メモ化可能な関数の実行時間、砂糖のメモ化に必要な余分な時間、および(誰もが忘れている)このメモ化を適切に固定する必要があるプログラマーの数のバランス。

しかし、簡単なものから始めましょう-この奇妙な言葉は何ですか-「メモ化」。
メモ化(英語のメモ化から)は、コンピュータープログラムの速度を上げるために使用される最適化手法の1つであり、再計算を防ぐために関数の結果を保存します。この非常にメモ化を提供する非常に多くのライブラリがありますが、誰もが独自の異なる実装の詳細を持っています-引数の数をどのように処理するか、結果をどのように保存するか、そしてもちろん、どれだけ速いかです。
ライブラリの速度によって、非常に大きく異なります-何千回も。 しかし、完全な秘密は、彼らが何をどのように測定するかということです。もちろん、各著者は、彼の作成に最適なケースを見つけ、彼のトリックを見つけます。
たとえば、 Lodash.memoizeは 、デフォルトで単一の関数引数で機能します。 Fast-memoize -1つまたは複数の引数の関数に対して異なるコードがあります。 メモ1または最後の応答をサイレントに再選択して保存し、それとのみ比較します。 一部の機能(コンポーネントの複数のインスタンス)を除き、場合によっては非常に悪い(たとえばフィボナッチ数の計算)、他の場合は非常に良い(React / Redux)。
一般的に-どこでもトリックがあります。 これがなければ、面白くないでしょう。 過去数年にわたって非常によく噛まれてきた最後のケース-Reduxについて考えてみましょう。 はい、それで終わりではありません。
React / Reduxの世界には、特定の要素のいくつかの値を大きな一般状態から「選択」するmapStateToProps関数があります。 関数の結果が以前に保存されたものと異なる場合、コンポーネントは新しいデータで再描画されます。
const mapStateToProps = state => ({ todos: state.todos.filter(todo => todo.active) });
^ここで少し台無しにしました。 アクティブなTODOのみを除外したかったのですが、関数呼び出しごとに一意の配列(一意でない値を持つ)を取得します。 これは非常に悪い考えです。なぜなら、戻り値はshallowequalで比較され、等しくないからです。
const filterTodos = memoize(todos => todos.filter(todo => todo.active)); const mapStateToProps = state => ({ todos: filterTodos(state.todos) });
^ここで修正しましたが、配列自体が変更された場合にのみ答えが変わります。
const filterTodos = memoize(todos => todos.filter(todo => todo.active)); const getTodos = memoize(todos => todos.map(todo => todo.text )) const mapStateToProps = state => ({ todos: getTodos(filterTodos(state.todos)) });
^そして、ここでは、アクティブなTODOのテキストが変更された場合にのみ、回答を変更したいのですが、欲求は有害ではありません。 実行することは事実上不可能です。
Reduxは非常に優れたツールであり、心から愛しています。 しかし、状態を解析してセレクターのカスケードにし、それに応じて後続のアセンブリを1つの目的のみで実行する場合、結果をメモして、Reactが再びヤンクしないようにします。 みんな-私はそのようなゲームをしません。
ここでのポイントは、メモ化機能の速度ではなく、「正しい」メモ化のプロセス、それに費やされる時間、および予想される最終結果です。
そしてもちろん、すべてがメモされるべきではないことを忘れないでください。 何かを数える必要がないことを数えるよりも、「本当の」何かを数える方が簡単な場合がよくあります。 砂糖のメモ化は無料にはほど遠い。しかし! React / Redux環境では、メモ化の速度はほとんど意味がありません。 重要なのは、メモ化の事実です。 すでに結果が得られていて、何も更新する必要がないことを時間内に理解できた場合、アプリケーションの更新された部分を無駄にする巨大なReactコードが欠落しています。
そして、最小の最適化でも、メモ化シュガーの「余分な」計算よりも10倍高くなり、この最適化が可能になりました。さて、フィボナッチのことを考えずに、より複雑なものを考えるとき、メモ化の「複雑な」機能を使用することが非常に可能であることが判明したら、それを使用しましょう。
メモ状態
Memoize-stateは、メモ化を簡単かつ高速にするわずかに異なる原則に基づいたメモ化ライブラリです。 通常のメモ化関数よりもコードが10倍多いという事実にもかかわらず。
例から始めましょう。
const filterTodos = memoizeState(todos => todos.filter(todo => todo.active)); const getTodos = memoizeState(todos => todos.map(todo => todo.text )) const mapStateToProps =state => ({ todos: getTodos(filterTodos(state.todos)) });
^最終的な結果は、アクティブなTODOのテキストが変更された場合にのみ変更されます。
const filterTodos =todos => todos.filter(todo => todo.active); const getTodos = todos => todos.map(todo => todo.text ) const mapStateToProps = memoizeState (state => ({ todos: getTodos(filterTodos(state.todos)) }));
^まったく同じ結果。 意外と?
