
こんにちは、RiotのエンジニアであるTony Albrechtです。 プロファイルと最適化が好きです。 この記事では、プロファイリングの基本について説明し、Windowsマシンでのプロファイリング中にC ++コードの例を分析します。 最も単純なものから始め、徐々に中央処理装置の内臓を掘り下げていきます。 最適化の機会に出会ったら、変更を実装します。次の記事では、League of Legendsのコードベースの実際の例を分析します。 行こう!
コードレビュー
最初に、プロファイルするコードを見てください。 私たちのプログラムは、シンプルな小さなOpenGLレンダラー、オブジェクト指向、階層シーンツリーです。 私はリソース的にメインオブジェクトObjectを呼び出しました-シーン内のすべてはこれらの基本クラスの1つから継承します。 コードでは、Node、Cube、およびModifierのみがObjectから継承されます。

キューブは、画面上でそれ自体をキューブとしてレンダリングするオブジェクトです。 モディファイヤは、シーンツリー内で「存続」するオブジェクトであり、更新されると、それに追加されたオブジェクトを変換します。 ノードは、他のオブジェクトを含む可能性のあるオブジェクトです。
システムは、ノードにキューブを追加したり、他のノードに一部のノードを追加したりして、オブジェクトの階層を作成できるように設計されています。 (修飾子を使用して)ノードを変換すると、ノードに含まれるすべてのオブジェクトが変換されます。 この単純なシステムを使用して、互いに周回するキューブツリーを作成しました。

提案されたコードはシーンツリーの最適な実装ではありませんが、大丈夫です。このコードはその後の最適化に必要です。 実際、これは2009年にオブジェクト指向プログラミングの落とし穴のパフォーマンスを分析するために書いたPlayStation3®の例の直接移植です。 今日の記事を9年前の記事と部分的に比較して、かつてPS3について学んだ教訓が最新のハードウェアプラットフォームに当てはまるかどうかを確認できます。
しかし、キューブに戻りましょう。 上記のgifは、約55千個の回転する立方体を示しています。 シーンのレンダリングのプロファイルを作成するのではなく、レンダリング時のアニメーションとカリングのみをプロファイルすることに注意してください。 サンプルの作成に関係するライブラリ: 親愛なるImguiとBulletの Vectormath、両方とも無料。 プロファイリングには、AMD Code XLと、この記事の速攻に組み込まれたシンプルな計装プロファイリングツールを使用しました。
仕事に取りかかる前に
単位
最初に、パフォーマンス測定について説明します。 ゲームでは、1秒あたりのフレーム数(FPS)が指標としてよく使用されます。 これは優れたパフォーマンスインジケータですが、フレームの一部を分析したり、さまざまな最適化による改善を比較したりするときには役に立ちません。 「ゲームは今では毎秒20フレーム高速になりました!」と言ってみましょう-それは一般的にどれくらい高速ですか?
それは状況次第です。 60 FPS(またはフレームあたり1000/60 = 16.666ミリ秒)で、現在80 FPS(フレームあたり1000/80 = 12.5ミリ秒)の場合、改善は16.666ミリ秒-12.5ミリ秒= 4.166ミリ秒ですフレームごと。 これは良いゲインです。
しかし、20 FPSがあり、今では40 FPSになっている場合、改善は既に等しくなります(1000/20-1000/40)= 50 ms-25 ms =フレームあたり25 ms! これは、ゲームを「再生不能」から「許容可能」に変えることができる強力なパフォーマンスブーストです。 FPSメトリックの問題は相対値であるため、常にミリ秒を使用します。 常に。
