今日は、ランタイムのパフォーマンスについてお話します。 単一ページのアプリケーションの場合、通常はネットワークパフォーマンスまたはランタイムパフォーマンスのいずれかです。
最初のケースでは、通常、ネットワーク経由で送信されるHTTPリクエストまたはデータの数を削減しようとします。 この方向には多くの研究があります。 たとえば、Google Closure Compilerチームはこれに取り組んでおり、未使用のコードとコードの縮小化をより効率的に削除するという目標を達成しています。 また、さまざまな圧縮アルゴリズムがあり、webpackチームも同様の目標を設定しています。 最後に、Angular CLIはさまざまなアプローチのベストを組み合わせて、非常によくカプセル化されたアセンブリを提供しようとします。
ただし、実行時のパフォーマンスに関しては、ほとんど開発されていません。 すべてが私たちの手に委ねられており、サードパーティの「魔法の杖」はありません。これにより、アプリケーションはより速く動作し始めます。 この問題にはいくつかの可能なアプローチがありますが、今日はより一般的なソリューションについて説明します。Angularだけでなく、多くの場合に適用できます。
これらの決定を説明するために、「シンプルなビジネスアプリケーション」を作成しました。 その中で、私は過去数ヶ月間と同じくらい多くのパフォーマンスの問題を再現しようとしました。 その結果、完全に不気味な製品が完成しました。これを何らかの方法で改善していきます。

私たちの最大限に簡素化されたアプリケーションでは、新しい従業員を追加し、リストにそれらを表示し、それらの値を計算できます。 従業員の2つのリストがあります。営業部門とR&D部門です。 両方に新しい要素を追加できます。 既存の要素がリストに表示され、名前と数値が表示されます(これが従業員の仕事の評価であると仮定します)。 新しい従業員の名前の入力フィールドもあります。 従業員を追加するときは、どこかから番号を取得し、何かを計算して、画面にすべてを表示できます。
アプリケーションの構造は、AppComponent(アプリケーション全体をカバー)と2つのEmployeeListComponent(リストごとに1つ)で構成されます。
EmployeeListComponentテンプレートは次のとおりです。

ここでは、入力要素に注意してください。 バナナボックス形式の構文(最初に角かっこ、次に丸かっこ)を使用して、EmployeeListComponentコントローラーで宣言されたラベルプロパティとテキストボックスの間に双方向のデータバインディングを確立します。
さらに、EmployeeListComponentはデータ配列内の従業員のリストを反復処理し、従業員ごとにリストアイテムが作成されます。 各要素について、従業員の名前を表示し、EmployeeListComponentクラスで定義されたcalculate()メソッドを使用して数値を計算します。
次に、このクラス自体を見てみましょう。

いくつかの重要なことがあります。 まず、状態はその中に保存されず、親コンポーネントからの入力に必要なすべてのデータ(EmployeeData []配列)を受け取ります。 したがって、この親コンポーネントであるAppComponentは、Reduxのコンテナコンポーネントとして機能します。
また、EmployeeListComponentクラスには、フィボナッチ数を計算する関数の実行を渡すことが唯一のタスクであるCalculate()メソッドがあります。 一見すると、フィボナッチ数はここで使用するには不便ですが、多くの重要な利点があります。 まず、誰もがそれらを計算する方法を知っているので、適切な関数の例の複雑な作業を説明する必要はありません。 標準偏差またはそのような何かに置き換えることができます。

第二に、この関数は、画面に表示されているように、非常に非効率的な方法で実装できます。 2つの再帰呼び出しがあり、フィボナッチ数ごとに、以前のすべてを再計算します。 したがって、ここでは、後続の最適化の効果がよりよく見えるように、アプリケーションを人為的に遅くしました。
そのため、アプリケーション自体のコンポーネントと、リストの2つのコンポーネントを持つアプリケーションがあります。 リストの各アイテムには多くの処理能力が必要です。
このアプリケーションで実際のデータを使用してみましょう。 合計140項目を含む2つのリストがあります。 この場合、新しい名前を入力するとき、入力は非常に遅くなります。 ユーザーがこのアプリケーションを好む可能性はほとんどありません。 しかし、なぜそんなに遅いのでしょうか? この問題のプロファイリングは、Chrome DevToolsを使用すれば簡単です。 これを行った後、フィボナッチ数を計算するための関数が非常に頻繁に呼び出されることがわかります。 この関数にロギングを追加することにより、呼び出しの正確な数を調べることができます。

ユーザーがキーを押すたびに、コンポーネントのツリー全体が少なくとも2回(押すとキーを離すと1回)再計算されます。 したがって、クリックごとに以前に取得したすべての値を再計算します。
これは、コンポーネントツリーの観点から見た状況です。 キーを押すたびに、最初にAppComponentで変更が発生します。 Angularの変更検出は深さ検索のように機能するため、EmployeeListComponentの変更検出もトリガーされ、次に各ワーカーアイテムの変更検出もトリガーされます。 これらの各要素について、数値が再計算されます。 次に、2番目のEmployeeListComponentの同じラウンドが発生します。
これはすべて非常に非効率的です。 原則として、配列内の各要素の数値を再カウントする必要はありません。これは、新しい配列が表示される場合にのみ必要です。 これで、新しい配列がAppComponentからEmployeeListComponentに転送される場合、計算できます。 これを最善にする方法についての考えはありますか?
たとえば、OnPush戦略を使用できます。 そのおかげで、コンポーネントの新しい入力が表示されたときにのみ変更検出が起動されます。 リンクをチェックするときにAngularが新しい入力の出現を検出すると、コンポーネントで変更検出が実行されます。 つまり、コンポーネントツリーがある場合、ルートコンポーネントが新しいデータを受け取ると、このコンポーネントからブランチ全体を更新します。 後でどのように見えるかを見ていきます。
ヘルプのために関数型プログラミングに目を向けて、EmployeeListComponentが関数であると想像してみましょう。 コンポーネントの入力データは関数の入力引数であり、画面上の画像は関数の結果です。 擬似コードを使用して私のアイデアを示します。

定数fで、定数データ-入力引数(1人の従業員のデータ)にEmployeeListComponent(現在は関数)へのリンクを保存します。
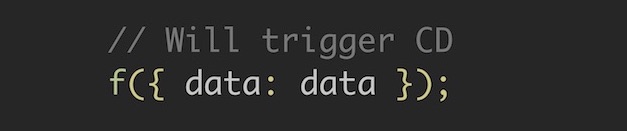
最初に、元の入力で関数を呼び出し、次にAngularが変更を検出します。 それまでは値が未定義で、データと未定義を比較していたため、Angularは入力データの値の変化を確認します。

ただし、リストに新しい要素を追加すると、以前と同じ引数を使用して関数が既に呼び出されます。同じデータ定数が指すデータ構造を変更します。 したがって、Angularは変更検出をトリガーしません。

