
こんにちは、Habr! 私たちは伝統を継続し、チャネル#article_essenseからオープンデータサイエンスコミュニティのメンバーから科学記事のレビューを毎月リリースします。 誰よりも早くそれらを受け取りたい場合は、 ODSコミュニティに参加してください!
記事は、個人的な興味から、または進行中のコンテストに近いために選択されます。 記事の説明は変更せずに、著者がチャンネル#article_essenceに投稿した形式で提供されることを思い出してください。 あなたがあなたの記事を提供したい場合、またはあなたが希望を持っている場合-コメントを書くだけで、私たちは将来的にすべてを考慮に入れようとします。
今日の記事:
- 機械学習:応用計量経済学的アプローチ
- スクイズおよび励起ネットワーク
- 拡張畳み込みを使用したテキストモデリング用の改善された変分オートエンコーダ
- CNNと同じ速さでRNNをトレーニングする
- 自動エンコーダーの変換
- 動作が集合論に依存しない比較的小さなチューリングマシン
- さまざまな寿命の樹木種におけるテロメア長とテロメラーゼ活性の分析、およびイガゴヨウマツの年齢
- 途方もなく大規模なニューラルネットワーク:疎ゲートの専門家の混合層
- 意識優先
1.機械学習:応用計量経済学的アプローチ
→ オリジナル記事
投稿者:dr_no
エントリー
MLなどの重要性について など、計量経済学者と高次元データの観点から、ML、ビッグデータと経済学、 LASSOのイントロに関する出版物へのリンクがあります。 回帰問題における差および関係パラメーターの推定と予測について。
機械学習の仕組み
問題の記述は、教師あり機械学習、最小二乗法の比較、回帰ツリー(回帰ツリー)、LASSO、ランダムフォレスト(700ツリー中)、オーバーフィット/クロス検証/ cfoldsについてです。
さまざまなアプローチの結果の評価:
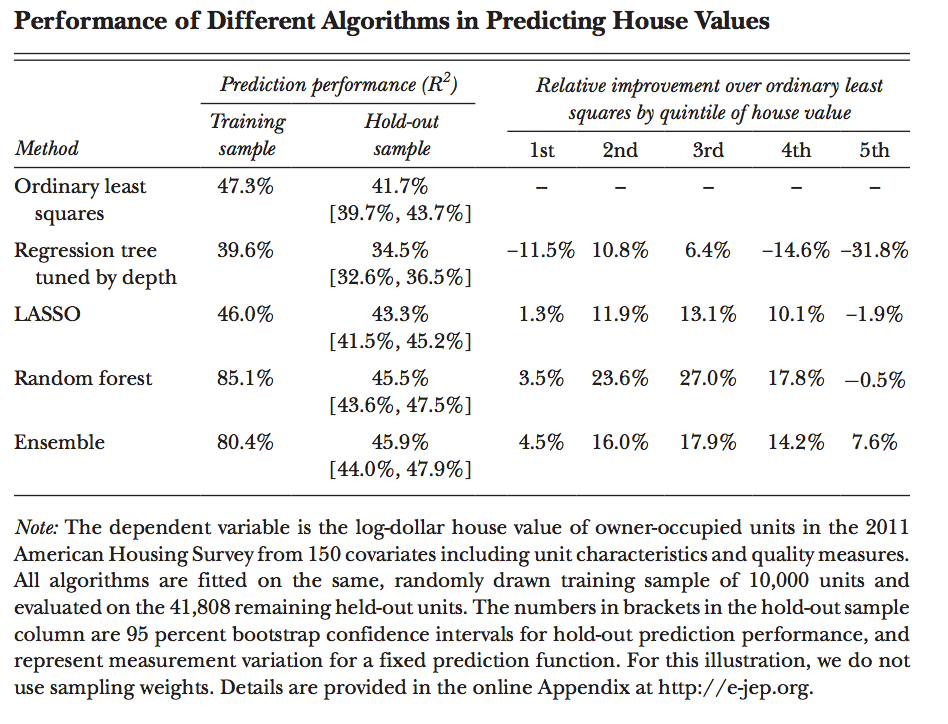
さらに、正則化、モデルパラメーターの経験的ツイストのアイデアを進めます。
経済的問題への適用についてさらに:
0)モデル選択;
1)データの準備/変換。
2)正規化の対象となる派生的特徴(部屋の数に対する面積の割合など)の重要性、多数の類似する特徴の計算の困難性など。
3)チューニング、ここでの考え方は、計量経済学は、一方では設計の選択(フォールドの数、予測関数のタイプ)を支援することにより、他方では、予測の最終的な品質を決定することにより支援することです(2番目に、当てはめられた予測関数ホールドアウトサンプルにより、近似関数の予測特性に関する適切なサイズのテストを正確に作成できます。
機械学習の出力から何を学べるか(学ばないか)
予測関数に基づいてシミュレートされたプロセスのパターンを見つけようとする試みの無意味さについて。 家の価格を予測するときにN
の変数N
関係しない場合、これはこの要素が重要ではないことを意味しますか? そのような結論は間違っています。
そのような結論の問題は、係数の標準誤差がないことです。 その結果が線形関数であるモデルであっても、これは問題です。理由はモデルの選択にある可能性があるためです。
