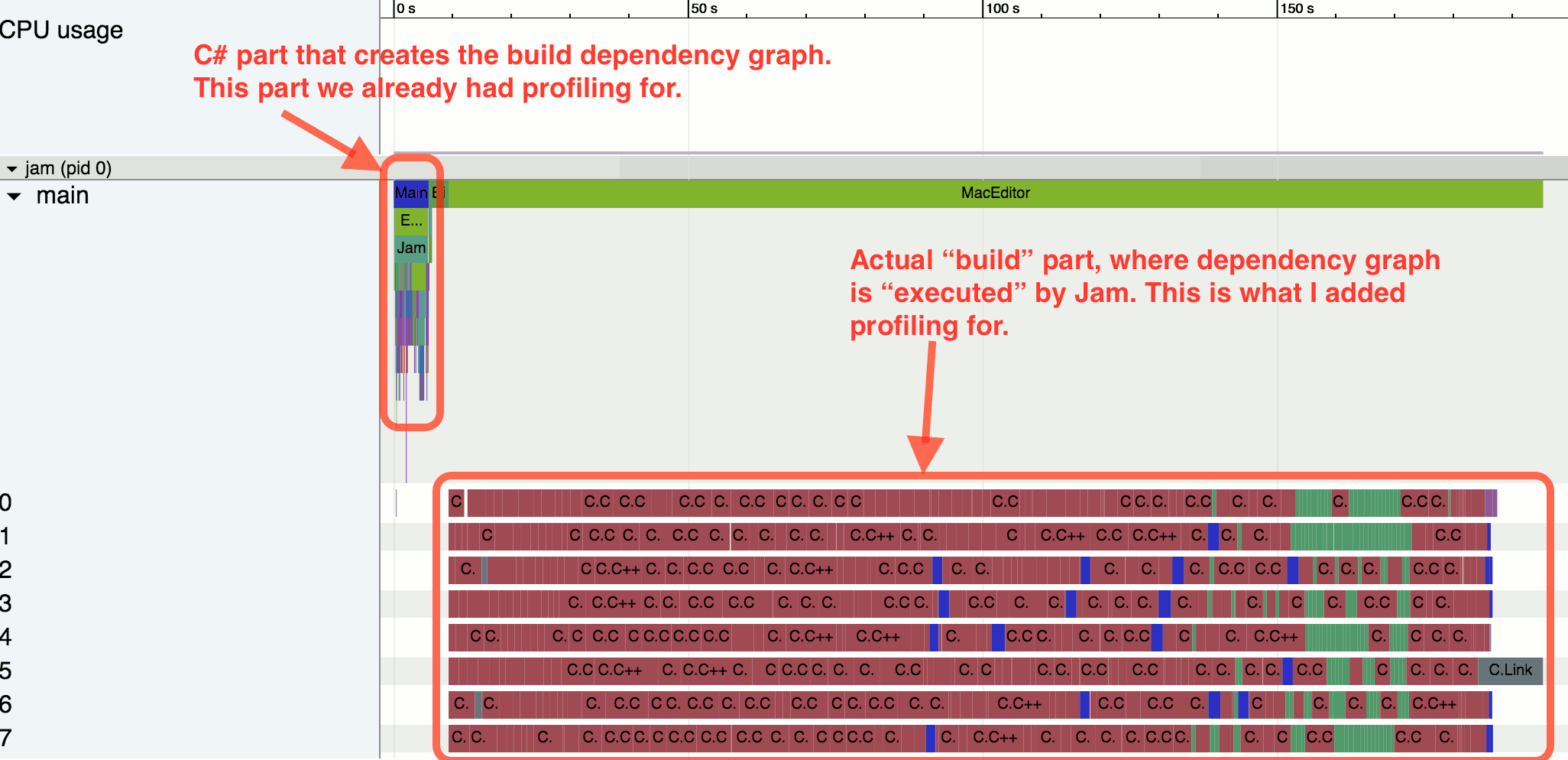
ここには目立ったものは何もありません。 しかし...最初のプロファイリング結果が得られるとすぐに、彼らはしばしばあなたに考えさせ、何かに気づき始めます。
見たもの
この記事のトピックとは無関係なことをしていたとき、何らかの理由で、製品の新しくビルドされたビルドのプロファイラーの出力を見ました。 経験上、C ++コードの構築には、リンクが時間の大部分を占めることが示唆されています。 ただし、今回はそうではありませんでした。

この図は、リンク手順の前の大きな遅延を示しています。 ほとんどのコードはすでにコンパイルされており、C ++コードを含む1つのファイルのみがコンパイルされ続けます。 それから私は別のタスクで忙しかったので、タスクボードでそれを把握するためにタスクを追加しました。 