2018年の顔認識は誰も驚くことではありません -すべての生徒、おそらく男子生徒もそうしました。 ただし、 100万人のユーザーがいない場合は少し複雑になりますが 、
- 3億3000万のユーザーアカウント。
- 2,000万人のユーザーの写真が毎日アップロードされます。
- 1枚の写真の最大処理時間は0.2秒を超えてはなりません。
- 問題を解決するための機器の限られたボリューム。

この記事では、Odnoklassnikiソーシャルネットワーク上のユーザーの写真で顔認識システムを開発および起動した経験を共有し、AからZまでのすべてについて説明します。
- 数学的装置;
- 技術的な実装;
- 打ち上げ結果;
- およびStarFace株 、これは私たちの決定をPRするために使用していました。
挑戦する
Odnoklassnikiには3億3千万件以上のアカウントが登録されており、これらのアカウントには300億枚以上の写真が含まれています。
OKユーザーは1日に2,000万枚の写真をアップロードします。 1日あたり900万枚の写真に顔があり、合計2,300万の顔が検出されています。 つまり、少なくとも1つの顔を含む写真あたり平均2.5の顔。
ユーザーは写真に写っている人をマークする機会がありますが、通常は怠け者です。 アップロードされた写真に対するユーザーの認識と、ユーザーの写真に対するフィードバックの量を増やすために、写真内の友人の検索を自動化することにしました。
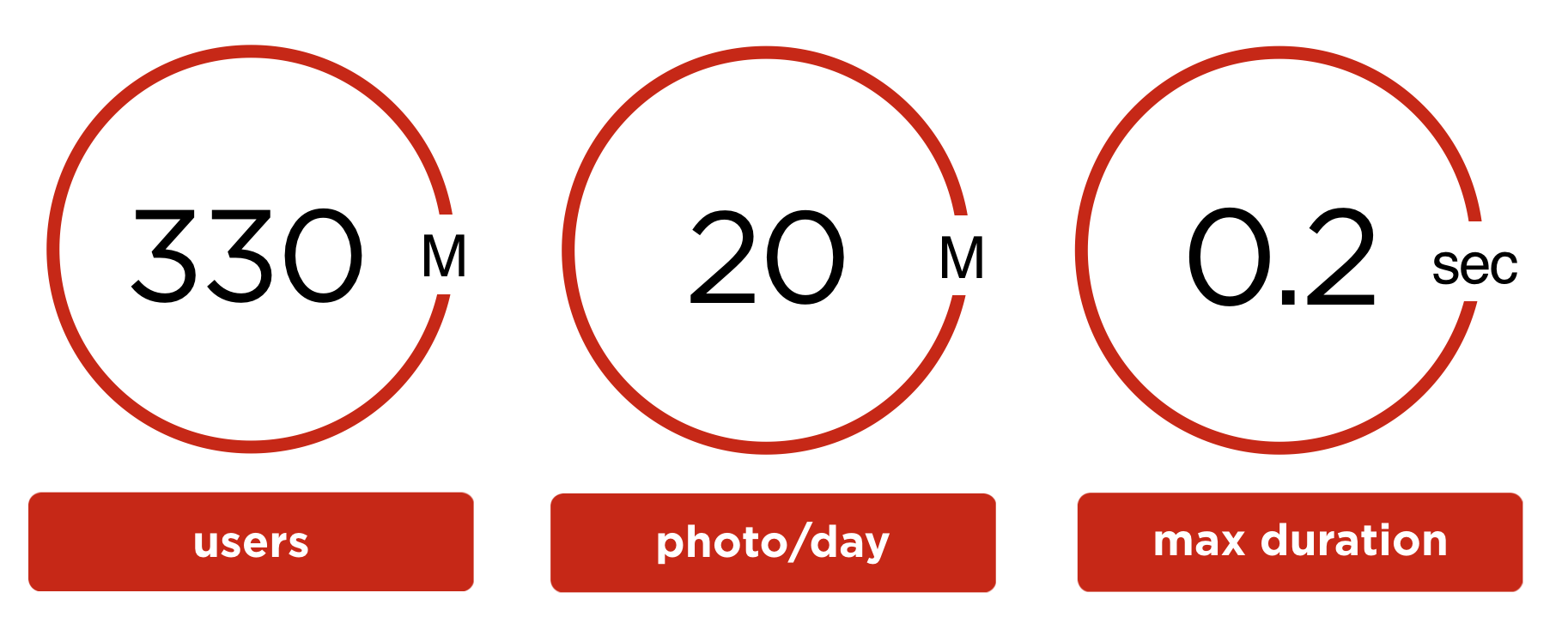
作者が写真をアップロードした後すぐに友人を確認するには、最悪の場合の写真処理は200ミリ秒に収まる必要があります。
社会認識システム
アップロードされた写真の顔認識
ユーザーは任意のクライアント(ブラウザまたはiOS、Androidのモバイルアプリケーション)から写真をダウンロードし、顔を見つけて顔を揃えることをタスクとするディテクターに到達します。
検出器の後、切り刻まれた前処理済みの顔は、ユーザーの顔の特徴的なプロファイルを構築するニューラルネットワーク認識に落ちます。 この後、最も類似したプロファイルがデータベースで検索されます。 プロファイルの類似度が境界値よりも大きい場合、ユーザーは自動的に検出され、写真に写っているという通知をユーザーに送信します。
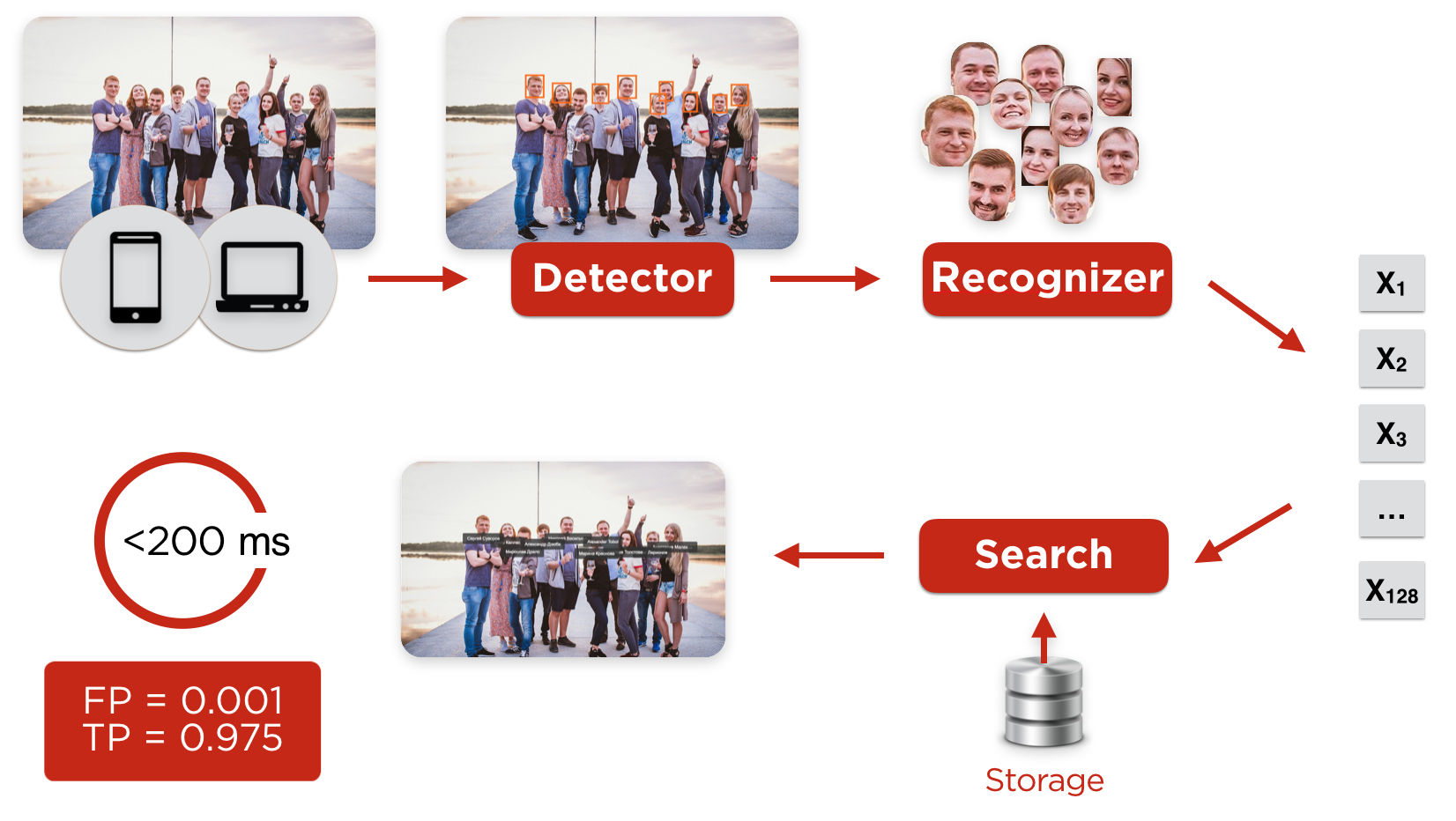
図1.写真内のユーザー認識
自動認識を開始する前に、各ユーザーのプロファイルを作成し、データベースに入力する必要があります。
ユーザープロファイルの作成
顔認識アルゴリズムの場合、1枚の写真、たとえばアバターだけで十分です。 しかし、このプロフィール写真にはプロフィール写真が含まれますか? ユーザーはアバターに星の写真を載せ、プロフィールにはミームがたくさんあるか、グループ写真のみが含まれます。