このような問題の別の例は、ソースデータのサブセットで同等の品質を備えた元のモデル(LASSO予測子)に類似した10モデルの再構築です。
上記の理由は、相関、機能の互換性です。 最終的な選択はデータに依存します。 さらに、従来のアプローチでは、観測値の相関が変数の最終効果を処方する大きな標準誤差に反映されると述べられています。
MLでは、膨大な数の異なる関数を取得でき、異なる係数により同等の予測品質が得られます。 正則化は、火災に燃料を追加するだけで、複雑さの少ない、したがってより不正確なモデルを選択することを余儀なくされ、変数バイアスの省略による体系的なエラーをもたらします。
それでも、モデルは時々、シミュレートされたものの性質について考えるための食物を提供できます。
そして、ML、ビッグデータ、絶対に一見無関係なタスク(夜間照明と経済指標)を解決するための衛星画像の使用に関する多くのインスピレーションを与えるスピーチがあり、同様のタスクが他の応用分野で与えられ、結論が引き出されます。 たとえば、裁判官の決定のタスク:拘禁後、裁判官は、被告人が自宅で聴聞会を待つか、バーの後ろで待つかを決定しなければなりません。
計量経済学者への利益の観点からの教師付きMLに関する疑わしい考え。 私が好きなことから:
1)結果の重みと結果の関数は、根本的な問題について実際には話さない。
2)モデルと正則化の要約表。
3)いくつかの参照。
4)裁判官によって「バーの後ろ/家」を選択するという事実。
特に読むことはお勧めしませんが、計量経済学の人がMLの価値を見ない場合は、この記事を手に入れることができます。
2. Squeeze-and-Excitation Networks(ImageNet 2017受賞者)
→ オリジナル記事
投稿者:kostia
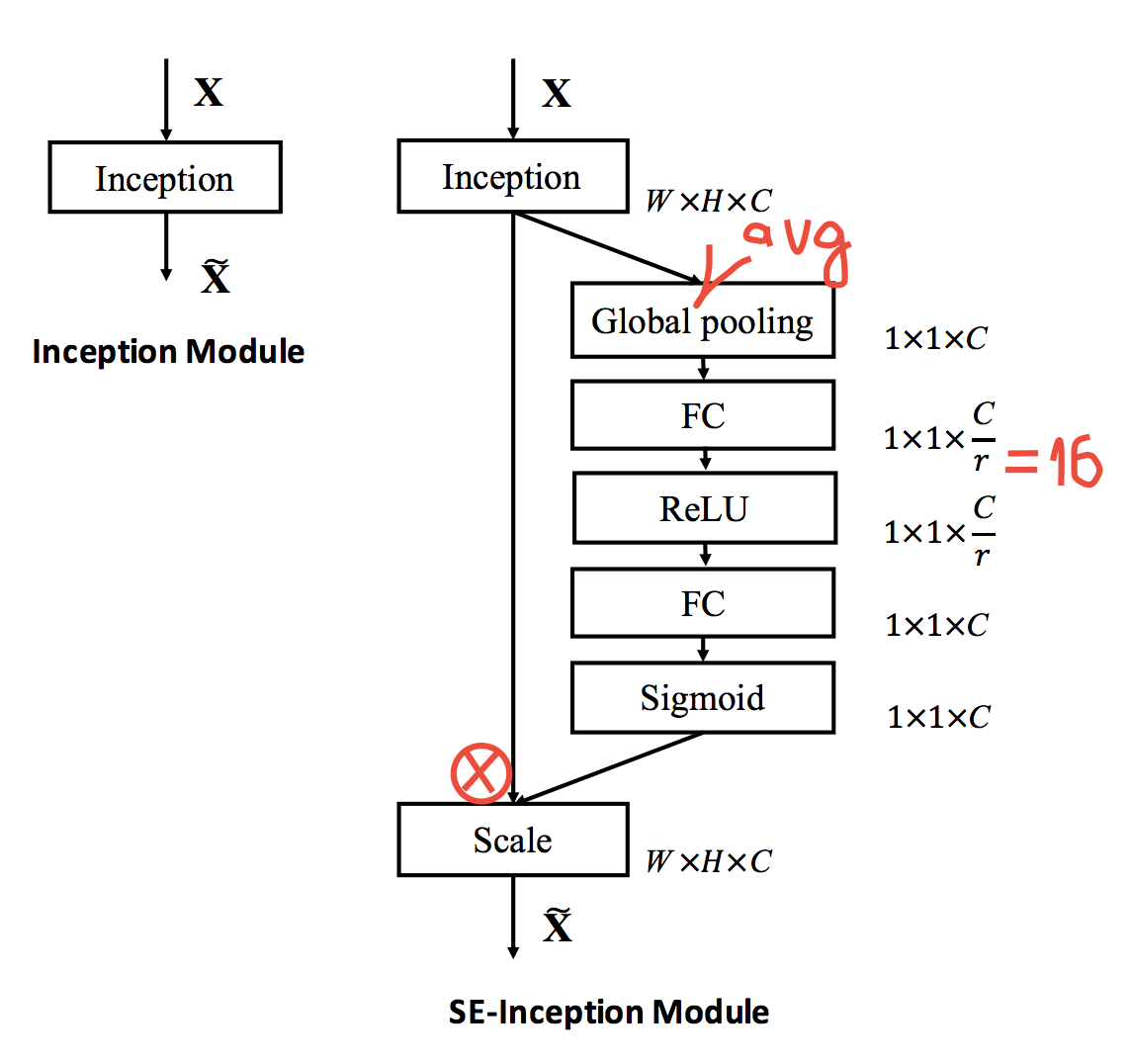
お気に入りのResNet、Inceptionなどに SEモジュールを追加して精度を上げることができます。たとえば、昨年2.99%の後、ImageNetの新しいtop5が2.99%になり、ResNet50では7.5%ではなく6.6%になります。 フロップのオーバーヘッドが最小で、時間のオーバーヘッドが約10%のResNet100とほぼ同じです。
モジュールは非常に単純で、畳み込みブロックの後にすべてのSoTAアーキテクチャに挿入され、実際にはゲーティングチャネルを生成します。 それがどのように機能するかについての詳細は、図に示されています。グローバルな平均プーリングを行い、ReLUでブロットルネックを行い、シグモイドをゲーティングします。 直感は、チャネル間の依存関係を明示的にモデル化し、再調整することです。
この記事には、モジュールの実証分析も含まれています。下位層では、すべてのクラスで同じことを行い、出力に近いほど、異なるクラスでは異なることを行います。
3.拡張畳み込みを使用したテキストモデリング用の改善された変分オートエンコーダ
→ オリジナル記事
投稿者:asobolev
