
最初の記事で物語の始まりを思い出すことができますが、何が起こっているかを簡単に思い出します。
それはすべて、モノリシックアプリケーションのマイクロサービスへの移行から始まりました。テスト環境に新しいリリースを展開する合理化されたプロセスが、「詳細」の急激な増加により失敗し始めたときです。 開発者が一般的なテストスタンドを争わず、すべてが迅速かつスムーズに機能するように、自動化プロジェクトを開始しました。
管理上の問題により、プロジェクトはすぐに結果を表示しませんでしたので、ストーリーの続きを提供します。
なぜ悪い手動回路
最近まで、同社には複数の古いモノリシックテスト環境があり、それぞれにフロントエンド/バックエンド/請求コンポーネントが含まれており、アプリケーション開発および統合テストに必要です。 テストベンチは、特定のアプリケーションセットを持つホストのグループです。 内部では、それらをテスト回路と呼びます。 合計で、いくつかの一般的なテスト回路がありました:統合、負荷など、生産アーキテクチャに対応していませんでした。
つまり、各アプリケーションが常に独自のコンテナにあるとは限らず、テスト回路でnginxの構成をテストすることは不可能でした。
テストのために将来のリリースをインストールして構成する必要があり、その後、競合しないように、別の表に使用するホストと用途を示します。 これにはすべて、次の一連の問題がありました。
- 使用中のホストを含むファイルは手動で維持され、人的要因に大きく依存していました。
- 同じテスト回路で、同じアプリケーションを頻繁にテストしましたが、機能は異なります。 さらに、それぞれが構成および依存アプリケーションに独自の制限を課しました。 もちろん、このような構成の構成と展開は手動で行われ、ヒューマンファクターにも依存していました。ポイントオートメーションは個人のイニシアチブでした。
- テスト環境の構成とその中で許可されるコンポーネントの相互作用は、本番環境に対応していませんでした。 つまり、新しいアプリケーションアセンブリの実際の状態での操作性を完全に検証することは不可能でした。
- 最大の問題は、古いスキームから新しいスキームに設定を転送することでした。 各アプリケーションには独自の設定とデータベースバインドがあるため、手動で転送すると、何かが失われる可能性があります。
約1年前、同社はチームの急速な成長を開始し、テスト回路の数は変わりませんでした。チームをサポートするために必要なリソースの数だけが増加しました。 つまり、手動操作と関連する問題の量は指数関数的に増加し、ある時点でテストプロセス、ひいては開発を深刻に阻害し始めました。
自動化の落とし穴
