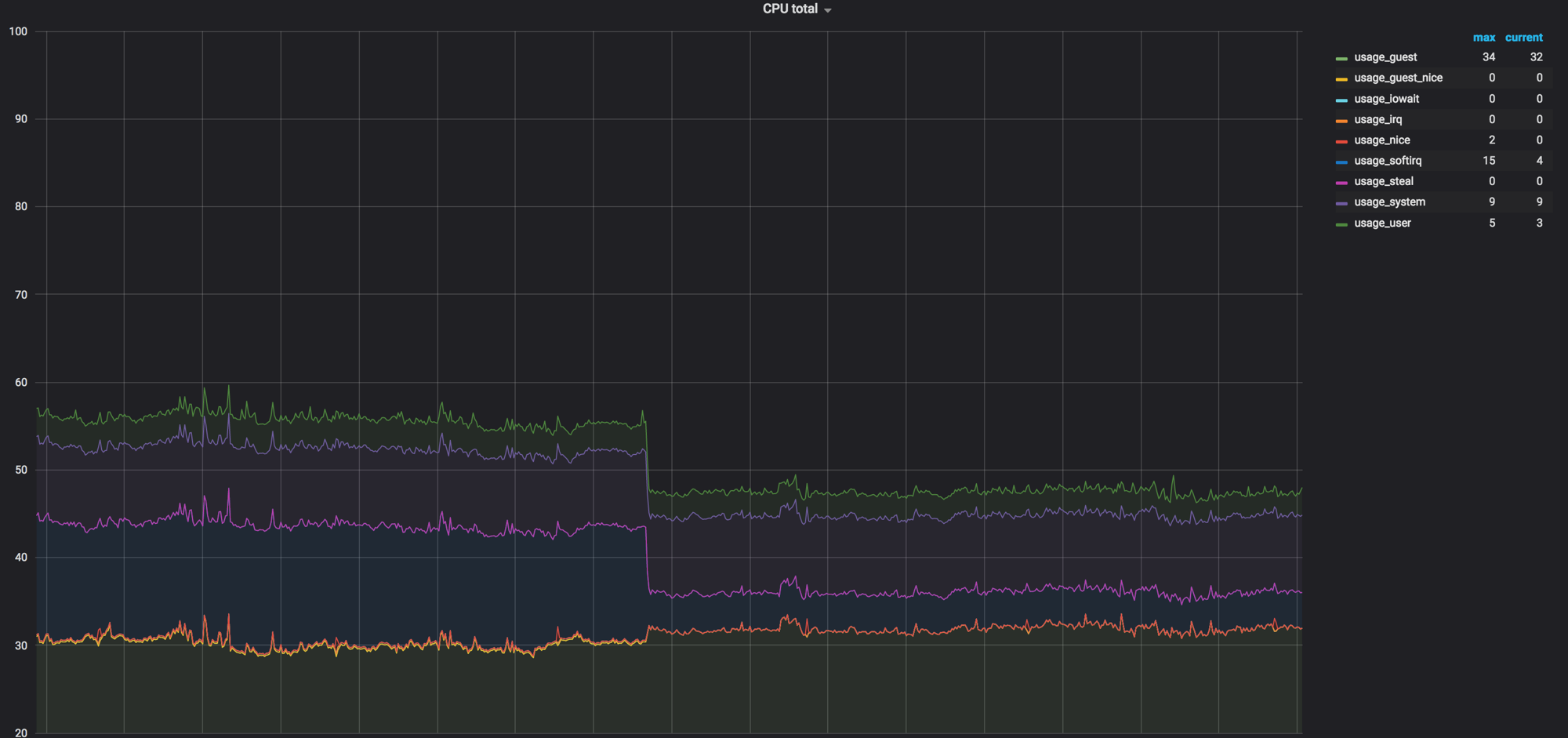
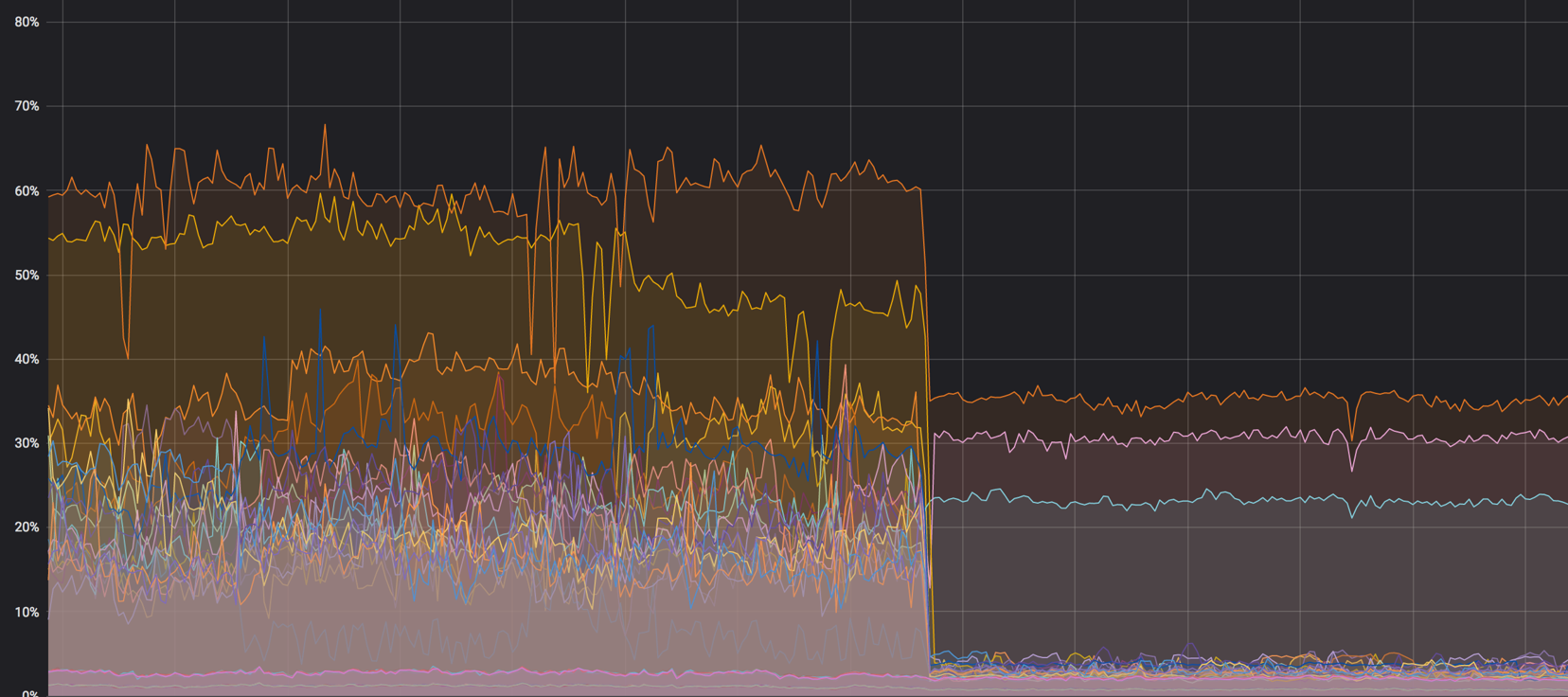
すべてが混合される前に、計算ノードのグラフをロードします。 約60%でしたが、負荷はわずかに低下しました

ネットワークエージェントが計算ノードを削除する前のsoftirqの負荷。 3つのコアがロードされたままです。 その時、私たちはそれが正常だと思った
ドキュメントとしてのコード
特にOpenStackのような大規模なサービスでは、コードがドキュメントであることがあります。 6か月のリリースサイクルでは、開発者は何かを文書化する時間を忘れるか、単に時間がないため、次の例のようになります。
タイムアウトについて
NeutronによるOpen vSwitchへの呼び出しが5秒以内に収まらず、タイムアウトになることがわかりました。
127.0.0.1:29696: no response to inactivity probe after 10 seconds, disconnecting neutron.agent.ovsdb.native.commands TimeoutException: Commands [DbSetCommand(table=Port, col_values=(('tag', 11),), record=qtoq69a81c6-e2)] exceeded timeout 5 seconds
もちろん、設定のどこかでこれが修正されると仮定しました。 config、ドキュメント、debパッケージを調べましたが、最初は何も見つかりませんでした。 その結果、検索結果の5ページ目に目的の設定の説明が見つかりました。コードをもう一度見て、正しい場所を見つけました。 設定は次のとおりです。
ovs_vsctl_timeout = 30
30秒(5秒)に設定すると、すべてが少し良くなり始めました。
もう1つ明らかなのは、ネットワークコンポーネントを再起動すると、一部のOpen vSwitch設定がリセットされる可能性があることです。 たとえば、これはovs-vsctl inactivity_probeで発生します。 これもタイムアウトですが、データベースへのovs-vsctlの呼び出しに影響します。 systemd initに追加し、起動時に必要なパラメーターですべてのスイッチを起動できるようにしました。