たとえば、教師なしモードで優れた機能を見つけるのに役立つ、テキスト用のバリエーション自動エンコーダーについて説明します。 ただし、このようなVAEを単純な方法で、つまりRNNエンコーダーとRNNデコーダーを使用して行う場合、多くの著者が学習の困難を報告します。 実際、問題は、RNN自体がすでにかなり強力なモデルであり、追加情報なしで言語モデルをモデル化し、リカレントネットワークがそのような分布のみをモデル化できることです。
したがって、通常のRNNデコーダーは非常に強力なので、それらをより単純なものに置き換えましょう。 著者は「希釈畳み込み」(「デビュー畳み込み」を選択しました。これはWaveNetについての記事でデビューしましたが、ストライド畳み込みと混同しないように、 ここでは「簡単なもの」として参照してください)。 私が理解しているように、この選択の理由は、比較的浅いデコーダでさえかなり広い範囲を持つことです。 十分に長いローカル依存関係をモデル化できます。 このようなデコーダーの深さを増やすことにより、そのパワーを増やすことが期待されます。
著者は、VAE自体だけでなく、それに基づく半教師あり学習も検討しています。 さらに、このようなモデルはクラスラベルを考慮することができるため、作成者が行うクラスタリングに使用するのが自然です。
実験:通常のLSTMがエンコーダーとして使用され、ベースラインLSTMおよび4つの畳み込みホールデコーダーが異なる深さ: 小 、 中 、 大 、および非常に大きい (スコープはそれぞれ16、63、125および187)がデコーダーとして使用されました。 ベースラインのLSTMは、言語をモデリングするタスク(YelpとYahooの応答のデータセット)についてはよく認識していることがわかりましたが、隠されたコードは無視しました。 一般に、パターンは目に見えます。デコーダーが小さい(そして弱い)ほど、隠れコードをより積極的に使用しますが、良い言語モデルを学ぶことは難しくなります。 最適なデコーダーは大きな畳み込み穴であることが判明し、 非常に大きなデコーダーは悪化し、コードを無視しました。
実際、これがすべて行われた理由:他のタスクで役立つ、優れた非表示のビュー(コード)が必要です。 まず、作成者はそれを2次元にし、データセット内のトピックが自動的にクラスター化される方法を示します。 次に、半教師あり学習が開始されます。著者がとんでもない数のラベル付きサンプル(100から2000)を使用して、非常にうまく(既存の方法に関して、ゼロからの学習との比較はありませんでした)、5または10クラスに分類するための教師ありモデルを教えます。
さらに、最後に、クラスラベル情報をモデルに含めることで、最終的に(VAE生成モデル!)サンプルを生成するのに役立つ小さな例があります。
追加の考え :
- 私の意見では、デコーダーはあまり強くてはいけないが、それほど強くないという結果は非常に合理的です。テキストには、隠されたコードでキャプチャしたい種類の「高レベルのアイデア」があります。 、したがって、小さなデコーダーはコードを積極的に使用しますが、そこにナンセンスを押し出す可能性があります(もちろん、この仮定は実験的な検証が必要です)。
- 条件付き生成についてはほとんど言われていません。
