 2年間、最高の分散エンタープライズレベル分析DBMSの1つがオープンソースにリリースされました。 この間に何が変わったのですか? プロジェクトにオープニングソースコードを与えたものは何ですか? Greenplumはどのようにさらに発展しますか?
2年間、最高の分散エンタープライズレベル分析DBMSの1つがオープンソースにリリースされました。 この間に何が変わったのですか? プロジェクトにオープニングソースコードを与えたものは何ですか? Greenplumはどのようにさらに発展しますか?
カットの下で、最初のメジャーオープンソースDBMSリリースの新機能、プロジェクトが現在のマイナーバージョンでどのように開発されているか、今後どのような革新が期待されるかについて説明します。
Greenplum DBMSに慣れていない場合は、 このレビュー記事で知り合いを始めることができます。
リリース5.0.0は9月7日に行われました。 これは最初のリリースであり、サードパーティの開発者(コミュニティ)による改善が含まれています。 バージョン4.3のリリースは、オープンリポジトリに配置されていましたが、Pivotalの専門家によってのみ開発されました。
このリリースは多くの革新をもたらしましたが、この主な理由は、Greenplumで長い間働いてきたユーザーが、Pivotalが実現できず、長い間蓄積してきたウィッシュリストをすべて実現する機会を得たためです 私の意見では、すべてを伝えるにはあまりにも多くの変更があるため、新しいメジャーリリースとそれに続くマイナーアップデートで最も重要な変更について簡単に説明します。 記事の最後に、新しいリリースとそのマイナーアップデートのリリースノートへのリンクを提供します。
従来、すべてのイノベーションは3つのグループに分類できます。
- 最新のPostgreSQLバージョンから移植された新機能
- Greenplumの革新
- 新しい追加のサービスと拡張機能
順番に始めましょう。
1. PostgreSQLの最新バージョンから移植された新機能
- PostgreSQL 8.3のリベース
PostgreSQLに基づく他の多くのプロジェクトとは異なり、Greenplumは最新バージョンのPostgreSQLをベースにしようとはしていません。バージョン5.0.0まで、GreenplumはPostgreSQL 8.2に基づいていました。現在のメジャーリリースでは8.3に引き上げられました。 同時に、PostgreSQLの新しいバージョンの可能性がプロジェクトに積極的に移されています。 - ヒープテーブルにチェックサムを設定できるようになりました
Greenplumでは、ヒープテーブルと追加最適化テーブルの2種類の内部テーブルを作成できます。 後者の場合、ディスク上のファイルのチェックサムを計算する機能が常に利用可能であった場合、ヒープテーブルでは現在のリリースで登場しました。 この機能は、パラメーターによって有効になります。 - 匿名ブロック
このイノベーションは、変更なしでPostgreSQLから引き継がれています。 最も重要なわけではありません(コードブロックは常に関数でラップできます)が、管理者と開発者が待ち望んでいた改訂版です。
DO $$DECLARE r record; BEGIN FOR r IN SELECT table_schema, table_name FROM information_schema.tables WHERE table_type = 'VIEW' AND table_schema = 'public' LOOP EXECUTE 'GRANT ALL ON ' || quote_ident(r.table_schema) || '.' || quote_ident(r.table_name) || ' TO webuser'; END LOOP; END$$;