図2.難しいプロファイル
グループ写真のみで構成されるユーザープロフィールを考えます。
アカウントの所有者(図2)は、彼の性別と年齢、およびプロファイルが以前に作成された友人を考慮すると決定できます。
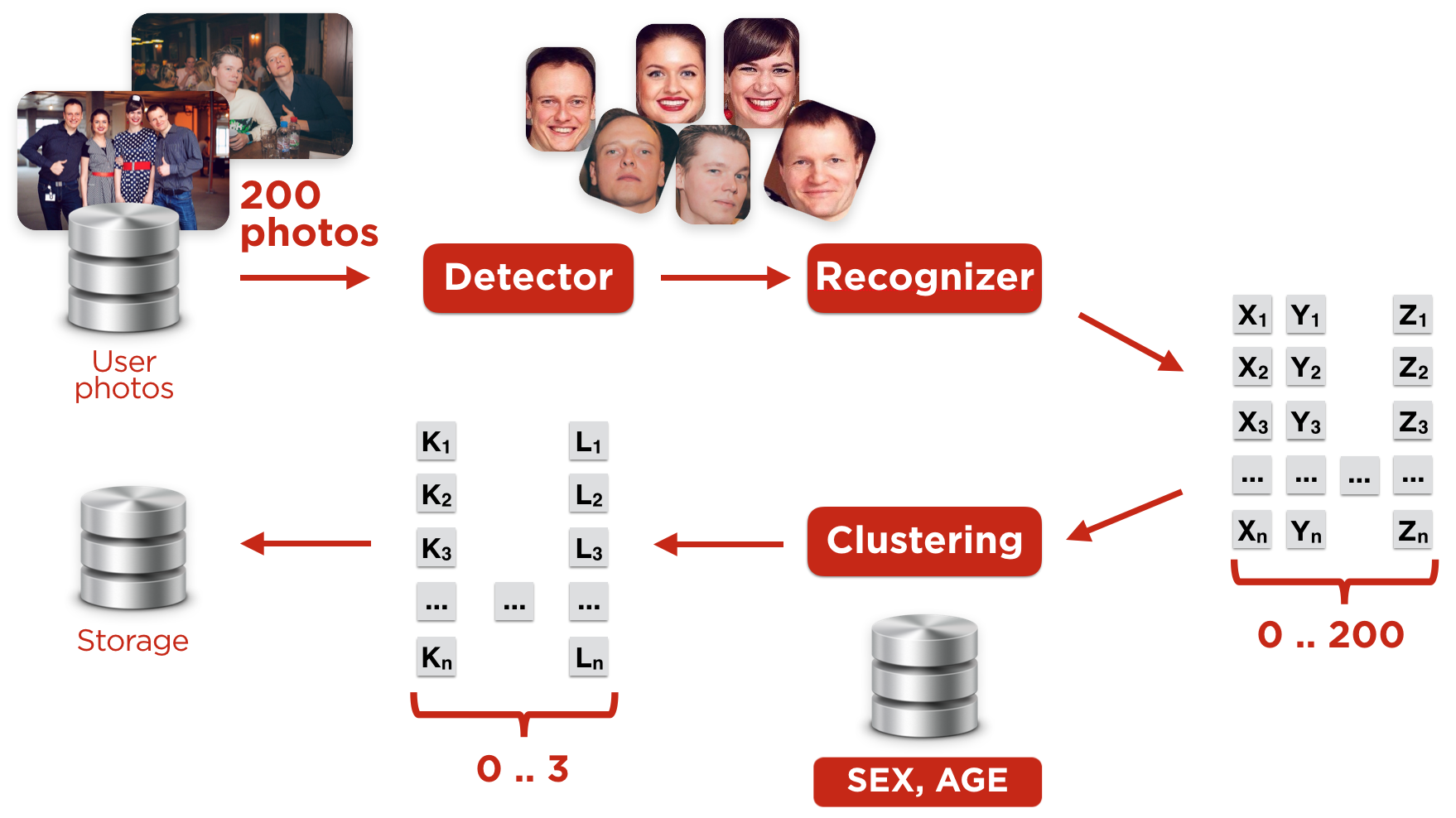
図3.ユーザープロファイルの作成
次のようにユーザープロファイルを作成しました(図3)。
1)最高品質のユーザー写真を選択する
写真が多すぎる場合は、最高の100枚しか使用していません。
写真の品質は以下に基づいて決定されました。
- 写真内のユーザーマークの存在(フォトピン)を手動で。
- 写真のメタ情報(携帯電話からアップロードされた写真、フロントカメラで撮影、休暇中など);
- 写真はアバターにありました
2)これらの写真で顔を探した
- 他のユーザーになっても怖くない(ステップ4で除外する)
3)特徴的な顔ベクトルが計算された
- そのようなベクトルは埋め込みと呼ばれます
4)クラスター化されたベクトル
このクラスタリングのタスクは、アカウントの所有者に属するベクトルのセットを判別することです。 主な問題は、写真に友人や親relativeがいることです。 クラスタリングには、DBScanアルゴリズムを使用します。
5)リードクラスターが決定されました
各クラスターについて、以下に基づいて重みを計算しました。
- クラスターサイズ;
- クラスターに埋め込みが構築される写真の品質。
- クラスターの人に取り付けられたフォトピンの存在;
- クラスター内の人の性別と年齢とプロファイルの情報との対応。
- 以前に計算された友人プロファイルへのクラスター重心の近接度。
クラスターの重みの計算に関係するパラメーターの係数は、線形回帰によって学習されます。 プロファイルの正直な性別と年齢は別の難しいタスクです。これについては後で説明します。
クラスターをリーダーと見なすには、その重みがトレーニングセットで計算された定数だけ、最も近い競合他社よりも大きいことが必要です。 リーダーが見つからない場合は、手順2に戻りますが、より多くの写真を使用します。 一部のユーザーについては、2つのクラスターを保存しました。 これは、ジョイントプロファイルで発生します。一部のファミリには共通のプロファイルがあります。
6)クラスターに埋め込まれた受信ユーザー
- 最後に、アカウント所有者の外観を特徴付けるベクター、つまり「ユーザーの埋め込み」を構築しています。
ユーザー埋め込みは、選択された(選択された)クラスターの重心です。
重心はさまざまな方法で構築できます。 数多くの実験を経て、最も単純なものに戻りました。クラスター内のベクトルの平均化です。