- 半教師ありトレーニングの結果は、同様の方法と比較して良好に見えますが、完全なマークアップを使用して同じデータセットで達成できる数値を見るのは興味深いです。
- 小さい畳み込みホールデコーダーでさえ、かなり大きなスコープを持っていました。 おそらく彼は深い能力を欠いていたので、この主題に関する実験も傷つけないだろう。
4. CNNと同じ速さでRNNをトレーニングする
彼らはSRU(Simple Recurrent Unit)をもたらしました-h_(t-1)への依存を取り除き、リカレントネットワークを並列化しました。 彼らは 、速度は5〜10倍に向上し、超精密ネットワークに匹敵するものの、品質に損失はないと書いています。 さらに、多くの場合、結果はLSTMアナログの結果よりもよく示されており、テキスト理解、言語モデリング、機械翻訳、音声認識などのかなり幅広いタスクでテストしました。
この写真の記事の要点:

別のかなり重要な結論は、機械翻訳の場合、明らかにオーバーフィットする傾向なく、10層のSRUを注入できたということです。 そして、機械翻訳では、エンコーダーとデコーダーのレイヤーは通常対称的に、つまり 実際、これらは20層のリカレントネットワークであり、これは巨大なものです。 比較のために、機械翻訳の単なる人間は4 + 4層でモデルを構築します。 Google、2016年後半-2017年初頭に、6 + 6層のトレーニングに多かれ少なかれ成功し、その時点で8 + 8層を販売したが、これらは8 GPUで16層がレイアウトされました。
PS同時に、BLEU En-> Deは、おそらくトレーニング時間が短いため、どうにかしてうまくいきませんでした。
5.自動エンコーダーの変換
→ オリジナル記事
投稿者:yane123
これは、イメージを操作するための新しいタイプのネットワークアーキテクチャです。 ヒントンとCo.は、画像の処理について話している場合、畳み込みネットワークの将来はありそうにないと考えています。 また、カプセルを優先して畳み込みを拒否すると、データの不変式のより便利な表現を取得できます。
ネットワーク内の各カプセルの目的は、観測に使用可能な変換の全範囲(変位など)で特定のエンティティを認識することを学習することです。 カプセルは、レコグナイザー、生成部分、および隠れ層で構成される小さなニューラルネットワークです。 隠されたレイヤーにあるものは、カプセルの出力値(より高いカプセルに移動する)として解釈され、次の2つの要素で構成されます。
- エンティティXが写っている可能性。 彼女は、カプセルによるXの本質の「認識度」です。
- エンティティXの特定のインスタンスの「インスタンス化パラメーター」。
カプセルの生成部分は、インスタンス化のこれらのまさにパラメータに従って排他的に生成されます。 次に、生成の結果にカプセルの信頼度を掛けます。 ゼロに等しい場合、カプセルの最終的な再構成への寄与もゼロになります。
モデルの解釈 :特定の不変式Xのすべての可能な形式が多様体に置かれている場合、カプセルの出力での「認識度」は、多様体のどの点がこのインスタンスに対応するかに依存しません。 高度な認知度は、適切な多様性を獲得するという事実についてのみ語っています。 しかし、インスタンス化のパラメーターは、すでにマニホールド内のオブジェクトの位置に依存しています。
