ケースは実生活から取られているので、顧客が私たちのために設定した条件について言うことが重要です。 それとは別に、これらの条件はそれほど実用的ではないように見えますが、一緒にタスクを複雑にします。
- タスクは、単一のマルチプラットフォームソリューションの一部として完了する必要があります。 (iOS / Android)。
- 認識用の画像とオブジェクトは、ワンクリックで変更できます。
- 3Dモデルとアニメーションは、頂点やポリゴンで踊ることなく簡単にロードする必要があります。
- 3Dモデルはクリックに応答する必要があります。
従来、作業プロセスは次のステップに分割されていました。
- 画像またはオブジェクトを認識します。 認識後、この場所に3Dオブジェクトを持つモデルを表示します。
- 特定の場所を参照せずに、ポケモンゴーに似た3Dオブジェクトを画面に表示します。 押すと、アニメーションが再生されます。
- 指定された座標の3DオブジェクトをPOI(関心のあるポイント)として表示します。
最初の部分を分析しましょう。つまり、画像を認識し、その場所に3Dオブジェクトを表示する方法を学習します。
プラットフォームの選択
ケースの作業中に、ARKitはベータ版になり、少し掘り下げることができました。 これは非常に強力なツールですが、ARKitのようなクールなSDKでもオブジェクト認識システムはありません。 いわゆる「平面検出」が含まれています-それは床または別の水平面を認識します。
必要に応じて、タスクを解決するための基盤としてARKitを使用できますが、ここにOpenCVを追加して、オブジェクト、おそらくはUnityを認識し、GUIコンポーネントをロードする必要があります。 面白いのは、性別を認識できるマルチプラットフォームのソリューションを探しに行くことです。ARKitでさえ、それをうまく行えないからです。
ケースの複雑さと多様性のために、ネイティブソリューションは適切ではないことが明らかになりました。 解決策は、プロジェクトを2つの部分に分割し、各プラットフォームですべてを実行することです。
これからの困難は依然として完全なブレークスルーであり、extを使用するためのフレームワークがそうなるように、作業量を削減したいと考えました。 私たちのためにすべての汚い仕事を現実にしました。
プロジェクトが最終的にどの程度の成果をもたらしたかを知っているので、私が選んだソリューションについて後悔はないと言います。
私たちが取り組んだこと
ARには多くのテクノロジーがありますが、私たちはWikitude SDKとSLAMに決めました。
なんで? すべてが非常に簡単です:
SLAM(同時ローカリゼーションとマッピング)は、マーカーベースとは異なり、表示された3Dオブジェクトを特定の画像にアタッチしないようにします。 これらの2つの異なるアプローチは、世界に対するオブジェクトの座標の位置に影響します。 また、作業を開始する前に、 公式Webサイトで Wikitude SDKフレームワークをよく理解することをお勧めします。
ARを使用するためのフレームワークの比較表:

実装
最も簡単な説明でさえ、常に多くの時間がかかるので、以降はコードのみで、厳密に実装について説明します。
まず、 ドキュメントをよく理解することを強くお勧めします。
マルチプラットフォームソリューションがあるため、JSを使用します。 サンプルを基礎とする既製のアプリケーションを使用できます。JSコードを使用してモジュールを呼び出すための基礎はすべて用意されています。
example.plistファイルはすでにサンプルに追加されています。 内部を見て、ニーズに合わせて編集し、その理由を調べましょう。
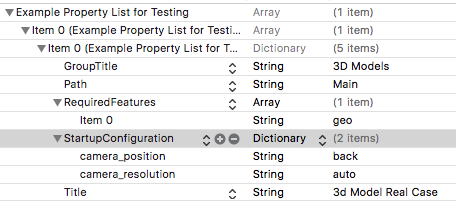
したがって、同じパスでJSの下にモジュールを含むフォルダーを作成します。
キーを取得
開始に加えて、キーを取得してコードで使用する必要があります。 キーがなくても機能しますが、画面全体に「トライアル」という碑文が表示されます。
Wikitudeの例は、セルを含むテーブルとして構成されています。 各セルは、タイプWTAugumentedRealityExperienceのモデルで表されます。 Examples.plistファイルの内容を見た少し前に覚えていますか? したがって、このシートの各要素は、WTAugumentedRealityExperienceオブジェクトの表現です。
写真をご覧ください。 その上に、このモデルのコンストラクターが表示されます。 前述の.plistのファイルがそこに転送されます。 世界は狭い!

図面をダウンロードする
認識のためにパターンをロードすることから始めましょう。 これを行うには、特別なツールwikitudeターゲットマネージャーのサイトにアクセスします。
登録後、新しいプロジェクトを作成します。
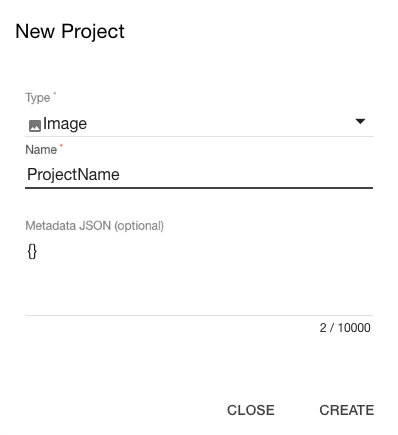
興味深いことに、3Dオブジェクトを追加するときは、このオブジェクトが撮影されたビデオをアップロードする必要があります。 これは、認識のためにオブジェクトの非常に正確な画像を作成するのに特に役立ちます。 彼らのウェブサイトには消防車が表示されており、認識されたマシンをクリックするとサイレンをオンにすることができます。