まず、同じスキーム内のアプリケーションバージョンの競合を排除し、あるコンポーネントの応答が別の開発者によって以前に選択されたものではなく特定のサーバーに到達するように、コールバックの正しい配信を保証することにしました。 最善の解決策は、各開発者に独自のサンドボックスを提供することです。
動作は1つの基準回路のみをサポートし、可能な限り生産を繰り返します。 解決すべき他の問題については、新しいテスト回路の要件の次のリストがそれらに表示されました。
- スキームには、事前に構成されたアプリケーションのセットが含まれています。その一部は、開発者の要求で構成されているか、スキームから除外されています。
- アプリケーションのバージョンと「戦闘」の同期。
- ダイアグラム上のアプリケーションの更新または更新の禁止。 これは、テスト環境で「戦闘」バージョン以外のアプリケーションバージョンが必要な状況向けです。
- 一部のデータベースの「戦闘」とのデータ同期。
- スキーマ作成中のデータを使用したデータベースの複製。
- ログのコレクション、各スキームのメトリック。 さらに、各スキームでモバイルへのサービス電子メール、SMS、およびプッシュ通知の配信を保証する必要があります。
- 相互デバッグのために外部パートナーから特定のスキームにアクセスする機能。
- スキーマ内では、Windows / IIS / Microsoft SQL(BI)コンポーネントをサポートする必要があります。 ここでは、さまざまな理由(歴史的な理由を含む)で、分析ツールが.Netスタックにあり、残りがJavaにあることを明確にする必要があります。
ソリューションを選択する際の主な制限は、アプリケーションの自動展開の欠如でした。アプリケーションパッケージは、ネットワークフォルダーを介してテスト環境に簡単に転送されました。 つまり、テストスキームの前に、自動展開システムを構築するか、新しいスキームを初めて作成するときに参照スキーム(主にWindowsコンポーネント)からアプリケーションのクローンが作成されたという事実と調和する必要がありました。
別の方法として、悪用スクリプトを使用してアプリケーションの製品バージョンをデプロイします。 このソリューションの主な欠点は、回路内のコンポーネントの新しいバージョンを取得するために、それを再作成するか、更新のメカニズムおよびアプリケーションから隔離されたそのようなスクリプトの継続的なサポートを検討する必要があることです。
ところで、アセンブリと展開を自動化する長い道のりについては、 別の記事がありますが、主にアセンブリについて説明しています。
呼び出し先のホスト名が変更されていない場合、スキームを作成するときに設定の変更を最小限に抑えることができます。 したがって、たとえば短い名前で参照スキームが対話用に構成されている場合、新しいスキームに複製するときに設定を変更する必要はありません。 新しいスキーム用に別のDNSサーバーを作成するだけです。
