この投稿は私の英語ブログからのRシリーズのデータ取得の3つの部分の翻訳です。 最初のシリーズは4つのパートで構想され、そのうち3つがこの投稿の基礎となりました。 一般的な統計データベースへのアクセス 。 人口統計データ ; 人口統計データ 。 まだ記述されていない最後の部分は、空間データの使用に焦点を当てます。

結果の再現性を高めるためにRをシャープにしました。 リテラシープログラミングの原則を適用するのに役立つシステムバージョンとパッケージの互換性を保証する優れたソリューションは数多くあります ...しかし、R自体を使用してデータを簡単に/効率的に検索/ダウンロード/抽出し、各ステップを文書化することで、プロセス全体の完全な再現性を保証する方法を示したいと思います。 もちろん、考えられるすべてのデータソースをリストし、主に人口統計データに焦点を当てる作業を自分で設定するわけではありません。 関心が人口統計の範囲外である場合は、壮大なオープンデータタスクビュープロジェクトの方向に目を向ける価値があります 。
情報源のそれぞれの使用を説明するために、取得したデータの視覚化の例を示します。 各コード例は、独立したユニットとして設計されています-コピーして再生します。 もちろん、最初に必要なパッケージをインストールする必要があります。 コード全体がここにあります 。
埋め込みデータセット
多くのパッケージには、メソッドを説明するための小さくて便利なデータセットが含まれています。 実際、Rカーネルにはdatasets
パッケージが含まれています。このパッケージには、多数の小規模で多様な、時には非常に有名なデータセットが含まれています。 さまざまなパッケージの組み込みイラストパッケージの詳細なリストは、Vincent Arel-Bundock Webサイトで入手できます 。
組み込みのデータセットの優れた機能は、それらが「常にあなたと」いるということです。 一意のトレーニングデータセット名は、グローバル環境のオブジェクトと同じくらい簡単に使用できます。 スイスの魅力的な小さなデータセット-スイスの生殖能力と社会経済指標(1888)のデータを見てみましょう。 以下に、農村人口の割合とカトリック信仰のvalence延によるスイスの州間の出生率の違いを示します。
library(tidyverse) swiss %>% ggplot(aes(x = Agriculture, y = Fertility, color = Catholic > 50))+ geom_point()+ stat_ellipse()+ theme_minimal(base_family = "mono")

ガプミンダー
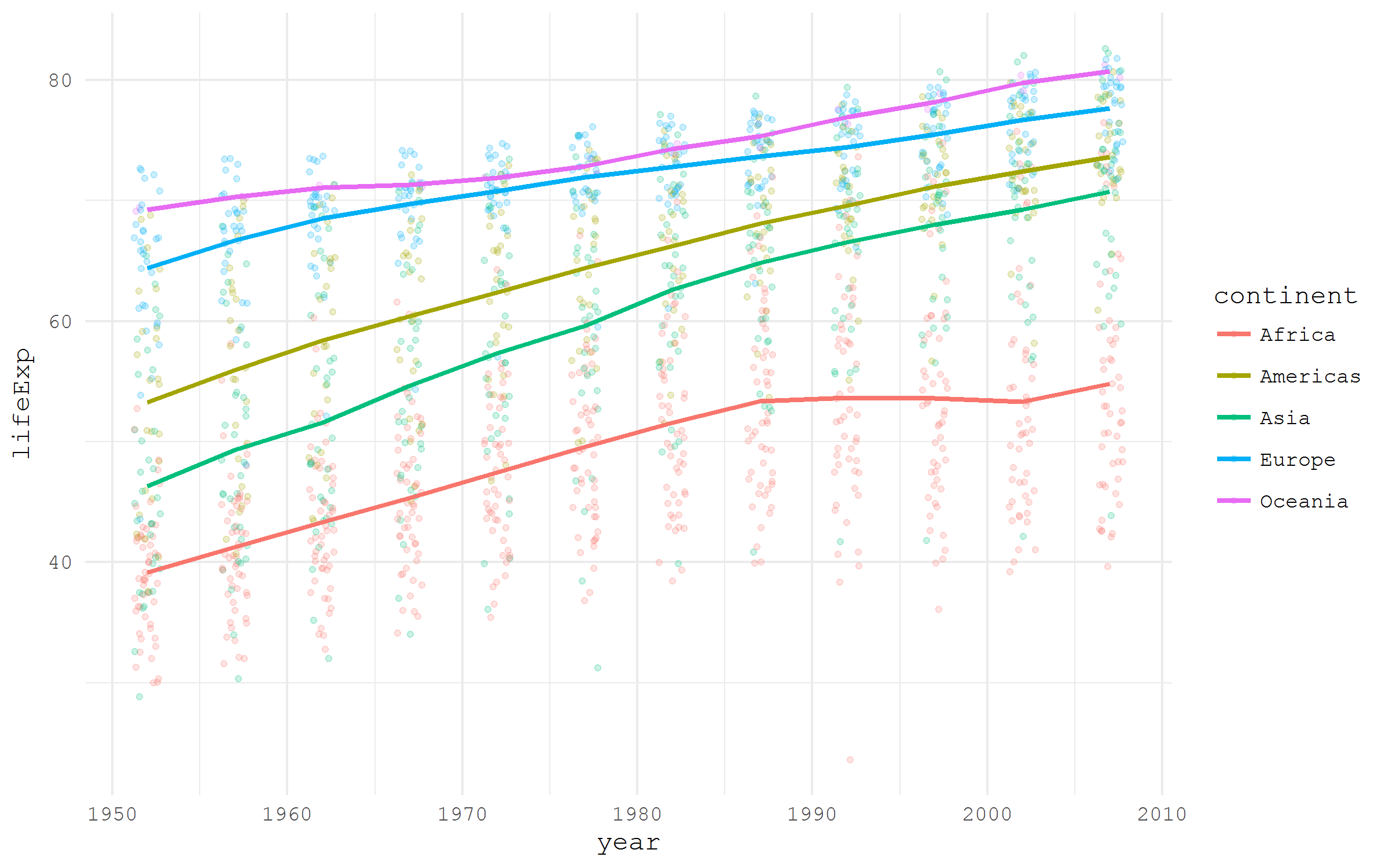
一部のパッケージは、R。ユーザーが特定のデータセットに簡単にアクセスできるように特別に設計されています。そのようなパッケージの良い例は、 Hap Rosling Gapminderプロジェクトのデータのサンプルを含むgapminder
です。
library(tidyverse) library(gapminder) gapminder %>% ggplot(aes(x = year, y = lifeExp, color = continent))+ geom_jitter(size = 1, alpha = .2, width = .75)+ stat_summary(geom = "path", fun.y = mean, size = 1)+ theme_minimal(base_family = "mono")
URLデータセットを取得する
