SQLとNoSQLの世界をどのように組み合わせるのですか? この記事は、Elasticsearchの高度な検索エンジンをRestX、Hibernate、PostgreSQL / MySQLで動作するレガシーアプリケーションに統合するいくつかの実例です。
このことについて、ElasticのエキスパートであるDavid Pilato(David Pilato)について話してください(Elasticsearch、Kibana、Beats、およびLogstashを実行した人、つまりElastic Stack)。 デイビッドは、Elastic製品に関するレポートの実施に豊富な経験を持っています(イギリス、ベルギー、フランスでのDevoxx会議、あらゆる種類のJUG、Web5、アジャイルフランス、Mix-IT、Javazone、特定の企業のレポートなど)。 言い換えれば、デビッドは非常に明確かつわかりやすく設定し、彼のレポートは何百もの石油のトレーニングに取って代わります。
この出版物の基礎は、昨年10月にサンクトペテルブルクで開催されたJoker 2016カンファレンスでのDavidのレポートです。 ただし、過去1年間に議論されたトピックは関連性を失っていません。
この記事には2つのバージョンがあります。レポートのビデオ録画と全文転写(「続きを読む」ボタンclickをクリック)。 テキスト版では、必要なすべてのデータがスクリーンショットの形式で表示されるため、何も失われません。
私の名前はデビッドピラトです。私はElasticで4年間働いています。
このレポートは、私がElasticsearchのインストールとSQLベースのアプリケーションの接続に関与していたフランスの税関で働いたときに得た個人的な経験に基づいています。
次に、同様の例を見てみましょう-マーケティングデータの検索です。 誕生日、名前、性別、子供の数などの個人情報、およびマーケティングデータ(ユーザーがモバイルアプリケーションのバスケットにあるボタンを使用する頻度など)を収集する必要があるとします。 既にSQLベースのアプリケーションがありますが、検索にはサードパーティのエンジンが必要です。
アプリ
アプリケーションは次のとおりです。
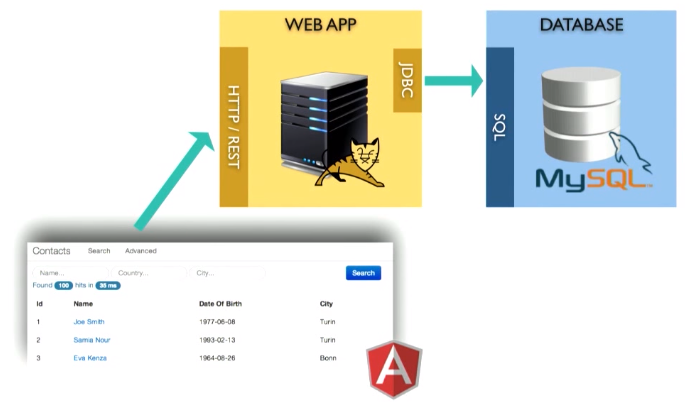
これは、たとえばTomcatコンテナで実行されるWebアプリケーションです。 MySQLデータベース内にデータを保存します。 上部にRESTインターフェースがあります。
たとえば、ある種のアプリケーションをビルドしましょう。 もちろん、今日の会話の主題はフロントエンドではなくバックエンドなので、すべてのJSPツールを使用したわけではありません。
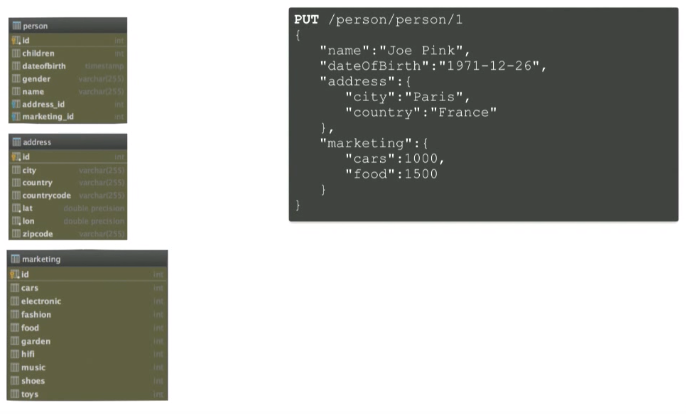
ドメイン

Beanには4つのタイプがあります。
- 人-このBeanには、名前、生年月日、性別などの情報が含まれます。
- 住所
- GeoPoint-地理座標、
- マーケティング-ここに保存されている以前のマーケティング情報について言及しました。
データベースがあるMySQLを見ると、同様の図、つまりテーブルが表示されます。
- 人
- 結合アドレス
- マーケティング。
例に移りましょう。
これらの例をすべて繰り返したい場合は、 GitHubで必要な資料を見つけることができます。

今日のすべてを繰り返すことができます:
$ git clone <a href="https://github.com/dadoonet/legacy-search.git">https://github.com/dadoonet/legacy-search.git</a> $ git checkout 00-legacy $ mvn clean install jetty:run
私の例では、IDEAを使用しています。
最初は何がありますか
アプリケーションには小さな検索部分があります。