ただし、関数の入力引数で配列のコピーを送信すると、変更の検出が発生します。リンクはそこで変更されます。
これは、変更を検出する必要があるたびに、アレイ全体をコピーする必要があるということですか? いくつかの理由により、これは非常に非効率的です。 第一に、メモリ使用量が極端に最適化されないことです。 変更を検出するたびに、最初に新しい配列全体にメモリを割り当てる必要があり、次にガベージコレクターがメモリを解放する必要があります。 第二に、計算の観点からは非効率的です。 このようなアルゴリズムの時間の複雑さは、少なくともO(n)です。
不変
これらの両方について、Immutable.jsのようなものを使用する方が賢明です。 これは、2つの非常に重要なプロパティを持つさまざまな不変データ構造のコレクションです。
まず、既存のデータ構造を変更することはできません。 代わりに、そのようなデータ構造を変更する必要がある呼び出しは、変更が既に適用された新しい参照を受け取ります。
第二に、データ構造全体をコピーするわけではありません。可能であれば、この構造の新しいインスタンスは古い要素を使用します。
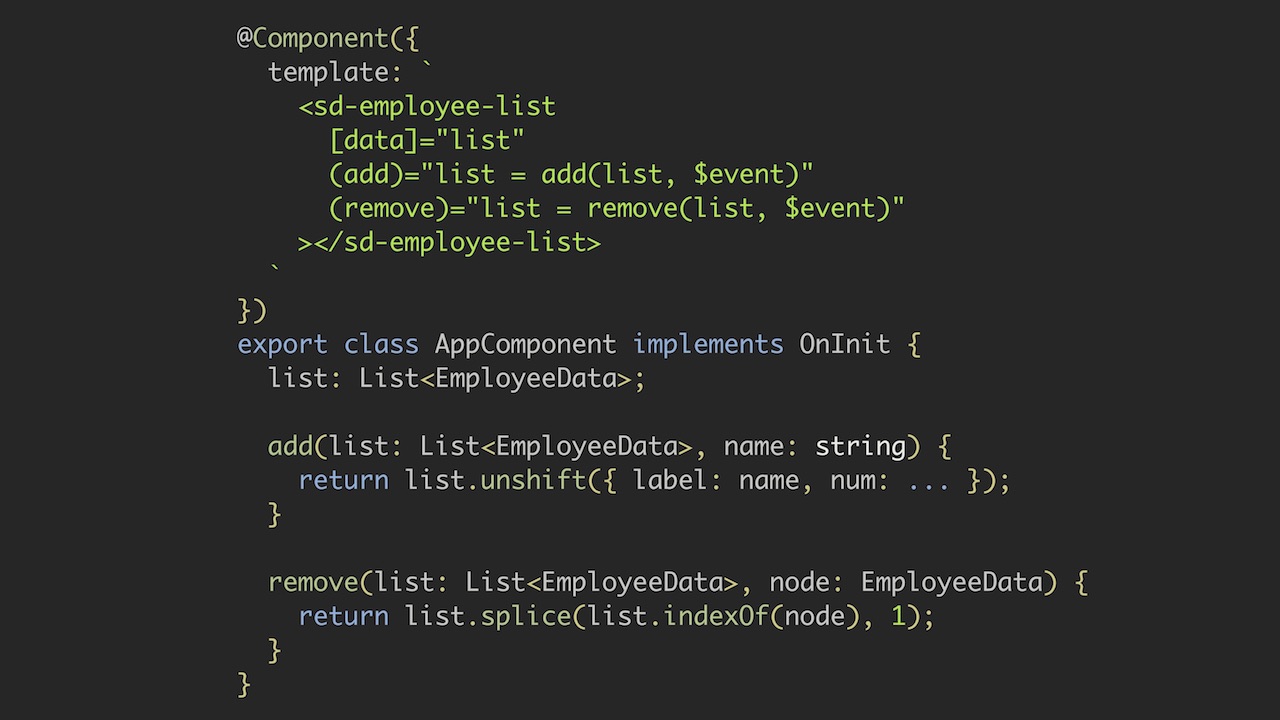
ここで、必要なリファクタリングを示します。 最初に、add()およびremove()メソッドの内容を変更しました。 add()で、要素をリストの先頭に移動するunshift()プロシージャを実行すると、新しいリストが取得されます。 remove()メソッドでも同じことが言え、splice()を呼び出すと新しいリストが返されます。
これらの2つの方法に加えて、リストへのリンクを変更する必要があります。 それ以外の場合、入力が変更されたことをEmployeeListComponentに通知できます。 したがって、add()およびremove()の出力値をAppComponentのリストプロパティに割り当てる必要があります。
アプリケーションを起動して、どれだけ速くなったかを確認してください。 ここで最適化しましたが、改善されているはずです...うーん、アプリケーションはまだ非常に遅いです。 以前よりも高速になった可能性がありますが、それでもユーザーの印象は良いとは言えません。
アプリケーションがどれだけ速く動作し始めたかを測定するために、いくつかのエンドツーエンドのテストを作成し、Angular Benchpressで実行しました。

彼らのおかげで、アプリケーションが作業を少なくとも2倍加速したことがわかります。 ただし、これでは十分ではありません。 不十分な作業の理由は、テキストを入力すると、変更検出が引き続きトリガーされるためです。 幸いなことに、2つのリストのいずれかでのみ実行されるようになりましたが、数値が変更されていないため、このリストでも必要ありません。
コンポーネントツリーの観点からアプリケーションがどのように見えるかを見てみましょう。 キーを押すたびに、AppComponent、EmployeeListComponent、および個々のコンポーネントの変更の検出を数回呼び出します。 ただし、2番目のリストへの呼び出しは行いません。 しかし、リストのデータ構造を変更した呼び出しのいずれも呼び出されなかったので、なぜ変更検出が一般的に発生するのでしょうか?
その理由は、特定のOnPush変更検出特性が十分に文書化されていないためです。

結論として、OnPushの変更検出は、入力データが変更されたときだけでなく、対応するコンポーネントでイベントがトリガーされたときにもトリガーされるということです。
この機能を知って、コードをリファクタリングできるようになりました。 これには、アプリケーションの責任の分割を改善し、コンポーネントツリーをよりスリムにすることができるため、これには独自の利点があります。 EmployeeListComponentに、NameInputComponentとListComponentの2つの子コンポーネントを作成しましょう。
それらのうちの最初のものは、入力行の現在の値を保存し、イベントをトリガーすることだけに責任があります。 2番目では、関数が評価され、そこでOnPush変更検出が使用されます。
コードのこれらの変更後、アプリケーションははるかに高速に動作し始めました。 アプリケーションは現在どの程度機能していますか? 残念ながら、ユーザーがキーを押すと、AppComponentで変更検出が呼び出され、EmployeeListComponentの両方のインスタンスで変更検出が呼び出されます。 ただし、今回は、EmployeeListComponentの子コンポーネントで変更検出が呼び出されなくなりました。 実際には、ListComponentはOnPush変更検出を使用し、イベントはEmployeeListComponent領域、つまりEmployeeListの親コンポーネントで発生します。 印刷速度は数桁向上します。