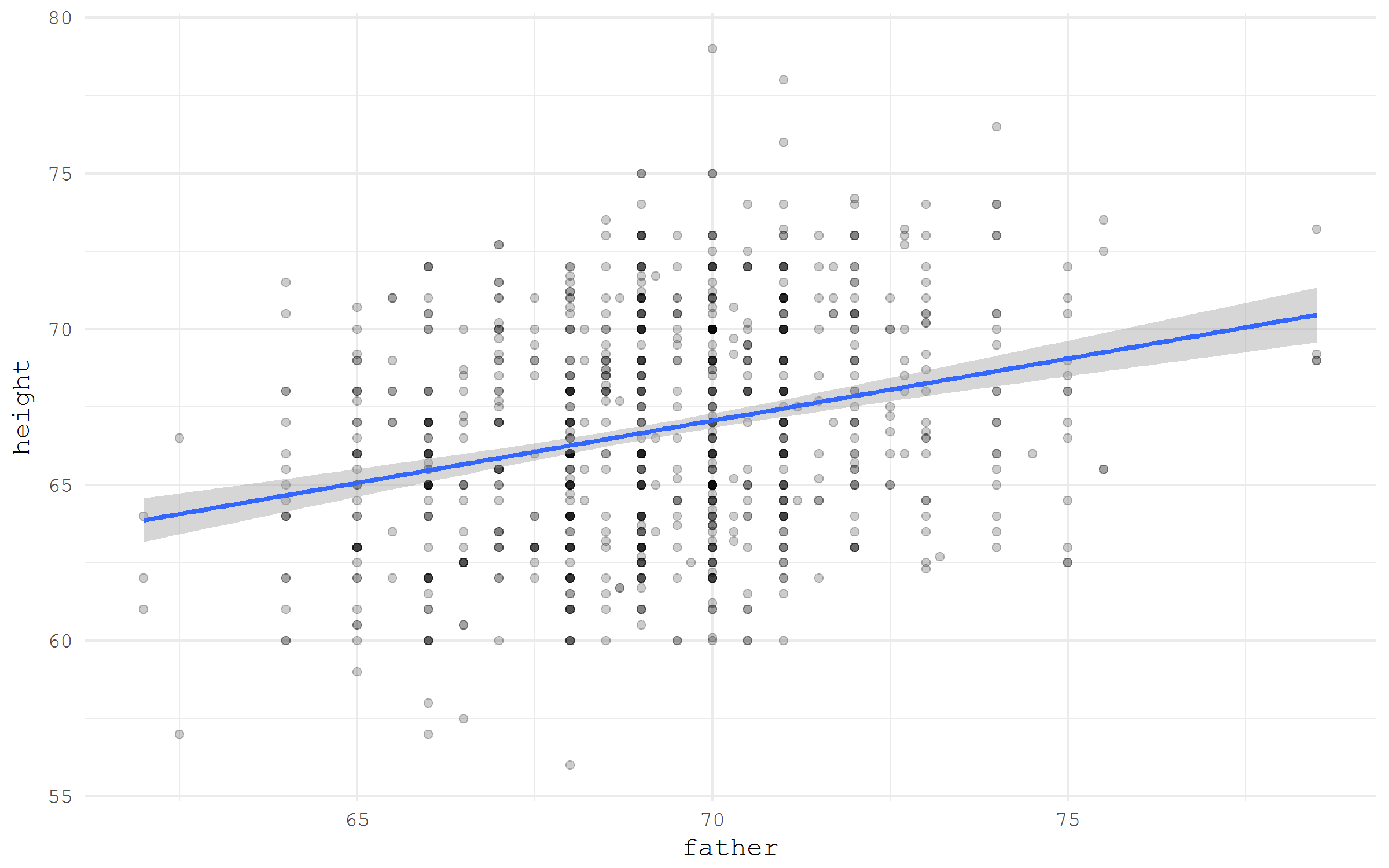
データセットがオンラインのどこかに保存されており、直接ダウンロードリンクがある場合、リンクを指定するだけでRでそれを読むことができます。 例として、 HistData
パッケージから父親と子供の成長に関する有名なGalton
データセットを取り上げましょう。 Vincent Arel-Bundockのリストから直接リンクデータを取得するだけです
library(tidyverse) galton <- read_csv("https://raw.githubusercontent.com/vincentarelbundock/Rdatasets/master/csv/HistData/Galton.csv") galton %>% ggplot(aes(x = father, y = height))+ geom_point(alpha = .2)+ stat_smooth(method = "lm")+ theme_minimal(base_family = "mono")
アーカイブをダウンロードして解凍します
多くの場合、データセットはインターネットにリリースされる前にアーカイブされます。 アーカイブの読み取りはすぐには機能しませんが、Rのソリューションは非常に簡単です。 プロセスのロジックは非常に単純です。まず、データを展開するディレクトリを作成します。 次に、アーカイブを一時ファイルにダウンロードします。 最後に、アーカイブを以前に作成したディレクトリに解凍します。 たとえば、ニューヨーク州政府から親切に提供され、open data.govデータリポジトリに保存されているニューヨークの犯罪データセットであるHistorical New York City Crime Dataをダウンロードします。
library(tidyverse) library(readxl) # create a directory for the unzipped data ifelse(!dir.exists("unzipped"), dir.create("unzipped"), "Directory already exists") # specify the URL of the archive url_zip <- "http://www.nyc.gov/html/nypd/downloads/zip/analysis_and_planning/citywide_historical_crime_data_archive.zip" # storing the archive in a temporary file f <- tempfile() download.file(url_zip, destfile = f) unzip(f, exdir = "unzipped/.")
ダウンロードされたアーカイブは非常に重い場合があり、コードを再生成するたびに再度ダウンロードしたくない場合があります。 この場合、元のアーカイブを保存し、一時ファイルを使用しないのが理にかなっています。
# if we want to keep the .zip file path_unzip <- "unzipped/data_archive.zip" ifelse(!file.exists(path_unzip), download.file(url_zip, path_unzip, mode="wb"), 'file alredy exists') unzip(path_unzip, exdir = "unzipped/.")