クラスターと同様に、ユーザーは複数の埋め込みを持つことができます。
反復中に、80億枚の写真を処理し、3億3,000万のプロファイルを反復処理し、3億のアカウントの埋め込みを作成しました。 平均して、26枚の写真を処理して1つのプロファイルを作成しました。 同時に、ベクターを作成するのに1枚の写真で十分ですが、写真が多いほど、作成されたプロファイルがアカウント所有者に属していることを確信できます。
友人に関する情報が利用できるようになると、クラスター選択の品質が向上するため、ポータルですべてのプロファイルを作成するプロセスは数回実行しました。
ベクターの保存に必要なデータの量は、約300 GBです。
顔検出器
顔検出器OKの最初のバージョンは、Viola-Jones方式に基づく検出器と特性が似ているサードパーティソリューションに基づいて2013年に発売されました。 5年の間、このソリューションは時代遅れであり、 MTCNNに基づく最新のソリューションは2倍の精度を示しています。 したがって、私たちはトレンドに従うことを決定し、畳み込みニューラルネットワーク(MTCNN)のカスケードを構築しました。
古い検出器を使用するために、CPUを備えた100台を超える「古い」サーバーを使用しました。 写真の顔を見つけるためのほとんどすべての最新のアルゴリズムは、GPUで最も効率的に機能する畳み込みニューラルネットワークに基づいています。 客観的な理由で、多数のビデオカードを購入する機会がありませんでした。 高い 鉱夫はすべてを買いました。 CPU上の検出器から開始することが決定されました(同じサーバーをスローしないでください)。
アップロードした写真から顔を検出するために、30台の車のクラスターを使用します(残りは 飲んだ スクラップに引き渡されます)。 ユーザーベクターの構築中の検出(アカウントに対する反復)は、クラウド内で優先度の低い1000個の仮想コアで実行します。 クラウドソリューションの詳細は、 Oleg Anastasievによるレポートに記載されています。One-cloud-OdnoklassnikiのデータセンターレベルのOSです 。
検出器の動作時間を分析するとき、このような最悪のケースに直面しました。トップレベルネットワークがカスケードの次のレベルにあまりにも多くの候補を渡し、検出器が長時間動作し始めます。 たとえば、このような写真の検索時間は1.5秒に達します。

図4.カスケードの最初のネットワークの後の多数の候補の例
このケースを最適化して、通常、写真には顔がほとんどないことを提案しました。 したがって、カスケードの最初の段階の後、この人がいる関連するニューラルネットワークの信頼度に依存して、200個以下の候補を残します。
