
ディープラーニングによる翻訳バックグラウンドの削除 。
機械学習の分野での過去数年間の作業で、機械学習に基づいて実際の製品を作成したいと考えました。
数か月前、 Fast.AIのすばらしいコースを修了した後、星が一致し、私たちはそのような機会を得ました。 ディープラーニングテクノロジの現代の進歩により、以前は不可能と思われていたことの多くを実行できるようになり、実装プロセスをこれまで以上にアクセスしやすくした新しいツールが登場しました。
次の目標を設定します。
- ディープラーニングスキルを向上させます。
- AIベースの製品実装スキルを向上させます。
- 市場の見通しを持つ有用な製品を作成します。
- 楽しんでください(そしてユーザーが楽しんでください)。
- 経験を共有します。
上記に基づいて、次のようなアイデアを検討しました。
- まだ誰も実装(または適切に実装)できていません。
- 計画と実装はそれほど複雑ではありません。1週間に1営業日の負荷で2〜3か月の作業をプロジェクトに割り当てました。
- シンプルで魅力的なユーザーインターフェイスを備えています。デモ用だけでなく、人々が使用する製品を作りたかったのです。
- トレーニングに利用できるデータがあります-機械学習の専門家なら誰でも知っているように、データはアルゴリズムよりも高価な場合があります。
- 高度なディープラーニングメソッド(クラウドプラットフォームでGoogle、Amazonまたはその友人によってまだ市場に出されていない)を使用しますが、高度ではありません(インターネットでいくつかの例を見つけることができます)。
- 彼らは、製品を市場に出すのに十分な結果を達成する可能性があります。
私たちの初期の仮定は、この分野は私たちに非常に近いので、何らかの医療プロジェクトを引き受けることでした。そして、私たちは、ディープラーニングに適した膨大な数のトピックがあると感じました。 しかし、データの収集に問題が生じ、場合によっては法律や規制に問題が生じることに気付きました。これは、自分自身のタスクを複雑にしたくないという私たちの願望に反していました。 そのため、画像の背景を削除する製品を作成するために、プランBに固執することにしました。
何らかの種類の「マーカー」および境界検出技術を使用する場合、背景の削除は手動またはほぼ手動で簡単に実行できるタスクです(Photoshop、およびPower Pointにもそのようなツールがあります)。 例を参照してください 。 ただし、完全に自動化されたバックグラウンド除去はかなり難しいタスクであり、私たちが知る限り、許容できる結果を達成した製品はまだありません( 試している人はいますが)。
どのような背景を削除しますか? この質問は重要であることが判明しました。モデルがオブジェクト、角度などに関してより具体的であるほど、背景と前景の分離の品質が高くなるためです。 作業を開始したとき、私たちは広範に考えました。各タイプの画像の前景と背景を自動的に識別する包括的な背景除去ツールです。 しかし、最初のモデルをトレーニングした後、特定の画像セットに重点を置く方が良いことに気付きました。 したがって、私たちは自分撮りと人々のポートレートに焦点を合わせることにしました。