したがって、長くて苦しい選択を省略した場合、私たちにとって最速の解決策は、 Openstackと各スキームのプライベートネットワークの組み合わせと、展開ツールとしてのAnsibleでした。
最終決定
最終的なソリューションはOpenstack + CEPHで構築され、各アプリケーションには独自のVMがあります。 各テスト回路について、Openstackで個別のプロジェクトが作成され、プライベートネットワークが割り当てられます。プライベートネットワークには、回路関連のアプリケーションを備えたマシンが接続されます。 そして何よりも、これはJenkinsビルドのセットであり、PipelineとAnsibleを介してすべてのサービス操作を実行します。回路、サブサーキットの作成と削除、アプリケーションの展開、データベースを同期するための定期的なタスク。
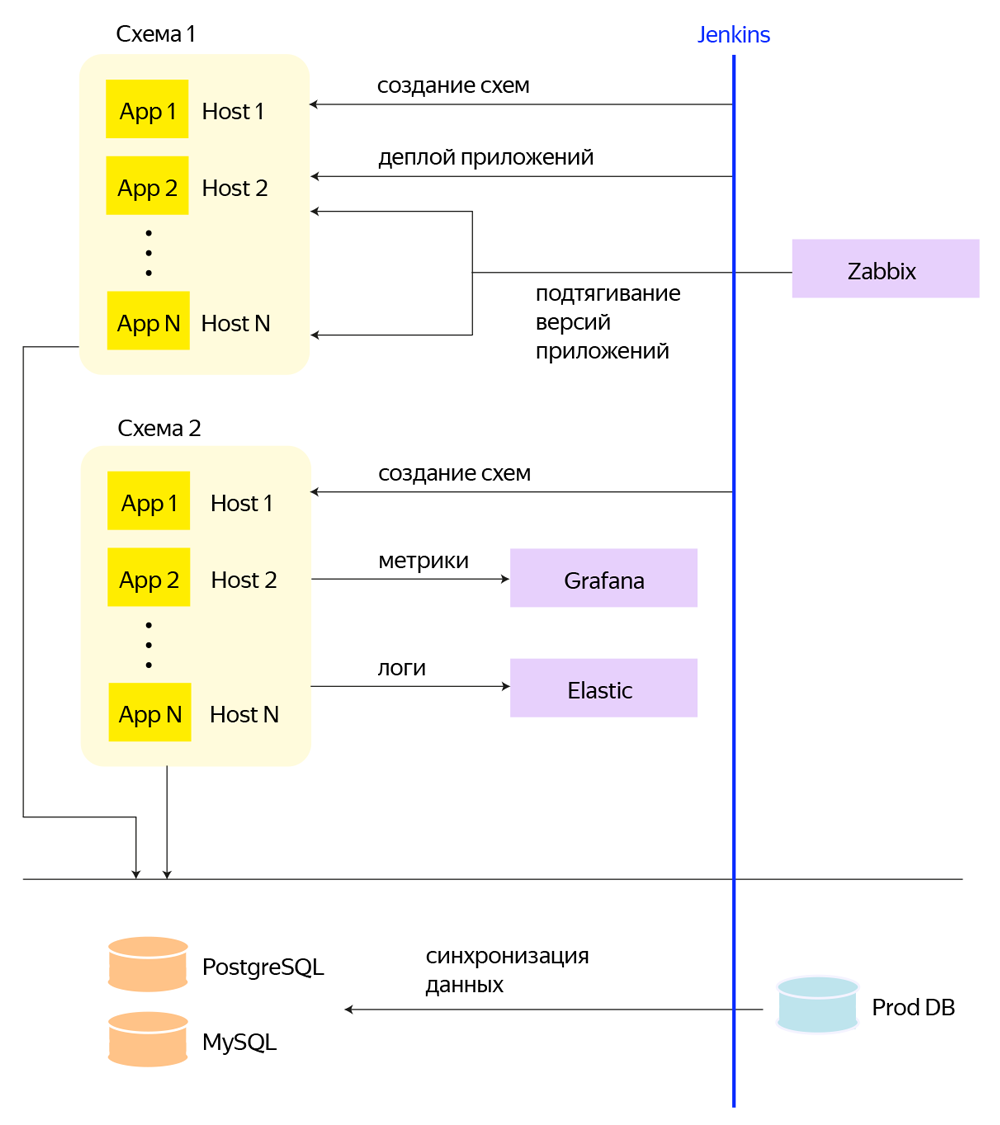
縦軸はJenkinsであり、これを介して、回路の作成、アプリケーションの展開、データベースの作成、およびその他のプロセスが行われます。
テスト回路を使用してすべてのプロセスを視覚化するには、Jenkins PipelineとBlue Oceanを使用します。すべてのステップの明確な画像が得られ、壊れたステージを簡単に確認できます。 ほとんどのプロセスはべき等であり、エラーが発生した場合は、ビルドを再起動するだけで十分です。
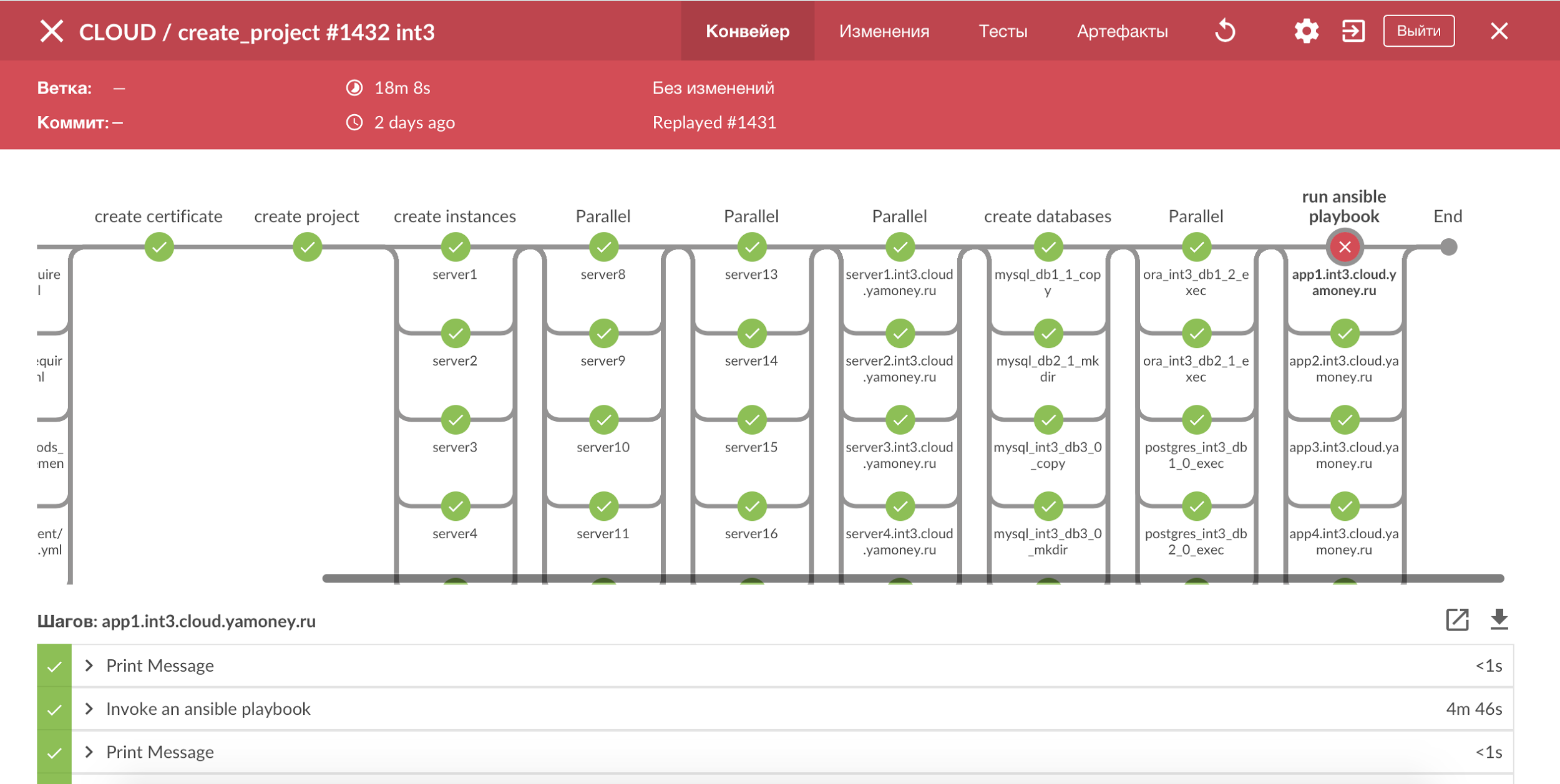
Jenkins Pipelineによるプロセスの視覚化。
不要なディスク負荷が発生しないように、すべてのデータベースを個別の物理マシンに転送して、アプリケーションサーバーをテスト回路に仮想的に残し、自動展開の方法がまだわからないすべてのインスタンスを複製しようとしました。 データベースであり、個別の物理マシンに送信されないアプリケーションを持つインスタンスは、個別のssdプールCEPHに作成します。
数字について言えば、プロジェクトの完了に近づくと、1つの中間スキームには、180 GBのメモリと600 GBのディスクスペースを使用する60を超えるインスタンスが含まれていました。
そしておそらく答えます:
- 第一に、インフラストラクチャに含まれていないためです。つまり、生産を含むこのプロジェクト専用に展開する必要があります。 OpenStackを使用すると、テストセグメントで戦闘環境をほぼ完全に繰り返すことができます。
- 第二に、各アプリケーションには、Heka、Zabbix、HAproxy、Pgbouncerからの独自のバインディングがあり、監視とログ、トラフィックのバランス、データベースの切り替えに必要です。 つまり、Dockerスキームでは、既存のアーキテクチャを大幅にリファクタリングする必要があります。