このような最適化により、最悪の場合の時間が350ミリ秒、つまり4倍に短縮されました。
いくつかの最適化(たとえば、カスケードの最初の段階の後の非最大抑制をBlob検出に基づくフィルタリングに置き換える)を適用して、品質を損なうことなく検出器をさらに1.4倍オーバークロックしました。
しかし、進歩も止まっておらず、写真の顔を探すことがよりエレガントな方法で採用されました-FaceBoxesを参照してください。 近い将来、同様のものに移行することを排除しません。
顔認識
レコグナイザーシステムを開発する際、 Wide ResNet 、 Inception-ResNet 、 Light CNNなどのいくつかのアーキテクチャを試しました。
Inception-ResNetは、他のものよりも少し優れていることを示しましたが、私たちはそれに着手しました。
このアルゴリズムには、訓練されたニューラルネットワークが必要です。 インターネットで見つけたり、購入したり、自分でトレーニングしたりできます。 ニューラルネットワークのトレーニングには、トレーニングと検証が行われる特定のデータセット(データセット)が必要です。 顔認識はよく知られたタスクであるため、MSCeleb、VGGFace / VGGFace2、MegaFaceという既製のデータセットが既に存在します。 ただし、ここでは厳しい現実が登場します。顔識別タスク(および実際には一般的)における最新のニューラルネットワークの一般化能力には、多くの要望が残されています。
また、ポータルでは、顔は開いているデータセットにあるものとは大きく異なります。
- 別の年齢分布-写真に子供がいます。
- 民族グループの別の分布。
- 非常に低い品質と解像度の顔に出くわします(10年前に撮影した携帯電話の写真、グループ写真)。
3番目のポイントは、人為的に解像度を下げてjpegアーティファクトを適用することで簡単に克服できますが、残りは定性的にエミュレートできません。
したがって、独自のデータセットを作成することにしました。
試行錯誤によってセットを構築する過程で、次の手順に到達しました。
- 〜10万のオープンプロファイルから写真を取り出します
プロファイルをランダムに選択し、お互いに友好的な関係にある人の数を最小限にします。 この結果、データセットの各人物は1つのプロファイルのみに表示されると考えられます - 人のベクター(埋め込み)を構築します
埋め込みを構築するために、事前に訓練されたオープンソースニューラルネットワークを使用します( ここから取りました )。 各アカウント内のクラスター面
いくつかの明らかな観察:
- アカウントの写真に何人の人が写っているのかわかりません。 したがって、クラスター化ツールは、ハイパーパラメーターとしてクラスターの数を必要としません。