(ほぼ)人の写真の背景を削除します。
Selfieは写真です:
- 特徴的で指向性のある前景(1つまたは複数の「人」)を使用して、オブジェクト(顔+上半身)と背景を適切に分離します。
- 一定の角度で、常に同じオブジェクト(人)で。
これらの主張を踏まえ、調査と実装に取り組み、使いやすいワンクリックバックグラウンド削除サービスを作成するために何時間ものトレーニングを費やしました。
作業の大部分はモデルを教えることでしたが、適切な実装の重要性を過小評価することはできませんでした。 優れたセグメンテーションモデルは、まだ画像分類モデル(たとえばSqueezeNet )ほどコンパクトではなく、サーバー側とブラウザー側の両方で実装オプションを積極的に研究しています。
製品の実装プロセスについて詳しく知りたい場合は、 サーバー側とクライアント側の実装に関する投稿をご覧ください。
モデルとそのトレーニングのプロセスについて学びたい場合は、ここから読み続けてください。
セマンティックセグメンテーション
ディープラーニングとコンピュータービジョンのタスクを研究するとき、私たちの前のタスクを思い起こさせるとき、私たちにとって最良の選択肢はセマンティックセグメンテーションのタスクであることは容易に理解できます。
深さで分割するなど、他の戦略もありますが、目的には十分に成熟していないように思われました。
セマンティックセグメンテーションは、コンピュータービジョンのよく知られたタスクであり、オブジェクトの分類と検出とともに、3つの最も重要なタスクの1つです。 実際、セグメンテーションは、各ピクセルをクラスに分散するという意味での分類タスクです。 分類モデルや画像検出モデルとは異なり、セグメンテーションモデルは画像の「理解」を実証します。つまり、「この画像に猫がいる」というだけでなく、猫がピクセルレベルでどこにいるかを示します。
では、セグメンテーションはどのように機能しますか? よりよく理解するために、この分野での初期の研究のいくつかを研究する必要があります。
最初のアイデアは、VGGやAlexnetなどの初期の分類ネットワークの一部を適応させることでした。 VGG(Visual Geometry Group)は2014年に画像を分類するための高度なモデルでしたが、そのシンプルで明確なアーキテクチャにより、今日でも非常に便利です。 VGGの初期の層を調べると、高い活性化が分類に固有のものであることがわかります。 より深い層はさらに強力な活性化を持っていますが、それでも繰り返しのプーリングアクションのために本質的にひどいです。 これらすべてを念頭に置いて、いくつかの修正を加えた分類ベースのトレーニングを使用してオブジェクトを検索/セグメント化することもできると仮定されました。
セマンティックセグメンテーションの初期の結果は、分類アルゴリズムとともに現れました。 この投稿では、VGGを使用して得られた大まかなセグメンテーション結果を確認できます。

より深い層からの結果:
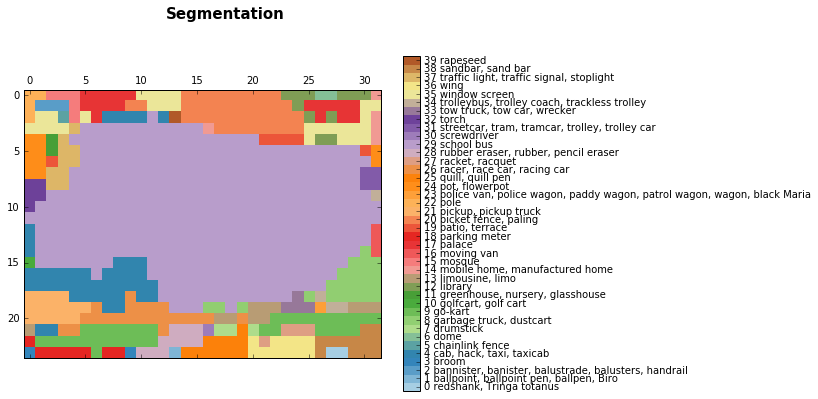
バス画像のセグメンテーション、ライトパープル(29)-これはスクールバスクラスです。
バイリニアリサンプリング後:
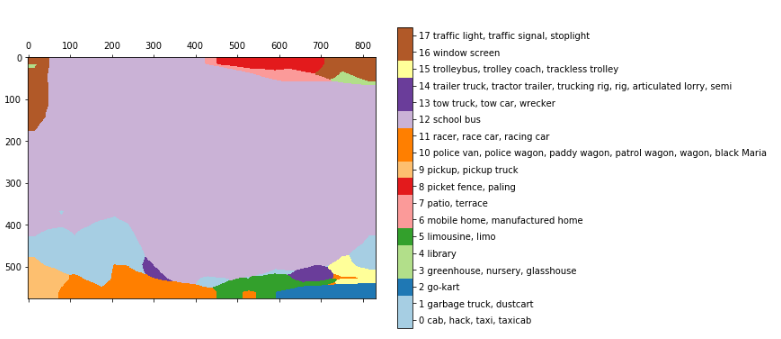
これらの結果は、完全に接続されたレイヤーを元の形に単純に変換(またはメンテナンス)することで得られ、その空間特性を維持し、完全な畳み込みニューラルネットワークを取得します。 上記の例では、画像768 * 1024をVGGにロードし、レイヤー24 * 32 * 1000を取得します。24* 32はプーリング後の画像(それぞれ32)、1000は上記を取得できるimage-netクラスの数ですセグメンテーション。
予測を改善するために、研究者は単純にオーバーサンプリングのあるバイリニアレイヤーを使用しました。
FCNでは、著者は上記のアイデアを改善しました。 オーバーサンプリングの頻度に応じて、FCN-32、FCN-16、FCN-8と呼ばれるより豊かな解釈を得るためにいくつかのレイヤーを接続しました:
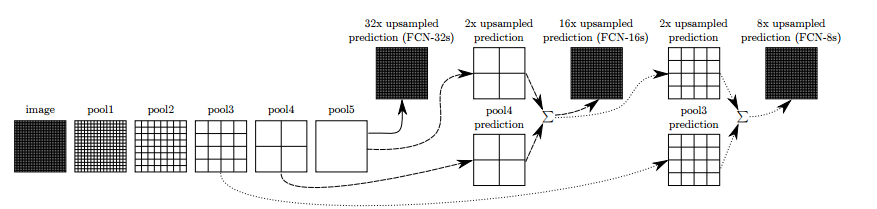
レイヤー間にスキップ接続を追加することで、元の画像のより詳細なエンコードを予測することができました。 さらなるトレーニングは結果をさらに改善しました。
この方法は、考えられるほどひどく見えず、ディープラーニングによるセマンティックセグメンテーションが本当に可能性があることを証明しました。