- 第三に、Yandex.Moneyにはサービスのアップタイムに対する高い要件があり、Dockerの可用性の合計レベル(戦闘環境での実装の必要性を考慮に入れて)を評価し、それを中心に構築されたすべてのサービスには個別の調査と多くの時間が必要です。
- しかし、戦闘システムでサービスを分離し、テスト環境で重い仮想マシンを軽く置き換えるために、コンテナ化を検討しています。 最初は、コンテナにさらに転送することを目指して、「1つのコンポーネント-1つの仮想マシン」という最も単純なソリューションが構築されました。 コンテナを並行して導入するのは危険すぎるように思えました。
テスト回路に既存のansibleロールとプレイブックを変更せずに適用できるようにするために、動的インベントリ生成スクリプトを使用します。これは、OpenStackのプロジェクト名と一致する回路の名前により、 実稼働と同じタイプのインベントリを作成します。 動的インベントリに必要なすべての情報は、OpenStackのインスタンスメタデータに含まれています。
アプリケーションに関しては、コンポーネントの大部分をansibleを介してデプロイに移行しました。アプリケーションは、さまざまな環境の設定テンプレートと変数値とともにdebパッケージにパッケージ化されています。 したがって、新しい回路を作成するときに最初に基準回路から複製する必要のあるコンポーネントの数が大幅に減少しました。
実際、すべてのコンポーネントがまだ新しい展開に移行されているわけではありません。このプロジェクトは、執筆時点で「残っているものを翻訳する」段階にあります。
もう1つの重要な機能は、すべてのテスト回路を最新の状態に保つプロセスでした。このため、夜間またはオンデマンドで、監視からアップデートを起動し、アップデートを起動するために実装しました。 さらに、ダイアグラムにアプリケーションの製品バージョンが含まれておらず、機能ブランチのアセンブリが含まれている場合、そのようなコンポーネントは夜間更新から自動的に除外されます。
しかし、処理はどうですか
テスト回路のアプリケーションの大部分は支払いプロセスに何らかの形で関係しているため、テストバンクカードのプールが自動的に生成されます。 カードの作成、カードによる承認、および清算は、テストスキームとは別に、すべての支払いコンポーネントに共通の処理モジュールで実行されます。 処理は特別なテストであるという事実にもかかわらず、特定のサーバーにのみ応答を送信できます。
つまり、多くのスキームと、この多くについて何も知りたくない処理サーバーがあります。 さらに、テスト回路では、新しいカード範囲が動的に追加されます。 問題の論理的な解決策として、各スキームの処理を単純に複製することができますが、これにはリソースの過剰な増加と各スキームの処理設定の自動化が必要になります。 一般的に、それは最適なパスではないようです。
