
いくつかの歌詞
昔、草がより緑で木がより高かったとき、ストリームの分岐、キャッシュの欠落、グローバルメモリアクセスの合体などの恐ろしい言葉は、GPUで複数の検索タスクを効果的に実装できないと固く信じていました。 年が経過しても、自信は消えませんでしたが、ある時点でPFACライブラリに出会いました。 彼女の能力に興味があるなら、猫へようこそ。
なぜこれすべて
なぜこれを行うのか、何を取得したいのか? 最も興味深い事実は、PFACライブラリのパフォーマンスです。 GPUを使用して得られる高速の作業を取得したいと思います。 比較のために、PFACアルゴリズムのCPUおよびOpenMP実装を使用します。
読者はCUDAアーキテクチャについてある程度理解していると思います。 それでもこれが当てはまらない場合は、基本的なアイデアを記事で見つけることができます 。たとえばhereやhereです。
図書館について
PFACライブラリは2012年に開発され、当時のビデオカードのアーキテクチャと機能に適応していたため、3.0以下の計算機能を備えたビデオカードをお持ちの場合は、ubuntu 12.04とcuda 4.2をすぐにインストールできます。 ただし、簡単な方法は探していません。この記事では、ubuntu 16.04およびcuda 9.0を使用します。 テストベンチでは、Intel Core i7-7500U、GeForce 940MX、および8 GB RAMを搭載したラップトップを使用します。
戦闘に突入してギガビットを数える前に、私たちが待ち望んでいることを理解するために、アルゴリズムの部分についていくつかの言葉を述べます。
このライブラリは、下降なしの並列アルゴリズムAho-Korasikを実装しています。 PFACは、それぞれParallel Failureless Aho-Corasickの略です。 このアルゴリズムは、下降なしでプレフィックスツリーを構築し、テーブルにパックします。
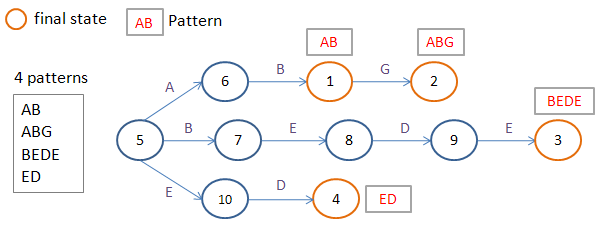
ドキュメントに記載されているように、各スレッドは入力文字から始まるデータを処理します。

ただし、ソースを見ると、各スレッドは4文字を処理しており、これはメモリアライメントに関連付けられています。
私が記事を始めたすべての恐ろしい言葉は、この決定にあるべき場所を持っています。 同じワープ内のすべてのスレッド(同じブロック内の32の連続するスレッド)が、狭い間隔のテーブルデータを処理することを保証するものはありません。 また、ワープ内のすべてのスレッドが同じブランチブランチを通過したり、一度にツリーを通過するサイクルを終了したりするという保証もありません。
しかし、私は悪いことについて考えないことを提案し、燃えるような目と楽観的な態度で、計算実験を開始します。
展開
まず、PFACを展開してみましょう。 CUDAはすでにインストールされており、nvccとライブラリへのパスが追加されていると思います。
私たちはプロジェクトに入ります。 待っています-すべて順調です。 厳しい現実-いくつかの奇妙な間違い。 CUDA 9.0の場合、3.0未満の計算機能を備えたビデオカードのアセンブリは非推奨になりました。 これは戦うことができます。 src / Makefileを変更するだけです。
計算機能5.0のMakefileの例。
# # Makefile in directory src # # resource usage: # # To compile a dynamic module # (1) nvcc cannot accept -fPIC, so compile .cu to .cu.cpp first # nvcc -arch=sm_50 -cuda ../src/PFAC_kernel.cu # # (2) then use g++ to comple PFAC_notex_shared_reorder.cu.cpp # g++ -fPIC -c PFAC_kernel.cu.cpp # # (3) finally combine two object files to a .so library # g++ -shared -o libpfac.so $(LIBS) PFAC_kernel.cu.o ... # # $(LIBS) is necessary when compiling PFAC library on 32-bit machine # include ../common.mk INC_DIR = ../include LIB_DIR = ../lib OBJ_DIR = ../obj INCPATH += -I../include/ CU_SRC = PFAC_kernel.cu CU_SRC += PFAC_reduce_kernel.cu CU_SRC += PFAC_reduce_inplace_kernel.cu CU_SRC += PFAC_kernel_spaceDriven.cu CPP_SRC = PFAC_reorder_Table.cpp CPP_SRC += PFAC_CPU.cpp CPP_SRC += PFAC_CPU_OMP.cpp CPP_SRC += PFAC.cpp inc_files = $(INC_DIR)/PFAC_P.h $(INC_DIR)/PFAC.h 35 CU_OBJ = $(patsubst %.cu,%.o,$(CU_SRC)) CU_CPP = $(patsubst %.cu,%.cu.cpp,$(CU_SRC)) CPP_OBJ = $(patsubst %.cpp,%.o,$(CPP_SRC)) cppobj_loc = $(patsubst %.o,$(OBJ_DIR)/%.o,$(CPP_OBJ)) cppobj_fpic_loc = $(patsubst %.o,$(OBJ_DIR)/%_fpic.o,$(CPP_OBJ)) cu_cpp_sm50_loc = $(patsubst %.cpp,$(OBJ_DIR)/sm50_%.cpp,$(CU_CPP)) cu_cpp_obj_sm50_loc = $(patsubst %.cpp,$(OBJ_DIR)/sm50_%.cpp.o,$(CU_CPP)) all: mk_libso_no50 mk_lib_fpic mk_libso_no50: $(cu_cpp_sm50_loc) $(CXX) -shared -o $(LIB_DIR)/libpfac_sm50.so $(LIBS) $(cu_cpp_obj_sm50_loc) mk_liba: $(cppobj_loc) ar cru $(LIB_DIR)/libpfac.a $(cppobj_loc) ranlib $(LIB_DIR)/libpfac.a mk_lib_fpic: $(cppobj_fpic_loc) $(CXX) -shared -o $(LIB_DIR)/libpfac.so $(cppobj_fpic_loc) $(LIBS) $(OBJ_DIR)/%_fpic.o: %.cpp $(inc_files) $(CXX) -fPIC -c $(CXXFLAGS) $(INCPATH) -o $@ $< $(OBJ_DIR)/PFAC_CPU_OMP_reorder_fpic.o: PFAC_CPU_OMP_reorder.cpp $(inc_files) $(CXX) -fPIC -c $(CXXFLAGS) $(INCPATH) -o $@ $< $(OBJ_DIR)/PFAC_CPU_OMP_reorder.o: PFAC_CPU_OMP_reorder.cpp $(inc_files) $(CXX) -c $(CXXFLAGS) $(INCPATH) -o $@ $< $(OBJ_DIR)/%.o: %.cpp $(inc_files) $(CXX) -c $(CXXFLAGS) $(INCPATH) -o $@ $< $(OBJ_DIR)/sm50_%.cu.cpp: %.cu $(NVCC) -arch=sm_50 -cuda $(INCPATH) -o $@ $< $(CXX) -fPIC -O2 -c -o $@.o $@ #clean : # rm -f *.linkinfo # rm -f $(OBJ_DIR)/* # rm -f $(EXE_DIR)/* ####### Implicit rules .SUFFIXES: .o .c .cpp .cc .cxx .C .cpp.o: $(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<" .cc.o: $(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<" .cxx.o: $(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<" .Co: $(CXX) -c $(CXXFLAGS) $(INCPATH) -o "$@" "$<" .co: $(CC) -c $(CFLAGS) $(INCPATH) -o "$@" "$<" ####### Build rules
再組み立てします。
ふう! すべてがうまくいくようです。 LD_LIBRARY_PATHのlibフォルダーにパスを追加します。 テスト例simple_exampleを実行しようとします-エラーがクラッシュします:
simple_example.cpp:64: int main(int, char**): Assertion `PFAC_STATUS_SUCCESS == PFAC_status' failed.
出力PFAC_statusを追加すると、PFAC_STATUS_ARCH_MISMATCHに対応するステータス10008が取得されます。 不明な理由により、アーキテクチャはサポートされていません。
コードの詳細を確認してください。 src / PFAC.cppファイルには、このステータスを生成する次のコードがあります。
ifsはあまり起こりません
int device_no = 10*deviceProp.major + deviceProp.minor ; if ( 30 == device_no ){ strcpy (modulepath, "libpfac_sm30.so"); }else if ( 21 == device_no ){ strcpy (modulepath, "libpfac_sm21.so"); }else if ( 20 == device_no ){ strcpy (modulepath, "libpfac_sm20.so"); }else if ( 13 == device_no ){ strcpy (modulepath, "libpfac_sm13.so"); }else if ( 12 == device_no ){ strcpy (modulepath, "libpfac_sm12.so"); }else if ( 11 == device_no ){ strcpy (modulepath, "libpfac_sm11.so"); }else{ return PFAC_STATUS_ARCH_MISMATCH ; }
その隣のコメントから、コードが計算機能1.0でのみ機能しないことが明らかになります。 このフラグメントを
int device_no = 10*deviceProp.major + deviceProp.minor ; if ( 11 > device_no ) return PFAC_STATUS_ARCH_MISMATCH ; sprintf(modulepath, "libpfac_sm%d.so", device_no);
今はすべて順調です。 ビデオカードのコンピューティング機能のバージョンに対するこれ以上の明らかな依存関係は観察されません。
繰り返しますが、テストバージョンを実行してみてください。 奇妙なエラーが見られます:
Error: fails to PFAC_matchFromHost, PFAC_STATUS_CUDA_ALLOC_FAILED: allocation fails on device memory.