最後に、ダウンロードして解凍したデータをインポートして視覚化します。
murder <- read_xls("unzipped/Web Data 2010-2011/Seven Major Felony Offenses 2000 - 2011.xls", sheet = 1, range = "A5:M13") %>% filter(OFFENSE %>% substr(1, 6) == "MURDER") %>% gather("year", "value", 2:13) %>% mutate(year = year %>% as.numeric()) murder %>% ggplot(aes(year, value))+ geom_point()+ stat_smooth(method = "lm")+ theme_minimal(base_family = "mono")+ labs(title = "Murders in New York")

フィグシェア
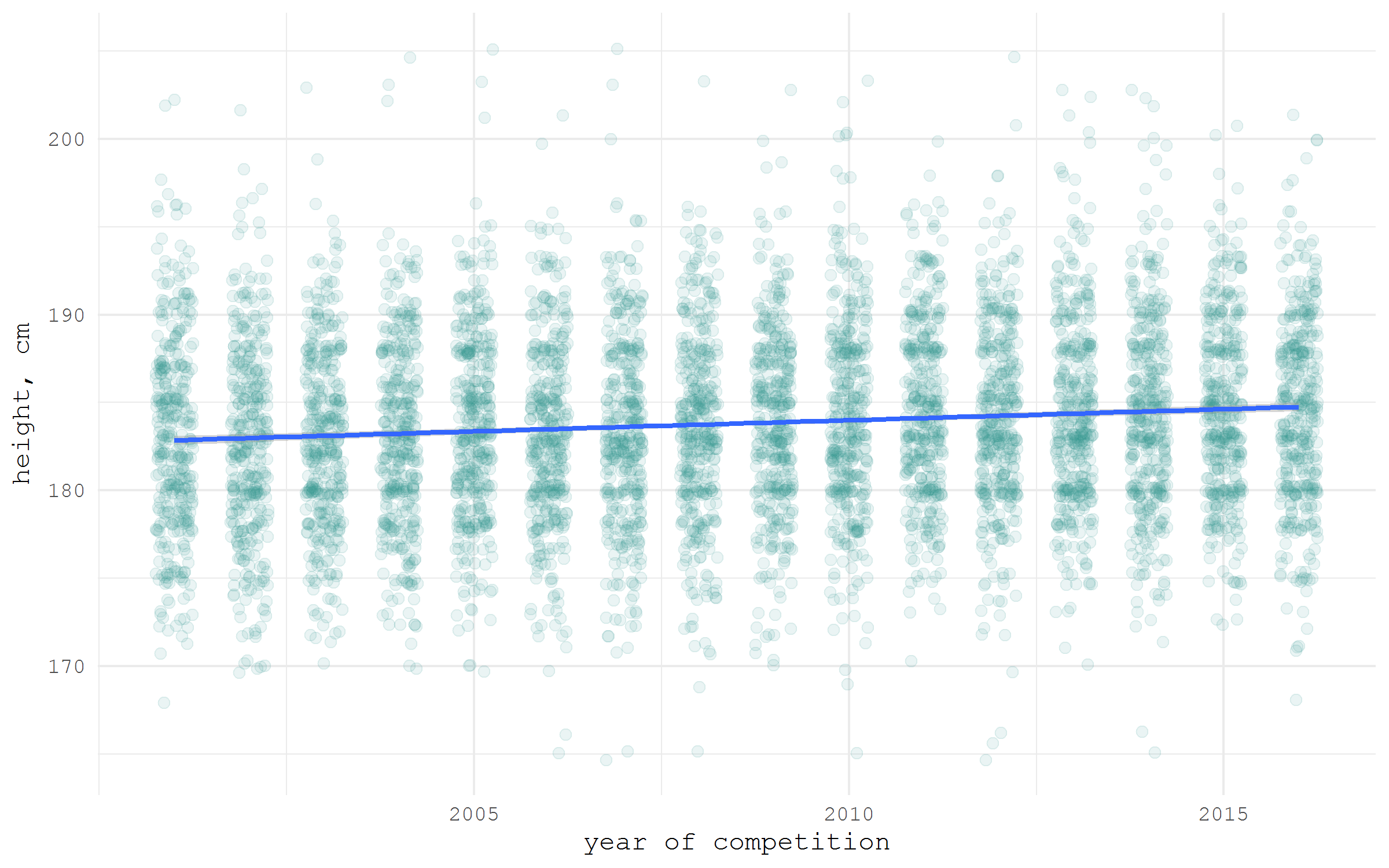
学問の世界では、結果の再現性の問題がますます深刻になっています。 したがって、ますますオープンに公開されたデータセットは、科学論文の忠実な仲間になりつつあります。 このようなデータセットには、多くの専用リポジトリがあります。 最も広く使用されているものの1つがFigshareです。 彼にはR- rfigshare
ラッパーがあります。 たとえば、ホッケー選手の成長に関する独自のデータセットをダウンロードします。 これは、Habréの以前の投稿の1つを書くために収集したものです 。 rfigshare
パッケージを初めて使用するときは、APIにアクセスするためにFigshareからログイン名とパスワードを入力するよう求められます。ブラウザで特別なWebページが開きます。
特別な関数fs_search
がありますが、私の経験では、興味のあるデータセットを見つけてRにダウンロードする一意の識別子をコピーする方が簡単ですfs_download
関数はidをファイルをダウンロードするための直接リンクに変換します。
library(tidyverse) library(rfigshare) url <- fs_download(article_id = "3394735") hockey <- read_csv(url) hockey %>% ggplot(aes(x = year, y = height))+ geom_jitter(size = 2, color = "#35978f", alpha = .1, width = .25)+ stat_smooth(method = "lm", size = 1)+ ylab("height, cm")+ xlab("year of competition")+ scale_x_continuous(breaks = seq(2005, 2015, 5), labels = seq(2005, 2015, 5))+ theme_minimal(base_family = "mono")
ユーロスタット
ユーロスタットは、欧州諸国とその地域に関する信じられないほどの量の統計をパブリックドメインで公開しています。 もちろん、このすべての富を得るための特別なeurostat
パッケージがあります。 残念なことに、組み込みのsearch_eurostat
関数search_eurostat
関連するデータセットを見つけるのsearch_eurostat
貧弱です。 たとえば、 life expectancy
は2つのオプションしかありませんが、実際には数十のデータセットが必要です。 したがって、最も便利なソリューションは次のようになります。EurostatのWebサイトにアクセスして 、興味のあるデータセットを見つけ、そのコードのみをコピーし、最後にeurostat
パッケージを使用してダウンロードします。 Eurostat地域統計はすべて別のデータベースにあることに注意してください。
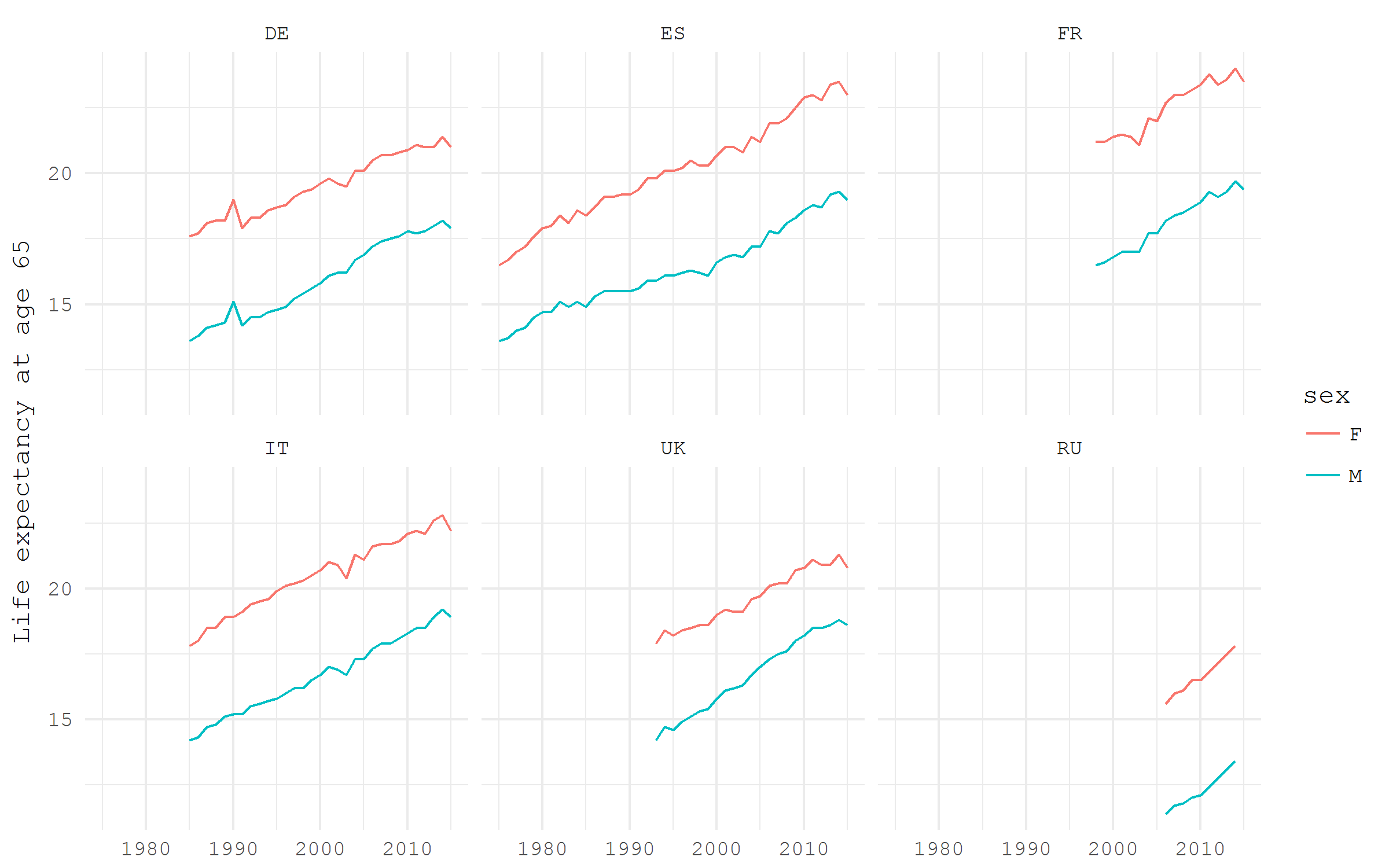
現在、ヨーロッパ諸国の平均余命に関するデータをダウンロードしています。 demo_mlexpec
コードはdemo_mlexpec
です。
library(tidyverse) library(lubridate) library(eurostat) # download the selected dataset e0 <- get_eurostat("demo_mlexpec")
データセットのサイズによっては、ダウンロードに時間がかかる場合があります。 この例では、400Kの観測値の中規模データセットがあります。 何らかの理由でデータセットを自動的にダウンロードできない場合(以前にデータセットを取得したことがない場合)、別のEurostat Webサイトから一括ダウンロードサービスを手動でダウンロードできます。
