私は質問を別の方法で定式化します: 自己設計されたプログラムはどれくらい効果的ですか? この質問の文言は、自動化された設計が高性能プログラムのソースであることを示唆しています。 効率性などの重要なトピックについてはまだ触れていませんが、「ディスプレイ」の例は、自動設計の有効性を示すのに理想的です。 最初の記事では、読者にこのモジュールの「実験室」バージョンを紹介しましたが、「戦闘」バージョンをテストします。その設計プロセスについては、次の記事で説明します。 パフォーマンス調査は、msp430およびCortexM3プラットフォームで実行されます。
主観的ではなく、有効性を評価するには、結果を何かと比較する必要があります。 そのため、 michael_vostrikovから親切に提供された「ディスプレイ」の例の非手動実装に対して同じテストセットを実施します。
オートマトン-A2ではなく、条件付きでオートマトン実装A1を呼び出します。 元のA2はJavaScriptで記述されていますが、これらの実装を同等の条件下で調査できるようにするために、 バージョンA2をC ++にロールしました 。 彼から始めます。
(FSM ||!FSM)?
実装A1の場合と同様に、オプションA2は、テキストをブロックに分割するモジュールとテキストブロックを表示するモジュールに分かれています。
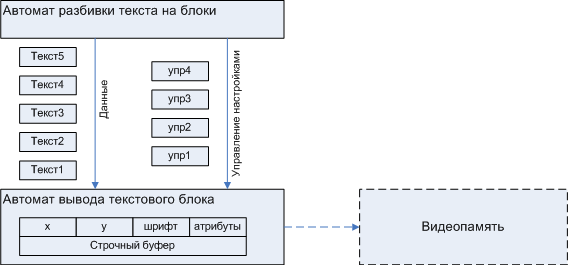
図1.モジュール「A2 :: Display」の大規模構造
ブロックブレーカーは、関数A2 :: tDisplay :: Out_textで表されます。 彼女の分析から、私が条件付きで「非自動」と呼んでいるオプションA2は、状態図で説明されている典型的なオートマトンによって実装されていることが明らかです。
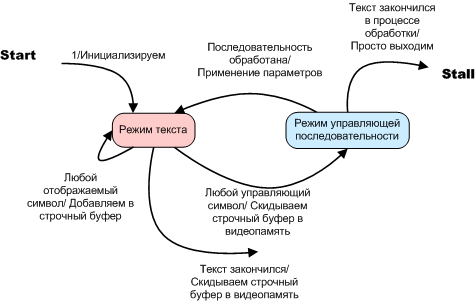
図2.オプションA2。 ブロック分割機。 状態図
ソースの状態を強調するために、色で強調表示します。

図3.オプションA2。 ブロック分割機。 「強調表示」状態のプログラムのソースコード
オートマトンA2 :: tDisplay :: Out_textは、前回の記事の例に続くオートマトンの実装の別の例です。 明示的に割り当てられた2つの状態と、現在の内部状態を定義する変数(esc_mode)があります。 この変数がbool型であるという事実は、少なくともその能力を低下させません。
オプションA1の同様のオートマトンを考えてみましょう
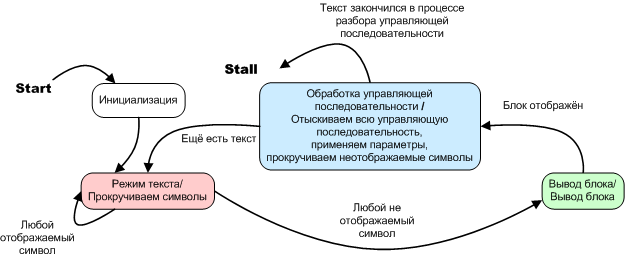
図4.オプションA1。 ブロック分割機。 状態図

これもオートマトンであり、3つの一意に区別される状態があり、それらの間の遷移が明確に登録されます。内部状態を記述する特別な変数はありませんが、プログラム構造はプログラムカウンターがこの変数であるようなものです。 いつ:
表1. プログラムカウンターの値とプログラムの現在の内部状態の対応
範囲内のソフトウェアカウンター値 | これは状態に対応します | |
state__inside_text_block | state__out_text_block | テキスト モード |
state__out_text_block | state__control_processing | ブロック 出力 |
状態 __ 制御 _ 処理 | サイクルの終わりまで | 制御処理 シーケンス |
A2の場合、変数内部状態の役割は、bool型の変数、A1の場合はプログラムカウンター、およびそれにもかかわらず、これらは自動的に実装されるアルゴリズムと発音されます。 A2オプションはMilesマシンであることを思い出させてください。 ムーアオートマトン(オプションA1)とは異なり、出力信号(またはアクション)は楕円ではなく、遷移矢印の上、遷移条件の後のスラッシュの後に書き込まれます。