FCN結果。
FCNはセグメンテーションの概念を明らかにし、研究者はこのタスクのために異なるアーキテクチャをテストすることができました。 基本的な考え方は変わっていません。よく知られたアーキテクチャ、オーバーサンプリング、スループット接続の使用は、最近のモデルでもまだ存在しています。
この分野の成果については、 こちら 、 こちら 、 こちらをご覧ください 。 また、ほとんどのアーキテクチャにはエンコーダーデコーダー方式があることに気付くかもしれません。
プロジェクトに戻る
いくつかの調査を行った後、FCN、 Unet、およびTiramisuの 3つのモデルを利用できました。これらは「エンコーダーデコーダー」などの非常に深いアーキテクチャです。 また、mask-RCNNメソッドについてもいくつか考えましたが、その実装はプロジェクトの範囲外でした。
FCNは、その結果が望みどおりではなかったため(出発点としても)、関連性があるとは思われませんでしたが、他の2つのモデルは良い結果を示しました:CamVid データセットを使用したUnetとTiramisuの主な利点は、コンパクトさと速度でした。 Unetは実装が非常に簡単でした(ケラスを使用しました)が、ティラミスも非常に実現可能でした。 何かを始めるために、ジェレミーハワードのディープラーニングコースの最後のレッスンで説明した優れたティラミス実装を使用しました。
いくつかのデータセットでこれら2つのモデルのトレーニングを開始しました。 ティラミスを最初に試した後、モデルは画像の鋭いエッジをキャプチャできるため、その結果は非常に大きな可能性を秘めていました。 一方、Unetは十分ではなく、結果は少しぼやけていました。

ぼかしUnet。
データ
モデルを決定したら、適切なデータセットを探し始めました。 セグメンテーション用のデータは、分類用、または検出用のデータほど一般的ではありません。 さらに、画像を手動でインデックス化することはできませんでした。 最も人気のあるセグメンテーションデータセットは、 COCOでした。これには、90カテゴリの約8万枚の画像、20クラスの1万1千枚のVOCパスカル 、および最近のADE20Kが含まれます。
COCOには、興味のある「人」クラスの画像がはるかに多く含まれているため、COCOを使用することにしました。
私たちのタスクを考えると、私たちは自分に関連する画像のみを使用するか、より一般的なデータセットを使用するかを考えました。 一方では、多数の画像とクラスを持つより一般的なデータセットを使用すると、モデルがより多くのシナリオとタスクに対処できるようになります。 一方、夜間トレーニングでは、約15万枚の画像を処理できました。 モデルにCOCOデータセット全体を提供すると、各画像が2回(平均)表示されるため、データセットを少しトリミングする方が適切です。 さらに、タスクに合わせてモデルがよりシャープになります。
言及する価値のある別のポイント:ティラミスモデルはもともとCamVidデータセットでトレーニングされていましたが、これにはいくつかの欠点があり、その主なものは画像の強い均一性です:車から作られた道路の写真です。 理解できるように、このようなデータセットのトレーニング(人が含まれている場合でも)を行ってもメリットはありませんでした。

CamVidデータセットからの画像。
COCOデータセットにはかなり単純なAPIが付属しており、どのオブジェクトがどの画像に含まれているかを正確に知ることができます(90の定義済みクラスによる)。
いくつかの実験の後、データセットを希釈することにしました。最初は、人物が写っている画像のみが除外され、4万枚の写真が残りました。 その後、彼らはすべての画像を数人で破棄し、1〜2人の写真のみを残しました。当社の製品はこのような状況に合わせて設計されているためです。 最後に、人が20%から70%の領域を占める画像のみを残し、小さすぎる人や奇妙な怪物の写真を削除しました(残念ながら、すべてを削除することはできませんでした)。 最終的なデータセットは11,000枚の画像で構成されており、この段階では十分であると感じました。