いくつかの選択されたヨーロッパ諸国の65歳での残りの平均余命を、男性と女性に分けて見てみましょう。 65歳は、最も一般的な伝統的な退職年齢です。 ダイナミクスにおけるこの年齢の残りの平均寿命を見るのは、定年の改革についての話に照らして非常に興味深いです。 ダウンロードしたデータから、65歳での平均余命の推定値のみを選択し、男性と女性の推定値のみを個別にフィルターで除外し、最後にドイツ、フランス、イタリア、ロシア、スペイン、英国の数カ国のみを残します。
e0 %>% filter(! sex == "T", age == "Y65", geo %in% c("DE", "FR", "IT", "RU", "ES", "UK")) %>% ggplot(aes(x = time %>% year(), y = values, color = sex))+ geom_path()+ facet_wrap(~ geo, ncol = 3)+ labs(y = "Life expectancy at age 65", x = NULL)+ theme_minimal(base_family = "mono")
世界銀行
Rからの世界銀行データへのアクセスを提供するパッケージがいくつかあります。おそらく、それらの中で最もwbstats
ているのは、かなり最近のwbstats
です。 そのwbsearch
関数は、関連するデータセットを見つけるのに非常にwbsearch
ます。 たとえば、 wbsearch("fertility")
は、339 wbsearch("fertility")
インジケーターの説明リストを便利なプレートの形式で表示します。
library(tidyverse) library(wbstats) # search for a dataset of interest wbsearch("fertility") %>% head
| indicatorID | 指標 | |
|---|---|---|
| 2479 | SP.DYN.WFRT.Q5 | 合計希望出生率(女性一人当たりの出生率):Q5(最高) |
| 2480 | SP.DYN.WFRT.Q4 | 合計希望受胎率(女性1人当たりの出生):第4四半期 |
| 2481 | SP.DYN.WFRT.Q3 | 合計希望受胎率(女性1人当たりの出生):第3四半期 |
| 2482 | SP.DYN.WFRT.Q2 | 合計希望出生率(女性1人当たりの出生):第2四半期 |
| 2483 | SP.DYN.WFRT.Q1 | 合計希望出生率(女性一人当たりの出生率):Q1(最低) |
| 2484 | SP.DYN.WFRT | 希望出生率(女性一人当たりの出生) |
Lifetime risk of maternal death (%)
(コードSH.MMR.RISK.ZS
)-子どもの誕生に関連する生涯にわたる女性の死亡Lifetime risk of maternal death (%)
指標を見てみましょう。 世界銀行は、国をグループ化するためのいくつかの異なるオプションと同様に国データを提供します。 注目すべきグループ化オプションの1つは、人口統計学的移行の完全性による分離です。 以下に、(1)APを既に完了している国、(2)APを完了していない国、および(3)全世界について選択したインジケータを表示します。
# fetch the selected dataset df_wb <- wb(indicator = "SH.MMR.RISK.ZS", startdate = 2000, enddate = 2015) # have look at the data for one year df_wb %>% filter(date == 2015) %>% View df_wb %>% filter(iso2c %in% c("V4", "V1", "1W")) %>% ggplot(aes(x = date %>% as.numeric(), y = value, color = country))+ geom_path(size = 1)+ scale_color_brewer(NULL, palette = "Dark2")+ labs(x = NULL, y = NULL, title = "Lifetime risk of maternal death (%)")+ theme_minimal(base_family = "mono")+ theme(panel.grid.minor = element_blank(), legend.position = c(.8, .9))

Oecd
経済協力開発機構(OECD)は、加盟国の経済的および人口統計学的開発に関する多くのデータを公開しています。 OECD
パッケージは、Rでのこのデータの使用を大幅に簡素化しますsearch_dataset
関数search_dataset
キーワードで必要なデータを見つけるのにget_dataset
、 get_dataset