まず、いくつかのデータを挿入する必要があります。 これを行うには、ランダムジェネレーターを使用します。 ランダムな個人データを生成し、配列に入れます。
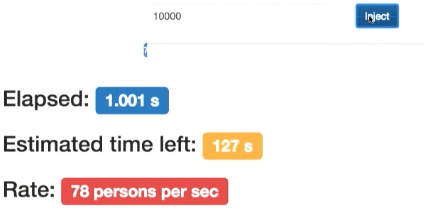
データの生成中に、検索を使用できます。
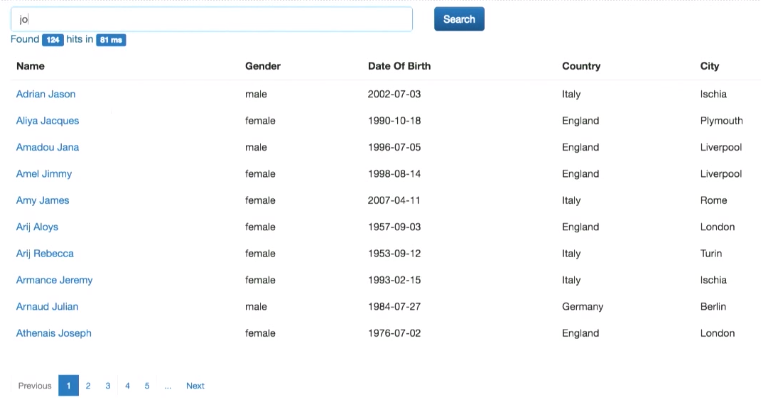
Google検索のようなものです。名前、国などで検索できます。 さらに、高度な検索が実装されています-同時にいくつかのフィールドに:
コード(SearchDaoImpl.java)を見てみましょう。
/** * Find persons by any column (like full text). */ @SuppressWarnings("unchecked") public Collection<Person> findLikeGoogle(String query, Integer from, Integer size) { Criteria criteria = generateQuery(hibernateService.getSession(), Person.class, query); criteria.setFirstResult(from); criteria.setMaxResults(size); return criteria.list(); }
fingLikeGoogleメソッドがあります。 クエリクエリはインターフェイスから取得されます。 検索結果のページへの分割もあります(from変数とsize変数)。 データベースに接続するには、hibernateを使用します。
つまり、hibernateQueryを生成します。 これは次のようなものです。
private Criteria generateQuery(Session session, Class clazz, String query) { String toLikeQuery = "%" + query + "%"; Criteria c = session.createCriteria(clazz); c.createAlias("address", "address"); c.add(Restrictions.disjunction() .add(Restrictions.ilike("name", toLikeQuery)) .add(Restrictions.ilike("address.country", toLikeQuery)) .add(Restrictions.ilike("address.city", toLikeQuery)) ); return c; }
これはtoLikeQueryクエリを使用します。 また、アドレスを結合する必要があります:c.createAliasフィールド( "address"、 "address")。 さらに、フィールドname、address.country、またはaddress.cityによる要求に一致する要素がデータベースにある場合、結果としてそれを返します。
高度な検索を見てみましょう。
public String advancedSearch(String name, String country, String city, Integer from, Integer size) { List<Criterion> criterions = new ArrayList<>(); if (name != null) { criterions.add(Restrictions.ilike("name", "%" + name + "%")); } if (country != null) { criterions.add(Restrictions.ilike("address.country", "%" + country + "%")); } if (city != null) { criterions.add(Restrictions.ilike("address.city", "%" + city + "%")); } long start = System.currentTimeMillis(); hibernateService.beginTransaction(); long total = searchDao.countWithCriterias(criterions); Collection<Person> personsFound = searchDao.findWithCriterias(criterions, from, size); hibernateService.commitTransaction(); long took = System.currentTimeMillis() - start; RestSearchResponse<Person> response = buildResponse(personsFound, total, took); logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits()); String json = null; try { json = mapper.writeValueAsString(response); } catch (JsonProcessingException e) { logger.error("can not serialize to json", e); } return json; }
インターフェイスから、名前、国、都市フィールドを取得します。 これらのインターフェイス要素に入力された組み合わせが、データベース要素の対応するフィールドで見つかった場合、この要素が結果として返されます。
問題の声明
何かを変更する前に、このSQL検索でどの問題を排除したいかという質問に答える必要があります。 例を挙げましょう。
これは、名前とコメントの2つのフィールドを持つ単純なテーブルです。 このような4つのドキュメントをデータベースに挿入します。

簡単な検索を実行します。 ユーザーがアプリケーションの検索バーにDavidと入力するとします。 このデータベースには一致するものはありません。

修正方法 カスタム検索文字列を%記号で囲むことにより、LIKEを使用できます。
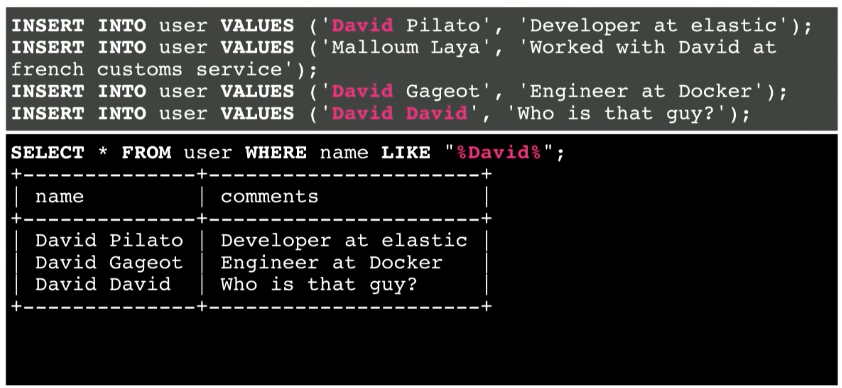
その結果、いくつかの情報が見つかりました。 この方法は機能します。
別の例を見てみましょう。 次に、David Pilatoを探します。
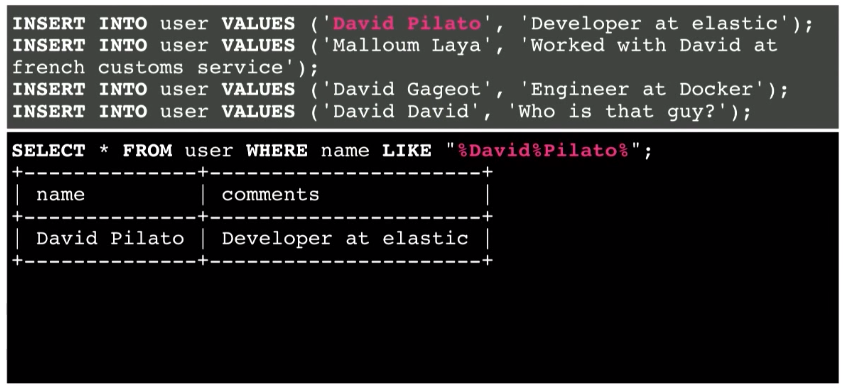
別々の単語の間に、%記号とスペースの両方を置くことができます。 とにかく動作します。
しかし、ユーザーがDavid PilatoではなくPilato Davidを検索した場合はどうなりますか?
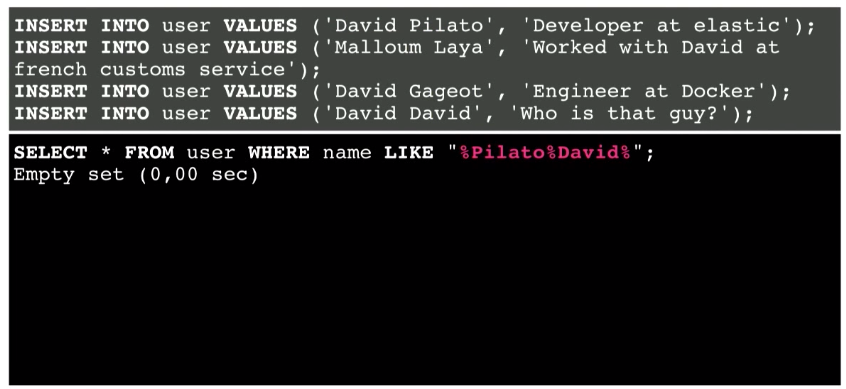
指定された組み合わせがデータベースに存在するという事実にもかかわらず、これは機能しません。
これはどのように修正できますか? インターフェースに入力されたユーザーリクエストを分割し、データベースへの複数のリクエストを使用します。
別の例は、2つのフィールド-名前フィールドとコメントフィールドの両方での検索です。
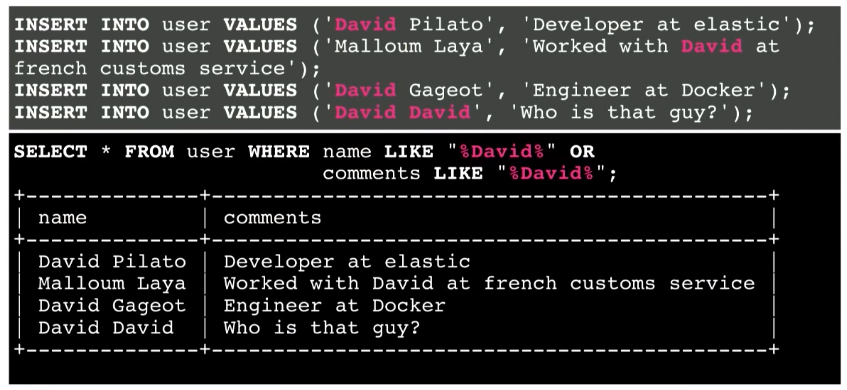
その結果、すべての情報が得られます。 しかし、100万または10億のレコードの場合はどうなりますか? ここで関連する情報は何ですか? おそらく4行目。 名前フィールドでの必要な情報の発見は、コメントフィールドよりも関連性が高いためです。 つまり、この情報をリストの一番上に取得したいのです。 ただし、SQLデータベースには関連性の表現はありません。 それは干し草の山で針を見つけるようなものです。

