Netflixはフェールオーバー時間を無料で45分から7分に短縮します

画像: フロリダメモリ Opensource.comによって変更されました。 CC BY-SA 4.0
2012年の冬、Netflixは、米国東部地域のAWS Elastic Load Balancerサービスの問題のために7時間オフになり、 長い障害を経験しました(NetflixはAWSで実行されます-独自のデータセンターはありません。Netflixとのすべての対話は、ストリーミングビデオ自体を除くAWS。[ 再生 ]をクリックすると、独自のCDNネットワークからのビデオストリームの読み込みが開始されます)。 クラッシュ中、米国東部地域からのパッケージはサーバーに届きませんでした。
これが再び起こらないようにするために、基本的なサービスプロバイダーの障害に耐えるフェールオーバーシステムを作成することにしました。 フェールオーバーは、メインシステムに障害が発生した場合に冗長機器が自動的にアクティブになるフェールセーフシステムです。
地域の変更はリスクを軽減します
3つのAWSリージョンに拡大しました。2つは米国(US-EastおよびUS-West)、もう1つは欧州連合(EU)です。 1つの領域で障害が発生した場合に切り替えるのに十分なリソースを予約しました。
典型的なフェイルオーバーは次のとおりです。
- 地域の1つで問題が発生していることを理解してください。
- 2つのレスキュー領域をスケールします。
- 問題地域から救助者へのプロキシトラフィック。
- DNSを問題地域から救助者に変更します。
すべてのステップを研究します。
1.問題を特定する
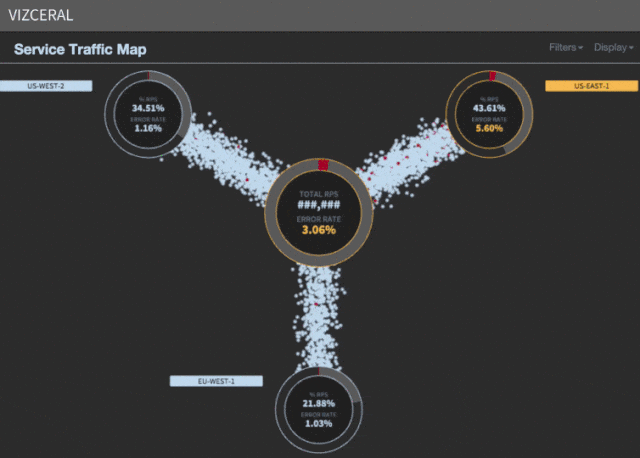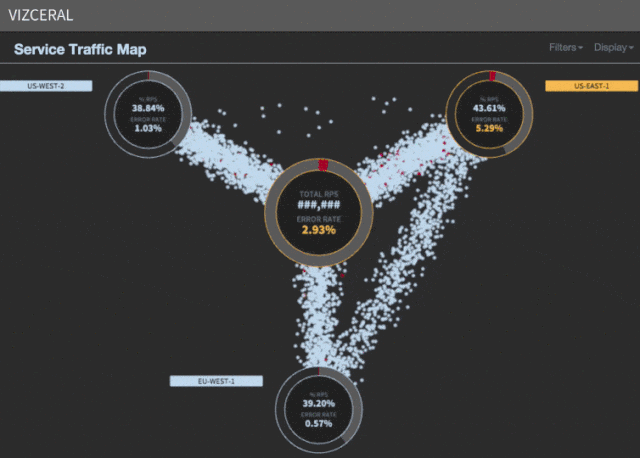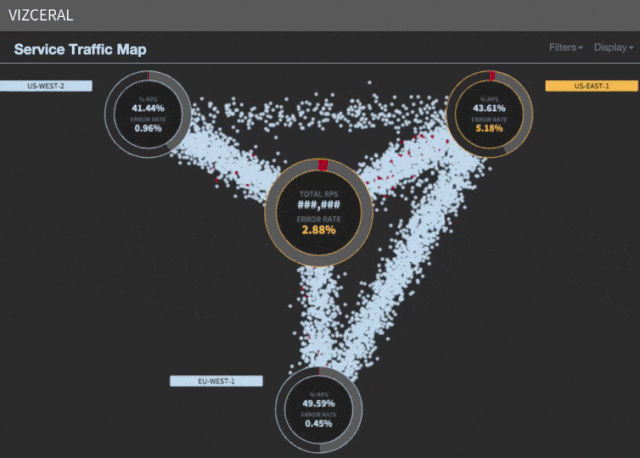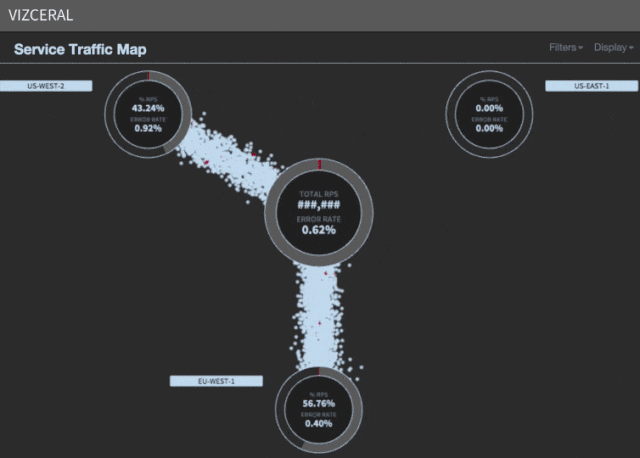
メトリックが必要ですが、システムの正常性について話すメトリックが1つ必要です。 Netflixは、ビジネスメトリック「1秒あたりのストリーム開始数」(略してSPS)を使用します。 これは、ストリーミングを正常に開始したクライアントの数です。
