
この夏、ニューラルネットワークに、画像上にドキュメントが存在するかどうか、存在する場合はどのドキュメントかを判断するように教えました。
なぜ必要なのか
従業員を降ろし、詐欺師から人々を保護するため。 新しいニューラルネットワークは2つの領域で使用します。ユーザーがページへのアクセスを取り戻したときと、一般的な検索から個人のドキュメントを非表示にするときです。
ページへのアクセスを復元します。 ドキュメントの写真は、アカウントを本当の所有者に戻すのに役立ちます。 たとえば、ユーザーが電話番号へのアクセスを失ったか、ページで2段階認証が有効になっている可能性があり、入場を確認するための1回限りのコードを受け取る機会はありません。 新しい開発により、アプリケーションの検討が迅速化されます。モデレーターは、毎回間違って記入されたアプリケーションを返す必要がなくなりました。 システムは、訪問者が必要な画像なしでフォームを送信することを単に許可せず、ランダムな画像をドキュメントに置き換えるように要求します。 もちろん、所有者の実際の写真がある場合にのみ、ページ自体へのアクセスを返すことができます。 私たちはアカウントのセキュリティと個人データの保存について話している-つまり、失敗や事故は絶対にあり得ないということです。
「 ドキュメント 」セクションでの検索結果のフィルタリング。 ユーザーがこのセクションにアップロードしたり、プライベートメッセージを介して送信したドキュメントはすべて、デフォルトではeyes索好きな目から隠され、検索結果には含まれません。 ただし、プライバシーレベルは、個々のファイルごとに手動で設定できます。 ニューラルネットワークが登場する前は、機密データを含むかなりの量のドキュメントがキーワードで見つかりました。 これらのファイルの所有者自身がプライバシー設定を変更しました。 ユーザーを保護し、ドキュメントの存在を判断できる公開検索から写真を削除し始めました 。
問題の解決方法
画像内のドキュメントを識別する最も簡単な方法は、ニューラルネットワークをセットアップするか、大規模なサンプルでゼロからトレーニングすることです。 しかし、それほど単純ではありません。
サンプルは代表的なものでなければなりません。 各オプションに対して十分な数の実際のサンプルを見つけることは困難です。これらのドキュメントがパブリックドメインにあるパブリックデータベースはありません。
ドキュメントを認識して解析するシステムは数多くあります。 通常、写真から特定の情報を取得することを目的としており、元の画像の理想的な品質を提案します。 たとえば、State Servicesポータルで機能するため、ユーザーはテンプレートの端に沿ってパスポートを揃える必要がある場合があります。
このようなシステムは、当社のタスクには適していません。 アクセス復旧のために当社に連絡する場合、ユーザーは写真、名、姓、印刷物を除くドキュメント上のすべてのデータを閉じることができることを別途指定します。 同時に、ドキュメントを決定する必要があります-シリーズと番号が隠されている場合でも、パスポートが周囲で撮影されている場合、または逆に、写真付きのドキュメントの一部のみが画像に表示されている場合でも。 また、異なる照明と角度を考慮する必要があります。 ニューラルネットワークは、そのようなすべての材料を受け入れなければなりません。 問題は彼女にこれを教える方法です。

他にも困難があります。 たとえば、パスポートを他の種類のドキュメントや、さまざまな手書きおよび印刷された紙から分離することは困難です。