さらに、スペルミスを覚えておく必要があります。 検索でそれらを考慮する方法は? クエリ内の各文字に疑問符を使用して置換しようとするのは非効率的です。
そして、データベースが本当に需要があり、多くの情報が常にデータベースから要求されていると想像してください。 新しい情報の追加と並行して検索できますか? おそらく10万件のドキュメント、おそらく100万件のドキュメントです。 しかし、10億のドキュメント(ペタバイトのデータ)はどうでしょうか。
検索エンジンを使用して検索してみませんか?
これが今日の予定です。
ソリューションのアーキテクチャ
私の意見では最高だから、Elasticsearchを検索エンジンとして選んだとしよう。 そして、アプリケーションをそれに接続する必要があります。

これをどのように行うことができますか?
ETLを使用できます。 ETLは、ソースからのデータの受信(データベースへのリクエストの送信)、データのJSONドキュメントへの変換、Elasticsearchへのアップロードを提供します。 talendまたはその他の既存のツールを使用できます。
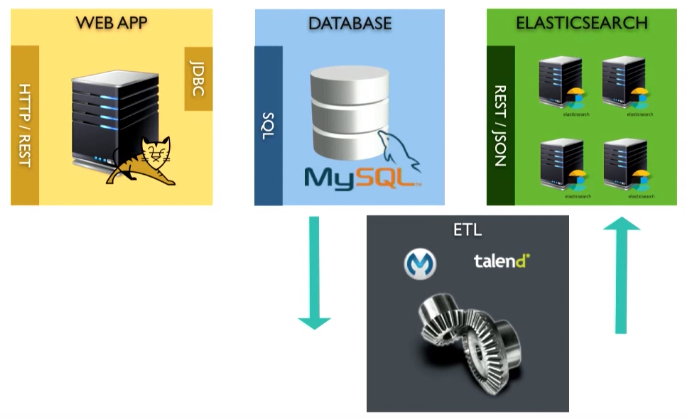
ただし、1つの問題があります。 ETLツールはバッチモードで実行されます。 これは、おそらく5分ごとにリクエストを実行する必要があることを意味します。 つまり、ユーザーがクエリを入力すると、検索結果は5秒後にしか取得できません。 これは完璧ではありません。
削除に問題があります。 データベースから何かを削除する必要があるとします。 SELECTクエリを再実行すると、応答として返されないものを削除する必要があります。 これは非常に難しい作業です。 技術的なテーブル、おそらくトリガーを使用できますが、これはすべて簡単ではありません。
このような問題を解決する私のお気に入りの方法は、アプリケーションとElasticsearchを直接接続することです。 できるなら、それをしてください。

Beanをデータベースにロードするときと同じトランザクションを使用できます。JSONドキュメントに変換してElasticsearchに送信するだけです。 5分後にデータベースを読み込む必要はありません-すでにメモリ内にあります。
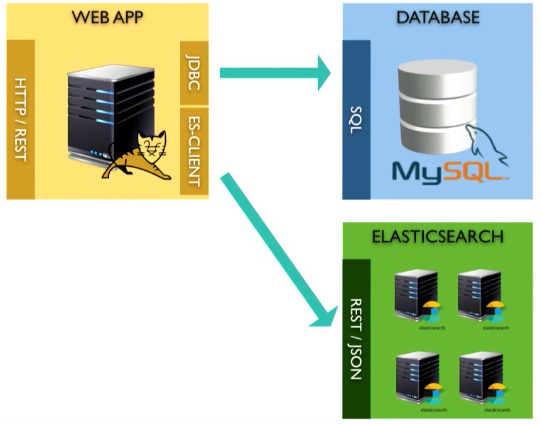
これを行う前に、1つの点に注意してください。 Elasticsearch(または別の同様のソリューション)のように、リレーショナルモデルからドキュメントシステムに移行する場合、モデル自体は異なるアプローチを反映しているため、慎重にモデル自体について考える必要があります。 1つのドキュメントをテーブルに追加してメモリ内で結合を実行する代わりに

