
パラレルSTLの概要
そのため、C ++で並行性をサポートする運命は非常に困難でした。 下の写真で
ソフトウェアまたはハードウェアメーカーによって作成されたさまざまな「外部」並列ソフトウェア開発ツールの「動物園」全体を含む、C ++の異なるバージョンでこれに使用できるマルチレベルツールに慣れることができます。
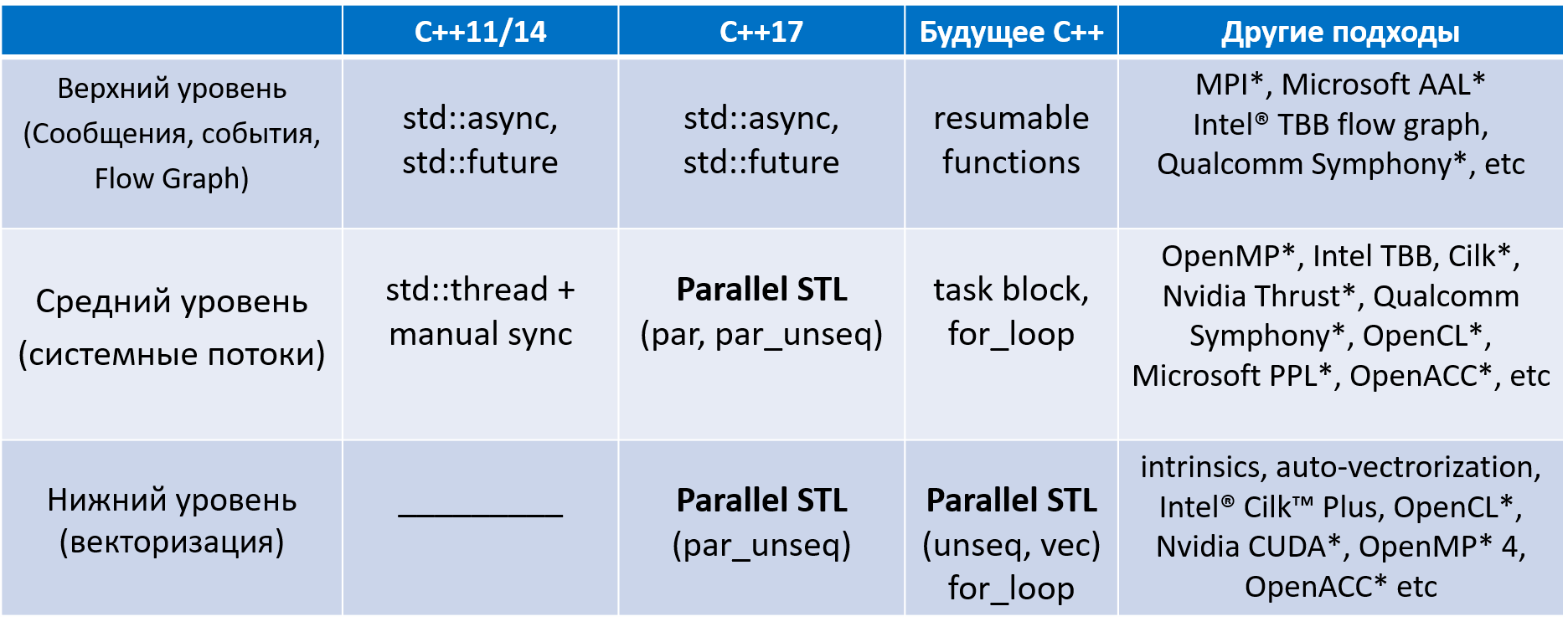
図1. C ++での並行性の進化
パラレルSTLは、標準テンプレートライブラリ(C ++)の拡張機能であり、「実行ポリシー」の重要な概念を導入しています。
実行ポリシーは、STLアルゴリズムをオーバーロードするための一意のタイプとして使用されるC ++クラスです。 使いやすくするために、標準では、このような各クラスの1つのオブジェクトも定義しています。これは、アルゴリズムを呼び出すときに引数として渡すことができます。 これらは、よく知られたアルゴリズム(transform、for_each、copy_if)と、C ++ 17で登場した新しいアルゴリズム(reduce、transform_reduce、inclusive_scanなど)の両方で使用できます。 C ++ 17のすべてのアルゴリズムがポリシーをサポートするわけではないことを明確にする必要があります。
さらに、アルゴリズムの並列実行とは、いくつかのCPUコアでの実行を意味します。 ベクトル化とは、ベクトルプロセッサレジスタを含む実行のことです。 並列ポリシーのサポートは、「並列処理のためのC ++拡張機能の技術仕様*」(並列処理TS)として数年間開発されてきました。 現在、この仕様はC ++ 17言語標準の一部です。 ベクトルポリシーのサポートは、Parallelism TS仕様の第2バージョン(n4698 [2]、p0076 [3])に含めることができます。 一般に、これらのドキュメントには5つの異なる実行ポリシーが記載されています(図2)。
- sequenced_policy(seq)は、アルゴリズムを順番に実行できることを示します[1]。
- parallel_policy(par)は、アルゴリズムを並列で実行できることを示します[1]。 アルゴリズムの動作中に呼び出されるカスタム関数は、「データの競合」を引き起こすべきではありません。
- parallel_unsequenced_policy(par_unseq)は、アルゴリズムを並列およびベクトル[1]で実行できることを示します。
- unsequenced_policy(unseq)-Parallelism TS v2 [2]ドラフトの一部であり、アルゴリズムがベクトル的に実行できることを示すクラス。 このポリシーでは、すべてのユーザー定義関数、ファンクターがパラメーターとしてアルゴリズムに渡され、ベクトル化に干渉しないこと(データの依存関係を含まない、データの競合を引き起こさないなど)が必要です。
- vector_policy(vec) (これも[2]から)は、アルゴリズムはベクターで実行できると述べていますが、 unseqとは異なり、 vecポリシーは、順次実行中に処理される順序でデータ処理を保証します(結合性を保持します)。

図2.アルゴリズムの実行ポリシー
上の図は、これらのポリシー間の関係を示しています。 ダイアグラム内のポリシーが高いほど、(並列性に関して)自由度が大きくなります。
以下は、C ++ 17標準に従ってSTLおよびParallel STLアルゴリズムを使用する例です。