は選択したデータセットをロードします。 次の例では、失業期間の長さに関するデータをダウンロードし、ヒートマップ視覚化方法を使用して、EU16、EU28、および米国の男性人口についてこのデータを表示します。
library(tidyverse) library(viridis) library(OECD) # search by keyword search_dataset("unemployment") %>% View # download the selected dataset df_oecd <- get_dataset("AVD_DUR") # turn variable names to lowercase names(df_oecd) <- names(df_oecd) %>% tolower() df_oecd %>% filter(country %in% c("EU16", "EU28", "USA"), sex == "MEN", ! age == "1524") %>% ggplot(aes(obstime, age, fill = obsvalue))+ geom_tile()+ scale_fill_viridis("Months", option = "B")+ scale_x_discrete(breaks = seq(1970, 2015, 5) %>% paste)+ facet_wrap(~ country, ncol = 1)+ labs(x = NULL, y = "Age groups", title = "Average duration of unemployment in months, males")+ theme_minimal(base_family = "mono")

WID
World Wealth and Income Databaseは、所得の不平等と富に関する調和した時系列データです。 データベース開発者は、これまでのところgithubでのみ利用可能な特別なパッケージRの作成を担当しました。
library(tidyverse) #install.packages("devtools") devtools::install_github("WIDworld/wid-r-tool") library(wid)
データをダウンロードするための関数はdownload_wid()
です。 データをダウンロードするための引数を正しく指定するには、パッケージのドキュメントを少し掘り下げて、かなり複雑な変数エンコードシステムを把握する必要があります。
?wid_series_type ?wid_concepts
上記の例は、 ビネットパッケージを改造したものです。 フランスと英国の人口の最も裕福な1%と10%が所有する富のシェアを表示します。
df_wid <- download_wid( indicators = "shweal", # Shares of personal wealth areas = c("FR", "GB"), # In France an Italy perc = c("p90p100", "p99p100") # Top 1% and top 10% ) df_wid %>% ggplot(aes(x = year, y = value, color = country)) + geom_path()+ labs(title = "Top 1% and top 10% personal wealth shares in France and Great Britain", y = "top share")+ facet_wrap(~ percentile)+ theme_minimal(base_family = "mono")

ヒト死亡率データベース
人間人口のダイナミクスの法則に関する大きな質問を確認する場合、 人間の死亡率データベースほど信頼できる情報源はありません。 このデータベースは、ソースデータを調和させるために最先端の方法論を使用する人口統計学者によって設計および管理されています。 HMDメソッドプロトコルは、人口統計データの方法論の傑作です。 逆に、十分に高品質のソースデータは、比較的少数の国でのみ利用可能です。 ユーザーが利用できるデータに慣れるために、 JonasSchöleyが作成した[Human Mortality Database Explorer] [exp]を心からお勧めします。
Tim HMDHFDplus
おかげで、わずか数行のコードでHMDデータをRに直接ロードできるHMDHFDplus
パッケージがあります。 データにアクセスするには、death.orgの無料アカウントが必要です。 パッケージの名前から推測できるように、同様に美しいHuman Fertility Databaseからデータをダウンロードすることもできます。