A2 :: OA。
テキストブロック出力マシンに移動して、A2 :: Displayオプションの分析を続けます。 このマシンは、同じマシンバージョンA1とは大きく異なります。
struct tFont_item{ u1x Width; const u1x * Image; }; union { u2x Data; u1x Array[2]; }Symbol_buffer; //////////////////////////////////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////////////////////////////////// void printToBuffer( int lineStartX, int lineStartY, const tFont_item * symbolInfo, int minX, int maxX) { u1x bytes_Width = (symbolInfo->Width + 7) >> 3; for (int y = 0; y < Font_height; y++) { if(bytes_Width == 1) Symbol_buffer.Array[1] = *((u1x*)(symbolInfo->Image + bytes_Width * y)); else Symbol_buffer.Data = *((u2x*)(symbolInfo->Image + bytes_Width * y)); u2x bit_mask = 0x8000; for (int x = 0; x < symbolInfo->Width; x++) { bool bit = Symbol_buffer.Data & bit_mask; bit_mask = bit_mask >> 1; int lineX = lineStartX + x; int lineY = lineStartY + y; if (lineX >= minX && lineX <= maxX) { setPixelInBuffer(lineX, lineY, bit); } }//for (int x = 0; x < symbolInfo->Width; x++) }//for (int y = 0; y < Font_height; y++) };//void printToBuffer( int lineStartX, int lineStartY, tFont_item * symbolInfo, int minX, int maxX ) //////////////////////////////////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////////////////////////////////// void setPixelInBuffer(int x, int y, bool bit) { int bitNumber = (x & 7); int byteNumber = x >> 3; if (bit) { Line_buffer[y][byteNumber] |= (0x80 >> bitNumber); } };//void setPixelInBuffer(int x, int y, bool bit)
この実装では、文字の分類は実行されません。したがって、 テキストブロック出力オートマトンの UAの操作は、表示される各シンボルの操作シンボル表示オートマトンへの直接呼び出しに削減されます。