#include <execution> #include <algorithm> void increment_seq( float *in, float *out, int N ) { using namespace std; transform( in, in + N, out, []( float f ) { return f+1; }); } void increment_unseq( float *in, float *out, int N ) { using namespace std; using namespace std::execution; transform( unseq, in, in + N, out, []( float f ) { return f+1; }); } void increment_par( float *in, float *out, int N ) { using namespace std; using namespace std::execution; transform( par, in, in + N, out, []( float f ) { return f+1; }); }
レコードはどこですか
std::transform( in, in + N, out, foo );
次のループと同等:
for (x = in; x < in+N; ++x) *(out+(x-in)) = foo(x);
そして
std::transform( unseq, in, in + N, out, foo );
次のサイクルとして表すことができます(私たちの実装は下位レベルで#pragma omp simdを使用し、他の並列STL実装はunseqポリシーを実装するために他の方法を使用する場合があります)
#pragma omp simd for (x = in; x < in+N; ++x) *(out+(x-in)) = foo(x);
そして
std::transform( par, in, in + N, out);
次のように表現できます。
tbb::parallel_for (in, in+N, [=] (x) { *(out+(x-in)) = foo(x); });
インテル®Parallel Studio XE 2018での並列STL実装の概要
インテルのParallel STL実装は、 Intel®Parallel Studio XE 2018の一部です。 並列およびベクトルの両方で実行できるアルゴリズムの移植可能な実装を提供します。 実装は、インテル®プロセッサー向けに最適化およびテストされています。 parおよびpar_unseqポリシーを使用する場合はインテル®スレッディングビルディングブロック(インテル ®TBB )を使用し、 unseqおよびpar_unseqポリシーではOpenMP *を使用したベクトル化を使用します。 vecポリシーは、Intel Parallel Studio XE 2018では表示されません。
Parallel STLをインストールしたら、 このドキュメントの説明に従って環境変数を設定する必要があります 。 また、並列および/またはベクトル実装を持つアルゴリズムの実際のリストもあります。 他のアルゴリズムの場合、実行ポリシーも適用可能ですが、シリアルバージョンが呼び出されます。
パラレルSTL実装で最良の結果を得るには、インテル®C ++コンパイラー2018の使用をお勧めします。ただし、C ++ 11をサポートする他のコンパイラーを使用することもできます。 ベクトル化の利点を得るには、コンパイラーはOpenMP 4.0( #pragma omp simd )もサポートする必要があります。 par、par_unseqポリシーを使用するには、Intel TBBライブラリが必要です。
Parallel STLをアプリケーションに追加するには、次の手順を実行します。
- #include "pstl / execution"を追加します。 次に、使用するアルゴリズムに応じて、次の行の1つ以上を実行します。
#include "pstl / algorithm"
#include "pstl / numeric"
#include "pstl / memory"
#include <execution>だけでなく、 #include "pstl / execution"を記述する必要があることに注意してください。 これは、特に標準C ++ライブラリのヘッダーファイルとの競合を避けるために行われます。 - アルゴリズムとポリシーが使用される場所については、それぞれ名前空間stdとpstl :: executionを指定します。