OOPのようなものです。カプセルAが高い信頼度でアクティブ化された場合、ステージにクラスAのオブジェクトが存在する可能性が最も高いことを意味します。実際に存在すると仮定すると、カプセルAの出力はそのパラメーターになります。
最も単純なケースでは、これらのパラメーターは、2Dイメージ内のオブジェクトの座標として解釈される数値のペアにすることができます。 もう少し複雑なものでは、認識されたエンティティの「標準的な」表現に適用される変換行列にすることができます。 要するに、想像力はここに示すことができます。
これらのカプセルのトレーニングをどのように組織化して、こうした「OOP方式」での作業を開始するかという疑問が残ります。 この記事は、カプセルが画像のペアでトレーニングされるとこれが達成されることを示しています。 この場合、2番目のイメージは最初のイメージの変換(たとえば、シフト)であり、ネットワーク自体は変換に関する情報(たとえば、どこで、どれだけ移動したか)にアクセスできます。 ここでは、そのサッカードを持つ脳のように。
説明した学習方法を使用して、カプセルに制御可能な画像プロパティの表現を作成させることができます。 この記事では、カプセルを使用したいくつかの実験について説明し、獲得した専門分野を利用しています。
私の個人的な履歴書 :クール! とても。
6.動作が集合論に依存しない比較的小さなチューリングマシン
→ オリジナル記事
投稿者:kt
理論の魅力的な才能を備えた、理論計算機科学の冷酷な抽象的でかなり愚かな部門のファンのための参考記事。
この研究では、著者はチューリングマシンの構築という目標を設定しました。チューリングマシンは、Zermelo-Frankelの理論の公理が選択の公理(つまり、ZFCがすべての数学の根底にあるもの)である場合にのみ停止します。 ゲーデルのおかげで、ZFCルールを使用してZFCルールの矛盾を証明または反証することは不可能であることがわかっているため、対応するプログラムが無限に機能することを証明または反証することは不可能であり、これは一種の楽しみです。
必要なタイプの最も単純なプログラムは、ZFCから考えられるすべての結論を単純に順番にリストし、矛盾(1 = 0など)を見つけると停止するプログラムです。 ただし、チューリングマシンの形式では、このようなプログラムは複雑すぎますが、もっと簡単なものが欲しいです。 このために、著者は特にいくつかのトリックを使用しました。
フリードマンが証明したように、「任意のk、n、p、有理数のブロブ数のサブセットのグラフにはblabが含まれる」タイプの特定の「フリードマン補題」があります。 したがって、すべてのZFC定理を繰り返すのではなく、「悪い」グラフが見つかるまで、目的のタイプのすべてのグラフを繰り返すことができます。
- 良い意味で、チューリングマシンの「プログラム」はその状態であり、「テープ」は中間計算に必要です。 ただし、プログラムを状態にプッシュすると、その数がすぐに増加しますが、これは見苦しいです。 テープにプログラムコードを記述し、このコードの一種の「ユニバーサルインタープリター」を記述する状態では、より美しいです。 すなわち 合計チューリングマシンは、最初にそのコードをテープに書き込み、次にそれを実行します。 必要な状態の数に関しては、より短いことがわかります。