測定する
プロファイラーにはいくつかの種類があり、それぞれに長所と短所があります。
計装機器
計装されたプロファイラーの場合、プログラマーは、パフォーマンスを測定する必要があるコードを手動でマークする必要があります。 これらのプロファイラーは、一意のマーカーに焦点を合わせて、プロファイルされたフラグメントの開始時間と終了時間を検出して保存します。 例:
void Node::Update() { FT_PROFILE_FN for(Object* obj : mObjects) { obj->Update(); } }
この場合、 FT_PROFILE_FN
は、作成時間を修正するオブジェクトを作成し、スコープ外になったときに破棄します。 これらの時点は、関数の名前とともに、その後の分析と視覚化のために、ある種の配列に保存されます。 試してみると、コードで視覚化を実装できます。または、 Chromeトレースなどのツールで、少し簡単に実装できます 。
テストプロファイリングは、コードパフォーマンスの視覚化とバーストの検出に最適です。 アプリケーションのパフォーマンス特性が階層の形で提示されている場合、どの関数が全体として最もゆっくり動作し、他のほとんどの機能を引き起こし、実行時間を最も変化させるかなどをすぐに確認できます。
この図では、各色のサイコロが機能に対応しています。 他のサイコロのすぐ下にあるサイコロは、「上流」機能と呼ばれる機能を示します。 プレートの長さは、機能の持続時間に比例します。
計装プロファイリングは貴重な視覚情報を提供しますが、依然として欠陥があります。 プログラムの実行が遅くなります。測定するほど、プログラムは遅くなります。 したがって、測定および制御プロファイラーを作成するときは、アプリケーションのパフォーマンスへの影響を最小限に抑えてください。 スロー機能をスキップすると、プロファイルに大きなギャップが表示されます。 また、コードの各行の速度に関する情報は得られません。可視領域のみを簡単にマークできますが、測定とプロファイリングのオーバーヘッドは通常、個々の行の寄与を無効にするため、それらを測定するだけでは役に立ちません。
サンプリングプロファイラー
サンプリングプロファイラーは、プロファイリングするプロセスの実行ステータスを要求します。 実行中の命令を示すプログラムカウンター(プログラムカウンター、PC)を定期的に保存し、現在の命令が含まれている関数が呼び出した関数を調べるためにスタックも保存します。 ほとんどのサンプルを含む関数または行が最も遅い関数または行になるため、この情報はすべて有用です。 サンプリングプロファイラの持続時間が長いほど、より多くの命令とスタックのサンプルが収集され、結果が改善されます。

サンプリングプロファイラーを使用すると、制御および測定プロファイラーの場合のように、プログラムパフォーマンスの非常に低レベルの特性を収集でき、手動の介入を必要としません。 さらに、プログラムの実行状態全体を自動的にカバーします。 これらのプロファイラーには2つの主な欠点があります。各フレームのバーストを決定するのにはあまり役に立たず、また、特定の関数が他の関数に対していつ呼び出されたかを知ることができません。 つまり、優れた制御および測定プロファイラーと比較して、階層呼び出しに関する情報が少なくなります。
専門のプロファイラー