- Dblink
このメカニズムにより、外部のサードパーティDBMSでクエリを実行し、結果を取得できます。 このメカニズムにより、Greenplumの機能が大幅に拡張され、データをソースから分析DBMSに直接取得できるようになりますが、DBlinkの適用範囲は非常に限られています-Greenplumアーキテクチャにより、DBlinkを使用したデータ転送は並行して実行されず、ウィザードを介してシングルスレッドで実行されます この事実により、DBlinkはサードパーティのデータベースへの制御要求にのみ使用され、直接のデータ転送は回避されます。 公平に言うと、サードパーティのDBMSからのデータの並行サンプリングにより、別の5つの革新が対処するのに役立つことに注意する価値があります。これについては、新しい機能のレビューの第3部で説明します。
SELECT * FROM dblink('host=remotehost port=5432 dbname=postgres', 'SELECT * FROM testdblink') AS dbltab(id int, product text);
- ORDER BY NULL値の制御
現在、SELECTクエリでは、[NULLS {FIRST | LAST}]、NULL値の表示方法を制御します-ソートされた値の最初または最後。
SELECT * from my_table_with_nulls ORDER BY 1 NULLS FIRST;
- 拡張機能
また、PostgreSQLから変更なしで移植されました 。 現在、さまざまなサードパーティの拡張機能を作成、削除、更新するためにこのメカニズムが使用されています。 基本的に、CREATE EXTENSION式は指定されたSQLスクリプトを実行します。
2. Greenplumの革新
- クエリオプティマイザーの改善-ORCA
代替コストクエリオプティマイザーはバージョン4.3にありましたが、オプションで含まれていました。 新しいリリースでは、オプティマイザーが大幅に改善されました。特に、短いライトクエリ、非常に多くの結合を含むクエリ、およびその他の多くのケースのパフォーマンスが向上しました。 リクエスト内のパーティションキーに条件がある場合、不要なパーティションを切断するメカニズムも改善されました。 現在、このオプティマイザーはデフォルトで使用されています。 - リソースグループ
Greenplumには既に負荷管理メカニズムがあります-リソースキューですが、コストに基づいてリクエストの起動を制限することしかできません。 新しいメカニズムにより、メモリとCPUの要求を制限できます(ただし、残念ながら、ディスクサブシステムの負荷ではありません)。
CREATE RESOURCE GROUP rgroup1 WITH (CPU_RATE_LIMIT=20, MEMORY_LIMIT=25);
- PL / Python 2.6-> 2.7
Pythonの組み込みバージョンは現在2.7です。 - コピーの改善
Greenplumからの並列データアップロードおよびダウンロードのすでに小さな棚が到着しました-テーブルからフラットローカルファイルにデータをアップロードするための標準コマンドは、ON SEGMENT構造をサポートします-それにより、データはすべてのデータベースセグメントでローカルファイルシステムにアップロードされます。 PROGRAMコンストラクトも登場しました-データを取得して外部bashコマンドに送信します。 ところで、これらの2つのオプションは一緒に使用できます。