Memoize-stateは、 MobXまたはImmer.jsに似た原理で動作します-ES6 Proxy 、WeakMaps、Reflection、およびこの魔法を可能にする別の現代のがらくた。
要するに-memoize-stateは、渡された引数をどのように使用し、答えとして何を返すかを監視します。 その後、彼女はどの変更に対応すべきか、どの変更に対応しないかを理解します。 (これが実際にどのように機能するかを理解するのにほぼ1か月かかりました)
つまり、任意の関数を記述し、memoize-stateでラップ(少なくとも10回)すると、理論上の最大値でメモされます。
PS:!!! 関数は純粋でなければなりません。そうでなければ、フォーカスは失敗します。 この関数は、入力として「オブジェクト」を受け入れ、オブジェクト内のキーを操作してオブジェクトを返す必要があります。そうしないと、フォーカスではなくゴミが発生します。memoize-stateは、複雑な場合、特にmapStateToPropsおよび類似物に最適です。 フィボナッチを計算するためにそれを使用しようとしないでください-フィボナッチを計算する複雑さよりも何倍も大きい腸にあまりにも多くのロジックがあります。
スピード
会話は速度に関するものなので、比較してみましょう。
1.フィボナッチ数の計算。 高速メモライブラリからのテスト
0. base line x 123.592 ( ) 2. fast-memoize x 203.342.420 3. lodash x 25.877.616 4. underscore x 20.518.294 5. memoize-state x 16.834.719 6. ramda x 1.274.908
まあ-最悪のオプションではありません。
2. 3つの整数引数の「遅い」関数の計算。 memoize-stateライブラリからのテスト
0. base line x 10.646 ( ) 1. memoize-one x 4.605.161 2. memoize-state x 2.494.236 3. lodash.memoize x 2.148.475 4. fast-memoize x 647.231
すでに良い。
3.「mapStateToProps」の計算-入力オブジェクト;値はランダムに変化します(または変化しません)。
0. base line x 2.921 ( ) 1. memoize-state x 424.303 3. fast-memoize x 29.811 2. lodash.memoize x 20.664 4. memoize-one x 2.592
とても良い。 memoize-stateは細断処理するだけです。 JSON.stringifyに基づくfast-memoizeとlodash.memoizeは、オブジェクトに新しいオブジェクトが与えられたが、その値が古い場合を処理します。
ラージオブジェクトが入力にフィードされるときのテストがまだあり、JSON.stringifyのオーバーヘッドコストが急上昇します。 違いはさらに大きくなります。
結果として、それは判明します-最も遅いのは、最も複雑であるため、メモ化の機能はそれほど遅くないからです。 はい。作業を維持するためのオーバーヘッドにより、1秒あたり1,600万回実行できます。もちろん、メモリーダーの200ほどクールではありませんが、react / reduxアプリケーションのニーズの10万倍以上です。