既存の処理を大幅に終了しないために、テスト回路でカード作成コンポーネントを修正し、luaモジュールを備えたnginxサーバーをインストールして、処理からの承認リクエストをプロキシすることにしました。 ある範囲のカードを回線に追加すると、処理中にマップを作成するプロセスが開始されます。その結果、サービスフィールドの各カードに対して、それを発行する回線の名前が追加されます。
処理からテスト回路へのすべての逆要求は、nginxを使用してサーバーに到達します。luaスクリプトは、要求本文で回路名を検索し、要求を正しくプロキシします。
そして、この物語に関する最後の記事からほぼ1年が経過しました...
Dimaがテスト環境についての小説の最初の部分で書いたように、いくつかの部門がシステムで作業するとき、プロジェクトは引きずられる傾向があります。
それでも、いくつかのフィニッシュラインはすでに表示されており、解決したことを要約できます。
- インスタンスの複製によってデプロイされたアプリケーションを更新するには、スキーム全体を再作成する必要がありました。 プロジェクトの結果によると、すべてのコンポーネントが標準の展開プロセスに移行されるときに問題を解決できるため、問題はまだ残っています。
- 一部のアプリケーションおよびローカルロギングからの高いディスク負荷は、SSDディスクおよびそのようなインスタンスのCEPHの個別のプールへの移行により許容可能な値まで減少しました。
- メモリはマシン内のオペレーティングシステムにも費やされるため、仮想マシンで作業するときにRAMを効率的に使用することは困難です。
- 新しいOpenStack / CEPHインフラストラクチャの導入により、新しいバージョンのテスト、バグの発見と修正などのために追加の作業が必要になりました。 一般に、インフラストラクチャ内の新しい製品に付随するすべてのもの。
- プロジェクトの結果、数千のインスタンスでアプリケーションログを記録すると、CEPHに顕著な負担が生じるため、ローカルログ記録を放棄する方向に考えています。
現在、すべてのテスト回路のほとんどのコンポーネントの製品版への自動更新をすでに行っており、リソースを節約するために選択したコンポーネントセットでテスト回路を作成するプロジェクトを開始しています。 OpenStackでLXCコンテナを使用する予定です。
一般に、この手法はすべて氷山の一角にすぎません。 最も苦労するのは、開発者とテスターを説得して新しいスキームに切り替える(新しいプロセスを確立する)ことです。 第2四半期は、ゆっくりと進みながら、古いスキームから新しいスキームに段階的に移行していきました。