
さまざまなサービスを提供するモバイルオペレーターは、膨大な量の統計データを蓄積します。 私は、オペレーターの操作中に1日に数百ギガバイトの統計情報を生成する加入者トラフィック管理システムを実装する部門を代表しています。 私は、これらのビッグデータで最大限の有用な情報を明らかにする方法という質問に興味がありました。 ビッグデータの定義におけるVの1つが追加の収入であることは、何もありません。
データマイニングの専門家ではなく、この仕事を引き受けました。 すぐに多くの疑問が生じました。分析にはどのような技術的手段を使用する必要がありますか? 数学、統計を知るにはどのレベルで十分ですか? どの機械学習方法を知っておく必要がありますか? それとも、RデータまたはPythonデータを研究するための専門的な言語を学び始めたほうがよいでしょうか?
私の経験が示しているように、データ調査の初期レベルではそれほど必要ありません。 ただし、簡単に説明するために、データを調査するための完全なアルゴリズムを明確に示す簡単な例はありませんでした。 この記事では、 アイリスフィッシャーの例を使用して、最初のトレーニングを最後まで行い、通信事業者の実際のデータに理解を適用します。 既にデータマイニングに精通している読者は、Telecomの章にスキップできます。
規約
はじめに、研究のテーマに取り組みましょう。 現在、人工知能、機械学習、深層機械学習という用語は同義語としてよく使用されますが、実際には明確に定義された階層があります。
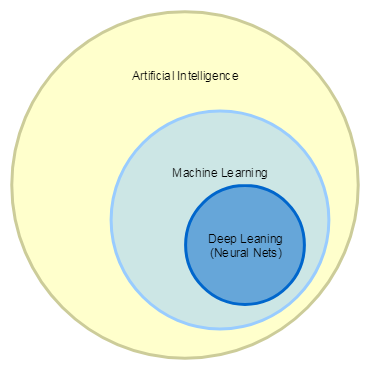
- 人工知能には、チェッカーやチェスをプレイするなど、機械が知的タスクを実行するすべてのタスク、スピーチを認識して質問に答えることができるヘルパー、さまざまなロボットが含まれます。
- 機械学習はより狭い概念であり、コンピューターが特定のアクションを実行するように訓練されているタスクのクラスに属します。たとえば、属性のセットに従ってオブジェクトを分類したり、音楽や映画を推奨したりする正しい答えがあります。
- ディープラーニングとは、パターン認識やテキスト翻訳など、ニューラルネットワークとビッグデータを使用して解決されるタスクを意味します。
この記事では、機械学習について説明します。 学習の2つの方法を区別します。
- 先生と
- 先生なし
教師の場合、これは正しい答えのデータがあるときです。 次に、このデータセットでアルゴリズムをトレーニングし、予測に適用できます。 これらのアルゴリズムには、分類と回帰が含まれます。 分類とは、一連の特性に従って特定のクラスにオブジェクトを割り当てることです。 たとえば、車の番号の認識、または医学における認識、病気の診断、または銀行部門でのクレジットスコアリング。 回帰は、株価などの重要な変数の予測です。
教師(自己学習)がなければ、データに隠されたパターンを検索します。 このようなアルゴリズムには、クラスタリングが含まれます。 たとえば、すべての主要な小売チェーンは、顧客の購入パターンを探し、一般的な大衆ではなく、顧客のターゲットグループと連携しようとします。
回帰、分類、クラスタリングは、データ調査の主要なアルゴリズムであるため、それらを検討します。
データマイニング
データマイニングアルゴリズムは、特定の一連の手順で構成されています。 タスクと使用可能なデータに応じて、一連のステップは異なる場合がありますが、一般的な方向は常に決定されます。
- データの収集と精製。 実践が示すように、この段階ではデータ分析全体の最大90%を占める可能性があります。
- データ、その分布、統計の視覚的分析;
- 変数(機能)間の関係(相関)の分析。
- モデルの構築に使用される機能の選択と定義。
- トレーニングモデルとテストモデルのデータへの分離。
- トレーニングデータのモデルの構築/テストデータの結果の評価。
- 得られたモデルの解釈、結果の視覚化。
アルゴリズムを把握し、分析にどのツールを使用する必要がありますか? ExcelからMathLabなどの専用ツールまで、多数のツールがあります。 Pythonを特殊なライブラリとともに使用します。 困難を恐れる必要はありません、すべてが簡単です:
- Anacondaという1つのディストリビューションでPythonとすべての数学パッケージをダウンロードします
- Linuxでインストールしても問題は発生しません: bash Anaconda2-4.4.0-Linux-x86_64.sh
- 実行: jupyterノートブック
- これにより、ブラウザが自動的に開きます。