これらのプロファイラーは、特定のプロセス情報を提供します。 通常は、中央処理装置やビデオカードなどのハードウェア要素に関連付けられており、たとえばキャッシュミスや誤った分岐予測など、ユーザーが興味を持っている特定のイベントを生成することができます。 機器メーカーは、これらのイベントを測定する機能を備えているため、パフォーマンスの低下の原因を簡単に見つけることができます。 したがって、これらのプロファイルを理解するには、使用するハードウェアの知識が必要です。
ゲーム固有のプロファイラー
より一般的なレベルでは、ゲーム固有のプロファイラーは、たとえば、画面上のミニオンの数や、キャラクターの視野内の目に見える粒子の数をカウントできます。 このようなプロファイラーも非常に便利で、ゲームロジックの高レベルのエラーを特定するのに役立ちます。
プロファイリング
比較標準なしでアプリケーションをプロファイリングすることは意味をなさないため、最適化するときには、信頼できるテストスクリプトを手元に用意する必要があります。 見た目ほど単純ではありません。 最新のコンピューターは、アプリケーションだけでなく、数百、あるいは数百の他のプロセスを実行し、絶えずそれらを切り替えます。 つまり、他のプロセスは、デバイスへのアクセス(たとえば、いくつかのプロセスがディスクからの読み取りを試みている)やプロセッサ/ビデオカードリソースの競合により、プロファイリングしているプロセスの速度を低下させる可能性があります。 したがって、適切な開始点を得るには、タスクに取りかかる前に、いくつかのプロファイリング操作を通じてコードを実行する必要があります。 実行の結果が大きく異なる場合は、理由を把握してその変動を取り除くか、少なくともそれを減らす必要があります。
結果の可能な限り最小の広がりを達成した後、システムの「ノイズ」で失われる可能性があるため、小さな改善(利用可能な変動性よりも小さい)は測定が難しいことを忘れないでください。 ゲームの特定のシーンがフレームごとに14〜18ミリ秒の範囲で表示され、平均で16ミリ秒であるとします。 関数の最適化、リプロファイリング、フレームあたり15.5ミリ秒の取得に2週間を費やしました。 速いですか? 正確に調べるには、ゲームを何度も実行して、このシーンをプロファイリングし、算術平均値を計算し、傾向をプロットする必要があります。 ここで説明するアプリケーションでは、数百のフレームを測定し、結果を平均して信頼できる十分な値を取得します。
さらに、多くのゲームは複数のスレッドで実行されます。その順序はハードウェアとOSによって決定され、非決定的な動作や少なくとも異なる実行時間につながる可能性があります。 これらの要因の影響を忘れないでください。
上記に関連して、プロファイリングと最適化のための小さなテストスクリプトを作成しました。 理解するのは簡単ですが、パフォーマンスを大幅に向上させるリソースがあるほど複雑です。 簡単にするために、プロファイリング時にレンダリングをオフにして、中央処理装置に関連する計算コストのみを表示することに注意してください。
コードのプロファイリング
以下は最適化するコードです。 1つの例がプロファイリングのみを教えてくれることを忘れないでください。 独自のコードのプロファイリングで予想外の困難に遭遇することは間違いありません。この記事が独自の診断フレームワークの作成に役立つことを願っています。
{ FT_PROFILE("Update"); mRootNode->Update(); } { FT_PROFILE("GetWBS"); BoundingSphere totalVolume = mRootNode->GetWorldBoundingSphere(Matrix4::identity()); } { FT_PROFILE("cull"); uint8_t clipFlags = 63; mRootNode->Cull(clipFlags); } { FT_PROFILE("Node Render"); mRootNode->Render(mvp); }