- サポートオプションC ++ 11以降でコードをコンパイルします。 適切なコンパイルオプションを使用して、OpenMPベクトル化を有効にします(たとえば、Intel C ++コンパイラの場合-qopenmp-simd (Windowsの場合は/ Qopenmp-simd *)。
- 最高のパフォーマンスを得るには、ターゲットプラットフォームを指定します。 インテル®C ++コンパイラーの場合、リストから適切なオプションを使用します: -xHOST、-xCORE-AVX2、-xMIC-AVX512 for Linux *または/ QxHOST、/ QxCORE AVX2、/ QxMIC-AVX512 for Windows。
- Intel TBBとリンクします。 Windowsでは、これは自動的に行われます。 他のプラットフォームでは追加
-ltbbからリンカーオプション。
Intel Parallel Studio XE 2018には、ビルドおよび実行できるParallel STLの使用例が含まれています。 ここからダウンロードできます 。
Parallel STL実装を使用した効率的なベクトル化、同時実行性および互換性
理論的には、Parallel STLは、C ++開発者が共有メモリを備えた並列コンピューティングシステム用のプログラムを作成するための直感的な方法として設計されました。 理論がネストされたループを並列化するベストプラクティスと相関するアプローチを考えてみましょう。たとえば、「内部レベルをベクトル化し、外部を並列化する」などのアプローチです(「Internalmost、Parallelize Outermostをベクトル化する」[VIPO])[4]。 例として、画像のガンマ補正を検討します。これは、各画像ピクセルの輝度を変更するために使用される非線形操作です。 逐次実行とベクトル実行の違いを示すために、アルゴリズムの順次実行の自動ベクトル化を無効にする必要があることに注意してください。 (そうでなければ、この違いは、自動ベクトル化をサポートしていないがOpenMPベクトル化をサポートしているコンパイラでのみ見られます)
順次実行の例を考えてみましょう。
#include <algorithm> void ApplyGamma(Image& rows, float g) { using namespace std; for_each(rows.begin(), rows.end(), [g](Row &r) { transform(r.cbegin(), r.cend(), r.begin(), [g](float v) { return pow(v, g); }); }); }
ApplyGamma関数は、参照によって一連の文字列として表される画像を取得し、 std :: for_eachを呼び出して文字列を反復処理します。 各行に対して呼び出されるラムダ関数は、 std :: transformを使用してピクセルをループ処理し、各ピクセルの輝度を変更します。
前に説明したように、Parallel STLは、 for_eachおよび変換アルゴリズムの並列バージョンとベクトルバージョンを提供します。 つまり、アルゴリズムの最初の引数として渡されたポリシーは、このアルゴリズムの並列バージョンまたはベクターバージョンの実行につながります。
上記の例に戻ると、 変換アルゴリズムから呼び出されるラムダ関数ですべての計算が実行されることがわかります。 「1石で2羽の鳥を殺す」ことを試み、 par_unseqポリシーを使用して例を書き換えましょう。