COPY mydata FROM PROGRAM 'cat /tmp/mydata_<SEGID>.csv' ON SEGMENT CSV;
3.新しいサービスと拡張機能
- PXFサポート
私の意見では、これは新しいリリースのGreenplumの最も重要な改訂版です。 PXFは、Greenplumがサードパーティシステムと同時にデータを交換できるようにするフレームワークです。 これは新しいテクノロジーではなく、もともとはGreenplumフォーク(HAWQ)用に開発されたもので、Hadoopクラスターの上で動作します。 GreenplumにはすでにHadoopクラスター用のコネクターの並列実装がありましたが、PXFは独自のコネクターを作成することにより、はるかに高い柔軟性と任意のサードパーティシステムを統合バンクに接続する機能をもたらします。
フレームワークはJavaで記述されており、Greenplumセグメントサーバー上の独立したプロセスであり、一方でREST APIを介してGreenplumセグメントと通信し、他方ではサードパーティのJavaクライアントとライブラリを使用します。 そのため、たとえば、現在、Hadoopスタックの基本サービス(HDFS、Hive、Hbase)のサポートと、JDBCを介したサードパーティDBMSからのデータの並行ダウンロードがサポートされています。
この場合、Greenplumクラスターの各サーバーでPXFサービスが実行されている必要があります。
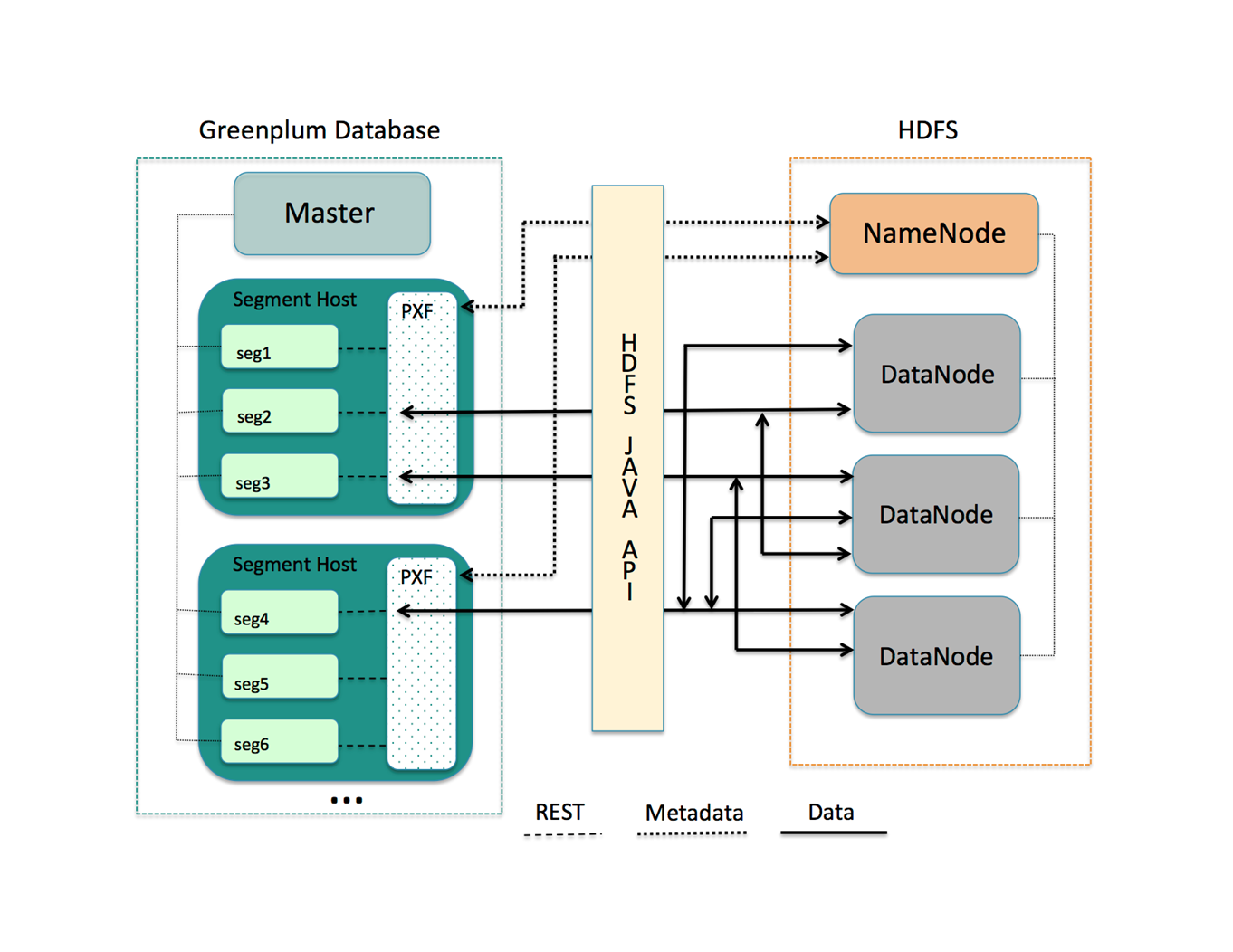
PXFからHDFSへのスキーム
最も興味深いのは、JDBCを介してGreenplumをサードパーティのDBMSと統合できることです。 したがって、たとえば、CLASSPATHにOracleデータベース用のJDBCシンドライバーを追加すると、同じ名前のDBMSのテーブルからデータを要求できるようになります。一方、並列の各Greenplumセグメントは、外部テーブルで指定されたロジックに基づいて、そのデータシャードを要求します:
CREATE EXTERNAL TABLE public.insurance_sample_jdbc_ora_ro( policyid bigint, statecode text, ... point_granularity int ) LOCATION ('pxf://myoraschema.insurance_test?PROFILE=JDBC&JDBC_DRIVER=oracle.jdbc.driver.OracleDriver&DB_URL=jdbc:oracle:thin:@//ora-host:1521/XE&USER=pxf_user&PASS=passoword&PARTITION_BY=policyid:int&RANGE=100000:999999&INTERVAL=10000') FORMAT 'CUSTOM' (FORMATTER='pxfwritable_import');
PXFは、パーティション(セクション)を1つのテーブルの外部テーブルとして使用する可能性を考慮して、Greenplumに基づいて驚くほど柔軟で生産性の高いデータ処理プラットフォームを構築できます。たとえば、Oracleに最新のデータを保存し、Greenplum自体に保存し、 -Hadoopクラスターでは、ユーザーはすべてのデータを1つのテーブルに表示します。 - パスワードチェックモジュール