以下の例は以前の投稿から引用したもので、少し更新されています。 Rへの自動データ読み込みの全力を十分に示しているように思えます。女性と男性を別々に、利用可能なすべての年のすべてのHMD諸国の1年年齢構造を簡単かつ自然にダウンロードします。 このコードを再生するとき、数十メガバイトのデータがダウンロードされることを覚えておく価値があります。 次に、2012年にすべての国のすべての年齢で性比を計算して表示します。 性比は2つの主要な人口統計パターンを反映しています。1)より多くの男の子が常に生まれます。 2)男性の死亡率は、すべての年齢で女性よりも高い。 よく研究されたいくつかの例を除いて、出生時の性比は、100人の女の子あたり105〜106人の男の子です。 したがって、性比の年齢プロファイルの有意差は、主に死亡率の性差を反映しています。
# load required packages library(HMDHFDplus) library(tidyverse) library(purrr) # help function to list the available countries country <- getHMDcountries() # remove optional populations opt_pop <- c("FRACNP", "DEUTE", "DEUTW", "GBRCENW", "GBR_NP") country <- country[!country %in% opt_pop] # temporary function to download HMD data for a simgle county (dot = input) tempf_get_hmd <- . %>% readHMDweb("Exposures_1x1", ik_user_hmd, ik_pass_hmd) # download the data iteratively for all countries using purrr::map() exposures <- country %>% map(tempf_get_hmd) # data transformation to apply to each county dataframe tempf_trans_data <- . %>% select(Year, Age, Female, Male) %>% filter(Year %in% 2012) %>% select(-Year) %>% transmute(age = Age, ratio = Male / Female * 100) # perform transformation df_hmd <- exposures %>% map(tempf_trans_data) %>% bind_rows(.id = "country") # summarize all ages older than 90 (too jerky) df_hmd_90 <- df_hmd %>% filter(age %in% 90:110) %>% group_by(country) %>% summarise(ratio = ratio %>% mean(na.rm = T)) %>% ungroup() %>% transmute(country, age = 90, ratio) # insert summarized 90+ df_hmd_fin <- bind_rows(df_hmd %>% filter(!age %in% 90:110), df_hmd_90) # finaly - plot df_hmd_fin %>% ggplot(aes(age, ratio, color = country, group = country))+ geom_hline(yintercept = 100, color = "grey50", size = 1)+ geom_line(size = 1)+ scale_y_continuous(limits = c(0, 120), expand = c(0, 0), breaks = seq(0, 120, 20))+ scale_x_continuous(limits = c(0, 90), expand = c(0, 0), breaks = seq(0, 80, 20))+ facet_wrap(~country, ncol = 6)+ theme_minimal(base_family = "mono", base_size = 15)+ theme(legend.position = "none", panel.border = element_rect(size = .5, fill = NA, color = "grey50"))+ labs(x = "Age", y = "Sex ratio, males per 100 females", title = "Sex ratio in all countries from Human Mortality Database", subtitle = "HMD 2012, via HMDHFDplus by @timriffe1", caption = "ikashnitsky.github.io")
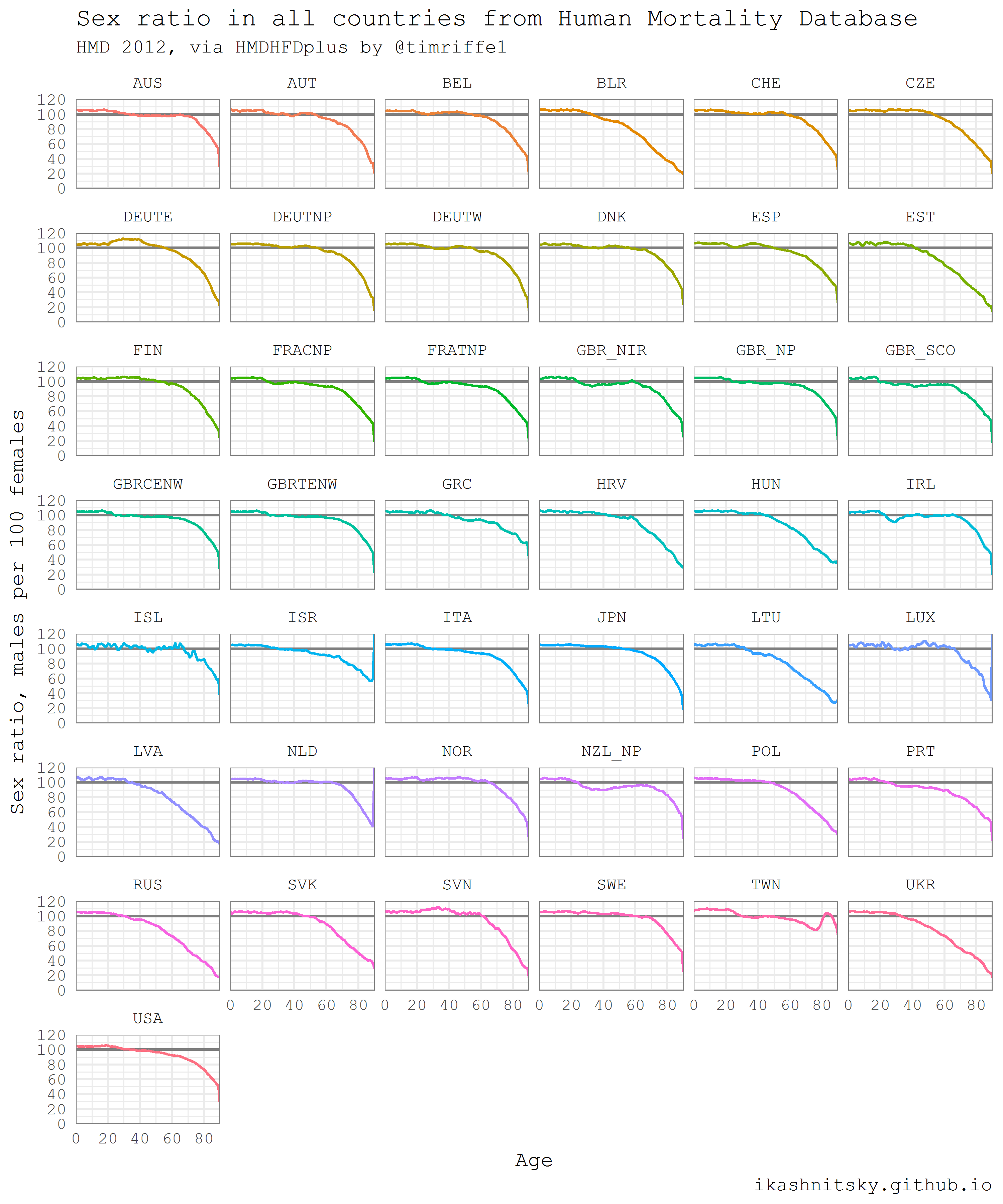
