今日は、姿勢推定の問題を解決する方法の1つについて説明します。 課題は、写真で身体の部分を検出することであり、その方法はDeepPoseと呼ばれます 。 このアルゴリズムは、2014年にGoogleから提案されました。 それほど昔ではないように思えますが、ディープラーニングの分野ではそうではありません。 それ以来、多くの新しい、より高度なソリューションが登場しましたが、完全に理解するには起源に精通する必要があります。

タスクの概要
最初に、問題のステートメントについて簡単に説明しましょう。 人がいる(1つまたは複数の)写真があり、これらの写真に身体の部分をマークしたい場合。 つまり、腕、脚、頭などはどこにありますか。
そのようなマークアップはどこで便利になりますか? 最初に頭に浮かぶのは、ビデオゲームです。 マウスでクリックするのではなく、仮想の剣を振り回してお気に入りのRPGをプレイできます。 これを行うには、手の動きのみを認識できれば十分です。
もちろん、はるかに実用的なアプリケーションがあります。 たとえば、店舗の買い物客がどのように商品をカートに入れ、時には棚に戻すかを追跡します。 その後、訪問者が購入したものを自動的に追跡でき、キャッシュデスクの必要性がなくなります。 AmazonはすでにAmazonGoストアでこのアイデアを実装しています。
与えられた使用例はすでに問題の解決に取り組むのに十分興味深いと思います。 ただし、これらの概念をどこに適用できるかについて独自のアイデアがある場合は、コメントに自由に記述してください。
クラシックレビュー
ニューラルネットワークなしでこの問題を解決する方法は? 人間の骨格はグラフの形で想像できます。頂点は関節であり、form骨は骨です。 そして、画像内の特定の場所に特定の関節が現れる可能性を記述し、これらの関節が互いにどの程度現実的であるかを考慮に入れる、ある種の数学的モデルを考え出します。 たとえば、左のかかとが右の肩にないようにします。 しかし、私はこれができる人がいる可能性を排除しません。
1つのオプションは、そのようなマットです。 モデルは、1973年に絵画構造モデルのフレームワークで実装されています。
しかし、あなたは問題の解決にそれほどunningな方法でアプローチすることはできません。 彼らが私たちに新しい画像を提供したら、マークアップされた画像の最初のセットで同様の画像を検索し、そのマークアップを表示しましょう。 最初はあまり多くの人の異なるポーズを持たない場合、この方法はうまくいきそうにありませんが、それを実装することは難しくありません。 類似の画像を検索するために、彼らは通常、画像処理領域から特徴を抽出するための古典的な方法を使用します: HOG 、 フーリエ記述子 、 SIFTなど。