簡単な方法で行こうとしても、あまり成功しませんでした。 結果の分類器は弱いことが判明し、第1種の小さなエラーと第2種の大きなエラーが発生しました。 たとえば、人が名前と姓を手で書いて、写真、パスポートの表紙を描いた-そして、システムがそのような文書をさりげなく受け入れた興味深いケースがありました。
何に来たの
私たちの状況では、問題に対する最善の解決策は、グリッドと顔検出器のアンサンブルを使用してドキュメントを認識し、そのタイプを決定することでした。 また、特徴的な機能を強調表示するエンコーダーや、ドキュメント画像と無関係なファイルを区別できるフォーム分類器を含む差分分類器も追加しました。 これに加えて、データセットの正規化を目的としたトレーニングセットの予備クラスタリングが行われます。 アーキテクチャの中で、 VGGとResNetが最も優れていることが証明されてい ます 。
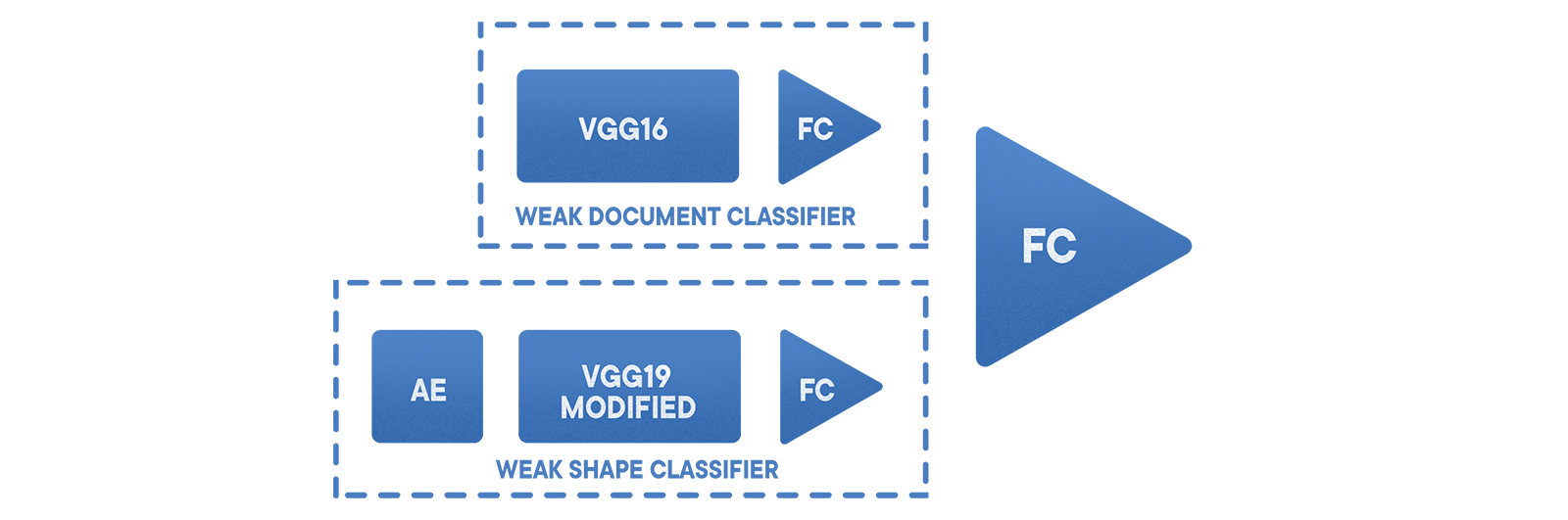
基本的な「ドキュメント/非ドキュメント」分類子は、19のレイヤーとゾーン化されたサンプルを持つカスタマイズされたVGGに基づいて機能します。 その上で、分類器の組み合わせアンサンブルが使用されます。これにより、第2種のエラーが減少し、結果が区別されます。 最初に層化サンプリングが行われ 、次にループに近い情報を抽出するエンコーダー、修正されたVGG、最後に単一のグリッドがあります。 このアプローチにより、第1種のエラーを約0.002のレベルに最小化することができました。 この場合の偽陰性の確率は、選択したデータセットと特定のアプリケーションによって異なります。
写真に写っているパスポートと運転免許証の存在を自動的に検出する方法を学びました。 照明条件が悪い場合でも、どんな角度でも、どんな背景でも認識に成功します。主なことは、画像に写真と名前の付いたドキュメントの一部があることです。 ただし、他の種類のドキュメントを識別するには、適切なデータセットのみが必要です。 独自のデータでネットワークをトレーニングします。ドキュメントのサンプルサイズは5〜10,000です(ただし、代表的なものではありません)。 他の画像の場合、サンプルは任意ですが、あちこちにアプリオリクラスタリングがあります。
技術的な観点から、システムはpython / keras / tensorflow / glib / opencvで記述されています。 新しいシステムを実際に適用するには、機械学習インフラストラクチャのPythonハンドラーに統合するだけで十分です。 同じ段階で、グラフィックエディターに写真変更検出器が追加されますが、このトピックは別の記事に値します。
結果は何ですか
現在、アクセスの復元のためのアプリケーションの6%は、ドキュメントの写真を追加または置換する要求とともに自動的に作成者に返され、2.5%のアプリケーションは拒否されます。 ヒューリスティックや写真内の顔検索など、画像全体の分析を見ると、部門の作業の最大20%が自動化されます。
ニューラルネットワークの開始後、「ドキュメント」セクションにアップロードされるパスポートの数を計算することもできました。 一般的な検索結果では、毎日約2,000枚の身分証明書がありました。 現在、それらが外部の手に落ちる可能性は最小限です。
ニューラルネットワークはすでに、スパムやあらゆる種類の詐欺との闘いを支援しています。 私たちは実験をやめず、ブログで実験について話し続けています。