さまざまなスコープに制御マクロFT_PROFILE()
を追加して、コードのさまざまな部分の実行時間を測定しました。 以下では、各フラグメントの目的について詳しく説明します。
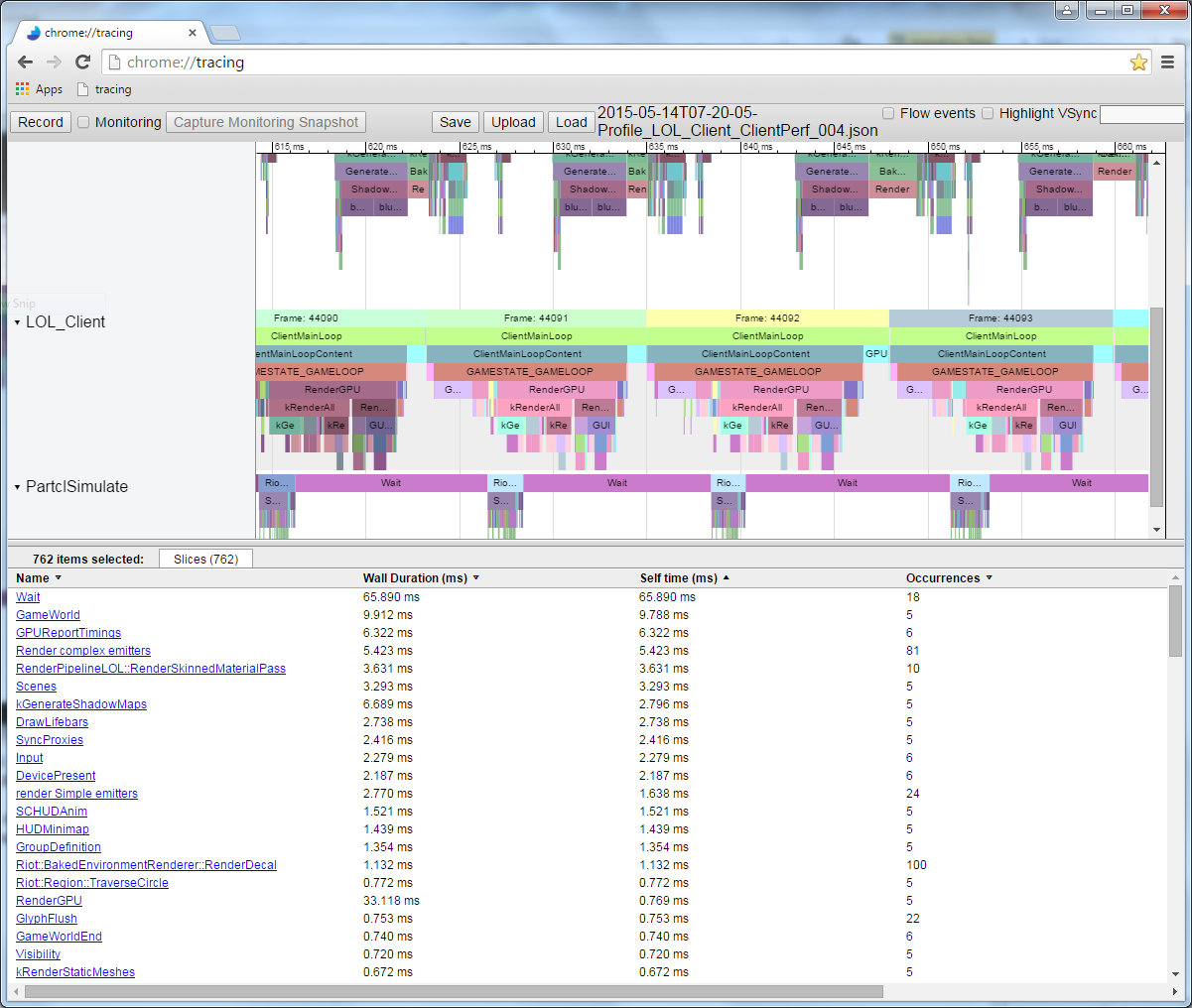
コードを実行し、測定されたプロファイルからデータを書き込むと、Chromeで次の画像が表示されました://トレース:

これは単一のフレームプロファイルです。 ここでは、各関数呼び出しの相対的な期間を確認します。 実行順序を確認できることに注意してください。 これらの関数呼び出しによって呼び出される関数を測定すると、親関数のサイコロの下に表示されます。 たとえば、 Node::Update()
を測定し、この再帰呼び出し構造を取得しました。

測定中のこのコードの1フレームの実行時間は数ミリ秒異なるため、少なくとも数百フレームの算術平均を取り、元の標準と比較します。 この場合、297フレームが測定され、平均値は17.5ミリ秒で、一部のフレームは19ミリ秒まで実行され、その他は16.5ミリ秒未満でしたが、それぞれでほぼ同じことが実行されました。 これは、フレームの暗黙的な変動です。 繰り返し実行して結果を安定して比較すると、約17.5ミリ秒が得られるため、この値は信頼できる出発点と考えることができます。

コードのチェックマークを無効にして、 AMD CodeXLサンプリングプロファイラーで実行すると、次の図が表示されます。

最も「要求された」5つの関数を分析すると、次の結果が得られます。

最も遅い関数は行列乗算のようです。 これらのすべての回転に対して、関数は多くの計算を実行する必要があるため、論理的に聞こえます。 上の図でスタック階層をよく見ると、 Modifier::Update()
、 Node::Update()
、 GetWorldBoundingSphere()
およびNode::Render()
を使用して行列乗算演算子が呼び出されていることがGetWorldBoundingSphere()
ます。 非常に多くの場所から頻繁に呼び出されるため、この演算子は最適化の良い候補と見なすことができます。
マトリックス::演算子*
サンプリングプロファイラーを使用して、乗算に関与するコードを分析すると、各行の「コスト」がわかります。

残念なことに、行列乗算コードの長さは(効率のため)1行のみであるため、この結果はほとんど得られません。 または、それほど小さくないですか?
アセンブラを見ると、機能のプロローグとエピローグを特定できます。

これは、内部関数呼び出し命令のコストです。 プロローグでは、新しいスタックスペースが指定され(ESPは現在のスタックポインター、EBPは現在のスタックフレームのベースポインター)、エピローグはクリーンアップして戻ります。 インラインではなく、ある種のスタックスペースを使用する(つまり、ローカル変数を持っている)関数を呼び出すたびに、これらすべての命令を挿入して呼び出すことができます。
関数の残りの部分を展開して、行列の乗算が実際に行うことを見てみましょう。

うわー、たくさんのコード! そして、これは最初のページのみです。 完全な機能は250-300命令で1キロバイト以上のコードを必要とします! 関数の始まりを分析します。

青色で強調表示された上の行は、合計実行時間の約10%かかります。 隣接するものよりもずっと遅いのはなぜですか? このMOVSS命令は、eax + 34hでメモリから浮動小数点値を取得し、xmm4レジスタに格納します。 上記の行はxmm1レジスタでも同じですが、はるかに高速です。 なんで?