- アプリケーションが機能していることを確認します: 「HelloWorld!」を印刷します
- Ctrl + Enterを押して、すべてが正常であることを確認します。
インターネット上のIPython Notebookでの自習については、たとえば、簡単な紹介: Ipython Notebook 2.0の概要など、多くの情報があります。
そして、私たちは研究を始めています!
データの収集と精製
Irisの例では、すべてのデータが収集され、入力されました。 それらをロードして見るだけです:
# : import numpy as np import pandas as pd from sklearn import datasets from sklearn import linear_model from sklearn.cluster import KMeans from sklearn import cross_validation from sklearn import metrics from pandas import DataFrame %pylab inline
次:
# : iris = datasets.load_iris() # print iris.feature_names # , 10 : print iris.data[:10] # : print iris.target_names print iris.target

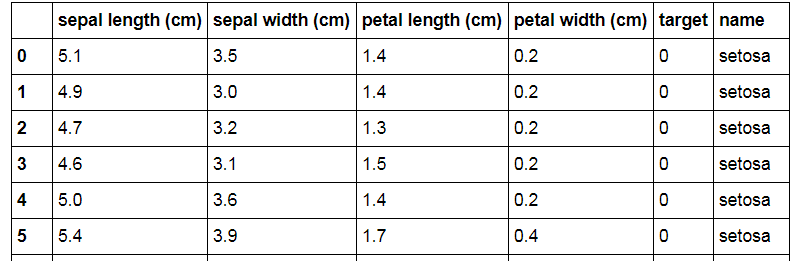
データセットは、2種類のアイリスの花びらの長さ/幅で構成されていることがわかります。がく片と花びらです。 彼らがアイリスの出身だと聞かないでください)。 ターゲット変数はアイリス品種です:0-Setosa、1-Versicolor、2-Virginica。 したがって、私たちのタスクは、利用可能なデータに基づいて、花びらのサイズとアイリスの品種との関係を見つけることです。
データを操作するために、それらからDataFrameを作成します。
iris_frame = DataFrame(iris.data) # , : iris_frame.columns = iris.feature_names # : iris_frame['target'] = iris.target # : iris_frame['name'] = iris_frame.target.apply(lambda x : iris.target_names[x]) # , : iris_frame
彼らが望んでいたことを解決するように見えた:
記述統計
# : pyplot.figure(figsize(20, 24)) plot_number = 0 for feature_name in iris['feature_names']: for target_name in iris['target_names']: plot_number += 1 pyplot.subplot(4, 3, plot_number) pyplot.hist(iris_frame[iris_frame.name == target_name][feature_name]) pyplot.title(target_name) pyplot.xlabel('cm') pyplot.ylabel(feature_name[:-4])

このようなヒストグラムを見ると、経験豊富な研究者はすぐに最初の結論を導き出すことができます。 一部の変数の分布が正常であるように見えるだけです。 もっと明確にしようとしましょう。 Irisの種類に応じて、符号間の依存関係とテーブルに色を付けるテーブルを作成します。
import seaborn as sns sns.pairplot(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)','name']], hue = 'name')

ここでは、経験の浅い研究者でも、「花びらの幅(cm)」と「花びらの長さ(cm)」に強い依存関係があることがわかります。同じ線に沿って点が伸びています。 そして、原則として、同じ特性に基づいて、分類を構築することが可能です。 ドットは非常にコンパクトに色別にグループ化されます。 しかし、たとえば、変数「sepal width(cm)」および「sepal length(cm)」を使用すると、定性的な分類を構築できません。 VersicolorとVirginicaの品種に関連するポイントは混在しています。
変数間の依存関係
次に、依存関係の数学的な値を見てみましょう。
iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']].corr()