- 理想的には、同じ人物の顔に対して、非常に類似したベクトルが密な球状のクラスターを形成することを期待しています。 しかし、宇宙は私たちの願望を気にしておらず、実際には、これらのクラスターは複雑な形に忍び寄っています(例えば、メガネを着用し、クラスターを持たない人の場合、通常2つの血塊で構成されます) したがって、ここでは重心ベースの方法は役に立ちません。密度ベースを使用する必要があります。
これら2つの理由と実験結果から、 DBSCANが選択されました。 ハイパーパラメーターは手作業で選択され、目で検証されました。ここではすべてが標準です。 それらの最も重要なもの-scikit-learnの観点からのeps-については、アカウント内の人数に関する単純なヒューリスティックを思い付きました。
クラスターをフィルター処理します
データセットの汚染の主な原因とそれらとの戦い方:
- 異なる人の顔が1つのクラスターに統合される場合があります(ニューラルネットワーク偵察機の欠陥とDBSCANの密度ベースの性質のため)。
最も簡単な再保険は私たちを助けてくれました。クラスター内の2人以上が同じ写真から来た場合、念のためそのようなクラスターを捨てました。
これは、セルフィーのコラージュが好きな人はデータセットにアクセスできなかったが、偽の「合併」の数が大幅に減少したため、価値があったことを意味します。 - 反対も起こります:同じ顔がいくつかのクラスターを形成します(たとえば、メガネとなし、メイクとなしなどで写真がある場合)。
常識と実験により、次のことがわかりました。 クラスターのペアの重心間の距離を測定します。 特定のしきい値を超えている場合-十分に大きいが、しきい値を超えていない場合は結合します-クラスターの1つを罪から遠ざけます。 - 検出器が誤っており、クラスタに顔が表示されていないことが起こります。
幸いなことに、ニューラルネットワークレコグナイザーは、このような誤検出を簡単に除外する必要があります。 詳細については、以下をご覧ください。
- 異なる人の顔が1つのクラスターに統合される場合があります(ニューラルネットワーク偵察機の欠陥とDBSCANの密度ベースの性質のため)。
- 何が起こったのかについてニューラルネットワークを訓練し、それをポイント2に戻します
準備が整うまで3〜4回繰り返します。
徐々に、ネットワークは良くなり、最後の繰り返しでは、発見的手法でのフィルタリングの必要性は完全になくなります。
多様性が高いほど良いと判断したため、新しいデータセット(3.7M人、77K人、コード名-OKFace)に何か他のものを混ぜます。