キャッシュミスがすべてです。
よく見てみましょう。 個々の指示のサンプリングは、さまざまな状況に適用できます。 最新のプロセッサはいつでも複数の命令を実行し、1クロックサイクル中に多くの命令を再ソート(リタイア)できます。 イベントベースのサンプリングでさえ、イベントを間違った指示に起因させることができます。 したがって、アセンブラのサンプリングを分析するときは、何らかのロジックに導かれる必要があります。 この例では、最もサンプリングされた命令が最も遅くなることはありません。 この線に関連する何かの遅い動作については、ある程度の確実性をもってのみ言うことができます。 また、プロセッサはメモリとの間で多数のMOVを実行するため、これらのMOVがパフォーマンスの低下の原因であると想定します。 これを確認するには、キャッシュミスのイベントベースのサンプリングを有効にしてプロファイルを実行し、結果を確認します。 しかし、今のところは、本能を信頼し、キャッシュミスの仮説に基づいてプロファイルを実行しましょう。
L3キャッシュのスキップには100サイクル以上(場合によっては数百サイクル)かかり、L2キャッシュのミスには約40サイクルかかりますが、これはすべてプロセッサに依存します。 たとえば、x86 命令は1から約100サイクルかかりますが、それらのほとんどは20サイクル未満です(除算命令の中には、かなり遅いハードウェアで動作するものもあります)。 私のCore i7では、乗算、加算、除算の命令に数サイクルかかりました。 命令がパイプラインに入るため、複数の命令が同時に処理されます。 これは、L3キャッシュの1つのミス-メモリから直接ロードすること-が完了するまでに数百の命令が必要になることを意味します。 簡単に言えば、メモリからの読み取りは非常に遅いプロセスです。
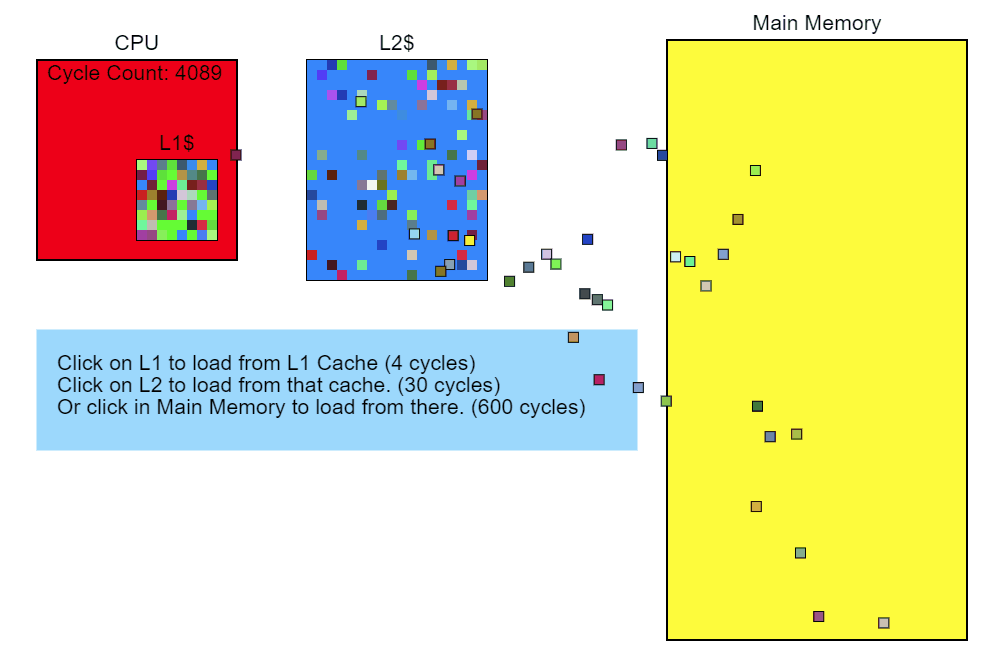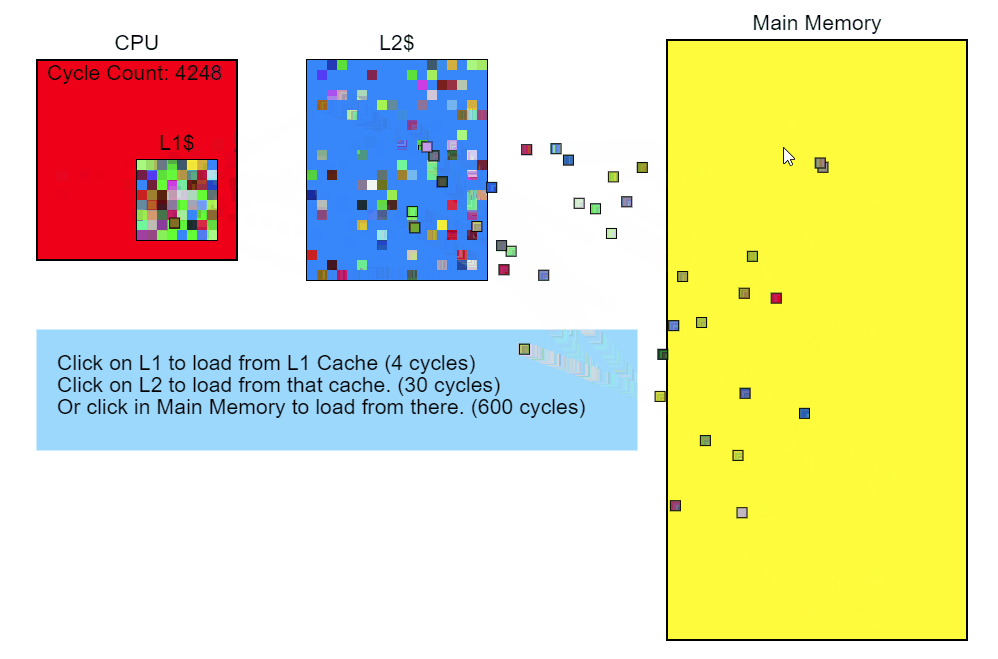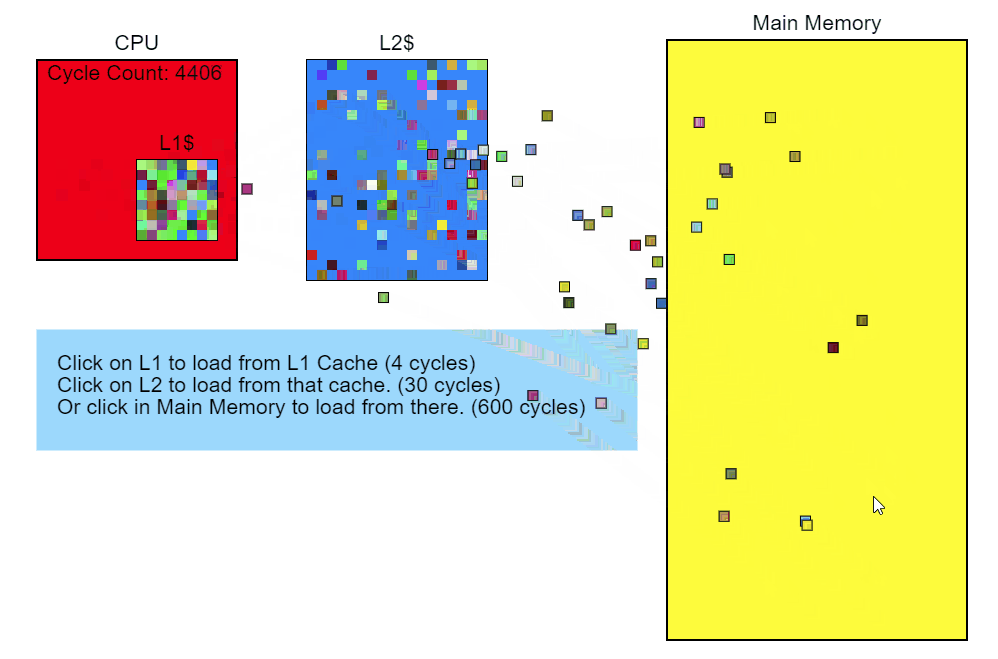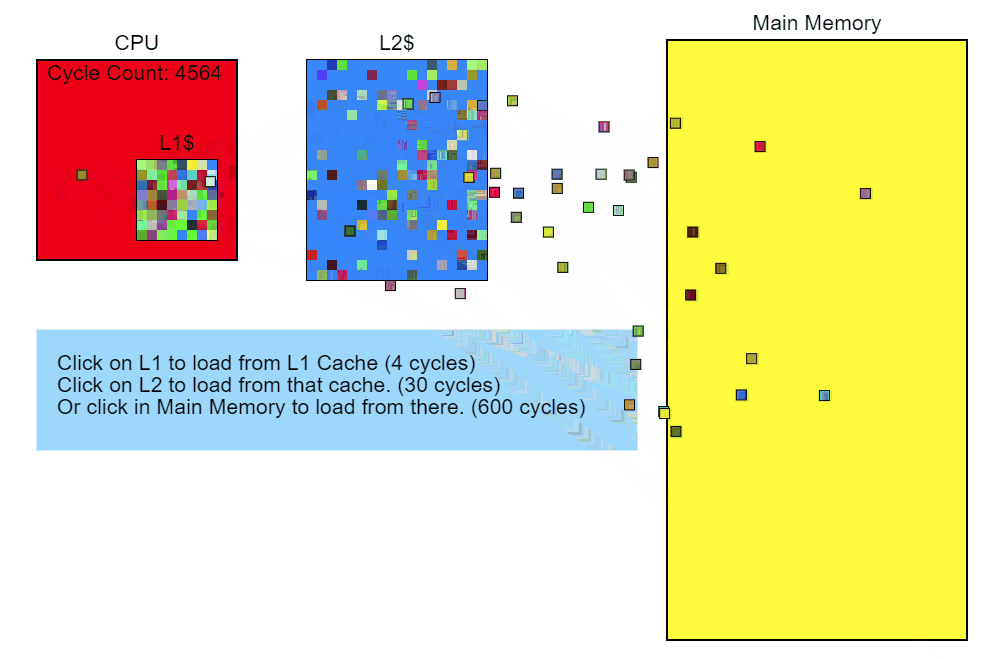
修飾子::更新()
そのため、メモリアクセスによりコードの実行が遅くなることがわかります。 戻って、この呼び出しにつながるコードの内容を確認しましょう。 コントロールプロファイラーは、 Node::Update()
実行が遅いことを示しており、スタックに関するサンプラープロファイルレポートから、 Modifier::Update()
関数が特にゆったりしていることが明らかです。 これから最適化を開始します。