ただし、これでは十分ではありません。 別の可能な最適化は、要素の追加に関するものです。 新しい要素を作成するとき、不変リストに追加する操作を呼び出すため、新しいリストが作成され、EmployeeListComponentへの入力に渡されます。 これにより、変更が検出されます。 つまり、テキストを入力すると、すべてが高速になりますが、要素を追加すると、これらすべてのコンポーネントの数値の不必要な再計算が依然として発生します。
この問題を解決するには、フィボナッチ数を計算するための関数を使用する必要があります。 今日は純粋な関数について言及しましたが、これはその1つです。 良いニュースは、標準偏差の計算など、アプリケーションで本当に役立つものの中に純粋な関数も見つかっていることです。
純粋な関数には、2つの非常に重要なプロパティがあります。 まず、副作用はありません。つまり、ネットワークを介した呼び出しは行われず、ロギングは発生しません。 次に、同じ引数を使用して関数を再度呼び出すと、同じ結果が得られます。 関数型プログラミングの世界では、これは「純粋関数」と呼ばれます。
そして、これは非常に重要な概念です。 Angularには、「純粋なパイプ」と「汚れたパイプ」(不純なパイプ、つまり内部状態を持つパイプ)があります。 通常、データ処理に使用されます。 通常、クリーンパイプはデータをフォーマットします;クリーンパイプの例はDatePipeです。
ダーティパイプは、AsyncPipeなどの特定の状態を内部に保存します。 2つのケースの違いは、Angularは引数が変更されたことを検出した場合にのみクリーンパイプを実行することです。 原則として、きれいなパイプを含む式は、参照透過的に副作用がないと見なされます。 これは関数型プログラミングの概念です。これをよりよく理解するために、Angularコンパイラーによって作成された、クリーンでダーティなパイプを持つテンプレート用のコードを見てください。

誕生日変数にクリーンな日付パイプを適用し、次に汚れたimpureDateを適用します。 画面には2つの異なる結果が表示されます。 最初はそれを理解するのは難しいです。 式の先頭にある不思議なキャラクターは、私たちの興味を引くものではありません。開発者がこれらのインポートを使用しないようにするためにのみ必要です。
私たちにとって重要な部分はそれらに従います。 _ck()はチェックで、現在の日付値が前の値と比較され、値が異なる場合、date.transform()メソッドが呼び出されます。 変更がない場合、キャッシュに保存されている以前の結果が返されます。 impureDateの場合、impureDate.transform()メソッドが単に呼び出されます。
したがって、参照の透過性とは、この式の代わりに出力値を置き換えても、式のセマンティクスがまったく変わらないことを意味します。 副作用は無視できます。
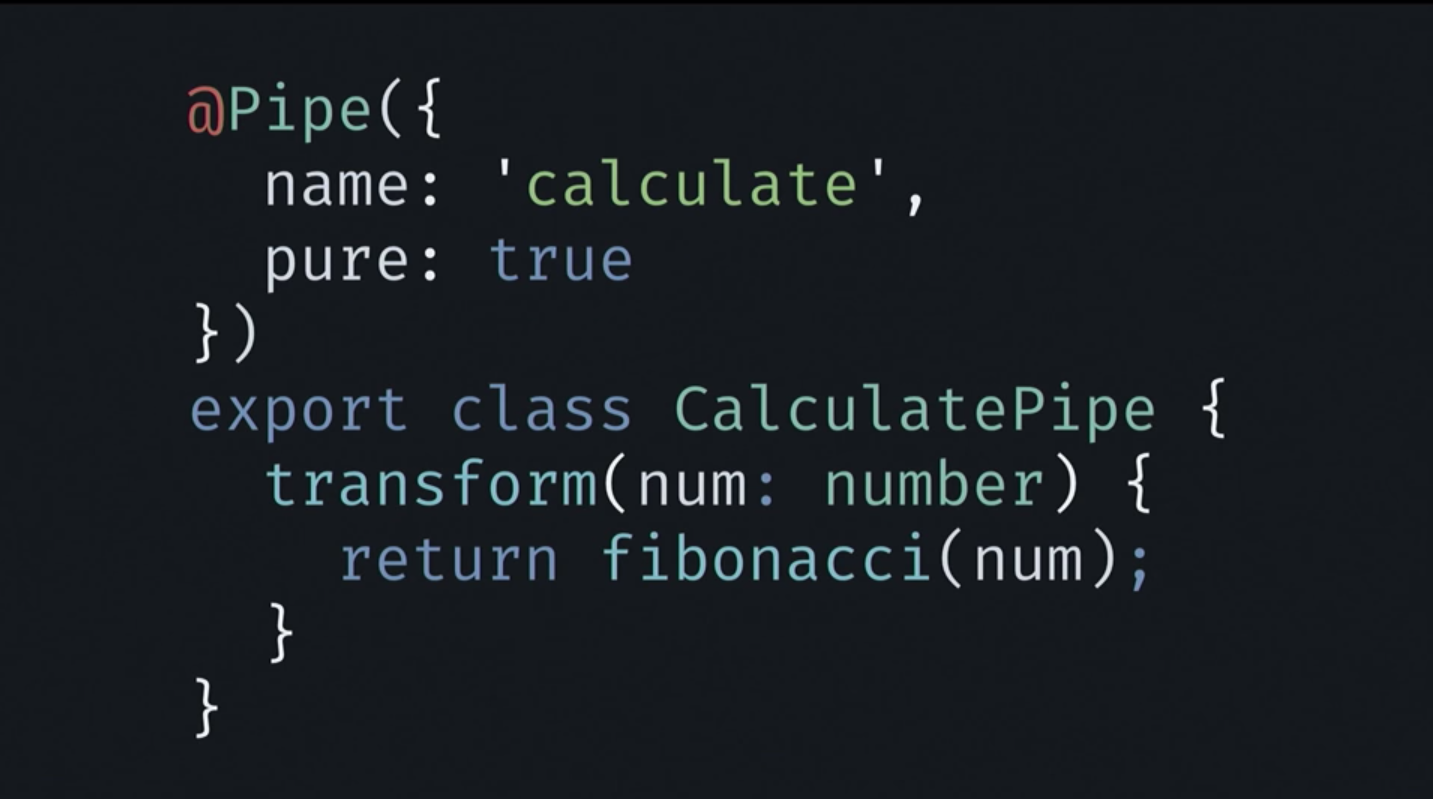
この原理に基づいて、フィボナッチ関数の計算を単純に委任して、作成したCalculatePipeクラスにフィボナッチ関数をカプセル化しました。 さらに、テンプレートを変更する必要があります。 Calculateメソッドの代わりに、パイプを使用します。
それでは、アプリケーションをテストしてみましょう。Benchpressは、新しいユーザーの追加と削除を繰り返します。 アプリケーションはすでに非常に高速に動作していることがわかります。 生産性は数桁向上しました。