幸いなことに、ライブラリ内のデバッグ情報を有効にする方法があります。
include / PFAC_P.hファイルで、行のコメントを外す必要があります
#define PFAC_PRINTF( ... ) printf( __VA_ARGS__ )
そして、それに応じて、コメント
//#define PFAC_PRINTF(...)
これで、simple_exampleを実行した後、より明確なエラーメッセージを確認できます。
Error: cannot bind texture, 11264 bytes invalid texture reference
Error: fails to PFAC_matchFromHost, PFAC_STATUS_CUDA_ALLOC_FAILED: allocation fails on device memory
ええ、つまり、問題はメモリの割り当てではなく、テクスチャメモリの使用にあるということです。 PFACでは、テクスチャメモリを無効にできます。 これを活用してみましょう。 test / simple_example.cppファイルで、ハンドルを作成した後、次の行を追加します。
PFAC_setTextureMode(handle, PFAC_TEXTURE_OFF ) ;
奇跡が起こった、コンソールは私たちに待望のラインを与えました。
何かが見つかりました
At position 0, match pattern 1
At position 1, match pattern 3
At position 2, match pattern 4
At position 4, match pattern 4
At position 6, match pattern 2
ただし、古代の原稿では、テクスチャキャッシュを使用すると、テクスチャメモリのパフォーマンスが向上することが示唆されています。 それでは、テクスチャメモリを使用してPFACを実行してみましょう。
PFACは、PFAC_TIME_DRIVENとPFAC_SPACE_DRIVENの2つの操作モードをサポートしています。 最初に興味があります。 実装はsrc / PFAC_kernel.cuファイルにあります。
テクスチャメモリがグローバルメモリにマウントされている行を見つけます。
cuda_status = cudaBindTexture( &offset, (const struct textureReference*) texRefTable, (const void*) handle->d_PFAC_table, (const struct cudaChannelFormatDesc*) &channelDesc, handle->sizeOfTableInBytes ) ;
計算機能が5.0以降のビデオカードの場合、テクスチャメモリ操作の実装がわずかに変更され、アクセスモードの設定が正しくないため、この行を次のように置き換えます。
cuda_status = cudaBindTexture( &offset, tex_PFAC_table, (const void*) handle->d_PFAC_table, handle->sizeOfTableInBytes ) ;
その後、ファイルtest / simple_example.cppで、テクスチャメモリを再度オンにします。
PFAC_setTextureMode(handle, PFAC_TEXTURE_ON ) ;
作業を確認します-すべてが機能します。
テストと比較
次に、ライブラリのパフォーマンスを見てみましょう。
テストには、 clamAVが提供する署名を使用します
main.cvdファイルをダウンロードします。 次に、開梱
dd if=main.cvd of=main.tar.gz bs=512 skip=1 tar xzvf main.tar.gz
main.mdbファイルの署名をテストします。 n行をカットしてパターンを考慮し、入力データをシャッフルします。 ここで詳しく説明する価値はないと思います。
パフォーマンスをいじるために、ファイルtest / simple_example.cppを少し変更しました
今日はこんな感じ
#include <stdio.h> #include <iostream> #include <stdlib.h> #include <string.h> #include <assert.h> #include <chrono> #include <PFAC.h> int main(int argc, char **argv) { if(argc < 2){ printf("args input file, input pattern\n" ); return 0; } char dumpTableFile[] = "table.txt" ; char *inputFile = argv[1]; //"../test/data/example_input" ; char *patternFile = argv[2];//"../test/pattern/example_pattern" ; PFAC_handle_t handle ; PFAC_status_t PFAC_status ; int input_size ; char *h_inputString = NULL ; int *h_matched_result = NULL ; // step 1: create PFAC handle PFAC_status = PFAC_create( &handle ) ; PFAC_status = PFAC_setTextureMode(handle, PFAC_TEXTURE_OFF); printf("%d\n", PFAC_status); assert( PFAC_STATUS_SUCCESS == PFAC_status ); // step 2: read patterns and dump transition table PFAC_status = PFAC_readPatternFromFile( handle, patternFile) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to read pattern from file, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } // dump transition table FILE *table_fp = fopen( dumpTableFile, "w") ; assert( NULL != table_fp ) ; PFAC_status = PFAC_dumpTransitionTable( handle, table_fp ); fclose( table_fp ) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to dump transition table, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } //step 3: prepare input stream FILE* fpin = fopen( inputFile, "rb"); assert ( NULL != fpin ) ; // obtain file size fseek (fpin , 0 , SEEK_END); input_size = ftell (fpin); rewind (fpin); // allocate memory to contain the whole file h_inputString = (char *) malloc (sizeof(char)*input_size); assert( NULL != h_inputString ); h_matched_result = (int *) malloc (sizeof(int)*input_size); assert( NULL != h_matched_result ); memset( h_matched_result, 0, sizeof(int)*input_size ) ; // copy the file into the buffer input_size = fread (h_inputString, 1, input_size, fpin); fclose(fpin); auto started = std::chrono::high_resolution_clock::now(); // step 4: run PFAC on GPU PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } auto done = std::chrono::high_resolution_clock::now(); std::cout << "gpu_time: " << std::chrono::duration_cast<std::chrono::milliseconds>(done-started).count()<< std::endl; memset( h_matched_result, 0, sizeof(int)*input_size ) ; PFAC_setPlatform(handle, PFAC_PLATFORM_CPU); started = std::chrono::high_resolution_clock::now(); // step 4: run PFAC on CPU PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } done = std::chrono::high_resolution_clock::now(); std::cout << "cpu_time: " << std::chrono::duration_cast<std::chrono::milliseconds>(done-started).count()<< std::endl; memset( h_matched_result, 0, sizeof(int)*input_size ) ; PFAC_setPlatform(handle, PFAC_PLATFORM_CPU_OMP); started = std::chrono::high_resolution_clock::now(); // step 4: run PFAC on OMP PFAC_status = PFAC_matchFromHost( handle, h_inputString, input_size, h_matched_result ) ; if ( PFAC_STATUS_SUCCESS != PFAC_status ){ printf("Error: fails to PFAC_matchFromHost, %s\n", PFAC_getErrorString(PFAC_status) ); exit(1) ; } done = std::chrono::high_resolution_clock::now(); std::cout << "omp_time: " << std::chrono::duration_cast<std::chrono::milliseconds>(done-started).count() << std::endl; PFAC_status = PFAC_destroy( handle ) ; assert( PFAC_STATUS_SUCCESS == PFAC_status ); free(h_inputString); free(h_matched_result); return 0; }
時間測定にstd :: chronoを使用しているため、フラグ-std = c ++ 0xをtest / Makefileファイルに追加する必要があります。 OpenMPのスレッド数を設定することを忘れないでください(自宅で4つ使用しました)。
export OMP_NUM_THREADS=4
これで、パフォーマンスの測定を開始できます。 GPUが表示できるものを見てみましょう。 各パターンの長さは32、入力データの長さは128 MBです。
次のチャートを取得します。

パターンの数が増えると、パフォーマンスが低下します。 降下なしのAho-Korasikアルゴリズムは入力データだけでなく、パターンにも依存するため、これは驚くことではありません。 テキスト内の各位置について、何らかの属性の接頭辞を持つテキストの一致する部分文字列の長さだけツリーを深くする必要があり、パターンの数が増えると、特定の接頭辞と一致する部分文字列を見つける可能性が高くなります。
そして今、より興味深いグラフのために-GPUを使用した加速。
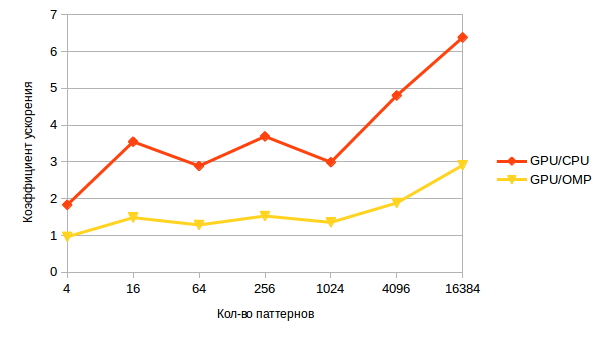
少数のパターンでは、ほとんど認識できません;データ転送はそれを使い果たします。 ただし、数の増加に伴い、加速も増加します。これは、異常なタスクにおけるGPUの潜在的な能力を示しています。
出力の代わりに
この仕事を始めたとき、私は懐疑的でした。そのようなことはあり得ないからです。 ただし、この結果は、CUDAが珍しい業界でCUDAを使用できる可能性に希望を与えています。
研究者の道はそれだけではありません。多くの作業、多くのパフォーマンスの調査、競合他社との比較が必要になります。
最初の一歩を踏み出した、希望を失わないでください!