void ApplyGamma(Image& rows, float g) { using namespace pstl::execution; std::for_each(rows.begin(),rows.end(), [g](Row &r) { // Inner parallelization and vectorization std::transform(par_unseq, r.cbegin(), r.cend(), r.begin(), [g](float v) { return pow(v, g); }); }); }
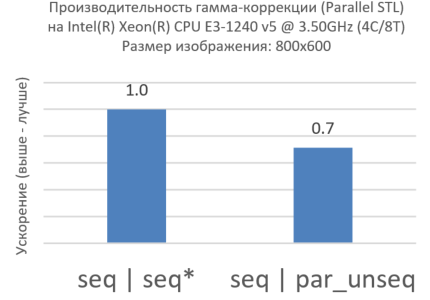
図3.内側のループのPar_unseq
驚いたことに、奇跡は起こりませんでした(図3)。 par_unseqを使用したパフォーマンスは 、順次実行よりも劣ります。 これは、パラレルSTLを使用しない方法の良い例です。 たとえば、 インテル®VTune Amplifier XEを使用してコードのプロファイルを作成すると、同じキャッシュラインにアクセスする異なるコアで実行されているスレッドに起因する多くのキャッシュミスを確認できます(この効果は「リソースの偽共有 "[ 偽共有 ])。
前述のように、Parallel STLは、中間レベル(システムスレッドを使用)と下位レベル(ベクトル化を使用)の並列性を表現するのに役立ちます。 一般的な場合、最大の加速を得るには、アルゴリズムの実行時間を評価し、それを並列化およびベクトル化のオーバーヘッドと比較します。 順次実行時間は、各同時実行レベルでのオーバーヘッドより少なくとも2倍長くすることをお勧めします。 これに加えて:
- 最高レベルを並列化します。 並行して行われる作業の最大量を探します。
- これで十分な並列化効率が得られれば、目標は達成されています。 そうでない場合は、以下のレベルを並列化します。
- アルゴリズムがキャッシュを効率的に使用していることを確認してください。
- 最低レベルをベクトル化してみてください。 ベクトル化された関数の条件付きジャンプの数を減らし、メモリへの均一なアクセスを維持してください。
- [4]でさらに推奨事項を探してください。
推奨事項は、異なるレベルで並列およびベクトルポリシーを正しく使用すると、パフォーマンスが向上することを示唆しています。
void ApplyGamma(Image& rows, float g) { using namespace pstl::execution; // Outer parallelization std::for_each(par, rows.begin(), rows.end(), [g](Row &r) { // Inner vectorization std::transform(unseq, r.cbegin(), r.cend(), r.begin(), [g](float v) { return pow(v, g); }); }); }
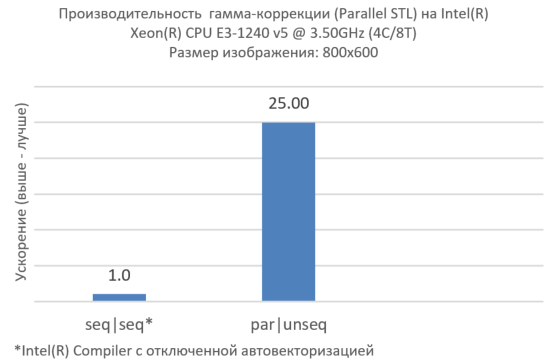
図4.内部レベルでのベクトル化、外部レベルでの並列化
これで、1つの画像の効果的な並列処理が行われました(図4)が、実際のアプリケーションは原則として多くの画像を処理します(図5)。 より高いレベルの同時実行は、標準のアルゴリズムではうまく機能しない場合があります。 この場合、Intel TBBとともにParallel STLを使用することをお勧めします。
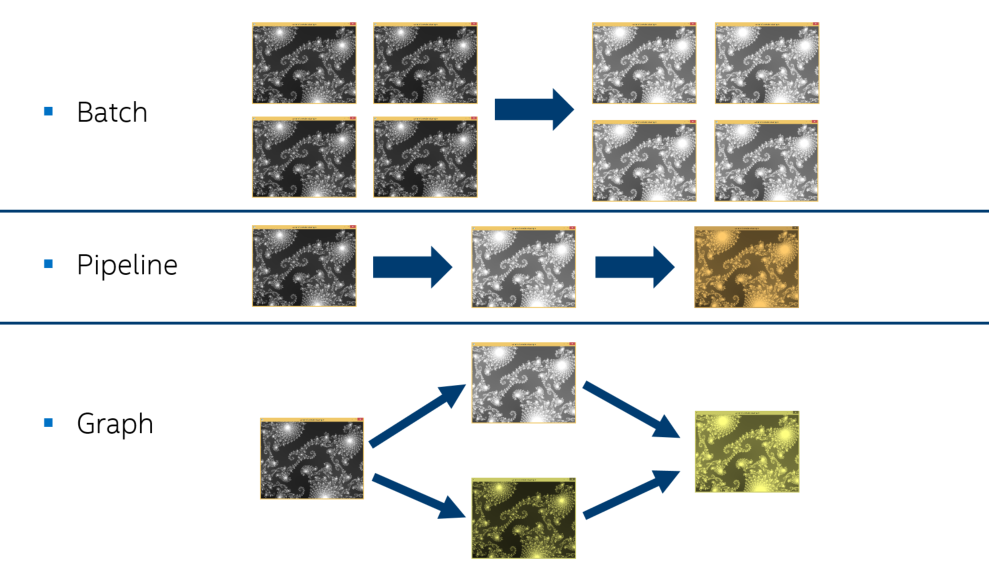
図5.複数の画像を処理する方法
これにより、システム内に過剰な数の論理フローを作成することを心配せずに、最高レベルのIntel TBBおよび下位レベルのParallel STLアルゴリズムをタスク(タスク)または並列構造(計算グラフ[フローグラフ]、パイプライン[パイプライン]など)に適用できます。 。 例:
void Function() { Image img1, img2; // Prepare img1 and img2 tbb::parallel_invoke( [&img1] { img1.ApplyGamma(gamma1); }, [&img2] { img2.ApplyGamma(gamma2); } ); }