他の古典的なアプローチもありますが、ここではそれらにこだわるのではなく、記事の主要部分に進みます。
新しいアプローチ
一般的な考え方
ご想像のとおり、記事DeepPose(Alexander Toshev、Christian Szegedy)の著者は、ディープニューラルネットワークを使用したソリューションを提案しました。 彼らは、このタスクを回帰タスクと見なすことにしました。 つまり、写真の各ジョイントについて、その座標を決定する必要があります。
データの前処理
次に、より正式な言語でモデルを説明し続けます。 ただし、このためには表記法を導入する必要があります。 便宜上、著者の表記法に従います。
入力画像を 、そしてポーズベクトルは どこで 座標が含まれています 関節の。 つまり、人間の骨格をグラフとして表します ピーク。 マークされた画像は次のように表示されます どこで -トレーニングデータセット。
写真にはさまざまなサイズがあり、写真の人物はさまざまな縮尺で表現され、フレームのさまざまな部分に配置されるため、画像の目的の領域(人体全体または対象物)を強調する境界ボックス( AABB )体の特定の部分に興味がある場合は、より詳細なもの)。 そのような領域の中心に関しては、内部ポイントの正規化された座標も考慮することができます。 最も些細なケースでは、領域はソース画像全体である場合があります。
ポイントを中心とする境界ボックスを示します 幅 そして背が高い 3つの数字 。
次に、正規化されたポーズベクトル エリアに関して このように書くことができます
つまり、すべての座標から目的の領域の中心を差し引いてから、分割します -長方形の幅の座標、および -高さに調整します。 ここで、すべての座標は、 前に 包括的に。
最後に 元の画像のトリミングを示す 境界領域 。 元の画像と等しい自明なボックスは、 。
今関数を取る場合 ( -入力画像 -モデルパラメータ、 -定義されたジョイントの数)、 正規化されたポーズベクトルを生成してから、元の座標のポーズベクトル 。
機能として 重みが記述されたニューラルネットワークがあります 。 つまり、固定サイズの3チャンネル画像を入力に送信し、出力を取得します ジョイント座標ペア:
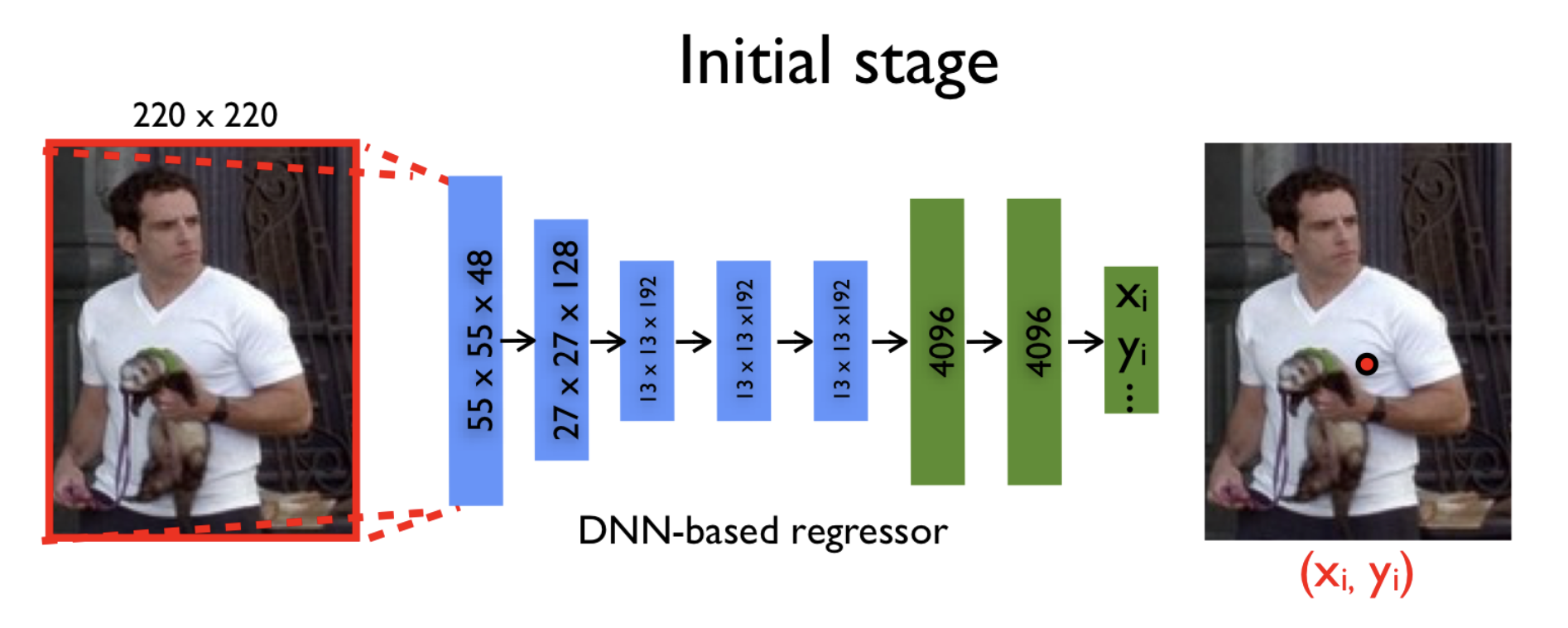
すでにこの段階で、いくつかのディープニューラルネットワーク(たとえば、2012年にImageNetの競争に勝った画像分類の問題で完全に現れたAlexNet)を使用して、その回帰を訓練できるようです。 真の座標からの予測座標の偏差の平方和を最小化するために、このようなモデルパラメーターを見つけます。 それが理想的なパラメーターです 。 したがって、ジョイントの元の座標を互いに独立して復元しようとしています。
ネットワークのカスケード
ただし、ニューラルネットワークの入力は固定サイズの画像を撮影するため(つまり、 ピクセル)、画像が元々最高の解像度であった場合、情報の一部が失われます。 したがって、モデルには、画像の細部をすべて分析する機能はありません。 モデルはすべてを大規模に「認識」し、おおよそのポーズのみを復元しようとします。
入力のサイズを単純に増やすことは可能ですが、同時に、グリッド内の既にかなりの数のパラメーターを増やす必要があります。 AlexNetの従来のアーキテクチャには、6,000万を超えるパラメーターが含まれていることを思い出させてください。 この記事で説明されているモデルのバージョンは4,000万を超えています。
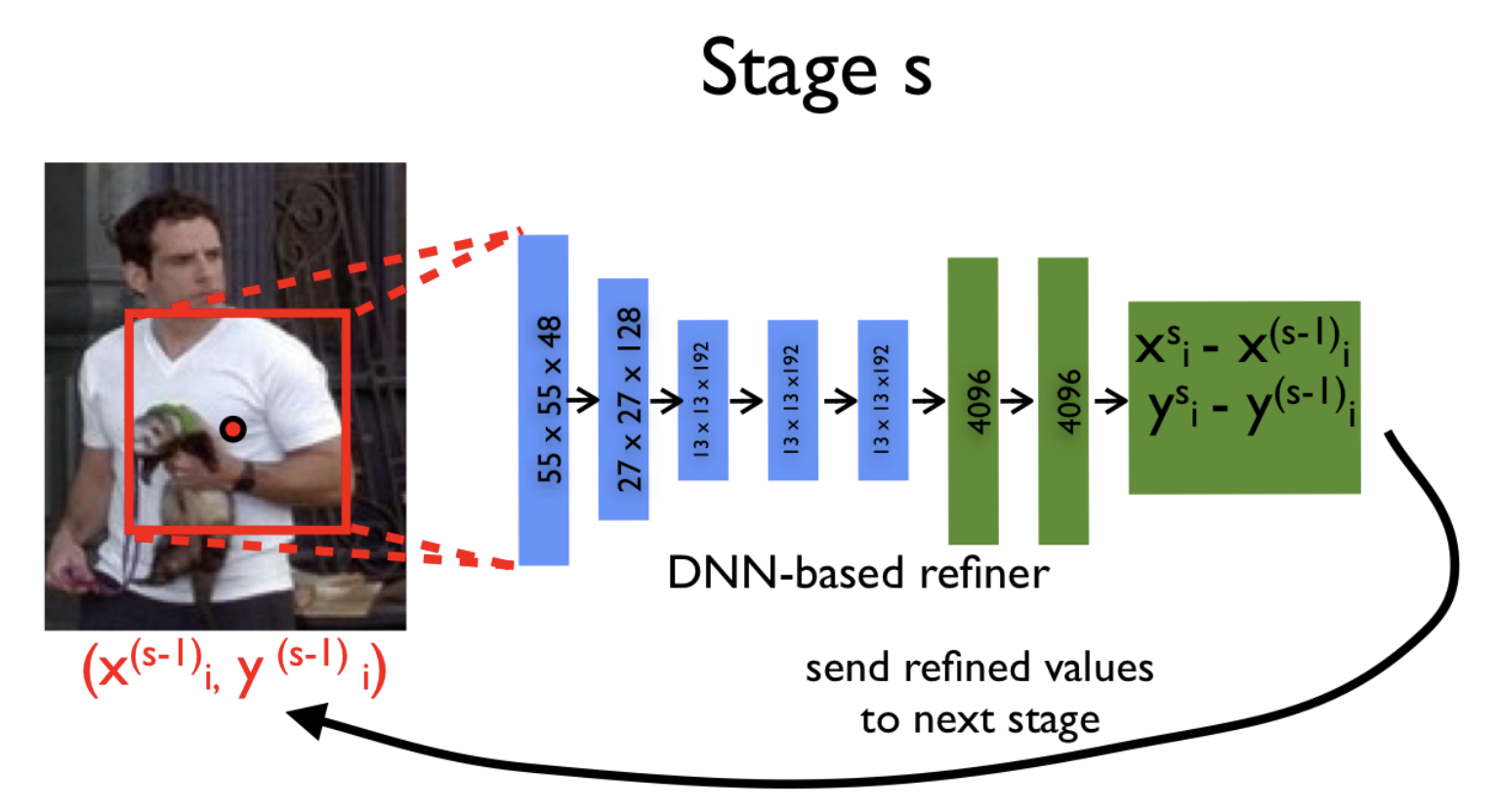
入力画像を適切な解像度で送信し、適切な数のパラメーターを維持する必要があるという妥協点は、ニューラルネットワークのカスケードの使用でした。 これはどういう意味ですか? まず、元の画像から、に圧縮 ピクセルの場合、関節のおおよその座標が予測され、後続の各ニューラルネットワークは新しい画像に従ってこれらの座標を調整します。 この新しい画像は、前の画像の必要な部分(前の段階からの予測の周りの非常に制限された領域)であり、サイズに縮小されています。 。
この方法のおかげで、各ステップのモデルのシーケンスは、より高い解像度の写真を観察します。これにより、モデルは詳細に焦点を当て、予測の品質を向上させることができます。
作成者は各ステージで同じネットワークアーキテクチャを使用します(合計ステージ )ただし、それらは個別に教えられます。 ステージでネットワークパラメータを設定しましょう のために 、および関節の座標を予測するモデル自体 。
初期段階( )境界領域を使用します (完全な元の画像)関節のおおよその座標を予測するには:
次に、新しい反復ごとに( )および各ジョイント 座標を指定します モデルを使用して :
データ生成
そしてすでに、そのようなモデルのトレーニングを始めることができました。 複雑なニューラルネットワーク、さらにはネットワークのカスケードを学習するには、多数のサンプル(この場合はラベル付き画像)が必要です。 たとえば、AlexNetは1500万のサイズの画像で構成されるImageNetでトレーニングされました。 。 しかし、そのようなデータセットでさえ、Alexと彼のチームは、ランダムな小さなサブ画像とその鏡像を選択することにより、2048倍以上に拡大されました。
検討中の問題で、データセットのサイズが小さくても深刻な問題にならないように、ネットワークのカスケードに適したデータを増強するための良い方法を考え出すことが重要でした。
しかし、ここで著者はかなりエレガントなソリューションを見つけました。 前の段階からのジョイント位置予測のみを使用する代わりに、彼らはこれらの座標を独自に生成することを提案しました。 これは、座標をシフトすることで実行できます 2次元正規分布から生成されたベクトル上のジョイント 観測された偏差の平均と分散に等しい平均と分散 から トレーニングサンプルのすべての例。
したがって、おそらく新しい写真で以前のレイヤーの作業をシミュレートします。 この方法の優れた機能は、上から生成できる画像の固定数に制限されないことです。 ただし、それらが多数ある場合、それらは互いに非常に似ているため、これは有用ではなくなります。
データセット
姿勢推定の問題には、研究者が科学研究でよく使用する2つの有名なオープンデータセットがあります。
シネマでラベル付けされたフレーム(FLIC)
このデータセットの名前はそれ自身を表しています。 さまざまな映画の5,000の注釈付きフレームを表します。 各画像について、10個の関節の座標を予測する必要があります。

リーズスポーツポーズデータセット(LSP)
このデータセットは、スポーツに関わる人々の写真で構成されています。 ただし、すべての写真に正しい写真があるわけではありません。
 |  |
ただし、これらは例外の可能性が高く、マークアップを使用した典型的な例は次のようになります。
 |  |  |
このデータセットにはすでに12,000個の画像が含まれています。 FLICとは異なり、ここでは10ではなく14ポイントの座標を予測する必要があります。
指標
最後に理解する必要があるのは、結果のマークアップの品質を評価する方法を理解することです。 この記事の著者は、仕事で一度に2つのメトリックを使用しました。
正しい部品の割合(PCP)
これは、正しく認識された身体部分の割合です。 体の一部とは、相互接続された一対の関節を意味します。 2つの関節の予測座標と実際の座標との距離がその長さの半分を超えない場合、身体の一部を正しく認識したと考えています。 その結果、同じエラーで、検出結果はジョイント間の距離に依存します。 しかし、この欠陥にもかかわらず、メトリックは非常に人気があります。
検出された関節の割合(PDJ)
最初のメトリックの欠点を補うために、著者は別のメトリックを使用することにしました。 正しく認識された身体部分の数を数える代わりに、正しく予測された関節の数を調べることにしました。 これにより、体の部分のサイズに依存することから私たちを救います。 予測された座標と実際の座標の間の距離が、画像内の身体のサイズに応じた値を超えない場合、関節は正しく認識されていると見なされます。