左:適切な画像。 中央:参加者が多すぎます。 右:オブジェクトが小さすぎます。
モデルティラミス
ティラミスモデルの完全な名前(「100ティラミスレイヤー」)は巨大なモデルを意味しますが、実際には非常に経済的で、900万個のパラメーターしか使用しません。 これに対して、VGG16は1億3,000万を超えるパラメーターを使用します。
Tiramisuモデルは、すべてのレイヤーが相互接続されている最新の画像分類モデルであるDenseNetに基づいています。 さらに、Unetの場合のように、レイヤーをリサンプリングするために、ティラミスにスルー接続が追加されます。
覚えていると思いますが、このアーキテクチャはFCNで提示された考え方と一致しています。分類のアーキテクチャを使用し、最適化のためにスループット接続をリサンプリングし、追加します。
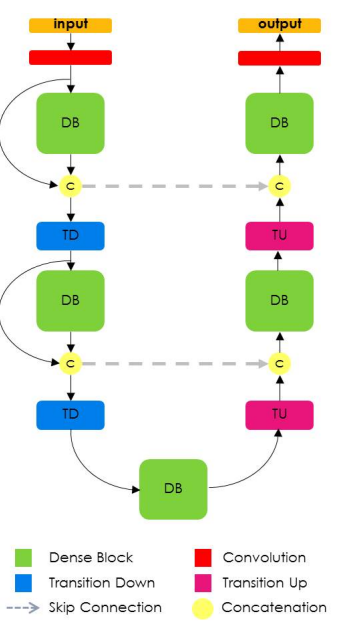
これがティラミスアーキテクチャの外観です。
DenseNetモデルはResnetモデルの自然な進化と考えることができますが、Densenetは次のレイヤーまで各レイヤーを「記憶」する代わりに、モデル全体のすべてのレイヤーを記憶します。 このような接続は高速道路接続と呼ばれます。 これにより、「成長率」(成長率)と呼ばれるフィルターの数が増加します。 ティラミスの成長率は16です。つまり、1072個のフィルターの層に達するまで、各層に16個の新しいフィルターを追加します。 100層のティラミスモデルであるため、1,600層が期待できますが、オーバーサンプリングレイヤーは一部のフィルターを破棄します。
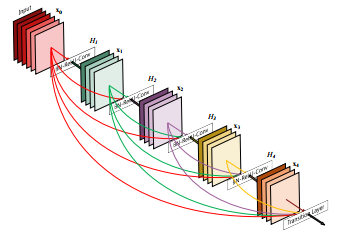
Densenetモデル図-初期のフィルターはモデル全体に積み重ねられます。
トレーニング
元のドキュメントに記載されているスケジュールに従ってモデルをトレーニングしました。標準クロスエントロピー損失、1e-3の学習係数とわずかな減衰を持つRMSPropオプティマイザーです。 11,000枚の画像を3つの部分に分割しました:トレーニング用70%、検証用20%、テスト用10%。 以下のすべての画像は、テストデータセットから取得したものです。
トレーニングスケジュールをソースドキュメントのスケジュールと一致させるために、サンプリング期間を500イメージに設定します。 また、ドキュメントよりもはるかに多くのデータでトレーニングしたため、結果が改善されるたびにモデルを定期的に保存できました(この記事で使用したCamVidデータセットには1,000枚未満の画像が含まれていました)。
さらに、背景と人間の2つのクラスのみを使用してモデルをトレーニングし、元のドキュメントには12のクラスがありました。 最初は、データセットのいくつかのクラスでCOCOをトレーニングしようとしましたが、これはより良い結果につながらないことに気付きました。
データの問題
データセットのいくつかの欠陥により、評価が低下しました。
- 動物 。 私たちのモデルは時々動物を分割しました。 これは、もちろん、低いIoU(結合に対する交差、結合と結合の比率)につながります。 動物をメインクラスまたは別のクラスに追加すると、おそらく結果に影響します。
- 体の部分 。 データセットをプログラムでフィルタリングしたため、人のクラスが本当に人であり、腕や脚などの身体の一部ではないかどうかを判断できませんでした。 これらの画像は私たちにとって興味のないものでしたが、それでもあちこちで発生しました。