もう一度、製品の別のコンポーネントのビルドをビルドし、アセンブリプロファイラーの出力を再度確認しました。
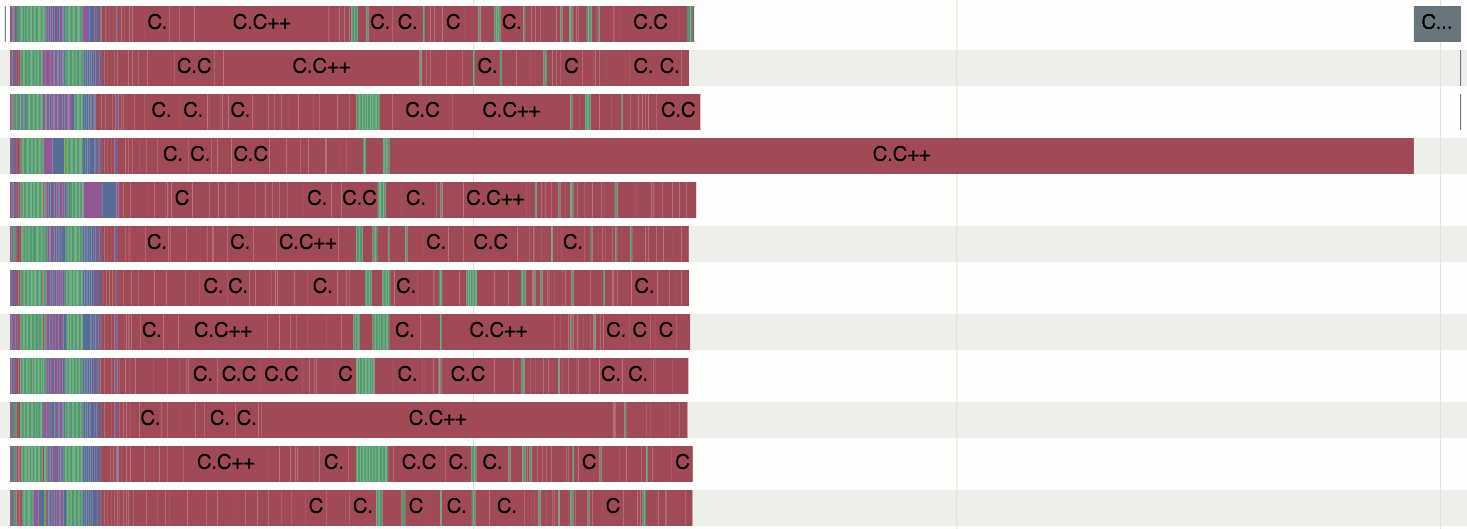
そして、ここで物事はすでに率直に悪い見えた。 合計ビルド時間は約10分で、そのうちの約7つは1つのファイルのみをコンパイルするのにかかりました(そのうち5つはコンパイルされていません)。 この時点で、問題はもはや無視または延期できないスケールのアセンブリシステムにあることが明らかになりました。
このプロジェクトおよびこの構成でのC ++ファイルの平均コンパイル時間は約2秒でした。 30秒間収集されたファイルがいくつかありましたが、アセンブリの400秒以上はすべての妥当な制限を超えました。 何が起こっているの?