データは地域ごとに分割されます。 いつでも、各地域のSPSチャートを作成して、現在の値を最後の日または週の値と比較できます。 SPSの低下に気付くと、クライアントがストリーミングを開始できないことがわかります。したがって、問題が発生します。
問題は必ずしもクラウドインフラストラクチャに関連しているわけではありません。 これは、Netflixエコシステムを構成する数百のマイクロサービスの1つ、壊れた海底ケーブルなどのコードの不良かもしれません。理由がわからない場合があります。
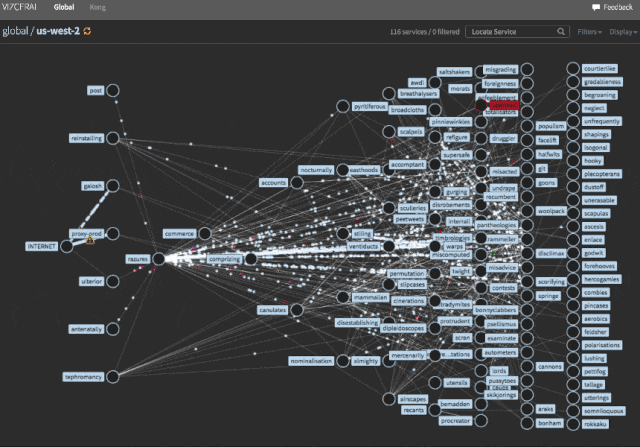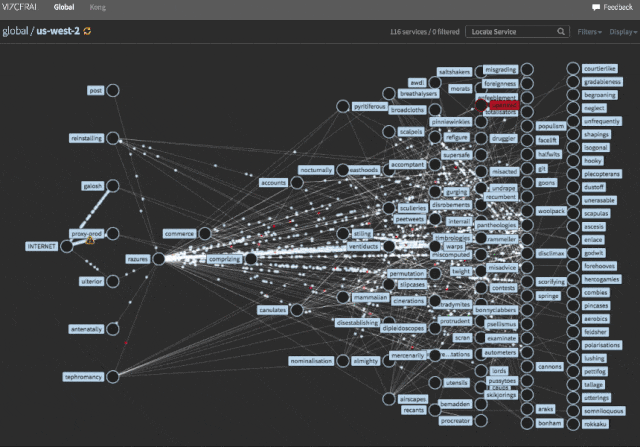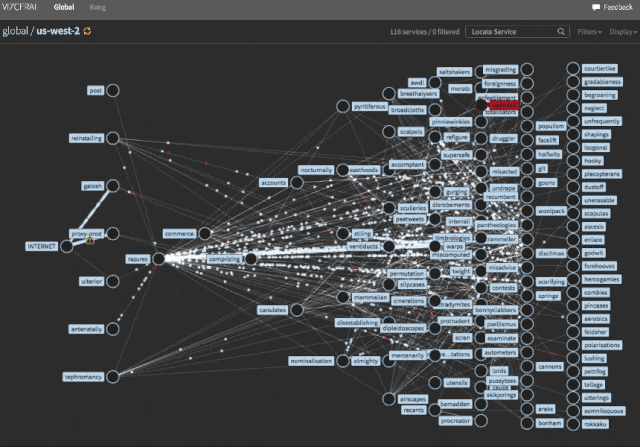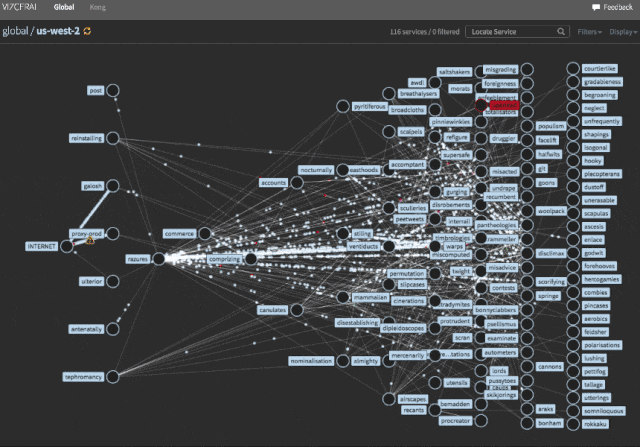
SPSが1つのリージョンでのみドロップした場合、これはフェイルオーバーの優れた候補です。 複数の地域にいる場合は、一度に1つの地域しか避難できないため、運はありません。 そのため、地域にマイクロサービスを順番に展開しています。 展開に問題がある場合は、すぐに問題を回避して修正できます。 まったく同じ方法で、トラフィックがリダイレクトされた後も問題が解決しない場合(DDoS攻撃の場合のように)障害を回避したいと考えています。
2.スケールレスキュー
影響を受ける地域を特定した後、トラフィックを転送するために他の地域(「救助者」)を準備する必要があります。 避難の前に、それに応じて救助地域のインフラストラクチャを拡張する必要があります。
この文脈でスケーリングとはどういう意味ですか? Netflixのトラフィックパターンは1日を通して変化します。 通常は午後6時から9時頃のピーク時間がありますが、世界のさまざまな地域では、この時期はさまざまな時間になっています。 トラフィックは、米国東部地域でピークに達し、米国西部地域よりも3時間早く、EU地域から8時間遅れています。
US-Eastがシャットダウンした場合、東海岸からEU地域へのトラフィック、および南アメリカからUS-Westへのトラフィックを転送します。 これは、遅延と最高のサービス品質を削減するために必要です。