レンダリングの最適化
さらに2つの最適化について説明します。 1つ目は、レンダリングの効率についてです。 アプリケーションに一度に1000個の要素を表示してみましょう。 もちろん、実際のアプリケーションではこれを行いません。そのような状況では、仮想スクロールまたはページネーションがあります。 ただし、ここでは作業を異なる方法で最適化しようとします。
アプリケーションがさまざまな方法ですでに最適化されているとします。 未使用のコードは削除されました。パッケージの重量は50キロバイトで、100ミリ秒でダウンロードします。 ただし、画像の描画には少なくとも8秒かかります。 ネットワークのパフォーマンスは優れていますが、ユーザーはまだ満足していません。
データをご覧ください。 それらには重複した値があります。 引数27、28、および29を持つフィボナッチ関数のインスタンスがいくつかあります。

きれいなパイプのおかげで、いくつかのキャッシュがありますが、これらの値は繰り返し計算されます。 幸いなことに、すべての例は小さなスペースにあります。 グローバルキャッシングシステムを作成することができます。 クリーンパイプは、単一の式のみのキャッシュを作成します。 このアプローチとメモ化による実際のキャッシングの違いがわかります。
使用するメモ化は、純粋な関数に対してのみ可能です。 その使用は非常に簡単です。

require( 'lodash.memoize')を介して、memoize関数を取得し、呼び出します。 必要なフィボナッチ関数を作成します。 この関数が作成されるたびに、その入力引数と結果が対応表に書き込まれます。 他に何も必要ありません。 これらの操作が9.5秒かかる前に、アプリケーションが6.7秒で表示されるようになりました。 このような小さな最適化の場合、これは悪くありません。
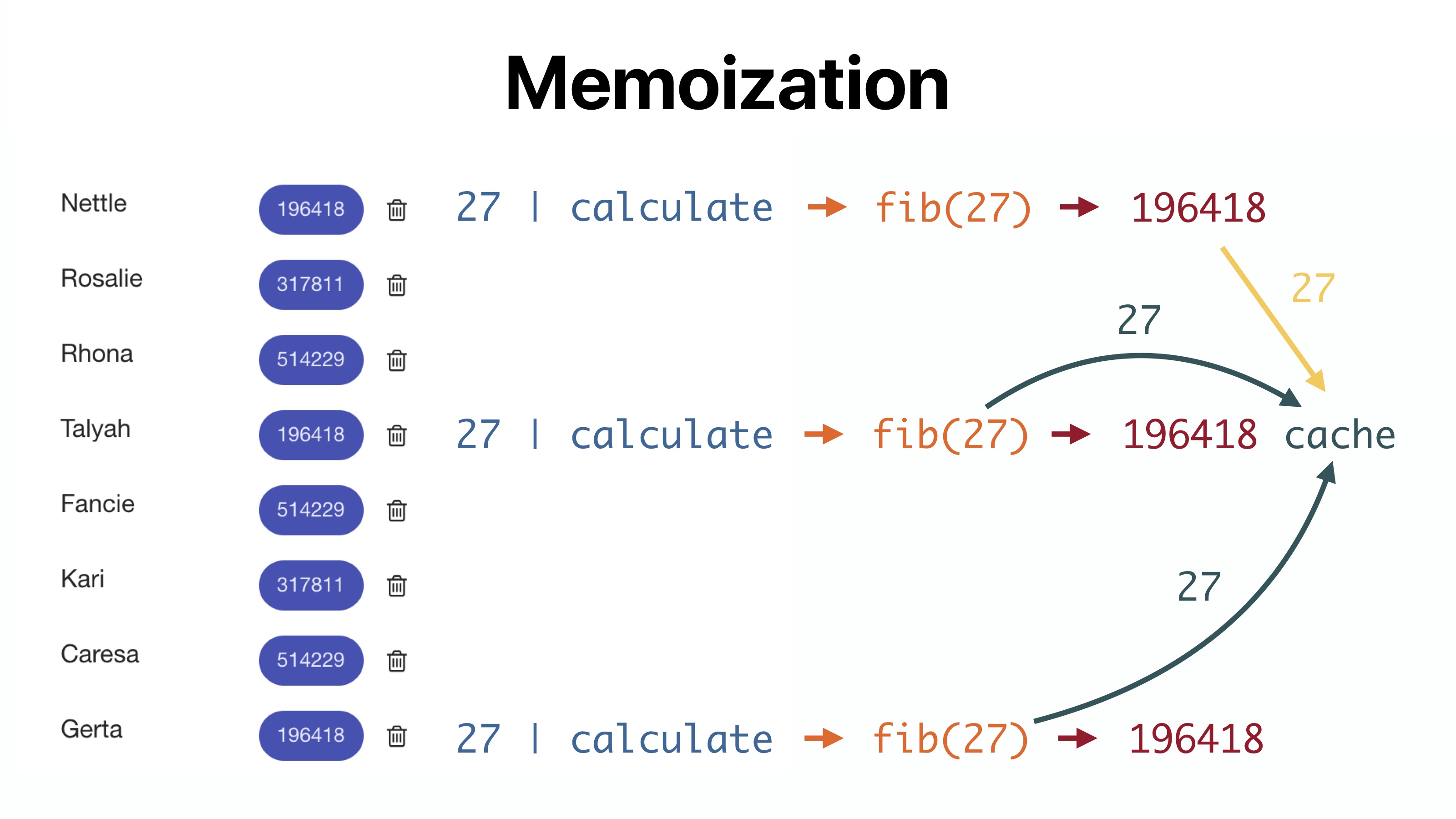
きれいなパイプとメモ化を比較します。 最初のケースでは、Angularが27 | 計算、実行はfibonacci関数に委任されます(27)。 呼び出しが行われるたびに、リストをさらにクロールします。 キャッシングはローカルでのみ行われるため、同じ操作が実行されます。
ただし、次回変更が検出されると、計算引数が変更されていない場合、Angularは結果を再計算しません。 したがって、以降の変更検出の実行ごとに、最適化が機能します。

メモ化の場合、すべてが少し異なって見えます。 最初に27を呼び出します| 計算すると、フィボナッチ数が計算され、数27とフィボナッチ関数の出力値がキャッシュに書き込まれます。 次のすべての呼び出しで27 | キャッシュから取得される結果を計算します。 時間の節約は明らかです。
そのため、いくつかの一般的な傾向が明らかになり始めています。 概念的には、OnPushの変更検出とメモ化は似ています。 あちらこちらに参照の透明性があります。 コンポーネントツリーを抽象構文ツリーとして式として表現する場合、参照透過を使用して最適化を適用することもできます。 ただし、どちらの場合も、これは最新の入力でのみ機能します。
もう少し高度な最適化を試してみましょう。 これを行うには、いくつかの内部Angular APIを参照する必要があります。 あなたがそれらに精通していない場合、心配しないでください、私はそれらについてできるだけ詳細に話そうとします。
ソフトウェア開発の約90%は、要素のリストをユーザーに提示するという要件に基づいています。 Angularは、この目的のためにNgForOfディレクティブを使用します。 ニーズに合わせて最適化を試みます。 仕組みは次のとおりです。