図5.テキストブロック出力マシン、制御マシン
しかし、オートマトンは手動実装のどこから来たのでしょうか? A2の実装は、条件付きで非自動と呼ばれたという事実にもかかわらず、運用マシンにも基づいています。 これは最も単純なランダムビットマップマシンです。
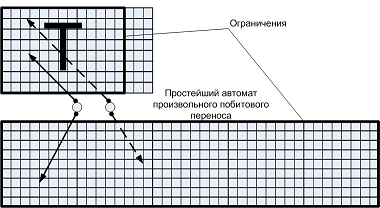
図6.例A2の自動機
前述のように、稼働中のマシンは、有効なパラメーターを使用して何らかのアクションを実行できる半製品です。 組み合わせパターンに縮退することができます。 それの主な要件:最大のシンプルさ、最大の効率。 これらの要件は、次に示すように矛盾します。
アルゴリズムの単純さの観点から、ランダムなビット単位の転送演算子は優れています。 それは普遍的で、文字ジェネレータの任意のピクセルを文字列バッファーの任意のピクセルにコピーできます。 この場合のOAのパラメーター化は、最も単純な制御オートマトンによって実行されます。

図7.制御出力マシン
この例は、単純な制御ロジックを備えたほとんどのプログラムが自動的に実装されることを示しており、制御ロジックの逐次的な複雑さが発生すると自律性が現れます。 明示的なオートマトンとしてアルゴリズムを設計していない場合、プログラムを順次複雑化することにより、別のチップ、別の「松葉杖」を追加した後、「構造遷移」が発生することがあります-自動化が消え、記事2および3から非手動の例のようなものが得られます
図8.非手動アルゴリズム
それで、A2の純粋な形式での実装が自動であることを確認する機会がありましたが、それはどれほど効果的ですか?
A1対A2
問題の実装の有効性を比較する唯一の方法は、テストすることです。 テストには、IAR開発環境を使用します 。
最初のテスト例は、画面全体から行が消えるまで、右から左に走る行として表示されるフルスクリーンの文字列です。 物理的な出力は、データをI / Oポートに出力することでエミュレートされますが、これは最初の近似では事実です。
フォント6x9、ディスプレイ256x64。 最適化-最高速度。
char Test_text[43]; int main( void ) { for(int i = 0; i < 42; i++) Test_text[i] = 'A' + i; Display = new tDisplay(256,64,16); for( int i = 0; i > -270 ; i-- ) { Display->Out_text(0,0,256,64,i,0, (uchar*)Test_text); } }
これを行うには、IARエディターでファイルを作成し、 cspy_1.macという名前で保存しました。 ファイルにマクロ関数を含むテキストを配置しました
__var filehandle; //////////////////////////////////////////////// setup() { filehandle = __openFile("filelog1.txt", "w"); } //////////////////////////////////////////////// clear() { #CCTIMER1 = 0; } //////////////////////////////////////////////// out_data() { __fmessage filehandle , #CCTIMER1, "\n"; #CCTIMER1 = 0; } //////////////////////////////////////////////// close() { __closeFile(filehandle); }
これはCに似た言語ですが、Cではなく、非常に単純であり、IARヘルプで詳しく説明されています。 次に、このファイルをプロジェクトに接続しました。 これを行うには、 [プロジェクト]-> [オプション]で[ デバッガ]を選択し、 [ マクロファイルを使用]チェックボックスをオンにし 、 cspy_1.macファイルを選択しました 。