必要なすべての情報を含む1つのドキュメントを作成できます。
検索エンジンをプラグインするとき、2つの質問に答える必要があります。
- 私は何を探していますか? 人を探していますか(つまり、人のインデックスを作成します)?
- この人をどのようなパラメーターで探していますか? どのフィールドが必要ですか? たとえば、フランスに住んでいる人を探しています。 次に、ドキュメント内で国のインデックスを作成する必要があります。
例に移りましょう。
直接接続
例のすべての手順はreadmeで説明されているため、すべて自分で実行できます。
$ git clone <a href="https://github.com/dadoonet/legacy-search.git">https://github.com/dadoonet/legacy-search.git</a> $ git checkout 01-direct $ git checkout 02-bulk $ git checkout 03-mapping $ git checkout 04-aggs $ git checkout 05-compute $ mvn clean install jetty:run $ cat README.markdown
そのため、Elasticsearchをプロジェクトに追加する必要があります。 ここではmavenを使用しているため、最初に行うことはElasticsearchを依存関係として追加することです(ここでは、最新バージョンのelasticsearchを使用します)。
<!-- Elasticsearch --> <dependency> <groupId>org.elasticsearch.client</groupId> <version>5.0.0-rc1</version> </dependency>
ここで、アプリケーションに直接渡します。 これは、サービスレベル(PersonService.java)でデータベースに個人の個人データを保存する方法です。
public Person save(Person person) { hibernateService.beginTransaction(); Person personDb = personDao.save(person); hibernateService.commitTransaction(); return personDb; }
hibernateトランザクションを開き、personDao.saveを呼び出してから、トランザクションを完了します。
ここでは、Elasticsearchを使用してデータのインデックスを作成できます。 新しいクラス-elasticsearchDao-を作成し、personDBオブジェクト(personID、hibernateによって生成されたElasticsearchに同じIDを使用するため)を保存します。
public Person save(Person person) { hibernateService.beginTransaction(); Person personDb = personDao.save(person); elasticsearchDao.save(personDb); hibernateService.commitTransaction(); return personDb; }
クラスを追加する必要があります。
private final ElasticsearchDao elasticsearchDao;
そして、このクラスを(ElasticsearchDao.javaで)作成します。
ここでは、restiksフレームワークを使用しているため、自動的に注入する注釈があります。
import restx.factory.Component;
ここでは、 Componentアノテーションを使用するため、PersonServiceクラス(PersonService.java)でこのコンポーネントを注入する必要があります。
@Inject public PersonService(PersonDao personDao, SearchDao searchDao, HibernateService hibernateService, <b> ElasticsearchDao elasticsearchDao,</b> ObjectMapper mapper, DozerBeanMapper dozerBeanMapper) { this.personDao = personDao; this.searchDao = searchDao; this.hibernateService = hibernateService; this.mapper = mapper; this.dozerBeanMapper = dozerBeanMapper; <b> this.elasticsearchDao = elasticsearchDao;</b> }
ここで、ElasticsearchDao.javaでelasticsearchDao.save(personDb)メソッドを実装する必要があります。 これを行うには、まずElasticsearchクライアントを作成する必要があります。 これを行うには、次を追加します。
@Component public class ElasticsearchDao { private final Client esClient; public void save(Person person) { } }
クライアントを実装する必要があります。 既存のクラスを使用して、既存のアーティファクトを転送できます。
@Component public class ElasticsearchDao { private final Client esClient; public ElasticsearchDao() { this.esClient = new PreBuiltTransportClient(Settings.EMPTY); } public void save(Person person) { } }
次に、Elasticsearchが配置されているマシンとポートを宣言する必要があります。 これを行うには、addTransportAddressを追加し、この場合のElasticsearchがローカルで実行されていることを示します。 デフォルトでは、Elasticsearchはポート9300で開始します。
public ElasticsearchDao() { this.esClient = new PreBuiltTransportClient(Settings.EMPTY); .addTransportAddress(new InetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300) )); }
BeanをJSONドキュメントに変換するものも必要です。 これを行うには、ジャクソンライブラリを使用します。 私のRestixにはすでに存在しているので、注入するだけです。
@Component public class ElasticsearchDao { private final Client esClient; <b>private final ObjectMapper mapper;</b> public ElasticsearchDao(<b>ObjectMapper mapper</b>) { this.esClient = new PreBuiltTransportClient(Settings.EMPTY); .addTransportAddress(new InetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300) )); <b> this.mapper = mapper;</b> } public void save(Person person) { } }
これで、saveメソッドを実装できます。
BeanをJSONドキュメントに変換する必要があります。 ここでは、出力をJSON StringまたはByteドキュメント(それぞれwriteValueAsStringまたはwriteValueAsBytes)にするかどうかを選択する必要があります-Byteを使用しますが、必要に応じてStringを使用できます。
public void save(Person person) throws Exception { <b>byte[] bytes = mapper.writeValueAsBytes(person);</b> }
JSONドキュメントはバイト配列になりました。 Elasticsearchに送信する必要があります。
Elasticsearchはさまざまなアクセスレベルを提供するため、同じ表記法を使用してさまざまなタイプのデータにインデックスを付けることができます。 ここでは、以前にhibernateから取得したドキュメントIDを使用します。
.sourceを使用すると、JSONドキュメント自体を取得できます。
public void save(Person person) throws Exception { byte[] bytes = mapper.writeValueAsBytes(person); <b>esClient.index(new IndexRequest("person", "person", person.idAsString()).source(bytes).actionGet());</b> }
したがって、これら2行を使用して、BeanをJSONに変換し、最後の行をElasticsearchに送信しました。
コンパイルしてみましょう。 例外を取得:
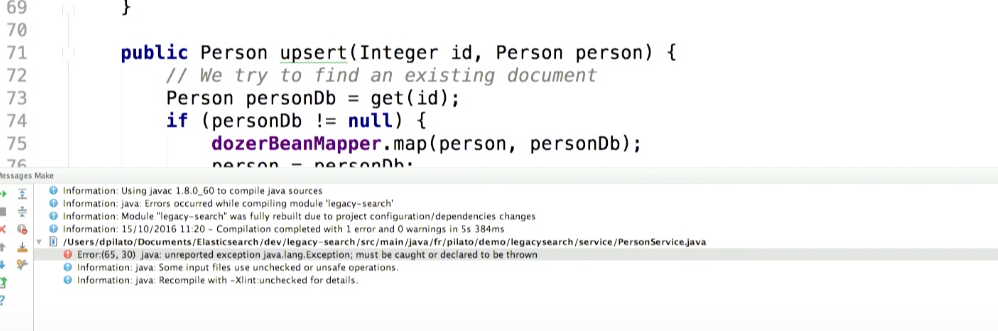
Elasticsearchとやり取りしているときに何か悪いことが起こったとします。 この例外で何ができますか? 休止状態でトランザクションをロールバックするようなもの。
これを行うには、PersonService.javaに追加できます。
public Person save(Person person) { hibernateService.beginTransaction(); Person personDb = personDao.save(person); try { elasticsearchDao.save(personDb); } <b>catch (Exception e) { hibernateService.rollbackTransaction(); e.printStackTrace(); }</b> hibernateService.commitTransaction(); return personDb; }
しかし、データベース内のデータの存在は検索エンジンの作業よりもはるかに重要だと考えているため、これを行いたくありません。 したがって、ユーザーの入力を失いたくありません。 トランザクションをロールバックする代わりに、例外をログに記録して、後でエラーの原因を見つけて修正します。
public Person save(Person person) { hibernateService.beginTransaction(); Person personDb = personDao.save(person); try { elasticsearchDao.save(personDb); } <b>catch (Exception e) { logger.error("Houston, we have a problem!", e); }</b> hibernateService.commitTransaction(); return personDb; }
次に、レコードを削除する操作を見てみましょう。 彼女は同一です。 Elasticsearchでは、同じトランザクションを使用してエントリを簡単に削除できます。
public boolean delete(Integer id) { logger.debug("Person: {}", id); if (id == null) { return false; } hibernateService.beginTransaction(); Person person = personDao.get(id); if (person == null) { logger.debug("Person with reference {} does not exist", id); hibernateService.commitTransaction(); return false; } personDao.delete(person); <b> elasticsearchDao.delete(person.idAsString());</b> hibernateService.commitTransaction(); logger.debug("Person deleted: {}", id); return true; }
このメソッドはElasticsearchDao.javaで実装できます。 インデックス名-personおよびtype-also personを使用してDeleteRequestを呼び出します。
public void delete(String idAsString) throws Exception { esClient.delete(new DeleteRequest("person", "person", idAsString)).get(); }
同様に、PersonService.javaにcatchを追加します。
personDao.delete(person); <b>try {</b> elasticsearchDao.delete(person.idAsString()); <b>} catch (Exception e) { e.printStackTrace(); }</b> hibernateService.commitTransaction();
それでは、アプリケーションを再起動しましょう。 Elasticsearchを実行するために残ります(Elasticsearchの通常のインストールがあります)。

Elasticsearchは2つのポートのリッスンを開始します。
- Javaクライアントの場合は9300。
- 9200-REST API。
また、別のツール-kibanaも並行して実行します。 Elasticで作成したこのオープンソースツール。 これを使用してデータを表示します。 しかし、今日、kibanaを使用して[コンソール]タブにアクセスし、個々のリクエストを実行できるようにします。
もう一度10,000個のドキュメントを生成しましょう。