これを考慮に入れると、線形回帰を使用して、各マイクロサービスの履歴スケーリングデータを使用して、この時刻(および曜日)に救助地域に送信されるトラフィックを予測できます。
各マイクロサービスの適切なサイズを決定した後、それらのスケーリングを開始し、各クラスターに必要なサイズを設定します-AWSに魔法をかけます。
3.トラフィックのプロキシ
マイクロサービスクラスターのスケーリングが完了したので、影響を受ける地域からレスキュー地域へのトラフィックのプロキシを開始します。 Netflixは、Zuulと呼ばれる高性能の地域間ボーダープロキシサーバーを開発しました。これをオープンソースとして公開しています 。
これらのプロキシは、要求の認証、負荷制限、失敗した要求の再試行などのために設計されています。Zuulプロキシサーバーは、リージョン間でプロキシを実行することもできます。 この機能を使用して、影響を受ける地域からのトラフィックをリダイレクトし、リダイレクトされるトラフィックの量を100%に達するまで徐々に増やします。
このようなプログレッシブプロキシにより、サービスはスケーリングルールを使用して着信トラフィックに応答できます。 これは、スケーリング予測が行われた瞬間と各クラスターのスケーリングに必要な時間の間のトラフィックの変化を補正するために必要です。
Zuulは、被害者からの着信トラフィックを正常な地域にリダイレクトすることにより、大変な仕事をしています。 ただし、影響を受ける地域の使用を完全に放棄する必要がある場合があります。 これがDNSの出番です。
4. DNSを変更する
緊急避難の最後の手順は、影響を受ける地域を指すDNSレコードを更新し、それらを作業地域にリダイレクトすることです。 これにより、トラフィックが完全に転送されます。 DNSキャッシュを更新しないクライアントは、影響を受ける地域のZuulによって引き続きリダイレクトされます。
これは、Netflixを地域から避難させる方法の一般的な説明です。 以前は、プロセスに多くの時間がかかりました-約45分(運がよければ)。
避難をスピードアップ
ほとんどの時間(約35分)が救助地域の拡大を待つことに費やされていることに気付きました。 AWSは数分以内に新しいインスタンスを提供できますが、スケーリングプロセスは、 UPが検出に登録される前に、サービスの起動、ウォームアップ、およびその他の必要なタスクの処理に大きな時間を費やします。