IterableDiffers型のオブジェクトを入力として受け取るコンストラクターがあります。 そして、これがIterableDiffersクラスそのものです。
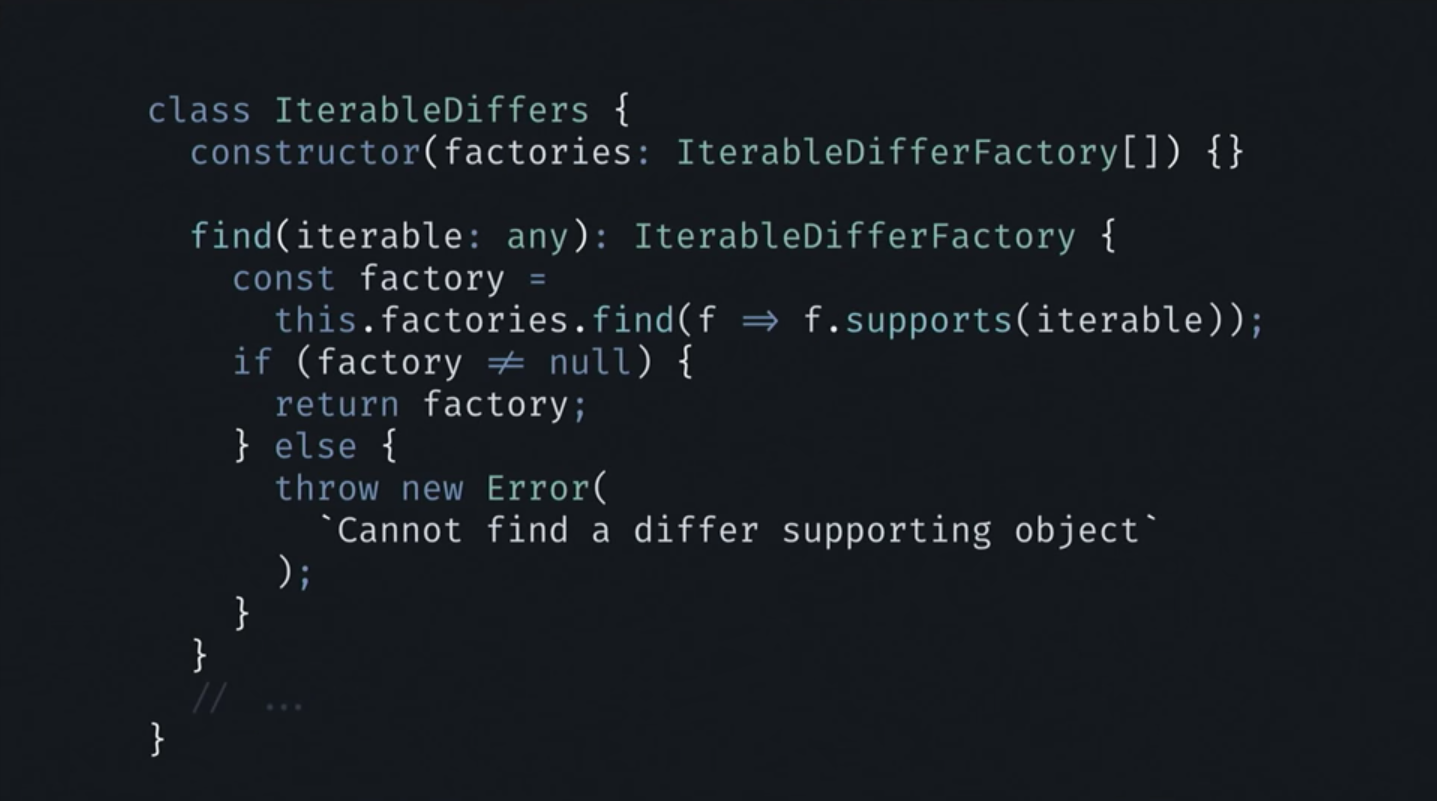
このオブジェクトのクラスでは、コンストラクターとfind()メソッドのみがあります。 コンストラクターはIterableDifferFactory []コレクションを入力として受け入れ、find()メソッドは任意のコレクション(リスト、バイナリ検索ツリー、またはその他)を受け入れます。
次に、このメソッドでは、入力データ構造をサポートする工場で利用可能なすべての工場間で検索が実行されます。 目的のファクトリが見つかった場合、メソッドはそれを返します。 ここでは他に何も起こりません。
さらに3つのインターフェイスを見てみましょう。