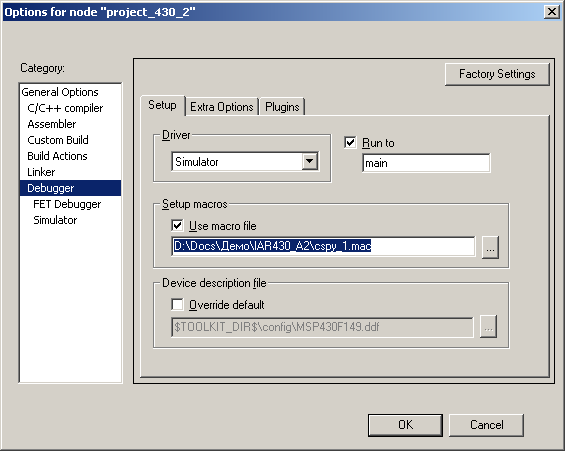
図sp。1。 マクロ関数ファイルをプロジェクトに接続する
cspy_1.macで説明されているマクロ関数は、図4に示されているブレークポイントに接続されています。 sp.2。

図sp.2。 ブレークポイントを接続する
これを行うには、目的の位置にブレークポイントを配置します。 テキストの左側にある灰色のバーをダブルクリックすると、ブレークポイントが設定および削除されます。 すべてのポイントを設定したら、[表示]- > [ブレークポイント ]タブを開く必要があります
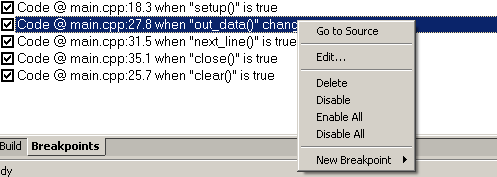
図sp.3。 カスタマイズ
関心のあるポイントを右クリックして[編集]を選択すると、[ ブレークポイントの編集]ウィンドウが表示されます
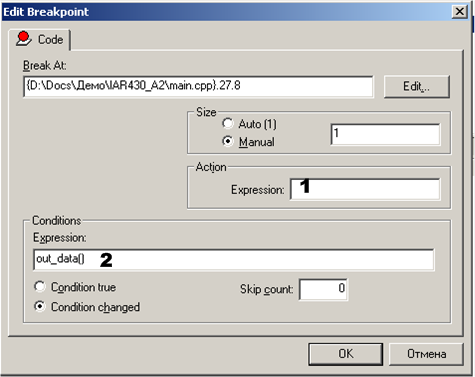
図sp.4。 カスタマイズ
表示されるウィンドウに、必要な機能の名前が登録されます。 1とマークされたフィールドに登録すると、指定された関数は、停止が発生したときにのみ呼び出されます。 プログラムを停止せずに、指定された関数を呼び出すには、その名前をフィールド2に書き込む必要があります。これにより、プログラムを停止するかどうかを決定するために、停止する前にこの関数が呼び出されます。 対応するマクロ関数が1を返す場合、停止が行われます。関数が0を返すか、何も返さない場合、停止はありません。 指定されたマクロ関数は、対応するCプログラム式がブレークポイントで実行されるまで実行されます。
調査結果はグラフに示されています。
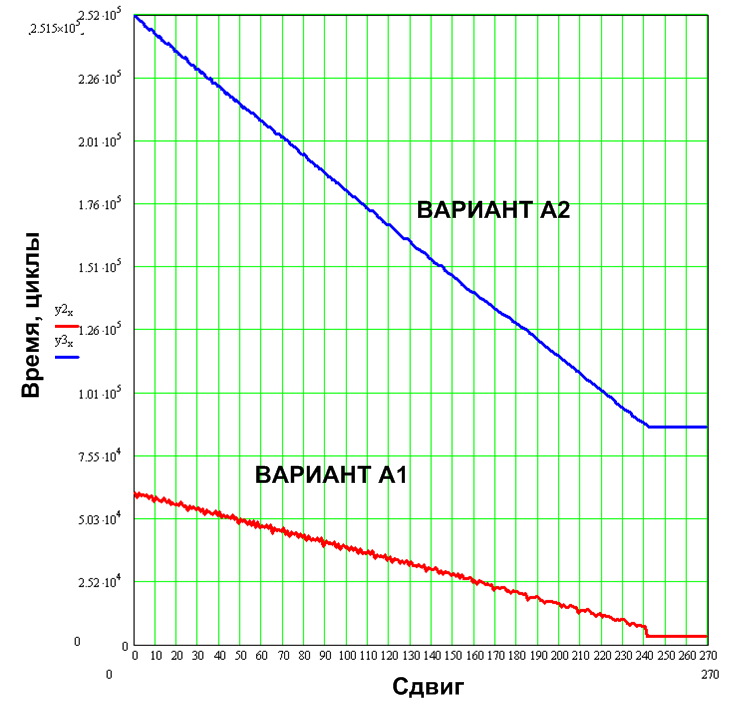
図9.最初のテストの結果
オプションA2の場合、行が実際に出力ウィンドウの端を超えて延びている場合、結果として何も表示しないためにかなりの数のサイクルが費やされることが明確にわかります。 検証オプションは可能ですが、出力するものがある場合、アルゴリズムをさらに遅くします。 オプションA1の場合、ラインがウィンドウを出ると、循環消費量は3000サイクルのオーダーの値まで低下します。 この動作は、もともとオートマトンの適切な状態を選択することでアルゴリズム自体の構造に組み込まれていました(次の記事では、A1の例を使用して開発プロセスを説明します)。追加のチェックは不要です。
最初の例では、これら2つのアルゴリズムがクリープラインモードでどのように機能するかについての一般的なアイデアを示しますが、Displayモジュールの主な用途は、画面上の任意の位置に完全に収まるテキストの通常の出力です。 メインモードでのモジュールの動作を調べるために、テスト例を使用します。
char Test_text[32]; int main( void ) { for(int i = 0; i< 31; i++) Test_text[i] = 'A' + i; Display = new tDisplay(256,64,24); for( int j = 0; j < 31; j++) { for( int i = 0; i < 8; i++) { Display->Out_text(0,0,256,64,i,0, (uchar*)&Test_text[31-j]); } } }
