パートI. Rによる抽出と描画
もちろん、PostgreSQLは最初からユニバーサルDBMSとして作成されたものであり、専用のOLAPシステムとして作成されたものではありません。 しかし、Postgresの大きな利点の1つは、プログラミング言語をサポートしていることです。これを使用して、何でも作成できます。 組み込みの手続き言語が豊富にあることを考えると、それは単に同等のものではありません。 PL / R-Rのサーバー実装-アナリストのお気に入りの言語-その1つ。 しかし、それについては後で。
Rは独特のデータ型を持つ驚くべき言語です-たとえば、
list
には、異なる型のデータだけでなく、関数も含めることができます(一般的に、言語は折lect的であり、気を散らす議論を引き起こさないように、特定の家族に属することについては話しません)。 RDBMSテーブルを模倣するかなりの
data.frame
データ型があります。これは、列レベルで共通するさまざまなデータ型が列に含まれるマトリックスです。 したがって、(および他の理由で)Rでデータベースを操作することは非常に便利です。
RStudioのコマンドラインで作業し、 ODBC RpostgreSQLドライバーを介してPostgreSQLに接続します。 インストールは簡単です。
Rは統計に従事している人のためのS言語の一種として作成されたため、単純なグラフィックと単純な統計の例を示します。 言語を導入するという目標はありませんが、 RとPostgreSQLの相互作用を示す目標があります 。
PostgreSQLに保存されたデータを処理するには、3つの方法があります。
まず、任意の便利な方法でデータベースからデータを汲み上げ、例えばJSONでパックします-Rはそれを理解します-Rでさらに処理します。これは通常、最も効率的な方法ではなく、確かに最も興味深いものではありません。ここでは考慮しません。
第二に、ODBC環境とDBIドライバーを使用して、R環境からクライアントでデータベースと通信し、データベースからデータを読み取り、データをダンプします。Rでデータを処理します。これがどのように行われるかを示します。
そして最後に、PL / Rを統合された手続き言語として使用して、データベースサーバー上にあるRを使用して処理を実行することができます。 Rには、たとえば
pl/pgsql
ないデータを集約する便利な手段があるため、これは多くの場合に意味があります。 これも表示します。
一般的なアプローチは、プロジェクトのさまざまなフェーズで2番目と3番目のオプションを使用することです。最初にコードを外部プログラムとしてデバッグし、次にデータベース内で移動します。
始めましょう。 Rインタプリタ言語。 したがって、手順に従うか、コードをスクリプトにダンプできます。 好みの問題:この記事の例は短いです。
最初に、もちろん、適切なドライバーを接続する必要があります。
# install.packages("RPostgreSQL") require("RPostgreSQL") drv <- dbDriver("PostgreSQL")
あなたが見ることができるように、割り当て操作はRで独特です。 一般に、R a <-bではb-> aと同じ意味ですが、最初の記述方法がより一般的です。
Postgres Professional トレーニング資料で使用される航空輸送のデモベースである完成したデータベースを使用します 。 このページで 、データベースオプションを選択(つまり、サイズ)して説明を読むことができます。 便宜上、データスキームを再現します。
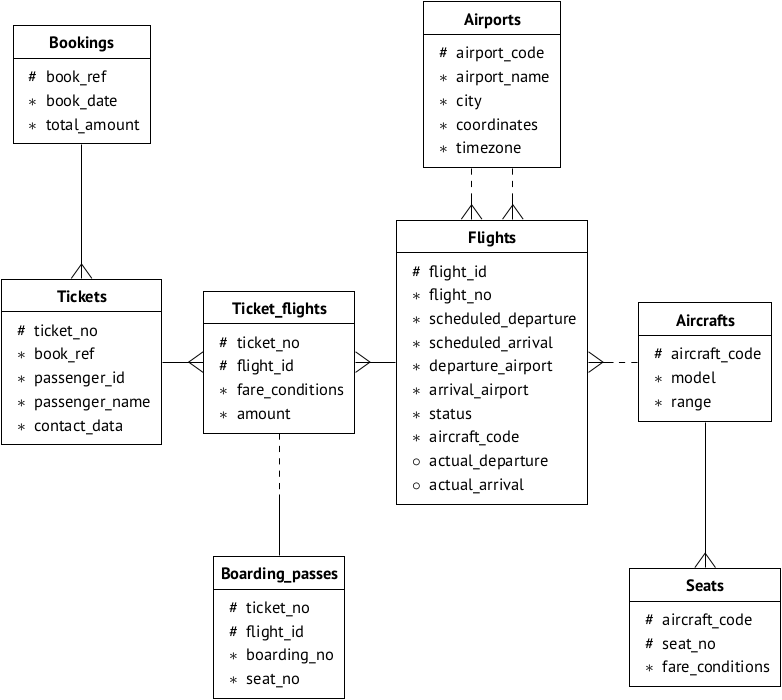
ベースがサーバー192.168.1.100にインストールされ、
demo
と呼ばれると仮定します。 接続する:
con <- dbConnect(drv, dbname = "demo", host = "192.168.1.100", port = 5434, user = "u_r")
続けます。 このようなクエリで、どの都市へのフライトが最も遅れているかを見てみましょう。
SELECT ap.city, avg(extract(EPOCH FROM f.actual_arrival) - extract(EPOCH FROM f.scheduled_arrival))/60.0 t FROM airports ap, flights f WHERE ap.airport_code = f.departure_airport AND f.scheduled_arrival < f.actual_arrival AND f.departure_airport = ap.airport_code GROUP BY ap.city ORDER BY t DESC LIMIT 10;
分を遅らせるために、postgres
extract(EPOCH FROM ...)
