
この記事の執筆時点で、ほとんどの大規模なテクノロジー企業(IBM、Google、Microsoft、Amazonなど)は、使いやすい視覚認識APIを提供しています。 同様のツールは、クラリファイなどの小規模企業によって提供されています。 ただし、いずれもオブジェクトを検出する機能を提供しません(オブジェクト検出)。

両方の画像は、標準のWatson Visual Recognition分類器を使用したタグ付けの例を示しています。 最初の画像のみが最初にオブジェクト検出モデルを通過しました。
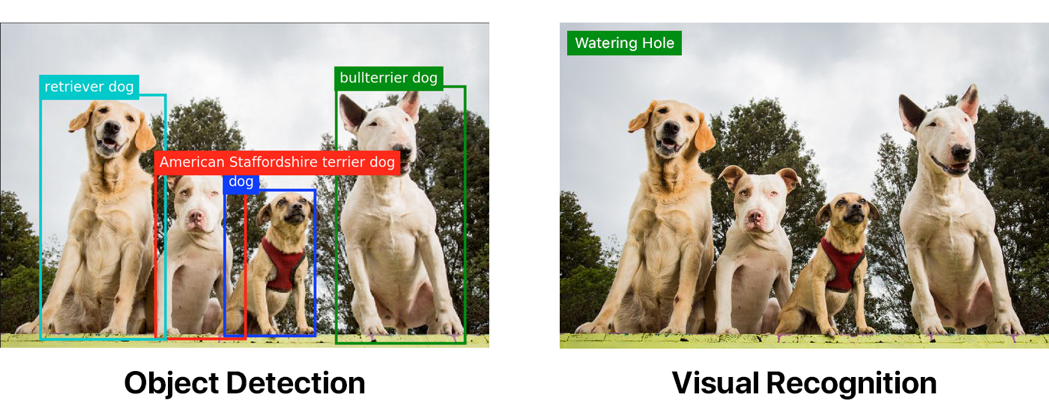
オブジェクト検出は、「単純な」視覚認識を大幅に上回ることができます。 ただし、オブジェクト検出を実装する場合は、一生懸命働く必要があります。
状況によっては、カスタムオブジェクト検出モデルが不要な場合があります。 対応するTensorFlow APIは、 COCOデータセットに基づいてパフォーマンスと精度が異なる複数のモデルを提供します。
便宜上、COCOモデルが検出できるオブジェクトの完全なリストをまとめました。