他の最も有用なものはVGGFace2でした -非常に大きく複雑です(ターン、照明)。 いつものように、Googleで見つけた有名人の写真で構成されています。 驚くことではないが、それは非常に「汚い」。 幸いなことに、OKFaceでトレーニングされたニューラルネットワークでクリーニングするのは簡単なことです。
損失関数
学習の埋め込みに適した損失関数は、まだ未解決のタスクです。 次の位置に依存してアプローチしようとしました:損失関数がトレーニング後のモデルの使用方法にできるだけ近くなるように努力する必要があります
そして、当社のネットワークは最も標準的な方法で使用されます。
人物が写真に写っているときに、埋め込み 候補者のプロファイルからの重心と比較されます(ユーザー自身+彼の友人) コサイン距離による。 もし 、写真でそれを宣言-候補者番号 。
したがって、次のことを行います。
- 「正しい」候補者 、 しきい値を超えました ;
- 残りのために-より低かった できれば余裕を持って 。
誰もが経験的にそれを行うので、この理想からの逸脱は広場によって罰せられます。 式言語でも同じ:
そして、重心自体 -これらはニューラルネットワークの単なるパラメーターであり、他のすべてと同様に勾配降下法によって訓練されます。
この損失関数には独自の問題があります。 まず、ゼロから学習するのには適していません。 第二に、2つのパラメーターを選択します- そして -かなり疲れます。 それでも、追加のトレーニングを使用することで、他の既知の機能であるCenter Loss 、 Contrastive-Center Loss 、 A-Softmax(SphereFace) 、 LMCL(CosFace)よりも高い精度を達成できました。
そして、それは価値がありましたか?
| Lfw | OKFace、テストセット | |||
| 精度 | TP@FP0.001 | 精度 | TP@FP0.001 | |
| に | 0.992 + -0.003 | 0.977 + -0.006 | 0.941 + -0.007 | 0.476 + -0.022 |
| 後 | 0.997 + -0.002 | 0.992 + -0.004 | 0.994 + -0.003 | 0.975 + -0.012 |
表の数値-10回の測定の平均結果+-標準偏差
私たちにとって重要な指標はTP @ FPです:一定の割合の誤検知で認識される個人の割合(ここでは-0.1%)。
1000分の1のエラー制限と、データセットでのニューラルネットワークの追加トレーニングなしでは、ポータル上の顔の半分しか認識できませんでした。
誤検知の最小化
検出器は、顔のない部分を見つけることがあり、ユーザーの写真でこれを行うことがよくあります(誤検出の4%)。
そのような「ガベージ」がトレーニングデータセットに入ると、かなり不快になります。