ビデオを撮影する例。 マシンは回転するトレイの上にあり、あらゆる角度から撮影が行われます。
プロジェクトを作成した後、認識の目標をすべて追加します。 1つのプロジェクトに複数の目標が含まれている場合があります。 これは、認識を伴うアニメーションやオブジェクトをすぐに追加できるためにも行われます。
認識用の画像を追加すると、それらはシステムによって0〜3のスケールで評価されます。
一般的なヒント:
- 写真のコントラストがより強くなります。
- テキストに加えて、グラフィック素材が必要です。
- 500から1000ピクセルのjpgサイズ。
- 空のスペースをクリーンアップします。
- ロゴだけでは不十分です。グラフィック素材を追加してください。
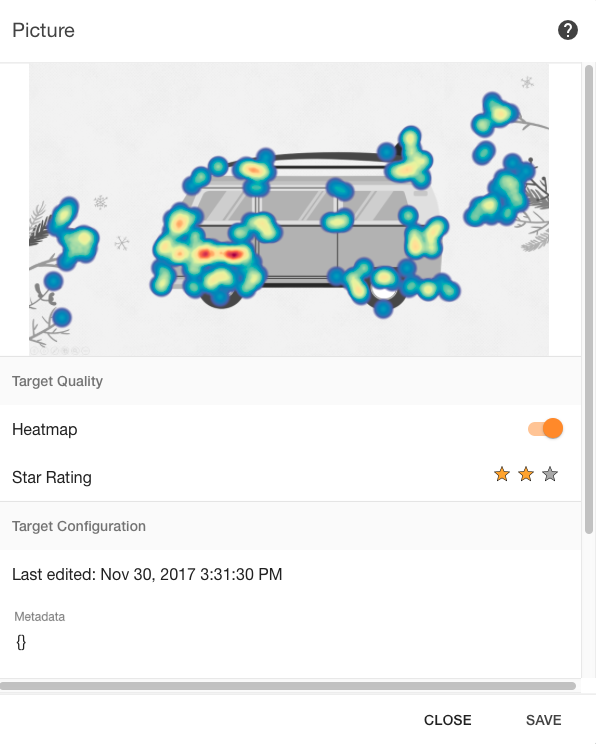
上の画像では、アップロードした画像です。 ヒートマップと評価が含まれています。
内部からのエディターの外観:

Augmentationsオブジェクトが使用される場合と使用されない場合があります。 これについては、後で3Dオブジェクトとアニメーションの表示に関する会話で取り上げます。
左上隅には2つのアイコンがあります。1つ目はクラウド認識用、2つ目はオフライン認識用です。 2番目のバージョンのファイルをダウンロードすると、出力は* .wtc形式になります。 (Wikitudeターゲットコレクション)。
ファイルをプロジェクトに追加し、コードを記述しました。

そして、それはすべて認識です。 これで、画像の上にマウスを移動すると、マシンが表示されます。
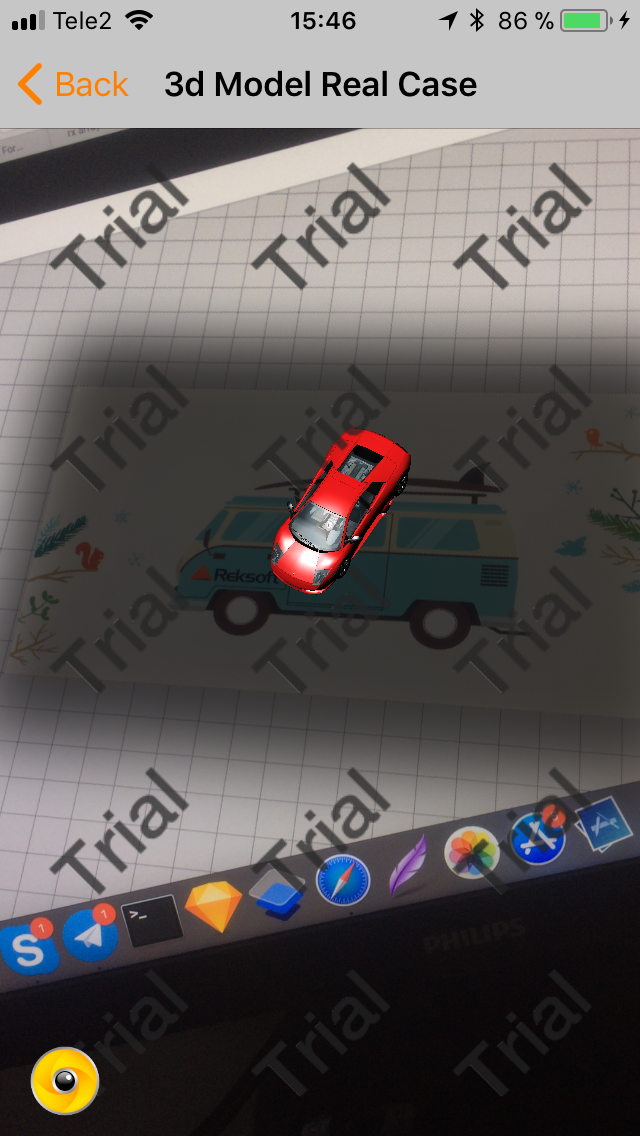
この場合、少しlittleし、すでにプロジェクトにロードされている3Dモデルを使用しました。
今日はそれだけです。 次回は、3Dモデルとそれらのアニメーションの読み込みをより詳細に分析し、オブジェクトを関心のあるポイントにスナップさせ、SLAMテクノロジーを使用してモデルを表示する方法も検討します。
じゃあね!