void Modifier::Update() { for(Object* obj : mObjects) { Matrix4 mat = obj->GetTransform(); mat = mTransform*mat; obj->SetTransform(mat); } }
Modifier::Update()
は、オブジェクトへのポインターのベクトルをmTransform
、変換行列をmTransform
し、 mTransform
Modifier行列で乗算してから、この変換をオブジェクトに適用します。 上記のコードでは、変換はオブジェクトからスタックにコピーされ、乗算されてからコピーされます。
GetTransform()
単にmTransform
コピーを返しますが、 SetTransform()
は新しいマトリックスをmTransform
コピーし、このオブジェクトのmDirty
状態を設定します。
void SetDirty(bool dirty) { if (dirty && (dirty != mDirty)) { if (mParent) mParent->SetDirty(dirty); } mDirty = dirty; } void SetTransform(Matrix4& transform) { mTransform = transform; SetDirty(true); } inline const Matrix4 GetTransform() const { return mTransform; }
このオブジェクトの内部データレイヤーは次のようになります。
protected: Matrix4 mTransform; Matrix4 mWorldTransform; BoundingSphere mBoundingSphere; BoundingSphere mWorldBoundingSphere; bool m_IsVisible = true; const char* mName; bool mDirty = true; Object* mParent; };
わかりやすくするために、Nodeオブジェクトのメモリ内のエントリに色を付けました。
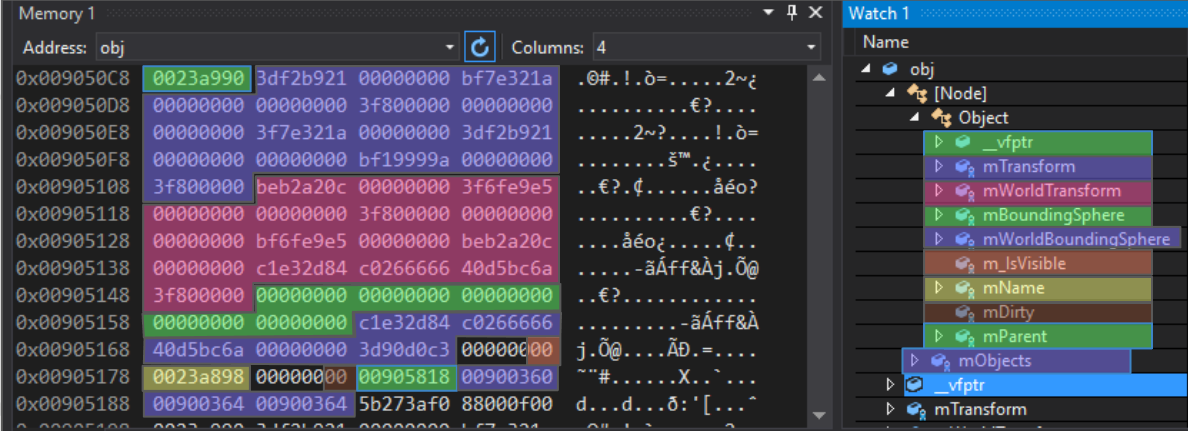
最初のエントリは仮想テーブルポインターです。 これは、C ++継承実装の一部です。この特定のポリモーフィックオブジェクトの仮想関数として機能する関数ポインターの配列へのポインター。 オブジェクト、ノード、修飾子、およびベースから継承されたクラスには、異なる仮想テーブルがあります。
この4バイトポインターの後に、浮動小数点数の64バイト配列が続きます。 mTransform