バラの花束やじゅうたんのテクスチャーに「友だちをマーク」するようにユーザーに強く要求するのは非常に不快です。
問題を解決することは可能です、そして、最も明白な方法はより多くの非人を集めて、ニューラルネットワーク認識装置を通して彼らを運転することです。
いつものように、私たちは手早く松葉杖から始めることにしました
- 私たちの意見では、個人がすべきではない画像をインターネットから借りています

- ランダムクロップを行い、それらの埋め込みを構築し、クラスター化します。 クラスターは14個しかありませんでした。
- テストされた「顔」の埋め込みがいずれかのクラスターの重心に近い場合、「顔」は顔ではないと見なします。
- 私たちの方法がうまく機能する方法を喜ぶ
- 説明したスキームは、埋め込みの上に2層ニューラルネットワーク(非表示層に14ユニット)で実装されており、少し悲しいことに気付きます。
ここで興味深いのは、認識ネットワークが非個人の多様性全体を埋め込みスペースのいくつかの領域に送信することですが、誰もこの方法を教えていません。
誰もが嘘をついたり、ソーシャルネットワークの実際の年齢と性別を決定したりする
ユーザーは多くの場合、年齢を示したり、誤って示したりしません。 したがって、ユーザーの年齢は友達グラフを使用して推定されます。 ここでは、友人の年齢のクラスター化が役立ちます。一般的なケースでは、ユーザーの友人の年齢の最大のクラスターでのユーザーの年齢と、性別、名前、姓の決定が役立ちました。
Vitaly Khudobakhshovはこのことについて次のように語っています。「 ソーシャルネットワークで人の年齢を調べる方法、たとえ彼が示されていなくても 」
ソリューションのアーキテクチャ
OKの内部インフラストラクチャ全体がJavaで構築されているため、すべてのコンポーネントをJavaでラップします。 検出器と認識器の推論は、Java APIを介してTensorFlowを実行しています。 Detectorは、要件を満たし、既存のハードウェアで実行されるため、CPU上で実行されます。 Recognizerの場合、72個のGPUカードをインストールしました。Inception-ResNetを実行することは、リソースの観点からCPU上ではお勧めできません。
Cassandraは、ユーザーベクトルを保存するデータベースとして使用します。
すべてのポータルユーザーのベクターの合計ボリュームは約300 GBなので、ベクターにすばやくアクセスできるようにキャッシュを追加します。 キャッシュはオフヒープに実装されています。詳細については、 Andrey Panginによる記事「 Javaでの共有メモリとオフヒープキャッシュの使用 」 を参照してください。