このテスト例では、0〜31文字の異なる長さの行、フォント6x9を表示しています。 各行は最初にシフトなしで表示され、次に右に1ピクセル、次に2ピクセルずつシフトして表示されます。 最大8ピクセル。 これは、画面上のさまざまな位置でのテキストの出力をシミュレートします(両方のアルゴリズムが影響を受けます)。
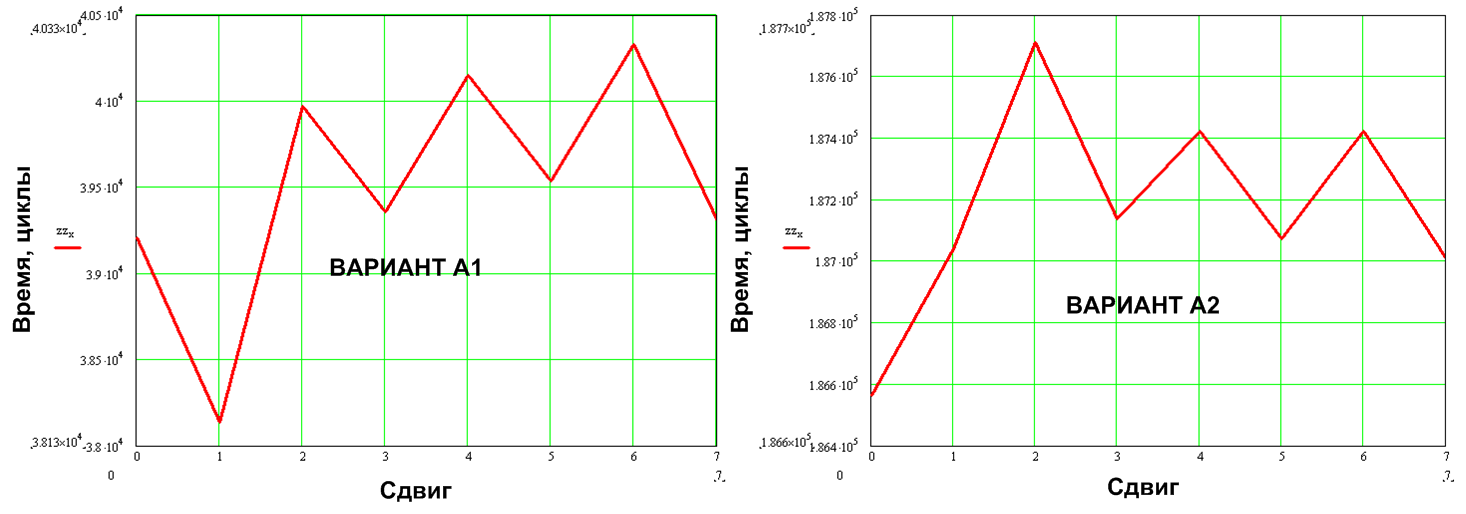
図10.循環消費に対するバイト境界からの出力ウィンドウの初期シフトの影響
結果はシフト全体で平均化されます。その結果、画面上の行の初期位置に依存しない値が取得されます。
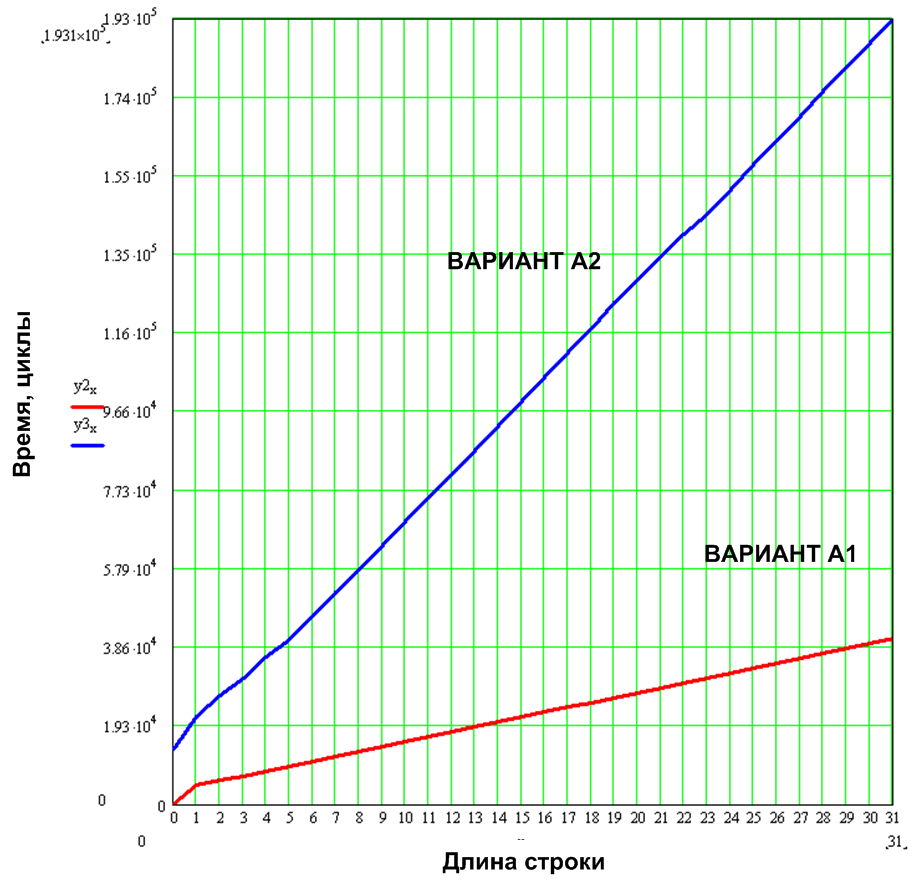
図11. 6x9フォントのテキスト文字列出力
予想どおり、循環消費の値は、文字列の文字数の増加とともに直線的に増加します。 オプションA1の場合、 特定の循環消費 (シンボルあたりのサイクル)はシンボルあたり1200サイクル、オプションA2の場合は5913サイクル(最適化、リコール、最大速度)です。
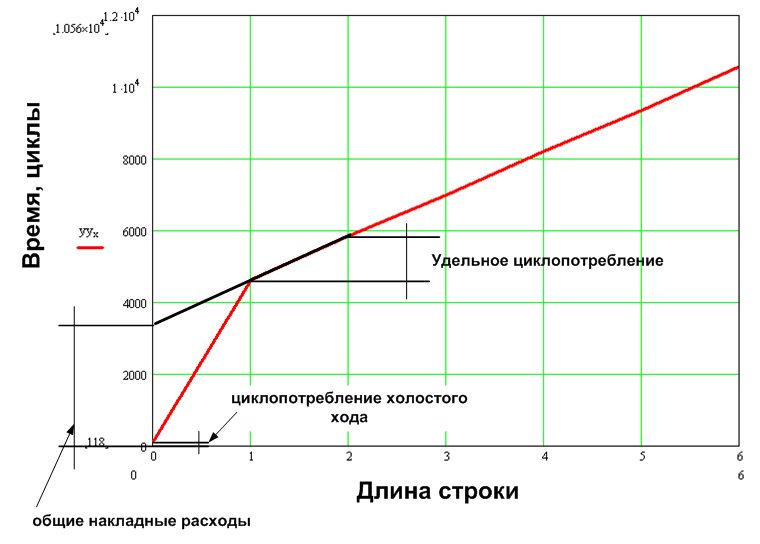
図12.一般的なオーバーヘッド、特定の循環消費、およびアイドルサイクル消費の用語の説明
総間接費は3431(A1)および16433(A2)です。 アイドルサイクルの消費に注意する価値があります 。つまり、長さ0文字の文字列が入力-118(A1)および13548(A2)サイクルに供給される場合です。 このような大きな違いは、オプションA2のラインバッファのフラッシュに関連しています。 さらに文字「\ 0」のソース文字列をチェックすることにより、空の文字列のラインバッファのクリーニングを排除し、アイドルサイクルの消費をA1に匹敵する値に減らすことができます。 ラインバッファをより詳細に検討する正当な理由があるために、意図的にこれを実行しませんでした。 小文字のバッファを使用することは、オーバーヘッドが大きくなる主要な要素です。 最初に、setPixelInBuffer関数を書き換えることにより、ラインバッファーをクリーニングする操作を排除できます。
void setPixelInBuffer(int x, int y, bool bit) { int bitNumber = (x & 7); int byteNumber = x >> 3; if (bit) { Line_buffer[y][byteNumber] |= (0x80 >> bitNumber); } else { Line_buffer[y][byteNumber] &= ~(0x80 >> bitNumber); } };//void setPixelInBuffer(int x, int y, bool bit)
ただし、この場合は加速ではなく、文字ごとにアルゴリズムが約1.5倍(6x9フォントの場合)遅くなります。これは、ラインバッファーのクリーニング時にすべての「白」ピクセルが一度に出力され、このバージョンでは各「白」ピクセルが個別に表示されるためです グラフ写真 この場合に判明する画像を表示します。
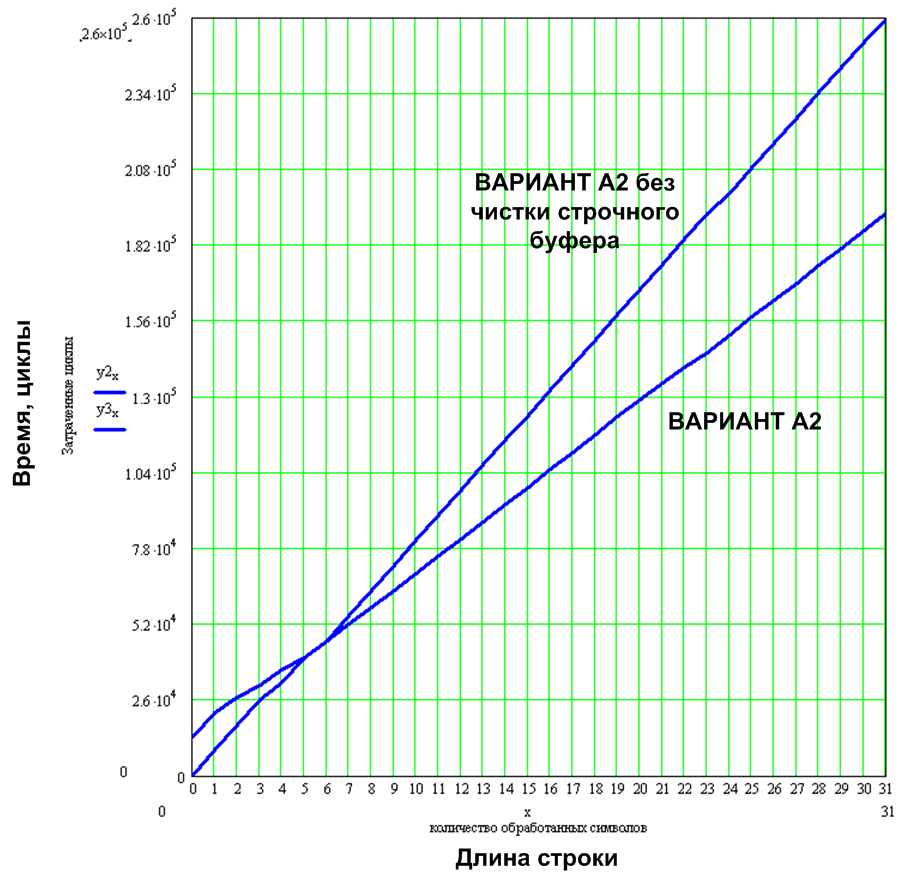
図13.ラインバッファをクリーニングする場合としない場合の実装の違い
ラインバッファに関連する2番目の問題は、ラインバッファをクリーニングする必要性とは関係がありませんが、存在します。 幅256ピクセルで最大フォント高が24ピクセルのディスプレイの場合、ラインバッファーのサイズは768バイトです。 一般的な「小型」マイクロコントローラ、特にmsp430では、RAM不足の問題が一般的です。 ラインバッファオプションには以下が必要です。