IterableDifferFactoryでは、先ほど説明したsupport()メソッドに加えて、trackByFunction関数を入力として取得するcreateメソッドがあります。 NgForディレクティブによって後者に精通しているかもしれません;それもあります。 createメソッドは、IterableDifferインターフェイスのインスタンスを返します。
IterableDifferは、入力としてデータ構造を取り、状態を保存する抽象化です。 その目的は、同じデータ構造の2つのインスタンスを比較することです。 diff()メソッドは、2つのインスタンス間の差の数(AとBと呼びます)、つまり、Bを取得するためにAに追加する必要がある要素の数、Aから取得する必要がある要素の数、および場所を変更した要素の数を返します。
最後に、TrackByFunction関数。 少し後で詳しく説明します。 最初に、説明した構造間の関係を見てみましょう。
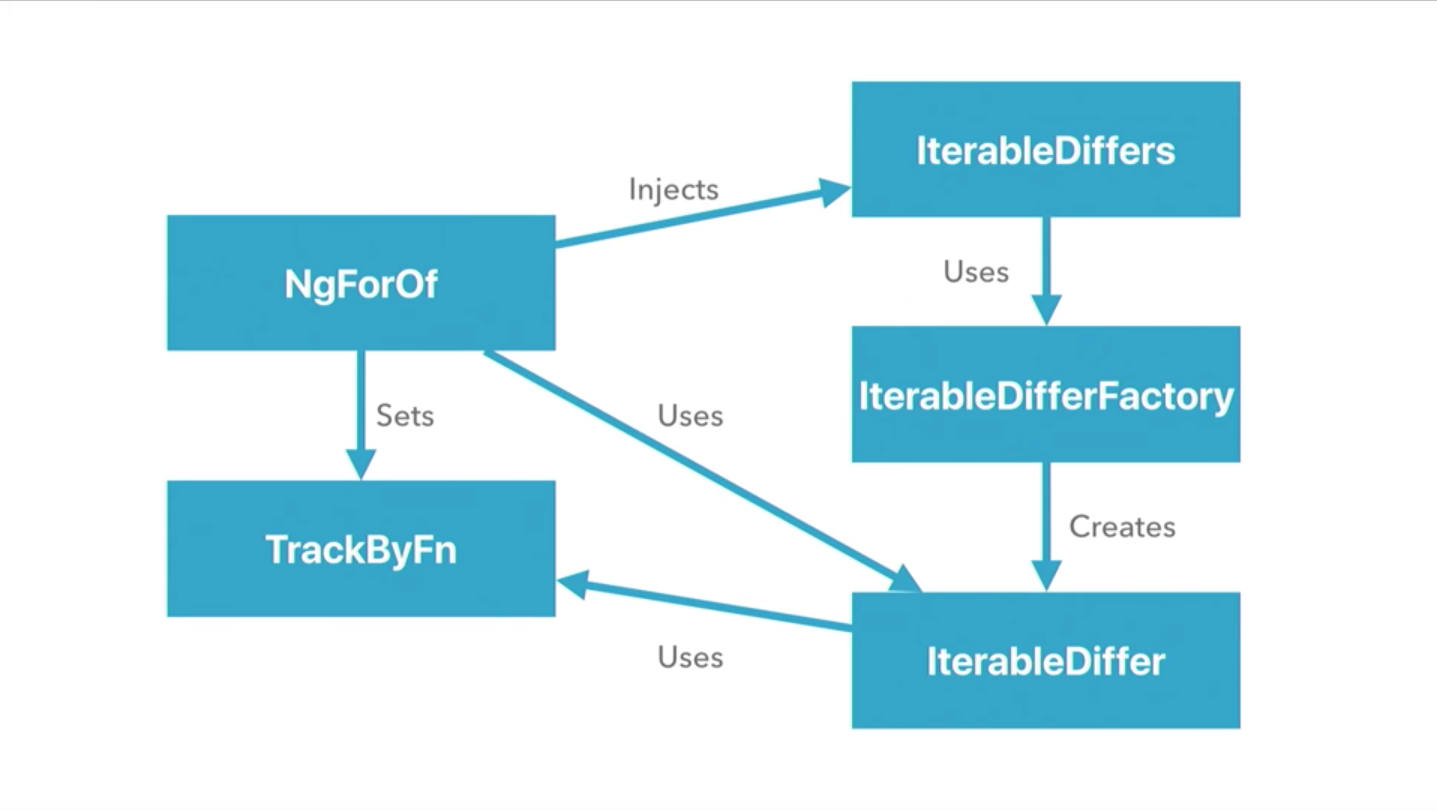
NgForOfディレクティブは、コンストラクターへの引数としてIterableDiffersを注入します。 IterableDifferは、繰り返し処理される現在のオブジェクトとその前の値との間の不一致を検出するために使用されます。 IterableDiffersは、IterableDifferを作成するファクトリーのコレクションを使用します。 この最後の例では、TrackByFnを使用して、コレクション内のアイテムを相互に比較する特性を決定します。
NgForOfの使用方法の違いをご覧ください。