構築されたアーキテクチャは、ユーザープロファイルを反復処理する場合、1日に最大10億枚の写真に耐えることができますが、アップロードされた新しい写真の処理は1日あたり2,000万枚まで続きます。

図6.ソリューションのアーキテクチャ
結果
その結果、限られたリソースで良好な結果をもたらすソーシャルネットワークからの実際のデータでトレーニングされたシステムを撮影しました。
実際のOKプロファイルに基づいて構築されたデータセットの認識品質は、FP = 0.1%でTP = 97.5%でした。 1枚の写真の平均処理時間は120ミリ秒で、99パーセンタイルは200ミリ秒に収まります。 システムは自己学習型であり、写真内でユーザーがタグ付けされるほど、プロファイルがより正確になります。
写真をダウンロードした後、ユーザーは写真を見つけて通知を受け取り、写真で自分自身を確認するか、写真が気に入らない場合は削除できます。

自動認識により、写真のマークに関するテープのイベントの印象が2倍に増加し、これらのイベントのクリック数が3倍に増加しました。 新しい機能に対するユーザーの関心は明らかですが、UXおよびStarfaceなどの新しいアプリケーションポイントを改善することで、アクティビティをさらに増やす予定です。
フラッシュモブスターフェイス
ソーシャルネットワークのユーザーに新しい機能を紹介するために、OKは競争を発表しました:ユーザーはロシアのスポーツスターと写真をアップロードし、Odnoklassnikiでアカウントを維持しているビジネスと人気のブロガーを表示し、アバターのバッジまたは有料サービスのサブスクリプションを受け取ります。 詳細はこちら: https : //insideok.ru/blog/odnoklassniki-zapustili-raspoznavanie-lic-na-foto-na-osnove-neyrosetey
アクションの最初の数日間、ユーザーはすでに有名人の写真を1万枚以上ダウンロードしています。 彼らは、セルフィーと星の写真、ポスターの背景の写真、そしてもちろん「フォトショップ」をレイアウトしました。 VIPステータスを受け取ったユーザーの写真:

計画
ほとんどの時間は検出器に費やされるため、速度のさらなる最適化を検出器で正確に実行する必要があります。それを交換するか、GPUに転送します。
品質が大幅に向上する場合は、異なる認識モデルの組み合わせを試してください。
ユーザーの観点からは、次のステップはビデオ内の人々を認識することです。 また、クローンについて苦情を申し立てることができる、ネットワーク上でのプロファイルのコピーの可用性についてユーザーに通知する予定です。
コメントで顔認識を使用するためのアイデアを送信します。