これは、2〜4 kbのRAMボリュームを備えたマイクロコントローラーにとっては非常に無駄です。 これは、同じコントローラーに60 kbのROMが含まれており、tDisplayモジュールのプログラムコードが同じ2 kbのコード-3.2%を占めるという事実にもかかわらずです。 基本的な入出力機能(実行中の行と仮想出力ウィンドウの効果的な実装が既に含まれています)の3.2%は非常に許容できますが、1つのテキスト出力操作のRAMの41.5%は重大な費用です。 4 KBのRAMでより堅牢なmsp430f2616を使用しても、20%はまだ小さくありません。
私たちはmspについて話しているので、省エネについて言うのは場違いではありません。 これは、バッテリー駆動のデバイスでの使用に最適な、最も控えめなパワーマイクロコントローラーの1つです。 プログラムの速度を複数回上げると、全体として作業が高速化されるだけでなく(パフォーマンスが常に重要になるわけではありません)、 バッテリー電力を直接節約し 、マイクロコントローラーがほとんどの時間スリープモードになり、作業時間を延ばすことができます。繰り返し充電。
オプションA1は、ラインバッファなしのスキームに従って設計されています。 つまり、このモジュールは何倍も高速であるだけでなく、何十倍も少ないRAMを必要とします。 A1で使用されるマシンには、高速と経済の2つのサブ実装があります。 経済的なものは、約60バイトのRAMで動作します。 疑問が自然に発生します:おそらくA1オプションは、コードのサイズでA2オプションに負けますか? 実際、最大速度の最適化(ただし、サイズの最適化が実行される)では、特性によって次の図が得られます。
表2.ソフトウェアモジュールの比較特性
pzu | オンス | 性能 | |
a2 | 1122 | 796 + 58スタック | 1 |
a1。速度 | 2088 | 240 + 26スタック | 4.6-7.9 |
a1。経済 | 2490 | 62 + 18スタック | 3.5-6 |
比較のために、6x9フォントの場合、256文字すべてのグリフが定義されている文字ジェネレーターのサイズは3344バイトです。
フォントサイズの増加に伴い、特定の循環消費量がどのように増加するかを分析しましょう。 図 図14は、フォント6x9、8x16、および16x24の特定の循環消費量のグラフを示しています。これは、オプションA2のCA値が面積に比例し、オプションA1のCA値が文字の高さに比例することを示します。 これを強調するために、x軸はオプションA2の文字の領域と、A1の行の文字の高さを示しています。
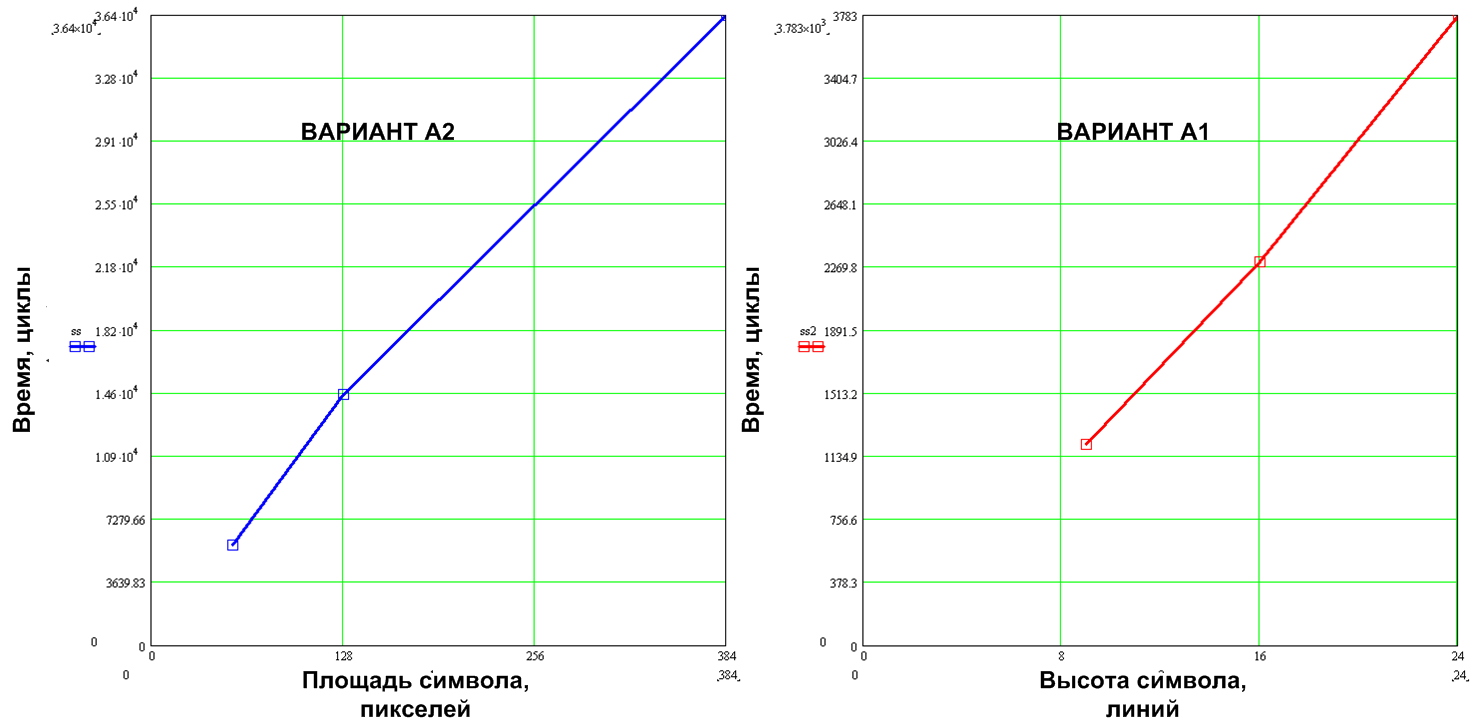
図14.特定の循環消費量のフォントサイズへの依存性
A2と比較したオプションA1(以下、高速のすべての数値)の特定の循環消費量は、6x9フォントで4.9、8x16フォントで6.4倍、16x24で9.2倍であり、平均して文字列長が0..31文字の場合、オプションA1はより大きく表示されますパフォーマンスは、6x9フォントで4.6倍、8x16で5.8倍、16x24で7.9倍です。
未来への展望。
この一連の記事の範囲をはるかに超える重要な問題を提案させてください。 テストモジュールには最大速度の最適化がありました。 これらの実装を最適化する方法を知りたいです。 図 図15は、両方のオプションの異なるフォントについて、文字列の長さに応じた最適化係数(最適化されていないものと最適化されたものの比率)を示しています。
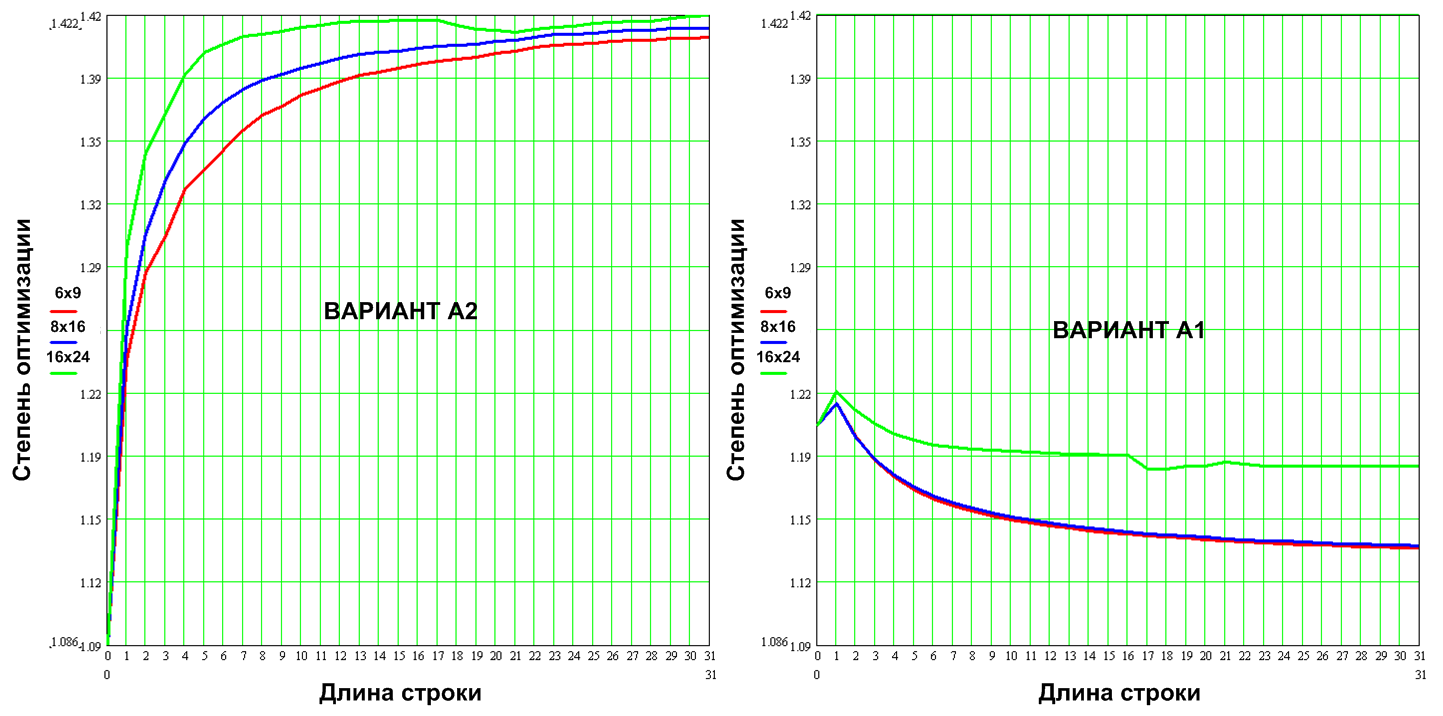
図15.プログラム最適化の程度