Kibanaは、インデックス作成者がすでに作成されていることを示しています。
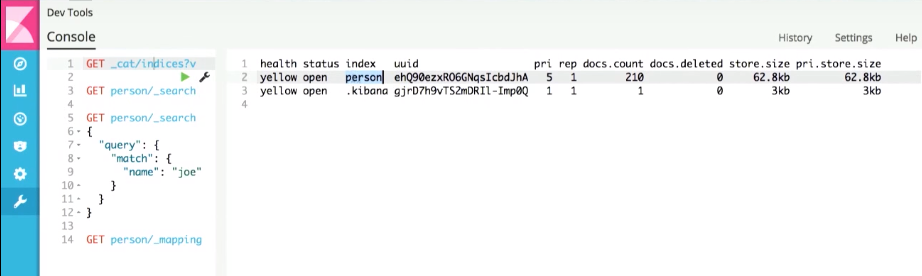
そして、任意のドキュメントに対して最も単純な検索を実行すると、最近生成されたドキュメントが取得されます。
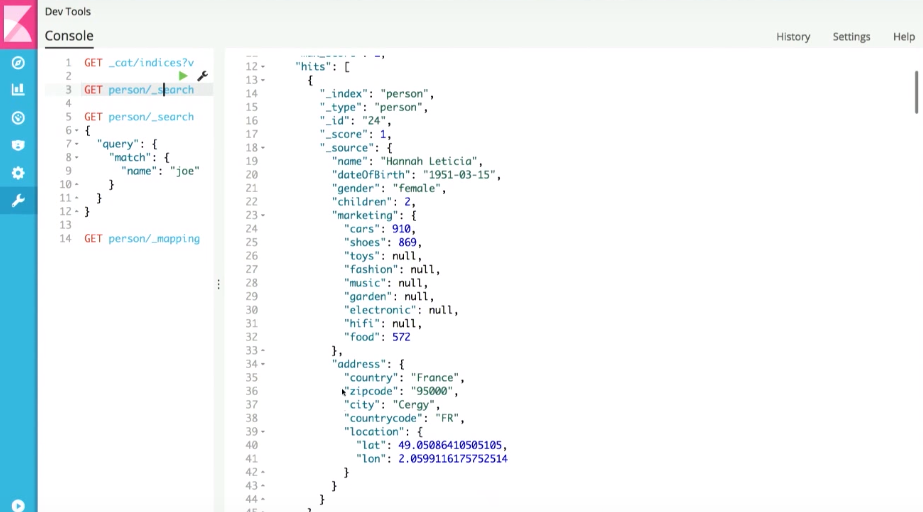
これは、Beanから生成されたJSONドキュメントです。
ここで、個々のフィールドを検索できます。
しかし、アプリケーションに戻ります。 変更にもかかわらず、検索エンジンがまだ統合されていないため、インターフェイスでデータベース検索を取得できます。 やってみましょう。
PersonService.javaには検索メソッドがあります。 置き換えてみましょう。 以前、そこでfindLikeGoogleを呼び出しましたが、今では解決策が異なります。
最初に、Elasticsearchへのクエリを作成する必要があります。
public String search(String q, String f_country, String f_date, Integer from, Integer size) { <b>QueryBuilder query;</b> }
ユーザーが何も入力しないとします。 この場合、特別なリクエスト-matchAll-を発行します。
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; <b>if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); }</b> }
それ以外の場合は、別の種類のクエリsimpleQueryStringQueryを使用します。 特定のフィールドにユーザーが入力したテキストを検索します。
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); }<b> else { query = QueryBuilders.simpleQueryStringQuery(q) .field("name") .field("gender") .field("address.country") .field("address.city"); }</b> }
次に、elasticsearchDaoを使用して検索クエリを送信します。
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); } else { query = QueryBuilders.simpleQueryStringQuery(q) .field("name") .field("gender") .field("address.country") .field("address.city"); } <b>elasticsearchDao.search(query, from, size);</b> }
このメソッドを実装しましょう。
繰り返しますが、esClientを使用する必要があります。 ここではprepareSearch()メソッドが使用されます。 この場合、検索は個人インデックスで実行され(必要に応じて、複数のエンティティを同時に検索できます)、タイプを設定し、以前に作成したクエリを実行します。 ページネーションオプションを設定します。 ここでは非常に単純です(データベースのページネーションは本当に悪夢です)。
get()メソッドを使用して、リクエストを実行し、結果を返します。
public SearchResponse search(QueryBuilder query, Integer from, Integer size) { SearchResponse response = esClient.prepareSearch("person") .setTypes("person") .setQuery(query) .setFrom(from) .setSize(size) .get(); return response; }
PersonService.javaのコードを修正して、検索クエリへの応答を取得しましょう。 残っているのは、結果を文字列として返すことだけです(最初は答えはJSONドキュメントです):
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); } else { query = QueryBuilders.simpleQueryStringQuery(q) .field("name") .field("gender") .field("address.country") .field("address.city"); } <b>SearchResponse response =</b> elasticsearchDao.search(query, from, size); return response.toString(); }
高度な検索のアップグレードに移りましょう。 ここでのすべては、以前に行ったことと似ています。
ユーザーが名前、国、都市のフィールドにクエリを入力していない場合は、matchAllクエリを実行してドキュメント全体を取得します。 それ以外の場合は、ブールリクエストを作成します。名前フィールドに何かがある場合は、JSONドキュメントの名前フィールドでそれを検索する必要があります(国および都市と同様)。
その後、同じelasticsearchDaoを使用して、結果をユーザーに送信します。
public String advancedSearch(String name, String country, String city, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(name) && !Strings.hasText(country) && !Strings.hasText(city)) { query = QueryBuilders.matchAllQuery(); } else { BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); if (Strings.hasText(name)) { boolQueryBuilder.must( QueryBuilders.matchQuery("name", name) ); } if (Strings.hasText(country)) { boolQueryBuilder.must( QueryBuilders.matchQuery("address.country", country) ); } if (Strings.hasText(city)) { boolQueryBuilder.must( QueryBuilders.matchQuery("address.city", city) ); } query = boolQueryBuilder; } SearchResponse response = elasticsearchDao.search(query, from, size); if (logger.isDebugEnabled()) logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits()); return response.toString(); }
仕組みを確認してください。 アプリケーションを再起動します。
次に、特定のリクエストを紹介して、Elasticsearchに送信します。
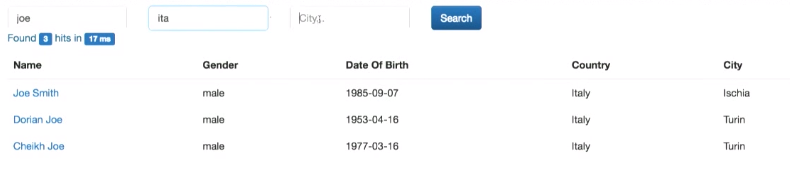
この実験は、完全一致検索のみが機能することを示しています(文字列の一部ではありません)。 これは後で修正します。 ただし、現在は姓と名、および姓と名の両方で検索できます。 さらに、結果の関連性が現れました。 Joe Smithを検索すると、完全一致レコード(Joe Smith)が最も関連性の高い結果リストの最上位になります。 次に、同じ名前または姓のレコードに移動します。
バッチモード
別のコンセプトを紹介したいと思います。 ElasticsearchにJavaクライアントを使用するかどうかに関係なく、Bulk APIを使用することをお勧めします。 ドキュメントをElasticsearchに1つずつ挿入する代わりに、Bulk APIを使用してドキュメントをバッチで処理できます。 Javaクライアントでは、Bulk APIはbulkProcessorと呼ばれます。