この美しさを実現するために、著者は2つの特別な言語を実装しました。TMDは、チューリングマシン(マシン自体をコンパイルできる)を簡単に説明するためのもので、Laconicは、TMDでコンパイルされた高級C言語のようなものです。
その結果、7918州から必要なチューリングマシンを受け取りました。 その後、彼らは苦しみ、ゴールドバッハ(4888州)とリーマン(5372州)の仮説を証明するためにチューリング機械を積み上げました。
この結果の面白い結果の1つは次のとおりです。 BB(k)を、k個の状態を持つチューリングマシンが実行できるステップの最大有限数とします(いわゆるビジービーバー関数)。 この場合、BB(7918)(およびk> = 7918のBB(k)と同様)は計算不可能な数値です(その値はZFCから証明または反証することはできません)。
7.さまざまな寿命の樹種におけるテロメア長およびテロメラーゼ活性の分析、およびイガゴヨウマツの年齢
→ オリジナル記事
投稿者:kt
私たちが知る限り、分裂中の細胞はDNA(テロメア)の一部を失い、いわゆる 細胞の老化。 一部の細胞(胚性、癌性)にはこれに対する特別なタンパク質があります-テロメラーゼはテロメアを回復し、細胞に永遠の命を与えます。
興味深い質問は、何が何百年から何千年も生きることができる一方で、成長は主に分裂組織の領域で発生するため(つまり、「胚」細胞のように)、木の中で何が起こるかです。 この記事の著者によると、2005年には植物の細胞老化の問題について特に明確なものはありませんでした(そして、私が個人的に結論付けたように、この記事はそれ以上明確になりませんでした)。
著者は、針、木材、および根から異なる年齢の6種類の木を取り、それらのテロメア長の分布とテロメラーゼ活性を測定し、これらの指標の樹種依存性のグラフ(「長命」、「中生」、「低生」)および1つの種(ある種のマツ)内の年齢。
著者は、最も長いテロメアとテロメラーゼ活性の長さは、長生きする木では平均して長いように見えたが、著者は統計的有意性を示さなかったので、特にそこにはないかもしれない(サンプルサイズは数十ポイントで測定される)。 さらに、1つの種の枠組みの中で、根のテロメアの長さは年齢とともに増加し、テロメラーゼ活性は一般に周期的です(約1000年のサイクル長)。 要するに、実際には、nifigaはテロメラーゼがまだ機能することを除いて明確ではありません。
8.途方もなく大規模なニューラルネットワーク:スパースゲートエキスパートの混合層
→ オリジナル記事
投稿者:yane123
やる気
モデルが複雑なサブジェクト領域を学習するタスクに直面している場合、モデルには多くのパラメーターが必要です。 ネットワークは大きくなければなりません。 すべての手段で大規模なネットワーク全体をアクティブ化するには費用がかかります。 その特定のセクション(条件付き計算)のみが各瞬間に機能/学習することが望ましいでしょう。