両方のバリアントの「削減」の程度は小さいことがわかります。これは、良い実装と悪い実装の両方について話していないことを意味します。 OA + UA。 ただし、圧縮オプションA2の1.4倍でも、オプションA1のみの圧縮オプション1.15倍よりも5〜8倍遅いことに注意してください。 オプティマイザーの主なツールであるインライン挿入関数、ループの最適化、短いループの展開など、これは驚くべきことではありません。 すなわち 標準の構造プログラミング構造を最適化します。 しかし、プログラムの基になっているオートマトン(図16)の最適化と同様に、アルゴリズムの最適化は生産性の大幅な向上をもたらします。これが今日の記事のライトモチーフです。
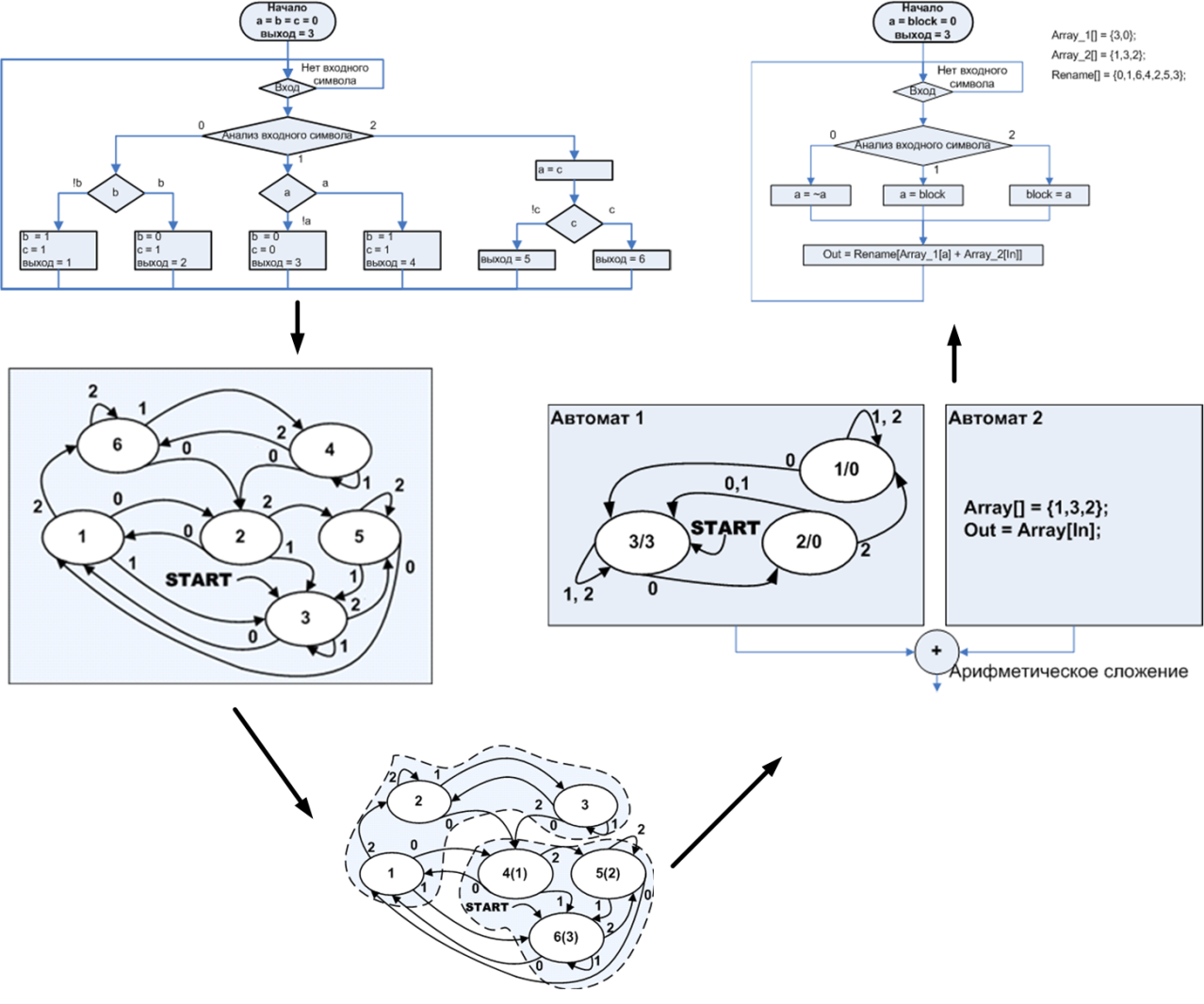
図16.対応するオートマトンを最適化することによるアルゴリズムの最適化
このことから、広範囲にわたる結論を引き出すことができます。コードオプティマイザーの進化経路の1つは、アルゴリズムのオートマトンへの変換と、結果のオートマトンの最適化に関連しています。 ただし、例A2には非常に原始的なオートマトンが存在するため、それらをさらに最適化する場所はありません。 A2と比較した場合のアルゴリズムA1の大幅な効率は、 運用オートマトンを構築するための根本的に異なるスキームの使用によるものです。 したがって、オプションA2の効率を高めるには、オプションA2の構造を最適化せずに、A1からOAを取得する必要があります。 「自動化された」コード最適化には、おそらく次のものが含まれます。
1. OA RefとUA Refへのソースコードの自動分割。 ほとんどの場合、行動の分析、パターンの検索になります。 この場合のオートマトンは、誰によっても取得されませんが、データベース内にあり、したがって分類できるオートマトンです。 したがって、OAの動作を説明するには、何らかの標準が必要です。 状態図と遷移図は原則として同じ動作を説明しているだけですが、直観では1つの状態図と遷移だけでは十分ではないことを示唆しています。

図17.任意のプログラミング言語のプログラムコードからオートマトンを取得する
ソースコード内のオペレーティングマシンの自動認識と分類は、状態図(たとえば、IAR visualStateを作成する)に従ってマシンコードを生成するよりも実装が難しく、したがって、開発ツールは1は除外され、開発は2から開始されます。
2.データベースで利用可能なOAのセットから最も効果的なOAの検索は、おそらくエンジンでトレーニングされたニューラルネットワークに基づいて、検索エンジンによって実行されます。 すなわち データベースで利用可能な既製のセットから最適なソリューションを選択します。 データベース内の既製のソリューションは、プログラマーや、たとえば遺伝的アルゴリズムを使用してオペレーティングマシンを「マイニング」する特別に訓練されたプログラムによって「初期蓄積」の時代に開発されると想定されています。
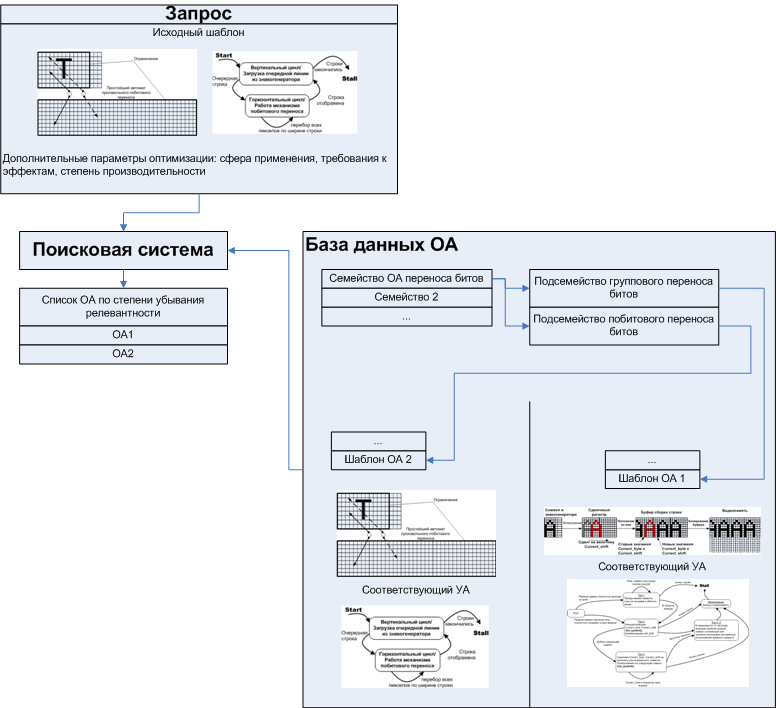
図18.効果的なソリューションの検索
3.選択したOAに対応する制御マシンをセットアップします。 オートマトンをコードに変換します。

図19.最適化された実装
上記の手順の後、追加のコード最適化を実行できます(今日と同じことを最適化と呼びます)。
前述のことは、操作オートマトンを記述するための標準が必要であることを意味します。 記述はすでにコードの形式で格納されているため、論理スキーム(VHDL)の意味ではなく、彼ができることとその適用性(動作の記述)のメタ情報のセット、オートマトンを自動的に検索できるようにするメタ情報の意味で-パートナー、たとえば、このAAをドッキングできるAA。 状態と遷移図は、間違いなくそのような記述の要素の1つです。