コンストラクトを使用して、
timestamp
フィールドから「絶対」秒を抽出し、60ではなく60.0で除算して、整数として理解される除算時の残りの破棄を回避しました。 1時間以上の遅延があるため、
EXTRACT MINUTE
は使用できません。 遅延を
avg
演算子で
avg
ます。
テキストを変数に渡し、リクエストをサーバーに送信します。
sql1 <- "SELECT ... ;" res1 <- dbGetQuery(con, sql1)
次に、リクエストがどのような形式で送信されたかを確認します。 これを行うために、R言語には
class()
関数があります
class (res1)
結果が
data.frame
タイプにパックされたことを示します。つまり、ベーステーブルの類似物を思い出します。実際には、任意のタイプの列を持つマトリックスです。 ちなみに、彼女は列の名前を知っており、列がある場合は、たとえば次のようにアクセスできます。
print (res1$city)
結果を視覚化する方法を考えましょう。 これを行うには、私たちが持っているものを見ることができます。 たとえば、 このリストから適切なスケジュールを選択します。
- Rバーチャート(棒)
- R-Boxplots(ストック)
- Rヒストグラム
- R線グラフ(グラフ)
- R散布図(ポイント)
入力の種類ごとに、画像に適したデータ型が提供されることに注意してください。 棒グラフ(横棒)を選択します。 軸方向の値には2つのベクトルが必要です。 Rのタイプ「ベクトル」は、同じタイプの値のセットです。
c()
はベクトルコンストラクターです。
次のように、
data.frame
タイプの結果から必要な2つのベクトルを生成できます。
Time <- res1[,c('t')] City <- res1[,c('city')] class (Time) class (City)
右側の表現は奇妙に見えますが、便利なテクニックです。 さらに、Rではさまざまな式を非常にコンパクトに記述できます。 コンマの前の角括弧内、コンマの後のシリーズのインデックス-列のインデックス。 コンマには何の価値もないという事実は、すべての値が対応する列から選択されることだけを意味します。
Timeクラスは
numeric
で、Cityクラスは
character
です。 これらはさまざまなベクトルです。
これで、視覚化自体を行うことができます。 画像ファイルを指定する必要があります。
png(file = "/home/igor_le/R/pics/bars_horiz.png")
その後、退屈な手順が続きます。チャートのパラメーター(
par
)を設定します。 また、Rグラフィックパッケージのすべてが直感的であったとは限りません。 たとえば、
las
パラメーターは、軸自体に相対的な軸に沿った値を持つラベルの位置を決定します。
- 0およびデフォルトで軸に平行。
- 1-常に水平。
- 2-軸に垂直;
- 3-常に直立
すべてのパラメーターをペイントするわけではありません。 一般的に、フィールド、スケール、色-を探して、あなたのレジャーで実験してください。
par(las=1) par(mai=c(1,2,1,1))
最後に、リカンベント列のグラフを作成します。
barplot(Time, names.arg=City, horiz=TRUE, xlab=" ()", col="green", main=" ", border="red", cex.names=0.9)
それだけではありません。 最後にもう1つ言わなければなりません。
dev.off()

変更のために、まだ遅延のドットダイアグラムを描画します。 リクエストからLIMITを削除します。残りは同じです。 ただし、散布図には2つではなく1つのベクトルが必要です。
Dots <- res2[,c('t')] png(file = "/home/igor_le/R/scripts/scatter.png") plot(input5, xlab="",ylab="",main=" ") dev.off()
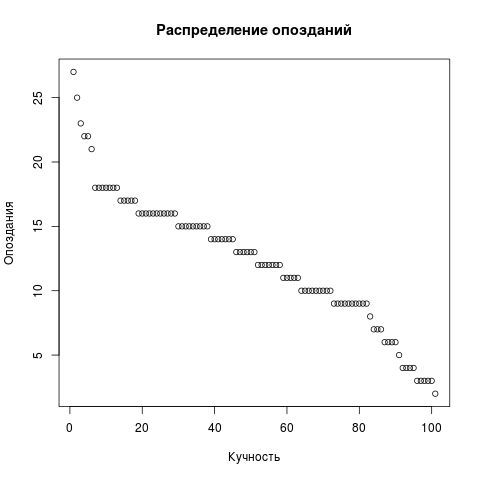
視覚化のために、標準パッケージを使用しました。 Rが一般的な言語であり、パッケージが無限に存在することは明らかです。 次のようにして、既にインストールされているものについて尋ねることができます。
library()
パートII Rは退職者を生成します
Rは、データ分析だけでなく、その生成にも使用すると便利です。 豊富な統計関数がある場合、ランダムシーケンスを作成するためのさまざまなアルゴリズムは存在できません。 特に、データベースクエリをシミュレートするために、典型的な(ガウス)分布とあまり典型的ではない(Zipf)分布を使用できます。
しかし、それについては次のパートで詳しく説明します。