マトリックスの後ろには、 mTransform
マトリックスがmTransform
、次に2つの境界球がmTransform
ます。 次のエントリm_IsVisible
はシングルバイトで、4バイト必要です。 次のエントリは少なくとも4バイトの境界調整が必要なポインターであるため、これは正常です。 m_IsVisible
後に別のブール値m_IsVisible
入れると、利用可能な3バイトにパックされます。 次に、 mName
ポインター(4バイトのアライメント)、ブール値のmDirty
(同じく緩やかにパック)、次に親オブジェクトへのポインターがmDirty
ます。 これらはすべてオブジェクト固有のデータです。 後続のベクトルmObjects
は、すでにNodeベクトルを参照しており、このプラットフォームでは12バイトを占有しますが、他のプラットフォームではサイズが異なる場合があります。
Modifier::Update()
のコードを見ると、キャッシュミスの原因が何であるかがわかります。
void Modifier::Update() { for(Object* obj : mObjects) {
まず、注意してください:ベクトルmObjects
は、メモリに動的に割り当てられるオブジェクトへのポインターの配列です。 このベクトルの繰り返しは、キャッシュ(下図の赤い矢印)でうまく機能します。これは、ポインターが次々と続くためです。 いくつかのミスがありますが、それらはおそらくキャッシュで動作するように適合されていない何かを示しています。 また、各オブジェクトは新しいポインターでメモリに配置されるため、干渉はメモリ内のどこかにあるとしか言えません。

Objectへのポインターを取得したら、 GetTransform()
呼び出します。
Matrix4 mat = obj->GetTransform();
このインライン関数は、 mTransform
オブジェクトのコピーを返すだけなので、前の行はこれと同等です。
Matrix4 mat = obj->mTransform;
図からわかるように、 mObjects
配列内のポインターによって参照されるオブジェクトは、メモリー全体に散在しています。 新しいオブジェクトを追加してGetTransform()
を呼び出すmTransform
、 mTransform
にロードしてスタックにmTransform
すると、必ずキャッシュミスが発生します。 私が使用する機器では、キャッシュラインは64バイトを使用するため、運が良ければ、オブジェクトが64バイトの境界の4バイト前に開始されると、 mTransform