長すぎると判断しました。 避難に10分もかからないことを望みます。 そして、追加の操作負荷なしでプロセスを最適化したいと思います。 財務コストを増やすことも望ましくありません。
1つの障害が発生した場合に備えて、3つの地域すべてで容量を確保しています。 これらの容量に対して既に支払いを行っている場合、それらを使用してみませんか? そこで、プロジェクトニンブル(プロジェクト「Shustrik」)を開始しました。
アイデアは、各マイクロサービスのインスタンスプールのホットプールを維持することでした。 移行の準備ができたら、クラスターに「ホット」リザーブを実装して、現在のトラフィックを受け入れます。
未使用の予約済み容量はトラフと呼ばれます。 一部のNetflix開発チームは、バッチジョブに「フィーダー」の一部を使用することがあるため、 すべてをホットリザーブに入れることはできません。 ただし、マイクロサービスごとにシャドウクラスターを維持することで、そのような必要が生じた場合に1日の各時間にトラフィックを避難させるのに十分なインスタンスが存在するようにできます。 残りのインスタンスはバッチジョブで使用できます。
避難中に、従来のAWSスケーリングの代わりに、シャドウクラスターから作業クラスターにインスタンスをデプロイします。 前の35とは異なり、プロセスには約4分かかります。
このような注入は迅速であるため、スケーリングルールが応答できるようにプロキシを使用して慎重に移動する必要はありません。 DNSを切り替えるだけでゲートウェイを開くことができるため、ダウンタイム中の貴重な時間をさらに節約できます。
これらのインスタンスがメトリックレポートに含まれないように、シャドウクラスターにフィルターを追加しました。 そうしないと、メトリックが汚染され、通常の動作が低下します。
また、検出クライアントを変更して、シャドウクラスターからインスタンスのUP登録を削除しました。 インスタンスは、避難が始まるまで影の中に残ります。
ここで、わずか7分でリージョンのフェイルオーバーを実行します。 既存の予約済み容量が使用されるため、追加のインフラストラクチャコストは負担しません。 フェイルオーバーソフトウェアは、3人のエンジニアのチームによってPythonで記述されています。