モデル
著者は、新しいタイプの層を提案しました-疎なゲートウェイの下の専門家の混合物。 結論:マネージャーとして機能し、それに従属するエキスパートのどれが現在のデータを処理するかを決定するニューラルネットワークゲートウェイがあります。 エキスパートは、単純な直接分布ニューラルネットワークです。 それらの多く(数千)がありますが、その都度、マネージャーが選択するのはほんの数個です。 ゲートウェイとエキスパートの両方は、逆伝播によって一緒に訓練されます。
出力では、ゲートウェイは長さnのベクトルを生成します。nはエキスパートの数です。 ゲートウェイアクティベーション関数-アドオンとソフトマックス:ノイズとスパースネス。 スパースネスは単純に設定されます-ベクトルkで最も明るいセルが選択され、残りは強制的にマイナス無限大に設定されます(したがって、それらのソフトマックスはゼロになります。これは、エキスパートがこのタスクを実行しなかったことを意味します)。
難しさ
難点の1つは、専門家が多いほど、各専門家が持つバッチの部分が少なくなることです。 バッチを無限に増やすことは不可能です。なぜなら、 メモリサイズは限られているため、著者は他のアプローチを探す必要がありました。
もう1つの微妙な点は、エキスパート間の負荷分散です。 実際には、ネットワークは次のように分類される傾向があることが判明しました。 st迷 定常状態。ゲートウェイは常に同じ専門家を選択し、他の専門家は学習する機会がありません。 著者は、この動作に対するいくつかのペナルティをコスト関数に追加することで問題を解決しました。 各エキスパートについて、このバッチを計算するときに、ゲートウェイによってどれだけ主張されているかが計算されました。 罰金は、すべての専門家に平等な需要を押し付けます。 付録は、滑らかな罰金の構築に専念しています。
もう1つのポイント:スケールの初期化。 ソフトの制限(専門家による不均等なワークロードに対する前述のペナルティなど)はすぐには機能しません。「同じを選択」モードでネットワークが即座に停止しないようにする最も簡単な方法は、ゲートウェイの重みを同じ方法で初期化することです。
結果
テキスト(10億語のベンチマークと機械翻訳)を扱うタスクのテストが行われました。 彼らはそれが最良の方法に匹敵するように機能すると言います。
9.事前の意識
→ オリジナル記事
投稿者:asobolev
- 4 RL- / (disentangled) , conscious ( 41 ! ! , !)
, .. , (, ), .. (conscious state), (sparse attention) , , . , , (, , , ).
, s_t
( RL) RNN' ( ), h_t
— , .
, c_t
: C(h_t, c_{t-1}, z_t)
, h_t
, c_{t-1}
, (exploration).
, - . , , , t
- c_t
, k
h_{t+k}
. V(h_t, c_{tk})
, . , — .
( 100+ ?), , .
yuli_semenovaを編集していただきありがとうございます。