上記のように、これは、家族によって分類され、上記の説明とともに提供された、以前に開発された標準の特定のライブラリを意味します。 このライブラリのオペレーティングマシンは、たとえばCまたはアセンブラで既製になります。 各OAは適切な制御オートマトンに対応し、状態図の形式で保存されます。
オペレーティングマシンは特定のタスクとプラットフォームに合わせて調整された非常に効率的なソリューションであるため、このようなスキーム(つまり、コードの形のOAと図の形のUA)が望ましいです。 一方で、このOAの特性は、制御オートマトンによって設定される外部パラメーター(厳密に指定された制限内)によって変化する可能性があります。
制御オートマトンは、基本的にフィードバックループの動作を記述するモデルです。 回路設計者は、アンプに特定のフィードバックを設定することで、増幅素子自体の設計を妨げることなくパラメーターの変更を実現できます。 同様に、オートマトンでは、AA-操作オートマトンのフィードバック(各OAに厳密に指定された制限内)を調整することにより、操作部分を変更せずにオートマトン全体のプロパティを変更することができます。
したがって、ライブラリに格納されている制御オートマトンはまだ既製のモジュールではなく、必要な動作を取得するように構成できます。また、接続された抵抗とコンデンサのフィードバックチェーンがそれぞれオペアンプから積分器を作成するように、1つのタイプのUAがOAのさまざまな変更に適していますオペアンプの特性のばらつきに依存します。 , .
:
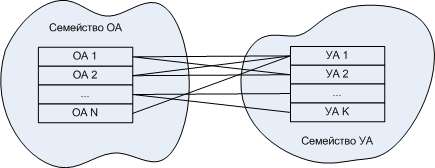
20.
. , .
, . . , . , , , . , , . , , CortexM3
CortexM3
予想どおり、このプラットフォーム用にコンパイルされた例は、より高いパフォーマンスを示しています。括弧は、プラットフォームmsp 430と比較した対応する値の減少を示しています。
表3.特性の最終比較
6x9 | 8x16 | 16x24 | ||||
総オーバーヘッド | 特定の循環消費 | 総オーバーヘッド | 特定の循環消費 | 総オーバーヘッド | 特定の循環消費 | |
msp430.a1 | 3431 | 1202 | 6122 | 2299 | 7764 | 4052 |
msp430.a2 | 15938 | 5716 | 28910 | 14318 | 42402 | 35748 |
皮質m3.a1 | 1831(1.9) | 715(1.7) | 3237(1.9) | 1370(1.7) | 4795(1.6) | 2238(1.8) |
皮質 m 3. a 2 | 6182(2.6) | 2131(2.7) | 11347(2.5) | 5236(2.7) | 16440(2.6) | 13282(2.7) |
結果について簡単にコメントします。アルゴリズムの高速化は、Cortex M3コアによる命令のより効率的な実行に関連しています。ほとんどの命令は1〜2サイクルで実行され、msp430カーネルは命令(大文字と小文字を区別しない)を2〜3サイクルで実行します。高速の2番目の理由は、せん断操作のより効率的な操作です。 Cortex M3は32ビット幅のワードを一度に最大32倍の位置にシフトできますが、msp430は一度に1ビットずつ16ビットをシフトします。
この場合、コードサイズはmsp430の対応するコードサイズよりもさらに小さくなります。1043対1122バイトオプションA2および1914対2088バイトオプションA1。このタイプのコントローラーに200バイトのRAMを保存することは関係ないため、A1オプションは経済的とは見なされません。
– . — . 1 , .