国連の世界人口見通し
国連人口省は、世界のすべての国に関する高品質の推定値と人口予測を公開しています。 計算は2〜3年ごとに更新され、 世界人口見通しのインタラクティブなレポートの形式で公開されます。 これらのレポートには、非常に一般的な記述分析と、もちろん豊富なデータが含まれています。 データはwpp20xx
ような名前を持つ特別なパッケージでRで利用可能です。 現在までに、2008、2010、2012、2015、および2017のリリースのデータを利用できます。 ここで、前回の投稿から取られたwpp2015
データを使用する例を示します。
クラウス・ウィルクの素晴らしいggridges
パッケージのおかげで、 ggjoy
夏(以前、 現在は拒否された ggjoy
名の下)にこの夏にggjoy
で人気を博したリッジプロットビジュアライゼーションタイプを使用して、1950年以降の世界の男性の平均寿命の印象的な収束を示します。
library(wpp2015) library(tidyverse) library(ggridges) library(viridis) # get the UN country names data(UNlocations) countries <- UNlocations %>% pull(name) %>% paste # data on male life expectancy at birth data(e0M) e0M %>% filter(country %in% countries) %>% select(-last.observed) %>% gather(period, value, 3:15) %>% ggplot(aes(x = value, y = period %>% fct_rev()))+ geom_density_ridges(aes(fill = period))+ scale_fill_viridis(discrete = T, option = "B", direction = -1, begin = .1, end = .9)+ labs(x = "Male life expectancy at birth", y = "Period", title = "Global convergence in male life expectancy at birth since 1950", subtitle = "UNPD World Population Prospects 2015 Revision, via wpp2015", caption = "ikashnitsky.github.io")+ theme_minimal(base_family = "mono")+ theme(legend.position = "none")
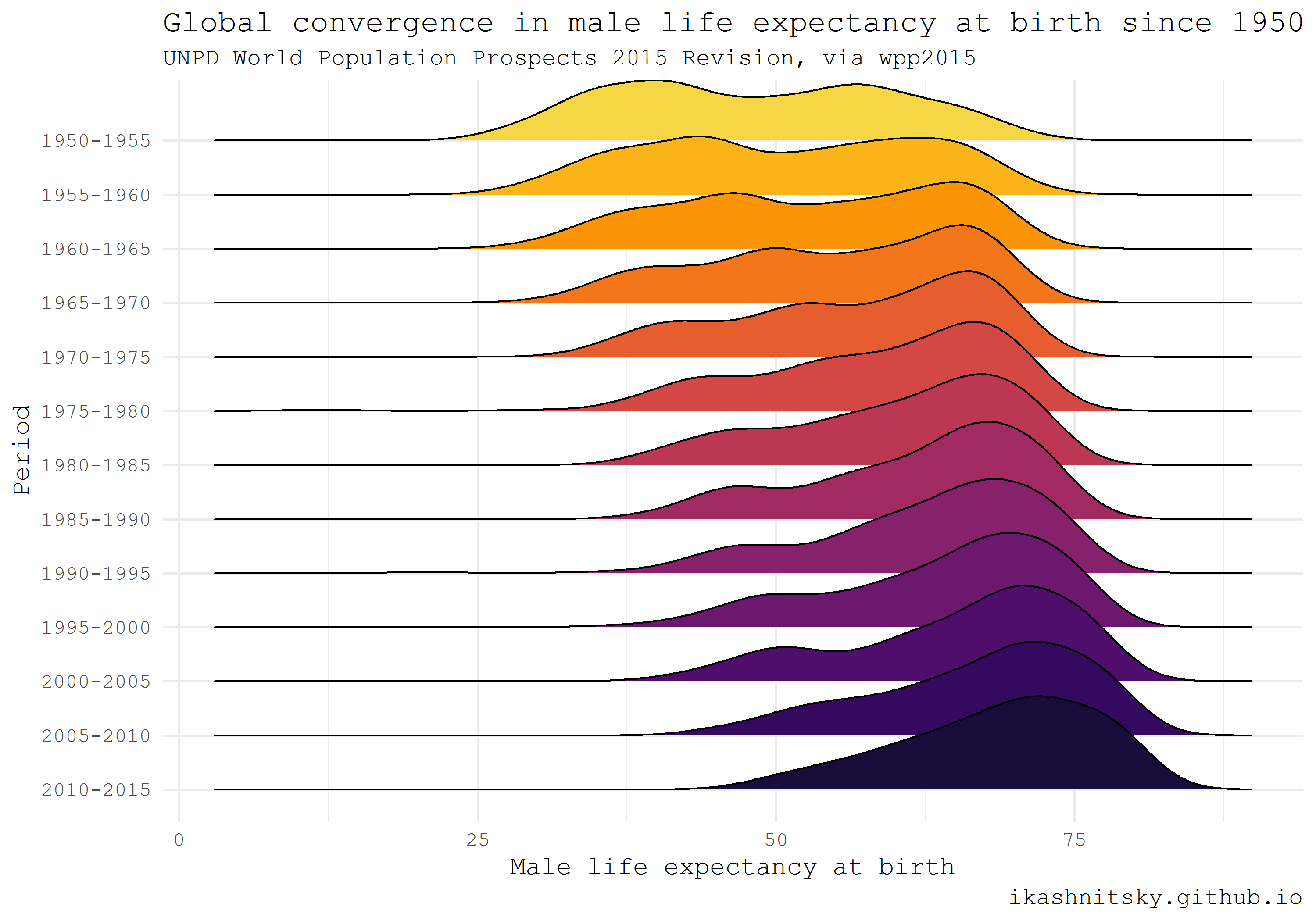
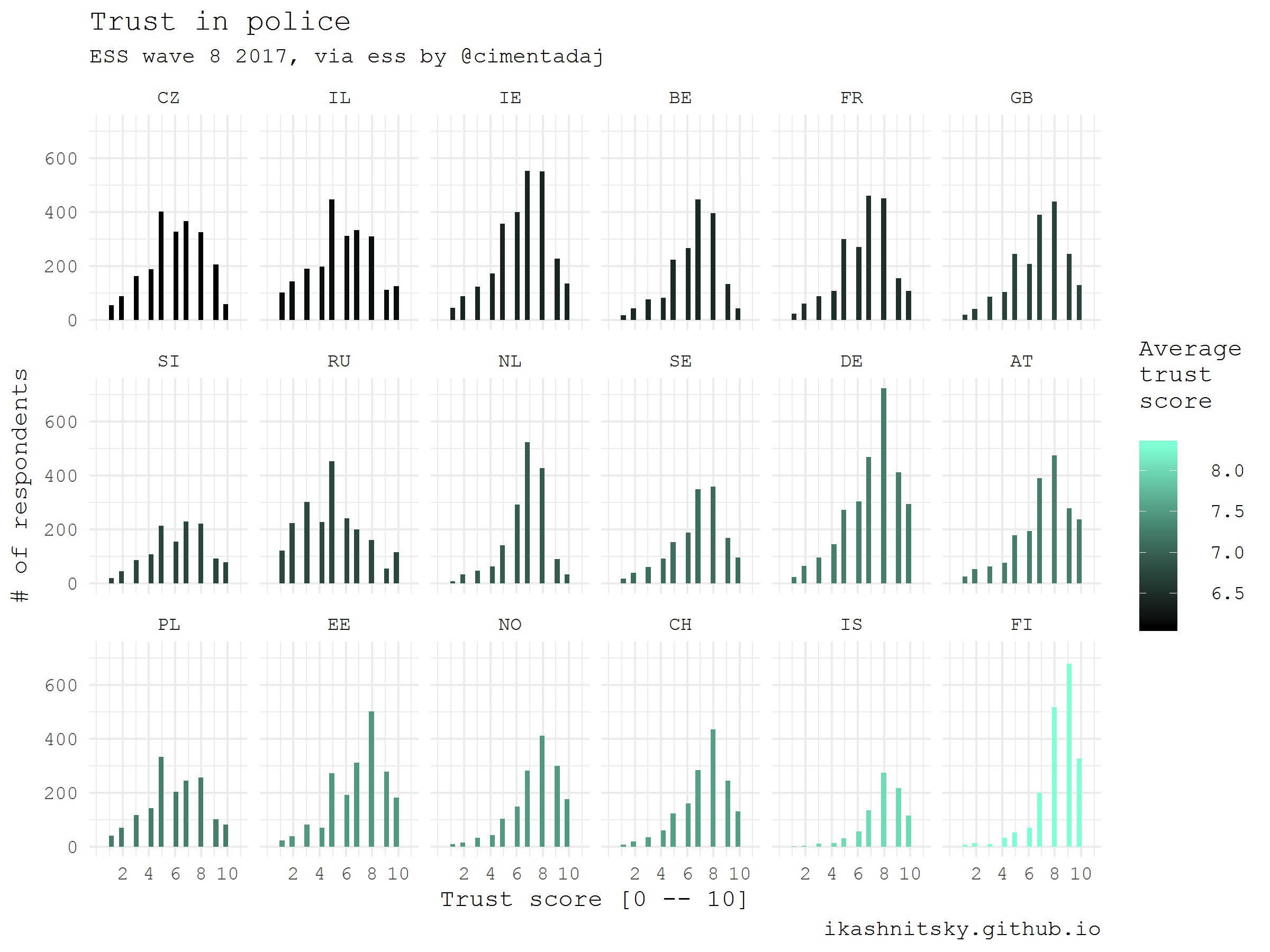
欧州社会調査(ESS)
欧州社会調査は、国レベルの代表であり、国間で比較可能なヨーロッパ人の価値に関する独自の詳細データを公開しています。 2年ごとに、参加国のそれぞれで別の調査が行われます。 データは無料登録後に入手できます。 データセットは、SAS、SPSS、またはSTATAを使用してすぐに分析できるように配布されます。 Jorge Cimentadaのおかげで、 ess
パッケージを使用してこのデータを準備し、Rで取得できるようになりました。 調査の最後の波に参加しているすべての国で、回答者が地元の警察に対する信頼レベルをどのように評価したかを示します。
library(ess) library(tidyverse) # help gunction to see the available countries show_countries() # check the available rounds for a selected country show_country_rounds("Netherlands") # get the full dataset of the last (8) round df_ess <- ess_rounds(8, your_email = ik_email) # select a variable and calculate mean value df_ess_select <- df_ess %>% bind_rows() %>% select(idno, cntry, trstplc) %>% group_by(cntry) %>% mutate(avg = trstplc %>% mean(na.rm = T)) %>% ungroup() %>% mutate(cntry = cntry %>% as_factor() %>% fct_reorder(avg)) df_ess_select %>% ggplot(aes(trstplc, fill = avg))+ geom_histogram()+ scale_x_continuous(limits = c(0, 11), breaks = seq(2, 10, 2))+ scale_fill_gradient("Average\ntrust\nscore", low = "black", high = "aquamarine")+ facet_wrap(~cntry, ncol = 6)+ theme_minimal(base_family = "mono")+ labs(x = "Trust score [0 -- 10]", y = "# of respondents", title = "Trust in police", subtitle = "ESS wave 8 2017, via ess by @cimentadaj", caption = "ikashnitsky.github.io")
アメリカのコミュニティ調査と国勢調査
いくつかのパッケージは、米国国勢調査のデータと定期的なアメリカのコミュニティ調査調査へのアクセスを提供します。 おそらく最も美しい実装は、最近Kyle Walker - tidycensus
によって作成されました。 このパッケージのキル機能は、統計とともに空間データをダウンロードする機能です。 空間データは単純な機能の形式でダウンロードされます。これは、Rのジオデータに対する革新的なアプローチで、最近sf
Edzer Pebesmaで導入されました 。 このアプローチにより、パスワードの処理が何十倍も高速化され、コードが不可能になります。 しかし、詳細はシリーズの最終投稿にあります。 シンプルな機能を描画するには、 ggplot2
パッケージの開発バージョンをインストールする必要があることに注意してください。
以下のマップは、2015年のACSデータによると、シカゴ市の国勢調査地区の人口の中央値を示しています。 tidycensus
を使用してこのデータを抽出tidycensus
は、最初にAPIキーを取得する必要があります。これは、 ここで登録するときに簡単に実行できます 。
library(tidycensus) library(tidyverse) library(viridis) library(janitor) library(sf) # to use geom_sf we need the latest development version of ggplot2 devtools::install_github("tidyverse/ggplot2", "develop") library(ggplot2) # you need a personal API key, available free at # https://api.census.gov/data/key_signup.html # normally, this key is to be stored in .Renviron # see state and county codes and names fips_codes %>% View # the available variables load_variables(year = 2015, dataset = "acs5") %>% View # data on median age of population in Chicago df_acs <- get_acs( geography = "tract", county = "Cook County", state = "IL", variables = "B01002_001E", year = 2015, key = ik_api_acs, geometry = TRUE ) %>% clean_names() # map the data df_acs %>% ggplot()+ geom_sf(aes(fill = estimate %>% cut(breaks = seq(20, 60, 10))), color = NA)+ scale_fill_viridis_d("Median age", begin = .4)+ coord_sf(datum = NA)+ theme_void(base_family = "mono")+ theme(legend.position = c(.15, .15))+ labs(title = "Median age of population in Chicago\nby census tracts\n", subtitle = "ACS 2015, via tidycensus by @kyle_e_walker", caption = "ikashnitsky.github.io", x = NULL, y = NULL)