Memoize-stateは、 構成を必要としないという点で通常のメモ化機能とは異なり、既に持っているメモの友達であり(共通状態から必要なキーも選択します)、最終的に「外部メモ化」と呼ぶことができます。
その結果、さらに魔法の魔法が可能になります-beautiful-react-redux 。
beautiful-react-reduxは、 react-reduxのラッパーであり、mapStateToPropsをmemoize-stateで2回静かにラップします。これにより、1つおよび多くのコンポーネントの自動メモ化を保証します(by re-reselect )。 1行-アプリケーション全体が少し(またはかなり)高速になりました。 あなたの側での作業なしで、これは重要です。
PS:beautiful-react-reduxは、memoize-stateをアクティブ化せずに、メモ化の「正確さ」についてアプリケーションをテストするためのツールも提供します。 それらは、この魔法を使用して、低レベルで、より複雑ですが、より高速なアプローチである標準請求書ライブラリをテストできます。 リポジトリの詳細。2番目の優れた使用例は、 react-memoizeです。これは、 Dan Abramovのツイートに基づいたライブラリであり(実際に)レンダリングをメモし、componentWillReceivePropsのロジックを実際に放棄できるようにします。
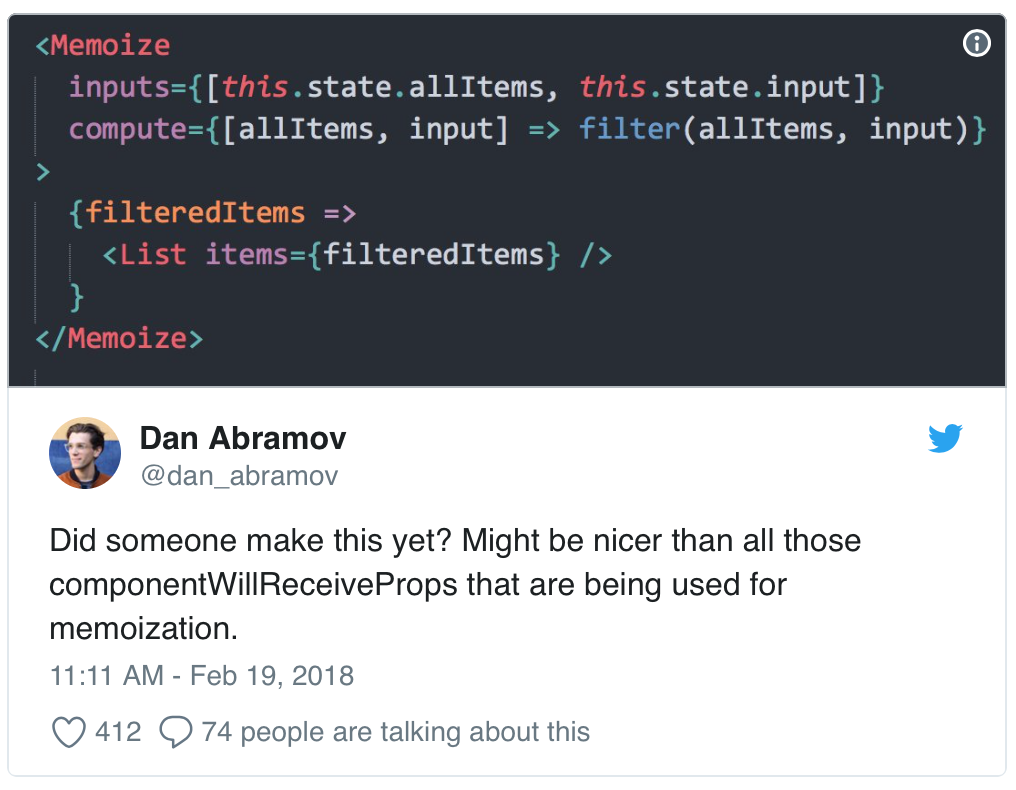
実際、実装はわずかに異なります。 「セレクタ」が不要になり、「コードを書くだけ」の機会が一般的になったからです。
いくつかの小道具を渡すだけで、何らかの形でそれらに基づいて何かを数えるだけで、ポイントは帽子にあります。
<Memoize prop1 = "theKey" state = {this.state} compute={({prop1, state}) => heavyComputation(state[prop1])} > { result => <Display>{result}</Display>} </Memoize>
そして再び、それは簡単かつ完全に自動的に動作します。
2番目の重要なオプションは、元のmemoize-stateテストが速度を比較するだけでなく、キャッシュのヒット/ミスを比較することです。 したがって、メモする必要がある場合は100件中99件、不要な場合は100件中0件です。 それはほぼ完璧に動作します。 そしてもちろん、memoize-stateは3つの部分で構成されているため、これはすべて3層のテストでカバーされます-memoize-stateは、メモ化自体のmemoize-state、オブジェクトのラッピング、展開、比較のプロキシイコール、および必要なオブジェクトの使用済み部分の検索を高速化するためのsearch-trie値で比較すべきではない値。
適合性
これらすべての短所は1つだけです。IE11およびAndroid(React Navite)の場合、プロキシ用のポリファイルが必要で、これにより少し遅くなります。 しかし、何もないよりはましです。
行動する時間
前にまだ耕されていないフィールドがあります。たとえば、メモ化のチェック速度を 2回上げることができます。 はい、場合によっては、react-redux統合を計算から排除できます。
一般に、関心のあるすべての人はmemoize-stateを追加し、実験することに招待されます。
Github