はすぐにキャッシュにロードされます。 ただし、 mTransform
をロードすると2つのキャッシュミスが発生する可能性が高い状況です。 Modifier::Update()
のサンプリングプロファイルから、マトリックスの配置が任意であることは明らかです。
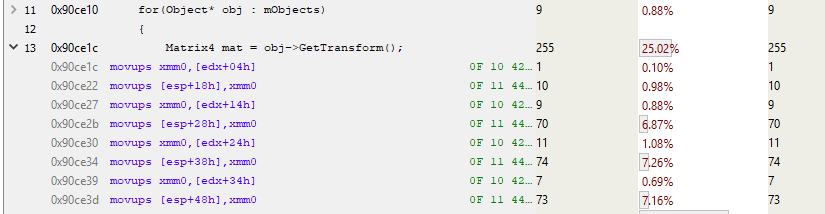
このスニペットでは、 edx
はオブジェクトの場所です。 そして、知っているように、 mTransform
はオブジェクトの開始の4バイト前に開始します。 したがって、このコードはmTransform
スタックにコピーします(MOVUPSは4つの非整列浮動小数点値をレジスタにコピーします)。 3つのMOVUPS命令への呼び出しの7%を支払います。 これは、MOVの場合にもキャッシュミスが発生することを示しています。 スタック上の最初のMOVUPSが他のMOVUPSに他の時間ほど時間がかからない理由はわかりません。 パイプライン化命令の特性により、「コスト」は後続のMOVUPに単純に転送されるように思えます。 しかし、いずれにせよ、メモリにアクセスするためのコストが高いことの証拠を受け取ったので、それを使って作業します。
void Modifier::Update() { for(Object* obj : mObjects) { Matrix4 mat = obj->GetTransform(); mat = mTransform*mat; obj->SetTransform(mat); } }
行列が乗算された後、 Object::SetTransform()
を呼び出します。これは、乗算の結果(スタックに新しく配置された)を取得し、Objectインスタンスにコピーします。 変換はすでにキャッシュされているためコピーは高速ですが、 mDirty
フラグを読み取るためSetDirty()
は低速であり、おそらくキャッシュにありません。 そのため、この1バイトをテストし、場合によっては決定するために、プロセッサは周囲の63バイトを読み取る必要があります。
おわりに
最後まで読んだら-よくできました! 特にアセンブラに慣れていない場合は、最初は難しいかもしれません。 しかし、コンパイラーが書いたコードでコンパイラーが何をするかを時間をかけて確認することを強くお勧めします。 これにはCompiler Explorerを使用できます。
サンプルコードのパフォーマンスの問題の主な原因はメモリアクセスポインターであるという証拠を集めました。 次に、メモリにアクセスするコストを最小限に抑え、パフォーマンスを再度測定して、改善が達成されたかどうかを確認します。 これが次回の予定です。