繰り返し処理するコレクションの現在の値でdiff()メソッドを呼び出し、コレクションの以前のバージョンと比較します。 変更が検出されると、DOMに適用されます。
IterableDiffersと特定のtrackBy関数でこれがどのように機能するかを見てみましょう。
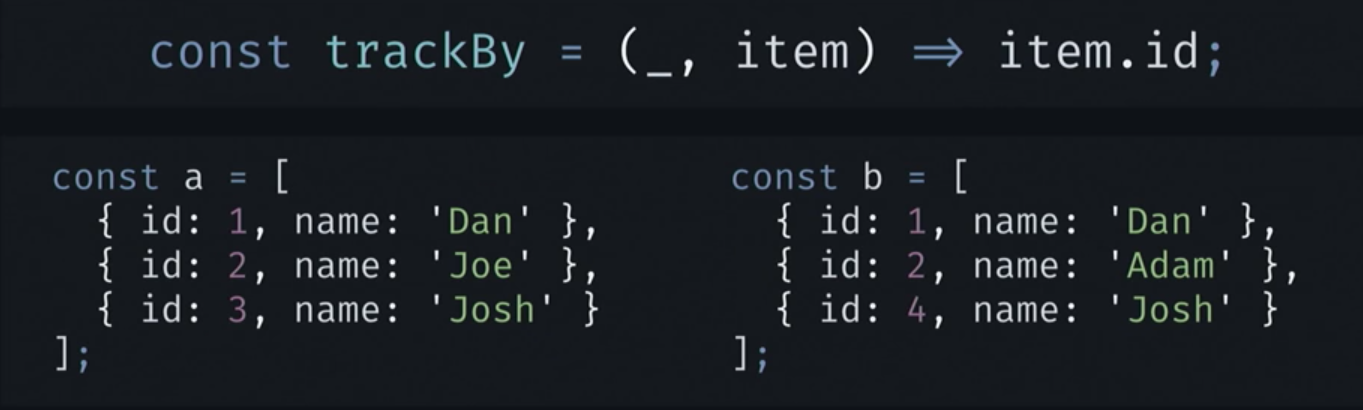
指定された要素の識別子を返すtrackBy関数があります。 そして、aとbの2つのコレクションがあります。 どちらもリストであり、要素のみが含まれています。
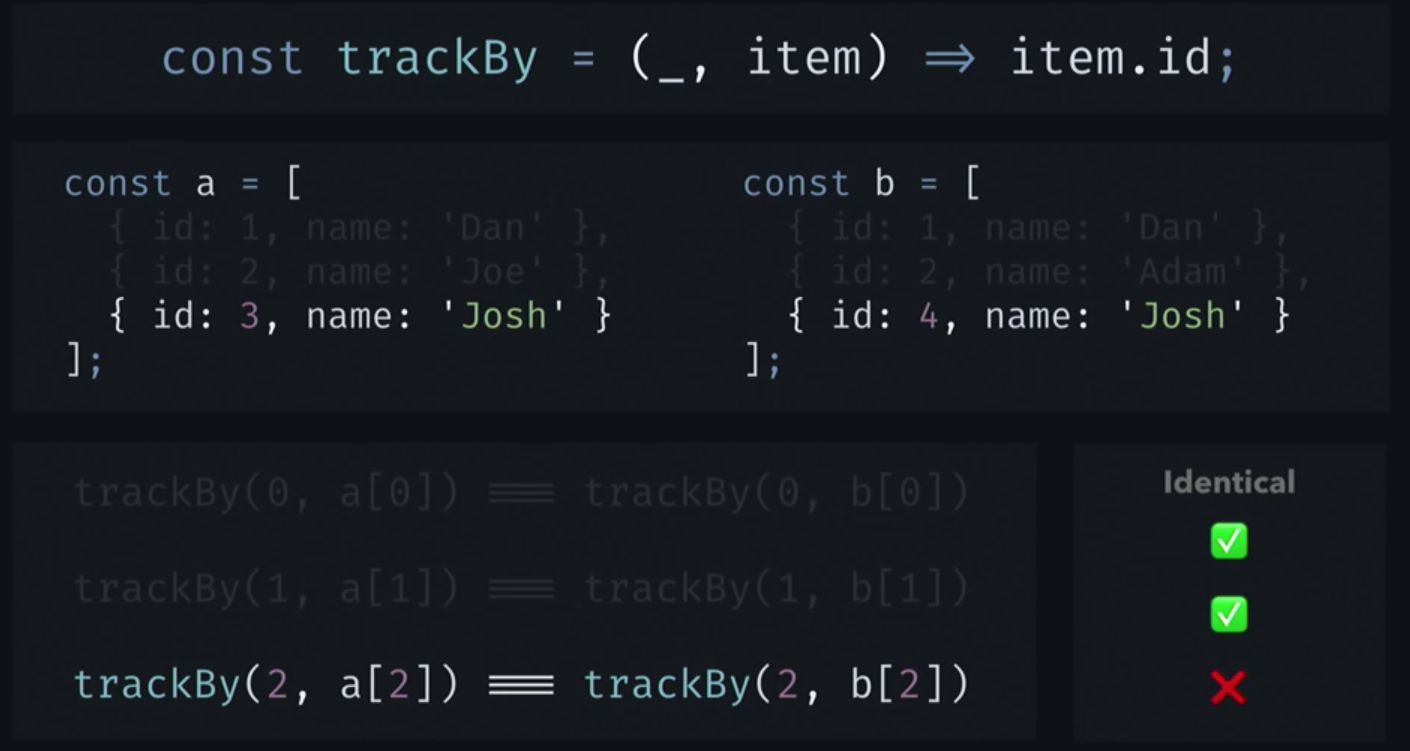
IterableDifferは最初にaの最初の要素とbの最初の要素を比較します。これらは同じ識別子を持つため、IterableDifferは要素が同一であると結論付けます。 2番目の要素でも同じことが起こります。 ここでは、ワーカーの名前が異なることに注意してください。 IterableDifferにとっては重要ではありません。 彼にとって、重要なのは識別子だけです。 ただし、各リストの3番目の要素の場合のように、識別子は異なり、IterableDifferは要素が異なると結論付けます。 したがって、aの最後の要素が削除され、bの最後の要素に置き換えられたことを示す結果が生成されます。
IterableDifferは、データ構造が変更されたかどうかを外部から確認します。 彼はそれを消費者として使います。 ただし、データ構造は、変更されたかどうかを知る方が適切です。 関数型プログラミングの別の概念に触発された、独自のDifferableListデータ構造を実装してみましょう。 それで発生する変更を追跡します。
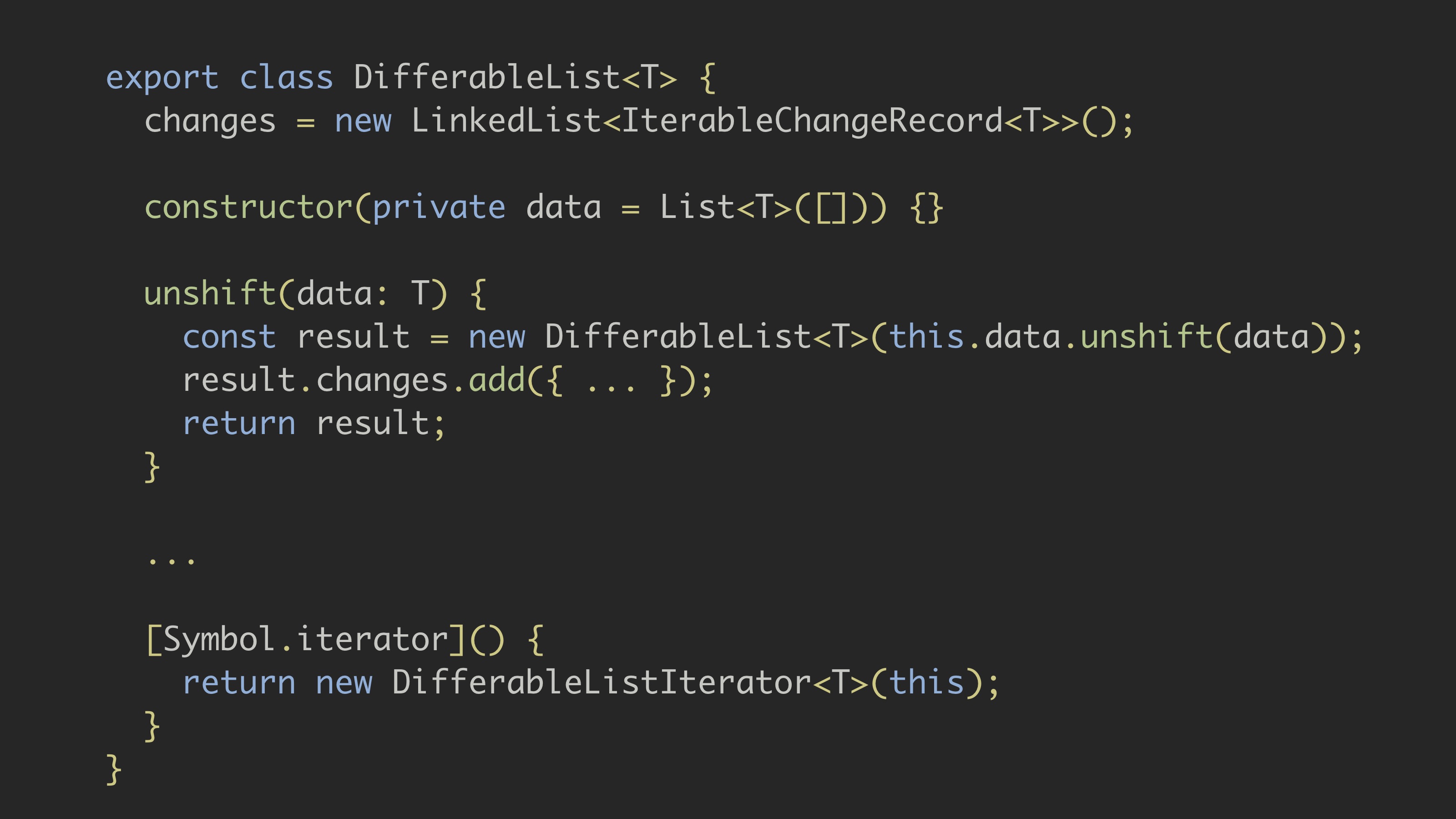
これを行うには、LinkedList(changes変数に格納されている)を使用します。これは、Arrayよりもわずかに高いパフォーマンスを提供し、要素へのランダムアクセスを必要としないためです。
データ自体を不変リストImmutable.jsに保存します。 必要に応じて、変更リストに変更を加えます。
基本的に、デコレータパターンを不変リストに適用します。 さらに、Angularがこのデータ構造をバイパスできるように、反復子パターンを実装しています。
したがって、Angular用に最適化されたデータ構造を作成しました。 ただし、デフォルトで異なるとパフォーマンスが向上しません。