動物、身体の一部、携帯物。 - ポータブルオブジェクト 。 データセット内の多くの画像はスポーツに関連しています。 野球のバット、テニスラケット、スノーボードはいたるところにありました。 私たちのモデルはどういうわけか「混乱」しており、セグメント化の方法を理解していません。 動物の場合と同様に、私たちの意見では、それらをメインクラスの一部として(または別のクラスとして)追加すると、モデルの改善に役立ちます。

オブジェクトを持つスポーツ画像。 - 大まかな地上データ 。 COCOデータセットには、ピクセルごとではなく、ポリゴンを使用して注釈が付けられました。 これで十分な場合もありますが、場合によっては、制御データが「粗すぎる」ため、モデルが微妙な点を学習できない場合があります。

画像自体と(非常に)大まかな制御データ。
結果
理想的ではありませんが、結果は満足のいくものでした。テストデータセットで84.6のIoUを達成しましたが、最新の成果は85 IoUの値です。 ただし、特定の値はデータセットとクラスによって異なります。 ほとんどのモデルが簡単に90 IoUを達成する家庭や道路など、本質的にセグメント化が容易なクラスがあります。 より難しいクラスは木と人で、ほとんどのモデルで約60 IoUの結果が得られます。 そのため、ネットワークが1つのクラスと限られたタイプの写真に集中できるようにしました。
私たちの作品はまだ「リリースの準備ができている」とは思っていませんが、写真の約50%が良い結果をもたらすので、私たちの成果をやめて議論する時が来たと信じています。
アプリの感触をつかむのに役立つ良い例をいくつか示します。

画像-制御データ-結果(テストデータセットから)。
デバッグとロギング
デバッグは、ニューラルネットワークを学習する上で非常に重要な部分です。 作業の最初に、すぐにビジネスに取り掛かることは非常に魅力的でした-データとネットワークを取得し、トレーニングを開始し、何が起こるかを見てください。 ただし、すべてのステップを追跡し、各ステップで結果を調べることが非常に重要であることがわかりました。
一般的な問題と解決策は次のとおりです。
- 初期の問題 。 モデルは学習を開始できません。 これは、たとえば、一部のデータの正規化を忘れた場合など、何らかの内部問題または前処理エラーが原因である可能性があります。 いずれにせよ、結果の単純な視覚化は非常に便利です。 このトピックに関する良い投稿があります。
- ネットワーク自体のデバッグ 。 重大な問題がない場合、トレーニングは事前に定義された損失とメトリックから始まります。 セグメンテーションでは、主な基準はIoU-交差と結合の比率です。 モデルの(クロスエントロピーの損失ではなく) IoUを主要な基準として使用するために、いくつかのセッションが必要でした 。 別の便利な方法は、各サンプリング期間でモデルの予測を表示することです。 これは、機械学習モデルのデバッグに関する優れた記事です。 IoUはケラの標準的なメトリック/損失ではありませんが、インターネットなどで簡単に見つけることができます。 また、この要点を使用して、各サンプリング期間の損失といくつかの予測をプロットしました。
- 機械学習のバージョン管理 。 モデルを訓練するとき、多くのパラメーターがあり、それらのいくつかは非常に複雑です。 私たちはすべての構成を熱心に修正したことを除いて、完璧な方法をまだ見つけていなかったと言わなければなりません(そして、kerasコールバックで最適なモデルを自動的に保存しました、下記参照)。
- デバッグツール 上記のすべてを行った後、すべてのステップで作業を分析することができましたが、困難がないわけではありません。 したがって、最も重要な手順は、上記の手順を組み合わせてデータをJupyter Notebook(分析レポートを作成するためのツール)にアップロードすることでした。これにより、各モデルと各画像を簡単にダウンロードし、結果をすばやく調べることができました。 したがって、モデル間の違いを確認し、落とし穴やその他の問題を検出することができました。
以下は、パラメーター設定と追加トレーニングによって達成されたモデルの改善例です。