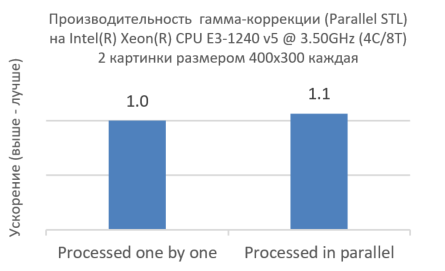
図6. Intel TBBとパラレルSTLの共有
図6に示すように、Intel TBBを使用して2つのイメージを同時に処理してもパフォーマンスは低下しませんが、逆にわずかに向上します。 これは、より低いレベルおよびより低いレベルで並行性を表現すると、CPUコアを最大限に活用できることを示しています。
ここで、処理用のイメージとCPUコアが増える状況を考えてみましょう。
tbb::parallel_for(images.begin(), images.end(), [](image* img) {applyGamma(img->rows(), 1.1);} );
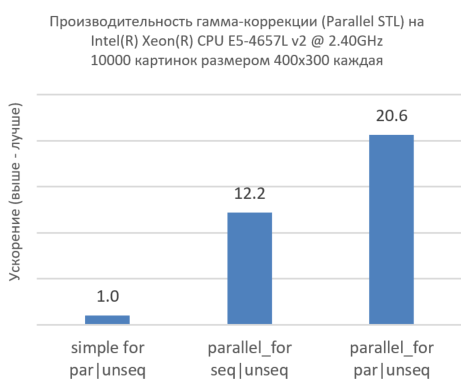
図7.より多くのイメージとより多くのCPUコアでIntel TBBとParallel STLを共有します。
上の図は、Intel TBB( parallel_for )を使用して複数のイメージを同時に処理すると生産性が劇的に向上することを示しています。 実際、最初の列を見てください。すべての画像を順番に実行し、各画像が下位レベルで並列処理されています。 最下位レベル( par )で並列処理を行わずに、最高レベル( parallel_for )でのみ並列処理を追加すると、パフォーマンスが大幅に向上しますが、これはCPUコアのリソースを最大限に活用するには不十分です。 3番目の列は、すべてのレベルでの並行性が生産性を劇的に向上させることを示しています。 これは、インテルTBBとパラレルSTL実装の共有の有効性を示しています。
おわりに
並列STLは、C ++並列処理の進化における重要なステップであり、コードの近代化中および新しいアプリケーションの作成中の両方で、標準STLライブラリのアルゴリズムに容易に適用できます。 標準のこの部分は、非標準または汎用の拡張機能を使用せずに、ベクトル化と並列処理の機能をC ++言語に追加し、実行ポリシーはハードウェアから抽象化して、そのような機能の使用を制御します。 並列STLを使用すると、開発者は低レベルのフロー制御とベクトルレジスタを心配することなく、アプリケーションの同時実行性の表現に集中できます。 高レベルアルゴリズムの効率的で高性能な実装に加えて、パラレルSTL実装は、インテルTBBパラレルパターンとの効率的な共有を実証します。 ただし、Parallel STLは万能薬ではありません。 タスクの次元、データのタイプと量、および関数のコード、アルゴリズムで使用されるファンクターに応じて、並列ポリシーとベクトルポリシーを慎重に使用する必要があります。 高いパフォーマンスを実現するには、[4]で説明されているいくつかの方法をお勧めします。
Parallel STLおよびIntel TBBの最新バージョン、および次のサイトで追加情報を見つけることができます。
- githubでのParallel STLのオープンソース実装
- インテルTBBの公式Webサイト
- github上のIntel TBB
- Intel TBB ドキュメント
フィードバックが必要です。 そして、あなたはそれらをここに残すことができます:
- Githubプロジェクトページ
- Intel TBB フォーラム
参照:
[1] ISO / IEC 14882:2017、プログラミング言語。 C ++
[2] n4698、 ワーキングドラフト、並列化バージョン2のC ++拡張機能の技術仕様 、プログラミング言語C ++(WG21)
[3] P0076r4、 ベクトルおよびウェーブフロントポリシー 、プログラミング言語C ++(WG21)
[4] Robert Geva、 コード最新化のベストプラクティス:インテル ®Xeon® およびインテル ®Xeon Phi™プロセッサーのマルチレベル並列処理 、IDF15-Webcast
*他の名前およびブランドは、他者の知的財産として宣言される場合があります。