ovs-vsctl set Controller "br-int" inactivity_probe=30000
ネットワークスタック設定について
また、他のサーバーで使用しているネットワークスタックで一般に受け入れられている設定から少し離れる必要がありました。
ARPレコードをテーブルに保存するのにかかる時間のセットアップは次のとおりです。
net.ipv4.neigh.default.base_reachable_time = 60 net.ipv4.neigh.default.gc_stale_time=60
デフォルト値は1日です。 一般に、1つのスキームは数週間存続できますが、1日に4〜6回スキームを再作成できますが、MACアドレスとIPアドレスの対応は絶えず変化しています。 ゴミが蓄積しないように、時間を1分に設定します。
net.ipv4.conf.default.arp_notify = 1 net.nf_conntrack_max = 1000000 (default 262144) net.netfilter.nf_conntrack_max = 1000000 (default 262144)
さらに、ネットワークインターフェイスを上げるときに、ARP通知を強制的に送信しました。 また、conntrackテーブルを増やしました。これは、NATとフローティングIPを使用するときにデフォルト値がなかったためです。 100万に増加(デフォルトは262 144)して、すべてがさらに良くなりました。
Open vSwitch自体のMACテーブルのサイズを修正します。
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048)

すべての設定後、負荷の40%がほぼゼロになりました
rx-flow-hash
プロセッサのすべてのキューとスレッド間でudpトラフィックの処理を分散させるために、rx-flow-hashを含めました。 Intelネットワークカード、つまりi40eドライバーでは、このオプションはデフォルトで無効になっています。 インフラストラクチャには72コアのハイパーバイザーがあり、1つだけがビジーの場合、これはあまり最適ではありません。