最高のIoU結果でモデルを保存するために(作業を簡単にするために、Kerasは非常に良いコールバックを作成できます):
callbacks = [keras.callbacks.ModelCheckpoint(hist_model, verbose=1,save_best_only =True, monitor= 'val_IOU_calc_loss'), plot_losses]
コードエラーの通常のデバッグに加えて、モデルエラーは「予測可能」であることがわかりました。 たとえば、体としてカウントされない体の部分の「カットオフ」、大きなセグメントの「ギャップ」、体の部分の過度の延長、照明不良、質の悪さ、および多くの詳細。 これらのエラーの一部は、異なるデータセットから特定の画像を追加することで回避され、一部のソリューションはまだ見つかりませんでした。 モデルの次のバージョンで結果を改善するために、画像モデルの「複合体」に拡張を使用します。
これについては既に(データセットの問題に関するセクションで)言及しましたが、今度はいくつかの困難についてさらに詳しく検討します。
- 洋服 非常に暗いまたは非常に明るい衣服は、背景として解釈されることがあります。
- 「クリアランス 。 」 結果は、他のすべての点で優れていますが、時にはギャップがありました。

衣類とクリアランス。 - 照明 照明や暗さが悪いことは画像によく見られますが、COCOデータセットには見られません。 通常、モデルがそのような画像を扱うことは難しく、モデルはそのような複雑な画像に対応していませんでした。 これを解決するには、データを追加するだけでなく、データを追加することもできます。 それまでは、夜間にアプリケーションをテストしない方が良いでしょう:)

照明不足の例。
さらなる改善のためのオプション
継続教育
テストデータを約300回サンプリングした結果が得られました。 その後、過剰適合が始まりました。 このような結果はリリースのすぐ近くで達成されたため、標準のデータ拡張プラクティスを適用する機会がありませんでした。
画像のサイズを224x224に変更した後、モデルをトレーニングしました。 大量のデータと大きな画像を使用したさらなるトレーニングも結果を改善するはずです(COCO画像の初期サイズは約600x1000です)。
CRFおよびその他の改善
いくつかの段階で、結果がエッジの周りで少し「ノイズが多い」ことに気付きました。 これを処理できるモデルはCRF(条件付きランダムフィールド)です。 この投稿では、著者はCRFを使用した簡単な例を提供します。
ただし、結果が粗い場合にこのモデルは通常有用であるため、おそらくあまり役に立ちませんでした。
つや消し
現在の結果でも、セグメンテーションは完全ではありません。 制御データのセグメンテーションにこれらのニュアンスが含まれていないという理由だけで、髪、薄い衣服、木の枝、その他の小さなオブジェクトが完全にセグメント化されることはありません。 このような繊細なセグメンテーションを分離するタスクはマットと呼ばれ、他の困難も明らかにします。 以下は、NVIDIAカンファレンスで今年初めに公開された最新のマットの例です。
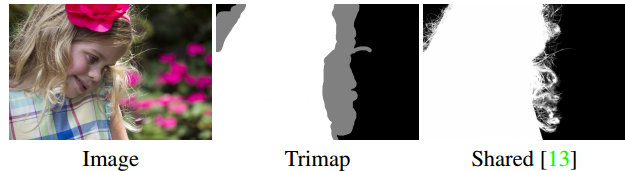
つや消しの例-入力にはtrimapが含まれます。
入力データには画像だけでなく、トライマップ(画像のエッジの輪郭)も含まれているため、マッティングタスクは画像処理に関連する他のタスクとは異なり、「半制御」トレーニングの問題が生じます。
セグメンテーションをトライマップとして使用して、マットを少し試してみましたが、重要な結果は得られませんでした。
別の問題は、トレーニングに適したデータセットの欠如でした。
まとめ
冒頭で述べたように、私たちの目標は、ディープラーニングを通じて意味のある製品を作成することでした。 Alonの投稿でわかるように、実装はより簡単かつ迅速になっています。 一方、モデルトレーニングでは事態はさらに悪化します。トレーニングは、特に夜間に行われる場合、慎重な計画、デバッグ、および結果の記録が必要です。
研究と何か新しいことをしようとする試みと、定期的な訓練と改善のバランスを取ることは容易ではありません。 ディープラーニングを使用しているため、より高度なモデル、または必要なモデルがすぐ近くにあり、別のGoogle検索、または別の記事を読んで、私たちが望むものに導くという感覚が常にあります。 しかし実際には、私たちの実際の改善は、元のモデルからますます「絞り込んだ」という事実によるものでした。 そして、私たちはまだもっと絞り込めると感じています。
私たちはこの仕事をするのがとても楽しかったです。数か月前はSFのようでした。
greenScreen.AI