リストにないロゴなどを検出する場合は、独自のカスタム検出器を作成する必要があります。 私は、マシンがハン・ソロのミレニアム・ファルコン船とタイファイターの帝国戦闘機を検出することを望んでいました。 明らかに、これは非常に重要なタスクです。人生でいつ役に立つかわからないからです...
画像に注釈を付ける
モデルのトレーニングは時間のかかるタスクです。 あなたはおそらく考えました:「ねえ、私はここに骨を置きたくない!」 もしそうなら、完成したモデルの使用に関する私の記事を読むことができます。 この方法ははるかに簡単です。
多くの画像を収集して注釈を付ける必要があります。 これらには、オブジェクトの座標の決定と対応する指定が含まれます。 Tie Fighterアノテーションが2つある画像の場合、次のようになります。
<annotation> <folder>images</folder> <filename>image1.jpg</filename> <size> <width>1000</width> <height>563</height> </size> <segmented>0</segmented> <object> <name>Tie Fighter</name> <bndbox> <xmin>112</xmin> <ymin>281</ymin> <xmax>122</xmax> <ymax>291</ymax> </bndbox> </object> <object> <name>Tie Fighter</name> <bndbox> <xmin>87</xmin> <ymin>260</ymin> <xmax>95</xmax> <ymax>268</ymax> </bndbox> </object> </annotation>
スターウォーズで動作するモデルの場合、308個の画像を収集しました。各画像には2〜3個のオブジェクトが含まれています。 少なくとも200〜300個の各オブジェクトの例を収集することをお勧めします。
数百の画像をシャベルで削って、すべての人のために大量のXMLを作成する必要があると思いましたか?
もちろん違います! labelImgやRectLabelなど、注釈を付けるための多くのツールがあります。 RectLabelを使用しましたが 、macOS専用です。 ツールは汗をかかなければなりませんが、私を信じてください。 データセット全体に注釈を付けるには、3〜4時間の継続的な作業が必要でした。
お金があれば、彼はこのために誰かを雇うことができます。 または、 Mechanical Turkのようなものを使用します。 あなたが私のような貧しい学生であり、そして/または何時間もの単調な仕事が好きなら、あなたは自分で注釈を付けることができます。
変換スクリプトを記述したくない場合は、注釈を記述するときに、PASCAL VOC形式でエクスポートされていることを確認してください。 私を含め、多くの人がそれを使用しているので、上記のスクリプトを借りることができます(私自身は誰かから借りました)。
スクリプトを実行する前に、TensorFlowを処理するためのデータを準備する必要があります。
リポジトリのクローニング
最初にリポジトリを複製します 。 ディレクトリ構造は次のようになります。
models |-- annotations | |-- label_map.pbtxt | |-- trainval.txt | `-- xmls | |-- 1.xml | |-- 2.xml | |-- 3.xml | `-- ... |-- images | |-- 1.jpg | |-- 2.jpg | |-- 3.jpg | `-- ... |-- object_detection | `-- ... `-- ...
そこにトレーニングデータを含めたので、すぐにすべてを実行できます。 ただし、データを使用してモデルを作成する場合は、トレーニング画像を画像に追加し、XML注釈を注釈/ xmlに追加する必要があり、trainval.txtとlabel_map.pbtxtを更新する必要もあります。
trainval.txtは、JPGファイルとXMLファイルを検索して関連付けることができるファイルのリストです。 以下はtrainval.txtリストの内容で、abc.jpg、abc.xml、123.jpg、123.xml、xyz.jpg、xyz.xmlを検索できます。
abc 123 xyz
注:拡張子を除いて、.jpgファイルと.xmlファイルの名前が同じであることを確認してください。
label_map.pbtxt-検出するオブジェクトのリスト。 次のようになります。
item { id: 1 name: 'Millennium Falcon' } item { id: 2 name: 'Tie Fighter' }
スクリプト実行
Pythonとpipをインストールしてから、スクリプト要件をインストールします。
pip install -r requirements.txt
models
と
models/slim
を
PYTHONPATH
追加し
models
。
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
重要 :このコマンドは、ターミナルが起動するたびに実行する必要があります。 または、
~/.bashrc
追加し
~/.bashrc
。
スクリプトを実行します。
python object_detection/create_tf_record.py
作業が終了すると、train.recordおよびval.recordファイルが作成されます。 これらを使用してモデルをトレーニングします。
基本モデルをダウンロードする
複数のビデオカードを使用している場合でも、オブジェクト検出器をゼロから学習するには数日かかる場合があります 。 プロセスを高速化するために、別のデータセットで既にトレーニングされた検出器を使用し、そのパラメーターの一部を使用して新しいモデルを初期化します。
ここからモデルをダウンロードできます。 ここでは、すべてのモデルの精度と速度が異なります。
faster_rcnn_resnet101_coco
を使用し
faster_rcnn_resnet101_coco
。
すべてのmodel.ckptファイルを抽出し、リポジトリのルートディレクトリに転送します。
faster_rcnn_resnet101.configファイルが必要です。 これらは、
faster_rcnn_resnet101_coco
モデルを操作するための設定です。 別のモデルを使用した場合は、対応する構成ファイルをここで見つけることができます。
教えられる
スクリプトを実行すると、トレーニングが開始されます!
python object_detection/train.py \ --logtostderr \ --train_dir=train \ --pipeline_config_path=faster_rcnn_resnet101.config
注:
pipeline_config_path
を構成ファイルへのパスに置き換えます。
global step 1: global step 2: global step 3: global step 4: ...
やった! うまくいく!
10分後。
global step 41: global step 42: global step 43: global step 44: ...
コンピューターは喫煙を開始します。
global step 71: global step 72: global step 73: global step 74: ...
これはいつまで続きますか?
ヘッダーGIFで使用したモデルは、約22,000サイクルでした。
なに?
MacBook Proを使用しました。 このモデルを同様のマシンで実行する場合、各サイクルには約15秒かかると想定しています。 このようなペースで、適切なモデルを取得するには、3〜4日間の継続的な作業が必要です。
バカだ、そんなに時間がない
PowerAIが助けになります!
パワーアイ
PowerAIを使用すると、P100 GPUを搭載したIBM Power Systemsでモデルをトレーニングできます。
1時間から10,000サイクルかかりました。 そして、それはたった1つのGPUでした。 PowerAIの真の力は、95パーセントの効率で何百ものGPUを使用して分散学習を提供できることにあります。
PowerAIのおかげで、IBMは最近、7時間で33.8%の精度で画像認識のトレーニングの新記録を樹立しました。 以前の記録はマイクロソフトのものでした-10日間で29.9%の精度。
とても速い!
私は何百万もの画像を訓練していないので、そのようなリソースは絶対に必要ありません。 1つのプロセッサで十分です。
Nimbixアカウントの作成
Nimbixは、開発者にPowerAIプラットフォームでの10時間の無料作業の試用アカウントを提供します。 ここで登録できます 。
注:登録は自動ではないため、承認には最大24時間かかる場合があります。
登録が承認されると、アカウントの確認と作成の手順が記載されたメールが届きます。 プロモーションコードの入力を求められますが、フィールドは空白のままにします。
ここでログインできます。
PowerAIノートブックの展開
PowerAIノートブックを検索します。