より視覚的な形で、標識の依存性のヒートマップを作成します。
import seaborn as sns corr = iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']].corr() mask = np.zeros_like(corr) mask[np.triu_indices_from(mask)] = True with sns.axes_style("white"): ax = sns.heatmap(corr, mask=mask, square=True, cbar=False, annot=True, linewidths=.5
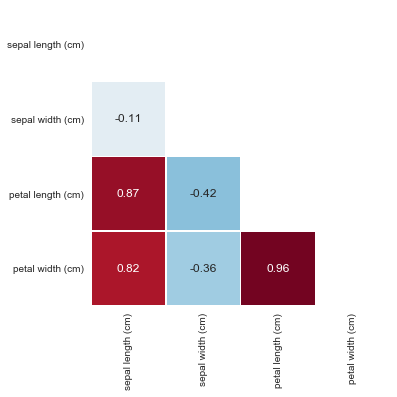
相関係数の値は次のように解釈されます。
- 最大0.2-非常に弱い相関
- 最大0.5-弱い
- 最大0.7-平均
- 0.9まで-高
- 0.9以上-非常に高い
実際、変数「花びらの長さ(cm)」と「花びらの幅(cm)」の間には、0.96という非常に強い依存性が明らかになっています。
サインを選択して作成します
最初の近似では、すべての変数をモデルに含めるだけで、何が起こるかを確認できます。 その後、削除するサインと作成するサインを考えることが可能になります。
トレーニングおよびテストデータ
データをトレーニング用データとテストデータに分割します。 通常、サンプルは66 / 33、70 / 30、または80/20の割合でトレーニングとテストに分けられます。 データに応じて、他のパーティションが可能です。 この例では、サンプル全体の30%をテストデータに割り当てます(パラメーターtest_size = 0.3):
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame['target'], test_size = 0.3, random_state = 0) # , : print train_data print test_data print train_labels print test_labels
モデル構築サイクル-結果の評価
最も興味深いものに渡します。
線形回帰-LinearRegression
線形回帰を視覚化する方法は? 2つの変数間の関係を見ると、線から点までの垂直距離が全体的に最小になるように線を引いています。 最も一般的な最適化方法は、勾配降下アルゴリズムにより標準誤差を最小化することです。 勾配降下については、たとえば「勾配降下とは」セクションで説明されています。 しかし、線形回帰をオブジェクトの分布の方向に最も近い線を見つけるための抽象的なアルゴリズムとして読んで知覚することはできません。 前に理解したように、強い依存関係を持つ変数を使用してモデルを構築します。これらは「花弁の長さ(cm)」と「花弁の幅(cm)」です。
from scipy import polyval, stats fit_output = stats.linregress(iris_frame[['petal length (cm)','petal width (cm)']]) slope, intercept, r_value, p_value, slope_std_error = fit_output print(slope, intercept, r_value, p_value, slope_std_error)
モデルの品質指標を確認します。
(0.41641913228540123、-0.3665140452167277、0.96275709705096657、5.7766609884916033e-86、0.009612539319328553)
最も興味深いのは、値が0.96275709705096657のr_value変数間の相関係数です。 私たちはすでにそれを見てきましたが、ここで再びその存在を確信しています。 点と回帰直線でグラフを描く:
import matplotlib.pyplot as plt plt.plot(iris_frame[['petal length (cm)']], iris_frame[['petal width (cm)']],'o', label='Data') plt.plot(iris_frame[['petal length (cm)']], intercept + slope*iris_frame[['petal length (cm)']], 'r', linewidth=3, label='Linear regression line') plt.ylabel('petal width (cm)') plt.xlabel('petal length (cm)') plt.legend() plt.show()

実際、見つかった回帰直線は点の分布の方向をよく繰り返していることがわかります。 現在、たとえば五角形のリーフレットの長さを入手できる場合は、幅を正確に決定できます!
分類
分類を直感的に表現する方法は? 2つの特性を持つオブジェクトの2つのクラスに分割する問題を見ると(たとえば、サイズがわかっている場合はリンゴとバナナを分離する必要があります)、分類はオブジェクトを2つのクラスに分割する平面上に線を引くことになります。 より多くのクラスに分割する必要がある場合は、複数の線が描画されます。 3つの変数を持つオブジェクトを見ると、3次元空間と平面の描画タスクが表示されます。 変数がNの場合、N次元空間の超平面を想像するだけです。
そこで、最も有名な分類訓練アルