
Googleは最近、ディープラーニングを加速するために特別に設計されたプロセッサであるTensor Processing Unit v2(TPUv2)をクラウドサービスのリストに追加しました。 これは、世界初の広く利用可能なディープラーニングアクセラレータの第2世代であり、Nvidia GPUの代替品であると主張しています。 最近、私たちは第一印象について話しました。 多くの人が、 Nvidia V100 GPUとのより詳細な比較を求めました。
ディープラーニングアクセラレータを客観的かつ有意義に比較することは簡単な作業ではありません。 しかし、このカテゴリの製品の将来の重要性と詳細な比較の欠如により、独立したテストを実施する必要性を感じました。 これには、潜在的に対立する当事者の意見を考慮に入れることが含まれます。 そのため、GoogleとNvidiaのエンジニアに連絡し、この記事のドラフトについてコメントするように招待しました。 バイアスがないことを保証するために、独立した専門家も招待しました。 このおかげで、私たちが知る限り、これまでのTPUv2とV100の最も完全な比較が判明しました。
実験セットアップ
以下は、4つのTPUv2(1つのクラウドTPUを形成)を4つのNvidia V100と比較しています。 両方とも64 GBの合計メモリがあるため、同じ量のトレーニングサンプルで同じモデルをトレーニングできます。 実験では、モデルを同じ方法でトレーニングします。CloudTPUの4つのTPUv2と4つのV100が同期並列分散学習のタスクを実行します。
モデルとして、画像を分類するための事実上の標準およびベンチマークであるImageNetでResNet-50を選択しました 。 参照ResNet-50実装は公開されていますが、Cloud TPUと複数のGPUの両方で同時にトレーニングをサポートするものはありません。
Nvidiaは、複数のV100用のNvidia GPUクラウドでDockerイメージとして利用可能なMXNetまたはTensorFlow実装を使用することを推奨します。 残念ながら、大量のトレーニングサンプルを使用して複数のGPUで作業する場合、両方の実装がデフォルト設定にあまりよく一致しないことが判明しました。 特に、学習率のスケジュールを変更する必要があります。
代わりに、TensorFlow ベンチマークリポジトリからResNet-50実装を取得し、Dockerイメージ(tensorflow / tensorflow:1.7.0-gpu、CUDA 9.0、CuDNN 7.1.2)として起動しました。 Nvidiaが推奨するTensorFlow実装よりも大幅に高速であり、MXNetよりもわずかに劣っています(約3%、以下を参照)。 しかし、それはうまく収束します。 さらに、フレームワークの同じバージョン(TensorFlow 1.7.0)での2つの実装を比較するという追加の利点があります。
Googleでは、Cloud TPUの公式TPUリポジトリからTensorFlow 1.7.0でbfloat16を使用することを推奨しています。 TPUとGPUの両方の実装は、対応するアーキテクチャで混合精度の計算を使用し、ほとんどのテンソルは半精度数で保存されます。
V100テストは、p3.8xlargeインスタンス(16コアXeon E5-2686@2.30GHz、メモリ244 GB、Ubuntu 16.04)で、 4つのV100 GPU (それぞれ16 GBのメモリ)を使用して実行されました。 TPUテストは、小さなインスタンスn1-standard-4(2つのXeon@2.3GHzコア、15 GBのメモリ、Debian 9)で実行され、 4つのTPUv2 (それぞれ16 GBのメモリ)からのCloud TPU(v2-8)が割り当てられました。
2つの異なる比較を行いました。 まず、合成データの帯域幅(1秒あたりの画像数)の観点から、増強なしで、つまり利用可能なデータから追加のトレーニングデータを作成せずにパフォーマンスを調査しました。 この比較は収束に依存せず、I / Oにボトルネックはなく、データの増強は結果に影響しません。 2番目の比較では、ImageNetの2つの実装の精度と収束性を調べました。
帯域幅テスト
合成データの 1秒あたりの画像数、つまり、さまざまなバッチサイズでのオンザフライトレーニング用のデータの作成によってスループットを測定しました。 TPUの場合、推奨されるサンプルサイズは1024のみですが、読者からの多数のリクエストにより、他の結果を報告していることに注意してください。

合成データおよび拡張なしのさまざまなサンプルサイズでのパフォーマンス(1秒あたりのイメージ)。 サンプルサイズはグローバルです。つまり、1024は各ステップでの各GPU / TPUチップ上の256のサイズを意味します
1024のトレーニングサンプルサイズでは、帯域幅に実質的な違いはありません! TPUはわずかに進んでおり、マージンは約2%です。 小規模なトレーニングサンプルでは、両方のプラットフォームで帯域幅が低下し、GPUの動作がわずかに向上します。 ただし、前述のように、このようなトレーニングサンプルサイズは現在TPUには推奨されていません。
Nvidiaの推奨に従って、 MXNetで GPUを使用した実験を実施しました 。 Nvidia GPU Cloudで利用可能なDockerイメージ( mxnet:18.03-py3 )でResNet-50実装を使用しました。 トレーニングサンプルサイズが768(1024は多すぎる)の場合、GPUは1秒間に約3280の画像を処理します。 これは、TPUの最良の結果よりも約3%高速です。 ただし、前述のように、MXNet実装はこのトレーニングサンプルサイズでは複数のGPUにあまりうまく収束しないため、ここではTensorFlow実装に焦点を当てます。
クラウドのコスト
Cloud TPU(4つのTPUv2チップ)は現在、Google Cloudでのみ利用可能です。 このような計算が必要な場合にのみ、VMインスタンスにオンデマンドで接続します。 V100については、AWSクラウドソリューションを確認しました(V100はまだGoogleクラウドで利用できません)。 上記の結果に基づいて、各プラットフォームおよびプロバイダーの1ドルあたりの1秒あたりの画像数を正規化できます。
パフォーマンス:1秒あたり1ドルあたりの画像
| クラウドTPU | 4×V100 | 4×V100 | |
|---|---|---|---|
| クラウド | Googleクラウド | AWS | AWSリザーブドインスタンス |
| 時間あたりの価格 | 6.7ドル | 12.2ドル | 8.4ドル |
| 1秒あたりの画像 | 3186 | 3128 | 3128 |
| パフォーマンス(1秒あたりのドルあたりのイメージ数) | 476 | 256 | 374 |
これらの価格で、Cloud TPUは明確な勝者です。 ただし、より長いレンタルまたは機器の購入を検討している場合、状況は異なって見える場合があります(ただし、このオプションは現在Cloud TPUでは使用できません)。 上記の表には、AWS上の予約済みインスタンスp3.8xlargeの12か月分のレンタル料金(前払いなし)も含まれています。 これにより、1ドルの生産性が374イメージ/秒に1ドル大幅に向上します。
GPUには他にも興味深いオプションがあります。 たとえば、 Cirrascaleでは、約7500ドル(1時間あたり約10.3ドル)で4台のV100を使用したサーバーレンタルを毎月提供しています。 ただし、この機器はAWSの機器(CPUタイプ、メモリ、NVLinkサポートなど)とは異なるため、直接比較するには追加のテストが必要です。
精度と収束
パフォーマンスレポートに加えて、計算が実際に「意味のある」ものであること、つまり実装が良い結果に収束することを確認したかったのです。 2つの異なる実装を比較したため、多少の逸脱が予想されます。 したがって、この比較は機器の速度だけでなく、実装の品質の指標でもあります。 たとえば、TPUの実装には非常にリソースを集中的に使用する前処理手順が含まれ、実際には帯域幅が犠牲になります。 Googleによると、これは予想される動作です。 以下で見るように、それは正当化されます。
ImageNetデータセットのモデルをトレーニングしました。タスクは、画像をハチドリ 、 ブリトー 、 ピザなどの1000のカテゴリのいずれかに分類することです。 データセットは、トレーニング用の130万画像(〜142 GB)と検証用の50,000画像(〜7 GB)で構成されています。
学習はサンプルサイズ1024で90を超える時代に行われ、その後、結果がコントロールデータと比較されます。 TPU実装は1秒間に約2796個の画像を処理し、GPU実装は1秒間に約2839個の画像を処理します。 これは、増強をオフにし、合成データを使用してTPUとGPUの正味速度を比較した以前の帯域幅の結果とは異なります。

90エポック後の2つの実装の上位1の精度(つまり、各画像について、最も信頼性の高い予測のみが考慮されます)
上記のように、TPUの実装の90エポック後のトップ1の精度は0.7 pp より良い。 これは取るに足らないように思えるかもしれませんが、この非常に高いレベルで改善を達成することは非常に困難です。 アプリケーションによっては、このような小さな改善が結果に大きく影響する場合があります。
モデルのトレーニング中に、さまざまな時代のトップ1の精度を見てみましょう。
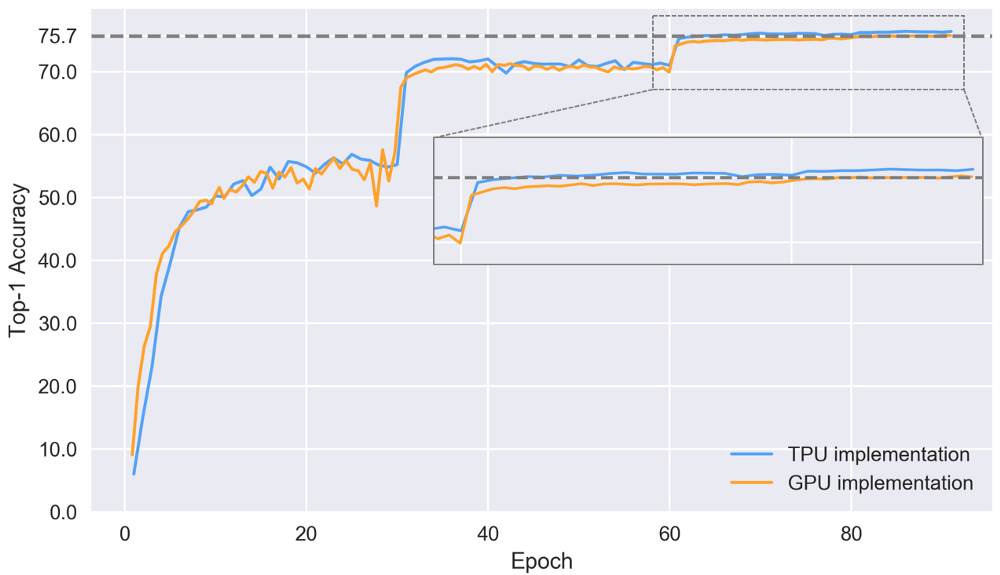
2つの実装のテストセットで上位1位の精度
上記のグラフの劇的な変化は、学習速度の変化と一致しています。 収束傾向は、TPUの実装の方が優れています。 ここでは、86の時代の後、最終的な精度は76.4%に達します。 GPUの実装は遅れており、84エポック後に75.7%の最終精度に達しますが、TPUでそのような精度を達成するには64エポックだけが必要です。 TPU収束の改善は、データの前処理と拡張の改善によるものと思われますが、この仮説を確認するにはより多くの実験が必要です。
費用対効果の高いクラウド価格設定ソリューション
最終的に、特定の精度を達成するために必要な時間とコストが重要になります。 75.7%(GPUを実装することで達成される最高の精度)のレベルでソリューションを採用する場合、必要な時代と1秒あたりの画像のトレーニング速度に基づいて、この精度を達成するためのコストを計算できます。 これにより、時代の間にモデルを評価する時間とトレーニングを開始する時間がなくなります。

75.7%のトップ1の精度を達成するための価格。 * 12か月間予約済み
上記のように、現在のCloud TPUの価格設定ポリシーでは、55ドルで9時間以内にImageNetでモデルをゼロから75.7%の精度でトレーニングできます! 76.4%の収束まで学習するには73ドルかかります。 V100は同様に高速で動作しますが、価格が高く、収束が遅いと、ソリューションコストが大幅に高くなります。
繰り返しますが、比較は実装の品質とクラウドの価格に依存することに注意してください。
エネルギー消費の違いを比較することは興味深いでしょう。 しかし、現在、TPUv2のエネルギー消費に関する公開情報はありません。
おわりに
ResNet-50の基本的なパフォーマンスについては、テストでは4つのTPUv2チップ(1つのCloud TPUモジュール)と4つのV100 GPUが同等に高速です(差は2%以内)。 おそらく将来のソフトウェア最適化(たとえば、TensorFlowまたはCUDA)により、パフォーマンスが向上し、比率が変化します。
ただし、実際には、ほとんどの場合、主なことは特定のタスクで特定の精度を達成するために必要な時間と費用です。 現在のクラウドTPUの価格設定と優れたResNet-50の実装は、ImageNetで時間とコストの印象的な結果をもたらし、約73ドルでモデルを76.4%の精度でトレーニングできます。
詳細な比較のために、他の分野のモデルと異なるネットワークアーキテクチャのベンチマークが必要です。 また、各ハードウェアプラットフォームを効果的に使用するために必要な労力を理解することも興味深いです。 たとえば、精度が混在する計算では、パフォーマンスが大幅に向上しますが、GPUとTPUでは異なる方法で実装されます。