データ構造の変更を常にチェックする特別な違いを使用できます。 したがって、毎回全体として回る必要はありません。 代わりに、単純にchangesプロパティを操作できます。
これらの変更には、少しのリファクタリングが必要になります。 既存のIterableDiffersのセットを拡張するだけです。

記述されたデータ構造は、不変データ構造の一般的な原則に従って作成されます-これも関数型プログラミングの概念です。 それらは、あなたが非常に珍しいことをすることを可能にします:時間の旅、既存の宇宙の枝としての新しい宇宙の作成。 これをご覧になることをお勧めします。
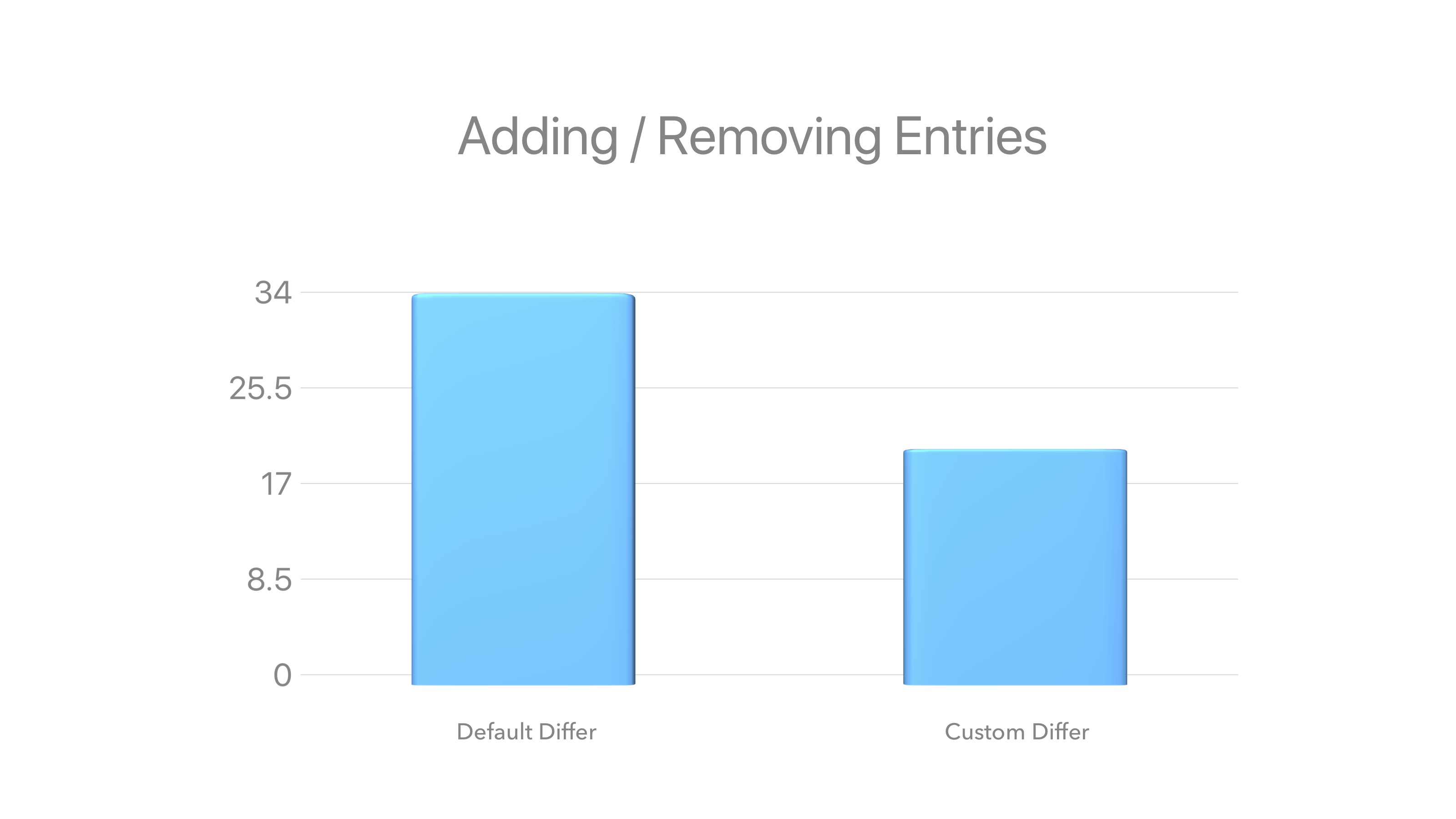
最後のリファクタリング以降、生産性は約30%向上しました。
散歩を繰り返す
変更の検出OnPushは常に期待どおりに動作するとは限りません。 変更検出は、このコンポーネントの入力データが変更されたときだけでなく、このコンポーネントでイベントが発生したときにも、このコンポーネントのサブツリーに対して呼び出されます。
さらに、メモ化による純粋なパイプの違いと、対応するキャッシングメカニズムの違いとは何かを学びました。 関数型プログラミングから取得した、純度と参照の透明性の概念を理解しました。
最後に、DifferオブジェクトとTrackByFn関数の動作を調べました。 また、デフォルトとは異なる他のTrackByFnを使用すると、パフォーマンスが低下するだけです。
結論として、パフォーマンスを最適化するための奇跡的な治療法はないと言えます。 コンポーネントツリーと操作するデータがどのように配置されているかを十分に理解し、これに基づいて、アプリケーションに固有の最適化を適用する必要があります。 そして、もちろん、コンピューターサイエンスから提供されたソリューションを適用する必要があります。
便利なリンクを次に示します。
- mgv.io/ng-cd-AngularのOnPush変更検出戦略
- mgv.io/ng-pure-純粋なパイプと参照の透明性
- mgv.io/ng-diff-角度の違いを理解する
- mgv.io/ng-perf-checklist-角度性能チェックリスト
- mgv.io/ng-checklist-video-角度性能チェックリスト
それらについては、説明されているトピックについて詳しく知ることができます。 最初の記事では、AngularでのOnPushの変更の検出について説明し、2番目はきれいなパイプと参照の透過性について、3番目は角度の違いについて説明します。 さらに、Angularパフォーマンスチェックリストのもう少し詳細なバージョンがあります。 変更検出を構成する方法について説明します。
広告の分。 以前のHolyJSからこのレポートが気に入った場合は、注意してください。HolyJS2018 Piterは5月19〜20日に開催されます。 また、5月1日からチケットの価格が上昇するという事実に注意を払ってください。