@Inject public ElasticsearchDao(ObjectMapper mapper) { this.esClient = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InternetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300) )); this.mapper = mapper; this.bulkProcessor = BulkProcessor.builder(esClient, new BulkProcessor.Listener() { @Override public void beforeBulk(long executionID, BulkRequest request) { logger.debug("going to execute bulk of {} requests", request.numberOfActions()); } @Override public void afterBulk(long executionID, BulkRequest request, BulkResponse response) { logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without"); } @Override public void afterBulk(long executionID, BulkRequest request, Throwable failure) { logger.warn("error while executing bulk", failure); } }) .setBulkActions(10000) .setFlushInterval(TimeValue.timeValueSeconds(5)) .build(); }
bulkProcessorとロガーを追加することも必要です。
private final BulkProcessor bulkProcessor; private final Logger logger = LoggerFactory.getLogger(ElasticsearchDao.class);
bulkProcessorは、以前に作成されたesClientで動作します。 リクエストがいっぱいで、10,000件の操作ごとにリクエストがElasticsearchにバッチ送信されます。 10,000件のリクエストを受信しなくても、送信は5秒ごとに実行されます。 ここにリスナーを追加し、リクエストのバッチ送信前、リクエスト送信後、またはリクエストの実行時に例外を受信した場合に実行するアクションを設定できます。
残りのコードに変更を加えましょう。
現在、esClient.indexの代わりにbulkProcessorがあります。 また、起動はbulkProcessorによって提供されるため、リクエストを実行する必要はありません。
public void save(Person person) throws Exception { byte[] bytes = mapper.writeValueAsBytes(person); bulkProcessor.add(new IndexRequest("person", "person", person.idAsString()).source(bytes)); }
削除についても同じ:
public void delete(String id) throws Exception { bulkProcessor.delete(new DeleteRequest("person", "person", idAsString)); }
, — . Elasticsearch.
, Elasticsearch (mapping — schema ), , city person, , text:
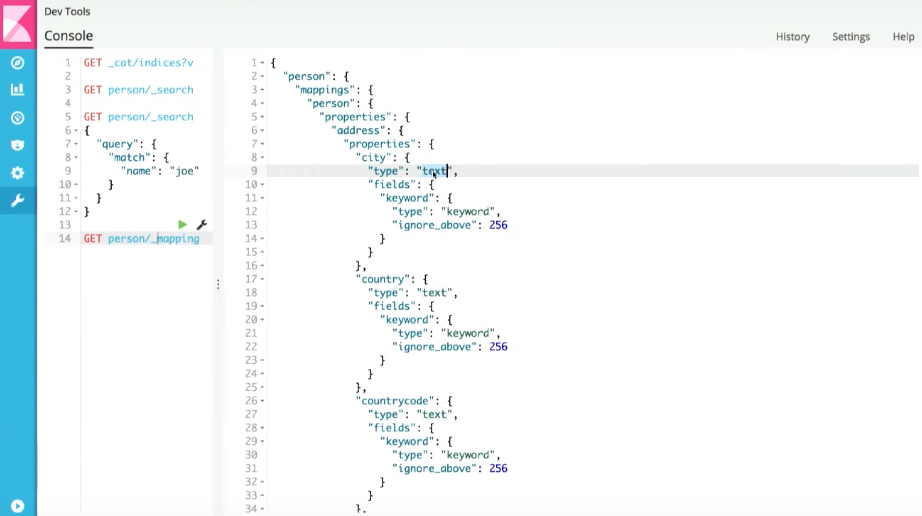
, . , mapping Elasticsearch ( ).
open source Beyonder.
maven:
<!-- Elasticsearch-Beyonder --> <dependency> <groupId>fr.pilato.elasticsearch</groupId> <artifactId>elasticsearch-beyonder</artifactId> <version>2.1.0</version> </dependency>
, elasticsearch resources, , index ( — person), beyonder , type.json ( type — person, — person.json). mapping.
mapping, REST- Elasticsearch, Beyonder .
, city text ( ), (address.city.autocomplete) text, — .
, , address.city fulltext, .
"city": { "type": "text", "copy_to": "fulltext", "fields": { <b> "autocomplete" : { "type": "text", "analyzer": "ngram", "search_analyzer": "simple" },</b> "aggs" : { "type": "keyword" } } },
address.coutry, name gender.
ngram . Elasticsearch _settings.json. , Beyonder .
( , — ). . «», Joe j, jo joe. , .
{ "analysis": { "analyzer": { "ngram": { "tokenizer": "ngram_tokenizer", "filter": [ "lowercase" ] } }, "tokenizer": { "ngram_tokenizer": { "type": "edgeNGram", "min_gram": "1", "max_gram": "10", "token_chars": [ "letter", "digit" ] } } } }
- Beyonder. ElasticsearchDao.java, :
@Inject public ElasticsearchDao(ObjectMapper mapper) { this.esClient = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InternetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300) )); this.mapper = mapper; this.bulkProcessor = BulkProcessor.builder(esClient, new BulkProcessor.Listener() { @Override public void beforeBulk(long executionID, BulkRequest request) { logger.debug("going to execute bulk of {} requests", request.numberOfActions()); } @Override public void afterBulk(long executionID, BulkRequest request, BulkResponse response) { logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without"); } @Override public void afterBulk(long executionID, BulkRequest request, Throwable failure) { logger.warn("error while executing bulk", failure); } }) .setBulkActions(10000) .setFlushInterval(TimeValue.timeValueSeconds(5)) .build(); <b>try { ElasticsearchBeyonder.start(esClient); } catch (Exception e) { e.ptintStackTrace(); } }
Beyonder . kibana:
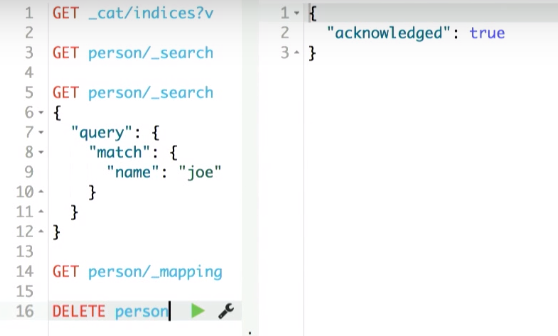
, person index:

( debug-). , Beyonder :
kibana , index person , resources.
10000 .

. . PersonService.java, , name, gender, address.country address.city. fulltext, . name, ( name, , ):
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); } else { query = QueryBuilders.simpleQueryStringQuery(q) .field(<b>"fulltext"</b>) .field(<b>"name", 3.0f</b>) } SearchResponse response = elasticsearchDao.search(query, from, size); return response.toString(); }
.

Joe Joe .
country, city.
, . PersonService.java name name.autocomplete, ( address.country address.city):
public String advancedSearch(String name, String country, String city, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(name) && !Strings.hasText(country) && !Strings.hasText(city)) { query = QueryBuilders.matchAllQuery(); } else { BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); if (Strings.hasText(name)) { boolQueryBuilder.must( QueryBuilders.matchQuery("<b>name.autocomplete</b>", name) ); } if (Strings.hasText(country)) { boolQueryBuilder.must( QueryBuilders.matchQuery("<b>address.country.autocomplete</b>", country) ); } if (Strings.hasText(city)) { boolQueryBuilder.must( QueryBuilders.matchQuery("<b>address.city.autocomplete</b>", city) ); } query = boolQueryBuilder; } SearchResponse response = elasticsearchDao.search(query, from, size); if (logger.isDebugEnabled()) logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits()); return response.toString(); }
.
作業速度
: Elasticsearch , . ?
.
Elasticsearch.
public Person save(Person person) { // hibernateService.beginTransaction(); // Person personDb = personDao.save(person); try { elasticsearchDao.save(<b>person</b>); } catch (Exception e) { logger.error("Houston, we have a problem!", e); } // hibernateService.commitTransaction(); return person; }
コンパイルします。 bulk API Elasticsearch. 10000 . .
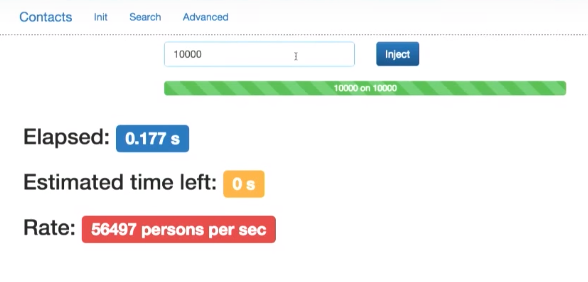
.
, . , 4 .
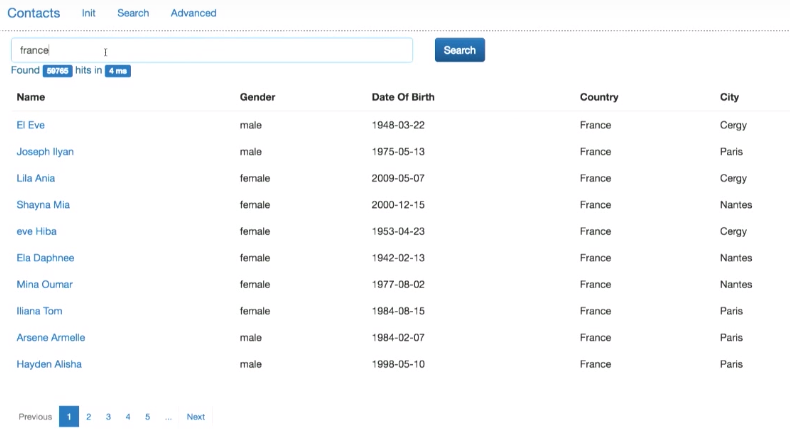
Elasticsearch . .
ElasticsearchDao .
public SearchResponse search(QueryBuilder query, Integer from, Integer size) { SearchResponse response = esClient.prepareSearch("person") .setTypes("person") .setQuery(query) <b> .addAggregation( AggregationBuilders.terms("by_country").field("address.country.aggs") ) .addAggregation( AggregationBuilders.dateHistogram("by_year") .field("dateOfBirth") .minDocCount(0) .dateHistogramInterval(DateHistogramInterval.YEAR) .extendedBounds(new ExtendedBounds(1940L, 2009L)) .format("YYYY") )</b> .setFrom(from) .setSize(size) .get(); return response; }
ここで何が起こっていますか? Aggregation by_country address.country (.aggs — «» keyword Elasticsearch 5 , ). -10 , ( , ).
by_year dateOfBirth.
. , .
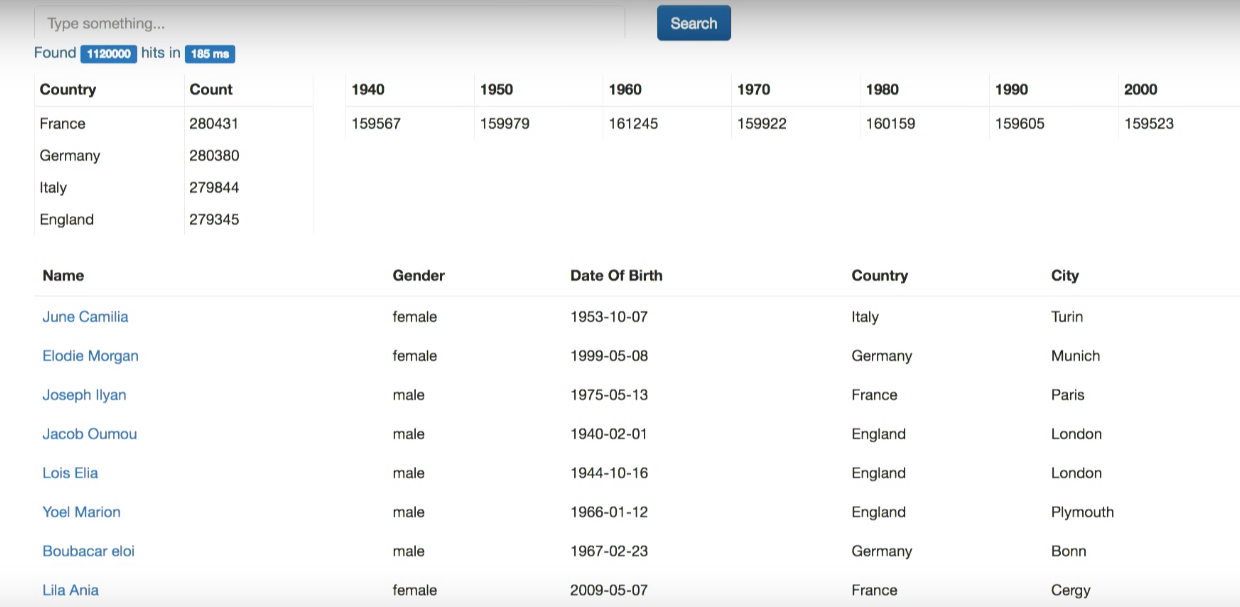
.
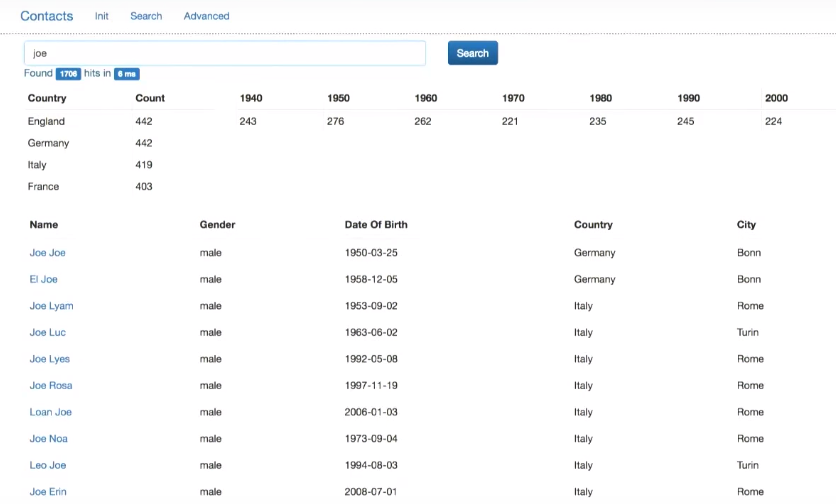
, , — , . .
PersonService.java, . , :
public String search(String q, String <b>f_country</b>, String <b>f_date</b>, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); } else { query = QueryBuilders.simpleQueryStringQuery(q) .field("fulltext") .field("name", 3.0f) } <b>if (Strings.hasText(f_country) || Strings.hasText(f_date)) { query = QueryBuilders.boolQuery().must(query); if (Strings.hasText(f_country)) { ((BoolQueryBuilder) query).filter(QueryBuilders.termQuery("address.country.aggs", f_country)); } if (Strings.hasText(f_date)) { String endDate = "" + (Integer.parseInt(f_date) + 10); ((BoolQueryBuilder) query).filter(QueryBuilders.rangeQuery("dateOfBirth").gte(f_date).lt(endDate)); } } SearchResponse response = elasticsearchDao.search(query, from, size); return response.toString(); }
- f_country f_date, , ( must query). - (f_country), . — f_date ( ).
— :
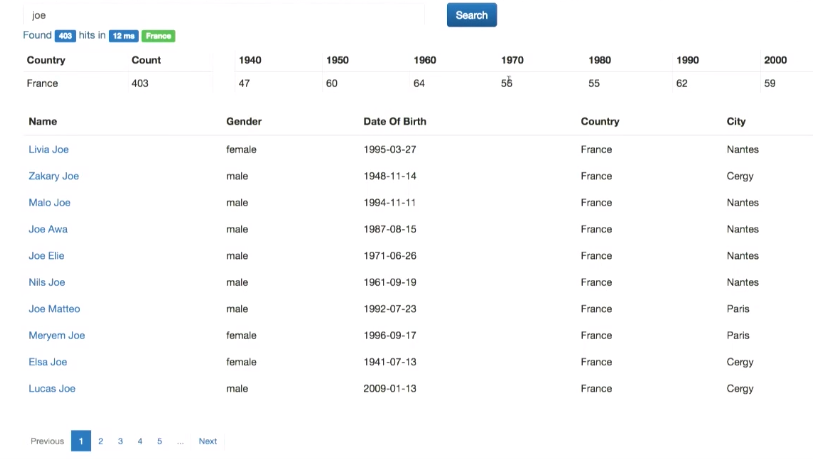
Elasticsearch ( ..). ElasticsearchDao.java.
public SearchResponse search(QueryBuilder query, Integer from, Integer size) { SearchResponse response = esClient.prepareSearch("person") .setTypes("person") .setQuery(query) .addAggregation( AggregationBuilders.terms("by_country").field("address.country.aggs") .subAggregation(AggregationBuilders.dateHistogram("by_year") .field("dateOfBirth") .minDocCount(0) .dateHistogramInterval(DateHistogramInterval.days(3652)) .extendedBounds(new ExtendedBounds(1940L, 2009L)) .format("YYYY") .subAggregation(AggregationBuilders.avg("avg_children").field("children")) ) ) .addAggregation( AggregationBuilders.dateHistogram("by_year") .field("dateOfBirth") .minDocCount(0) .dateHistogramInterval(DateHistogramInterval.YEAR) .extendedBounds(new ExtendedBounds(1940L, 2009L)) .format("YYYY") ) .setFrom(from) .setSize(size) )); return response; }
. , , , .
( ):