これは次のように行われます。
ethtool -N eno50 rx-flow-hash udp4 sdfn

重要な結論:すべてをすべて設定できます。 デフォルトの構成は、ある時点で適合します(私たちがしたように)が、タイムアウトの問題により、検索が必要になりました。 これは正常です。
安全ルール
セキュリティサービスの要件によると、社内のすべてのプロジェクトには個人的なルールとグローバルルールがあります-それらのかなりの数があります。 300台の仮想マシンから1つのハイパーバイザーに海外に移動すると、これらすべてがiptablesの8万のルールに流れ込みました。 iptables自体については、これは問題ではありませんが、NeutronはRabbitMQからこれらのルールを1つのスレッドにロードします(Pythonで記述されており、マルチスレッドではすべてが悲しいため)。 Neutronエージェントはフリーズし、RabbitMQとの接続とタイムアウトによる連鎖反応を失い、回復後、Neutronはすべてのルールを再要求し、同期を開始し、すべてが最初からやり直します。
これに伴い、スタンドの作成時間が20〜40分からせいぜい1時間に増加しました。
最初は、すべてを取得でラップしました(この段階で、問題をそれほど迅速に解決できないことを既に認識していました)。その後、 FWaaSの使用を開始しました 。 これにより、計算ノードからセキュリティルールを取り出して、ルーター自体が配置されている別のネットワークノードに移行しました。

したがって、プロジェクト内では必要なものすべてに完全にアクセスでき、外部接続にはセキュリティルールが適用されます。 そこで、Neutronの負荷を減らし、テスト環境を作成する20〜30分に戻りました。
まとめ
OpenStackは、鉄をリサイクルし、内部クラウドを作成し、それに基づいて何かを作成できるクールなものです。 これに加えて、Telegramには大規模なコミュニティとアクティブなグループがあり 、そこでタイムアウトに関するプロンプトが表示されました。
それだけです 私の同僚に質問して、私たちの経験に答え、共有する準備ができています。