結果をクリックして、TensorFlowを選択します。

マシンタイプ32スレッドPOWER8、128GB RAM、1 x P100 GPU w / NVLink(np8g1)を選択します。

下の図のように、パネルが表示されます。 サーバーのステータスが処理中になると、サーバーにアクセスできます。
(クリックして表示)をクリックしてパスワードを取得します。
次に、ここをクリックして接続し、ノートブックを起動します。
名前nimbixと受信したパスワードでログインします。

トレーニングを開始
[新規]ポップアップメニューをクリックし、[ターミナル]を選択して、新しいターミナルウィンドウを開きます。

おなじみのインターフェイスに会います:

注:端末はSafariで動作しない場合があります。
学習プロセスは、ローカルコンピューターと同じ方法で開始されます。 トレーニングデータを使用する場合は、次のコマンドを使用してリポジトリを複製します。
git clone github.com/bourdakos1/Custom-Object-Detection.git
または、リポジトリを複製します。 次に、ルートディレクトリ内でcdを実行します。
cd Custom-Object-Detection
以前にダウンロードした事前学習済みのfaster_rcnn_resnet101_cocoモデルをダウンロードする以下のコードを実行します。
wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz tar -xvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz mv faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.*
次に、新しいターミナルがあるので、PYTHONPATHを再度更新します。
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
これで、トレーニング起動コマンドを実行できます。
python object_detection/train.py \ --logtostderr \ --train_dir=train \ --pipeline_config_path=faster_rcnn_resnet101.config
モデルをダウンロードする
モデルの準備はいつですか? トレーニングデータに依存します。 それらが多いほど、運転する必要のあるサイクルが多くなります。 私は約4500サイクル後にかなり賢明なモデルを得ました。 そして、約20,000サイクルでピークに達しました。 一般に、200,000サイクルを運転しましたが、モデルはそれ以上良くなりませんでした。
5000サイクルごとにモデルをダウンロードし、パフォーマンスを評価して正しい方向に進んでいるかどうかを確認することをお勧めします。 左上隅のJupyterロゴをクリックし、ファイルツリーを介してCustom-Object-Detection / trainに移動します。
名前が最も大きいすべてのmodel.ckptファイルをダウンロードします。
•model.ckpt-STEP_NUMBER.data-00000-of-00001
•model.ckpt-STEP_NUMBER.index
•model.ckpt-STEP_NUMBER.meta
注:一度にダウンロードできるファイルは1つだけです。

注:トレーニングを完了した後、赤いボタンをクリックしてください。そうしないと、時計が永遠に続きます。
結果グラフのエクスポート
コードでモデルを使用するには、チェックポイントファイル(model.ckpt-STEP_NUMBER。*)を固定結果グラフ( 推論グラフ )に変換する必要があります。
ダウンロードしたチェックポイントファイルをリポジトリのルートフォルダーに転送します。
次に、次のコマンドを実行します。
python object_detection/export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path faster_rcnn_resnet101.config \ --trained_checkpoint_prefix model.ckpt-STEP_NUMBER \ --output_directory output_inference_graph
PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
をエクスポートする
PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
忘れないでください。
新しいディレクトリ
output_inference_graph
がファイル
frozen_inference_graph.pb
とともに表示されます。 彼が必要です。
モデルテスト
次のコマンドを実行します。
python object_detection/object_detection_runner.py
output_inference_graph / frozen_inference_graph.pbにあるオブジェクト検出モデルをtest_imagesディレクトリ内のすべての画像に適用し、結果をoutput / test_imagesディレクトリに書き込みます。
結果
Star Wars:The Force Awakensのパッセージのすべてのフレームでモデルを実行すると、これが得られます。