実験
上記のモデルは以下で構成されていることを思い出させてください ステージ。 ただし、この定数の選択方法はまだ指定していません。 このおよびその他のハイパーパラメーターに適切な値を選択するために、この記事では、検証サンプルとして両方のデータセットから50枚の画像を取得しました。 したがって、著者は3段階で停止しました( ) つまり、最初の画像から、ポーズの最初の近似値を取得してから、座標の調整を2回行います。
第2段階から開始して、実際の例から各ジョイントに対して40個の画像が生成されました。 たとえば、この方法では、LCPデータセット(14の異なるジョイントを予測する)に対して、鏡像を考慮して、 百万の例! また、FLICが元のバウンディングボックスであることに注意してください 人間検出アルゴリズムによって取得された境界矩形が使用されました。 これにより、画像の不要な部分を事前にカットすることができました。
カスケードの最初のニューラルネットワークは、約100台のマシンで3日間トレーニングされました。 しかし、最初の12時間ですでに最大に近い精度が達成されたと主張されています。 次の段階の各モデルは、元のモデルの40倍のデータセットで機能するため、7日間トレーニングされました。
結果
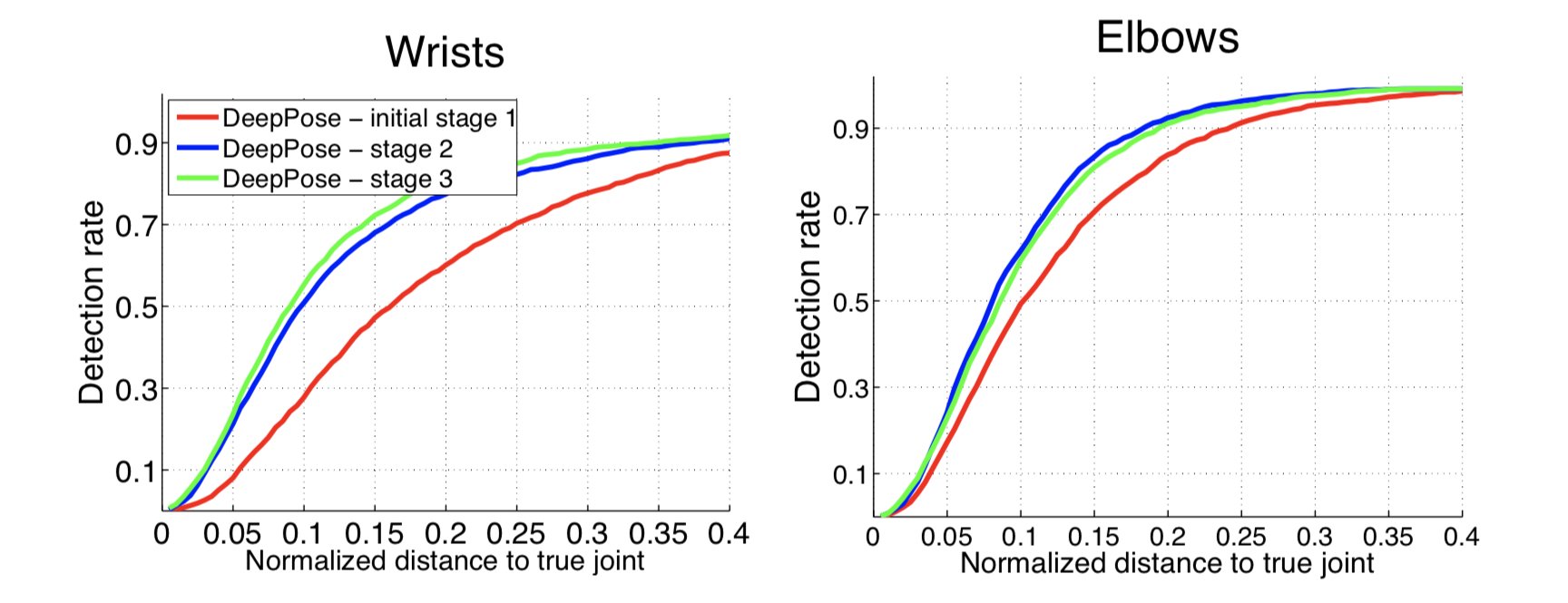
さらにグラフでは、モデルのさまざまな段階でのブラシと肘の認識の精度を確認できます。 軸に沿って -PDJメトリックのごみ箱の値(予測座標と現在の座標の差がごみ箱より小さい場合、ジョイントが正しく定義されていると考えられます)。 グラフから、追加の手順によって精度が大幅に向上することがわかります。
後続の各ニューラルネットワークがどのように座標を改良するかを見るのも興味深いです。 以下の画像では、実際のポーズは緑で描画され、モデルは赤で予測されています。

また、このモデルの結果を当時の他の5つの最新のアルゴリズムと比較します。

結論
私の意見では、この研究の興味深い点の1つは、同じアーキテクチャの複数のニューラルネットワークを連続して接続することにより、精度を向上させることをお勧めするモデルを構築する方法です。 トレーニングデータセットを拡張するための追加の例を生成する方法と同様。 限られたデータセットで作業するときは、常に2番目のものについて考える必要があると思います。 そして、あなたが知っている増強の方法が多ければ多いほど、あなたのために右に来るのは簡単です。
投稿はavgaydashenkoと共同で書かれました 。