私はいくつかの実験を行い、次のことを発見しました:
- ユニティビルドの原理に基づいて構築されたアセンブリシステムは、何が起こっているのかという原因ではありませんでした。 それはすべて1つの特定のcppファイルに関するものでした。
- この動作はMSVCコンパイラーによって明確に示されました(clangは10倍高速でした)が、その後MSVCが必要になりました
- 問題はリリースアセンブリ(またはインライン化が有効になっているアセンブリ)のみに関するものです。
- 問題は、比較的古いVS2010コンパイラだけではありません。 VS2015でのコンパイルはさらに遅かった
- コンパイルに30秒以上かかったすべてのファイルの共通点は、「数学的なSIMDライブラリ」の使用でした。これにより、HLSLスタイルでコードを記述できるようになりました。 実装は、非常に複雑なマクロとパターンに基づいていました。
- コンパイルに7分かかった同じファイルには、非常に大きく複雑なSIMD関数が含まれていました。また、コンパイル段階でテンプレートを使用していくつかの型付き実装を作成する必要がありました(したがって、実行時のオーバーヘッドを取り除きました。アプローチは理にかなっています)
私たちのアプローチが理想的であったかどうかは別の質問ですが、それはそれをあきらめないで十分な利点を与えました。 しかし、それでもコンパイル速度で何かをしなければなりませんでした。
コンパイルの高速化
ビルドシステムに完全に依存していた1つの単純な変更は、Unityビルドからゆっくりコンパイルされたファイルを除外することでした。 全体のポイントは、コンパイラプロセスの開始と共通ヘッダーファイルの前処理を少し節約することです。 ただし、コンパイルに30秒以上かかる複数のファイルの場合、このゲインは最小限に抑えられますが、アセンブリファイルの最後に「スタック」が生じるため、アセンブリごとに数分待つ必要があります。
ビルドシステムができる限り早く「遅い」ファイルのコンパイルを開始するようにするとよいでしょう。 早く始めましょう-早く終わります。 理想的なオプションは、以前のアセンブリの履歴データの分析とそれらに基づくコンパイルキューの自動構築をアセンブリシステムに固定することです。 しかし、この特定のケースではこれは必要ありませんでした。ビルドシステムのユニティビルドからファイルを除外するだけで、キューの先頭に移動しました。 さて、これでこれで十分です。
このトリックは実際にその「悪い」ファイルの7分間のビルドを1秒間高速化しませんでしたが、それは簡単で、ビルド全体ですぐに約1分間の合計勝利をもたらしました(その前に10分かかりました)。
そしてその後、私は実際にはまったく期待していなかった何かをしました-その「遅い」ファイルの最大のテンプレート関数をいくつかの小さなものに分割しました(その一部はもはやテンプレートではありませんでした)。 些細なリファクタリング。 一部のIDEは、「コードのマウス部分で選択、右クリック、関数の抽出」モードでそのようなことを実行できます。 さて、これは単なるC ++であり、コードには多くのマクロとテンプレートが含まれていたため、すべてを手動で行う必要がありました。
約5つの関数を割り当てた後、問題ファイルのコンパイル時間は420秒から70秒に減少しました。6倍速くなりました!
もちろん、関数の割り当ては、それらがインラインコードではなくなったことを意味し、それらを呼び出すコスト(引数を渡す、ジャンプ、リターン)があります。 同時に、このアプローチでは、呼び出し側の関数がレジスタを使用する(より良いまたはより悪い)こと、コードの総量を減らすことなどが可能です。 異なるプラットフォームで変更されたコードの速度を測定し、パフォーマンスの変更は重要ではないという結論に達しました。 今回はうまくいきました!