このモジュールを使用すると、ロール(CREATE ROLEまたはALTER ROLE)を作成または変更するときに「弱い」パスワードの設定を制限できます。 - PGAdmin 4
人気のあるPostgreSQLクライアントは、Greenplumとの強化された対話をサポートするようになりました。 オンボードは、DDLパーティションテーブル、AOテーブル、およびヒープテーブルをサポートします。 外部テーブルのDDLはまだサポートされていません。
2年間のオープンソース滞在の革新は、次のように要約できます。
- Greenplumアーキテクチャはそれ自体に忠実です。 重大な変化(不均一なセグメントや可変数のミラーなど)は発生せず
、神に感謝します。 - DBMSのPostgreSQLコンポーネントの開発は同じままです。リベースのために絶えずアップグレードするのではなく、新しい関数を移植します。
- サードパーティのシステムとの統合に向けた開発を見ることができますが、これは非常に正しいようです。
- Greenplumはモジュール性と柔軟性を獲得し、古い柔軟性のない機能は徐々にシステムから削除されます(GPHDFS、Legacy Optimizer)。
次は?
少し前まで、リリース6.0.0は公式リポジトリでタグ付けされていました。 このリリースは来年9月にリリースされる予定です。ここに(少なくとも)イノベーションがあります。
- PXFプッシュダウン-データ選択条件(where-filters)のDBMSソース側への転送。 これにより、負荷の一部をサードパーティシステムに転送し、それらから最終結果を取得できます。
- PXFはユーザーIDを渡します-将来、PXFは要求が実行されるGreenplumユーザー名を外部システムに転送します。 安全性、すべてのもの。 おそらく、この改訂版は「5」のマイナーアップデートの1つに実装されるでしょう。
- 新しいタイプの圧縮はZstdです。 最初のテストの結果によると、GreenplumのZstdは4倍速く、Zlibと比較してデータを10%効率的に圧縮します。 特に誇りに思うのは、この機能が私たちのチーム(Arenadata)によって開発されたという事実です。
- 新しいORCAオプティマイザーのさらなる改良。
オープンソースに行くことは間違いなくGreenplumに行ったように思えます。 前のコースに忠実なままであるプロジェクトの開発は、大幅に加速および拡大しました。 近い将来、Greenplumの完全に新しい機能が多数登場するでしょう。
関連リンク:
公式リポジトリ
5.0.0リリースノート
5.1.0リリースノート
5.2.0リリースノート
5.3.0リリースノート
私たちについて少し:Arenadataプロジェクトは、2015年にPivotal(開発会社GreenplumおよびPivotal Hadoop)からの移民によって設立されました。その目標は、GreenplumおよびHadoopエンタープライズレベルの独自のディストリビューションを作成して、最新のデータストレージおよび処理プラットフォームを構築することでした。
2017年初頭、プロジェクトはIBSに買収されました。
現在、プロジェクトポートフォリオには3つの独自のディストリビューションと必要なすべてのサービスがあります。 特に、Greenplumの方向では:
- テクニカルサポートを提供します。
- コンサルティングサービスを提供します。
- データとプロセスをサードパーティのDBMSからGreenplumに移行します。
コメントでは、ArenadataプロジェクトとGreenplum全般に関する質問に答えようとします。 また、TelegramのGreenplumユーザーチャネルでお会いできることを嬉しく思います。 どういたしまして!