Exception
, Elasticsearch. , Elasticsearch. , exception, . , broker. Elasticsearch message queue system, , , , , message queue esClient Elasticsearch.

, message queue, - logstash:
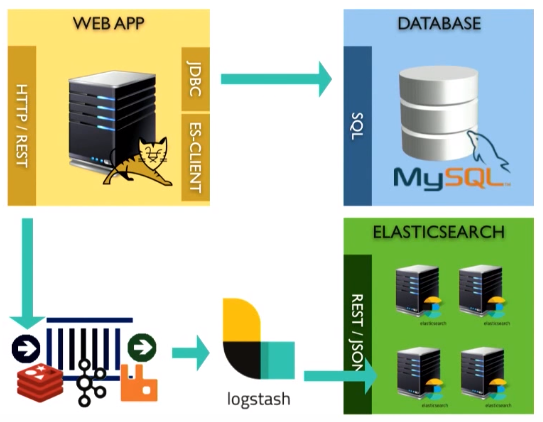
open source , Elastic. , Elasticsearch .
Logstash — :

合計ではなく
- , 1-2 («proof of concept»), Elasticsearch, , , .
— kibana, , , :
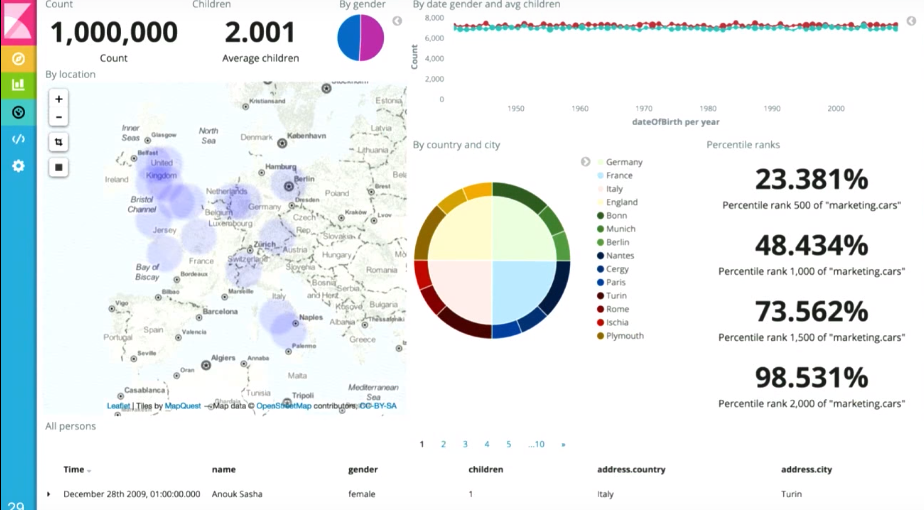
.
Java, Joker 2017 :
- Java 9: the good parts (Cay Horstmann, San Jose State University)
- Java 8: , , ( , XP Injection)
- Birth, life and death of a class (Volker Simonis, SAP)
- Java Code Coverage mechanics (Evgeny Mandrikov, Marc Hoffmann)