もちろん、単一のファイルをコンパイルするのにまだ時間がかかります。 しかし、さらにコンパイルを高速化しようとすると、数学ライブラリの設計に大きな変更が必要になります。 これには、より綿密な計画が必要でした。
変更後のアセンブリはすでに見栄えが良くなっています。 それらの1つでコンパイルプロセスを完了するのを待機しているプロセッサコアのヒープはありません。 リンクはまだ一貫していますが、これはニュースではありません。 合計ビルド時間は10分から5分10秒に減少しました。 ほぼ2倍高速になりました。
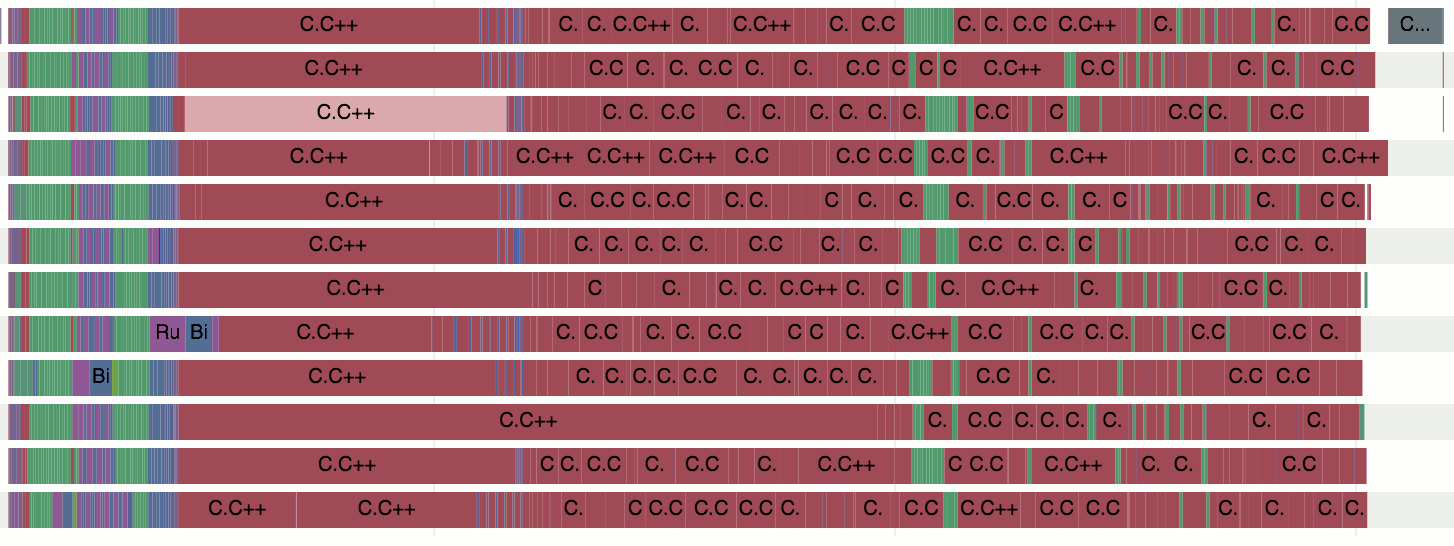
道徳
- プロジェクトを構築するために、少なくとも何らかのプロファイリングシステムを持つことは、まったく持たないよりも優れています。 そのようなシステムがなければ、プロジェクトの各ビルド(ビルドサーバー上だけでなく、開発者のマシン上でも)で5分を失っていたでしょう。
- テンプレート関数がコンパイルされると、その型付き表現のN個が作成されます。 また、各ビューは個別のコードであり、最初に自動的に生成されてからコンパイルされます。 同時に、使用されるタイプに応じて、このようなコードの異なるバージョンに対して、コンパイラーはさまざまな最適化を適用することもできます。 大きなテンプレート関数を小さなテンプレート関数(テンプレートではない場合もある)に分割すると、実際にコンパイルを高速化できます。
- オプティマイザの動作が長すぎるため、複雑なテンプレート関数は長時間コンパイルできます。 たとえば、MSVCコンパイラはほとんどの時間をそれだけに費やします。
- ビルドの高速化は良いことです。 まあ、その漫画を覚えておいてください-「ねえ、どこに行くの?-コードはコンパイル中です!」。 これが人生で起こることが少ないほど良い。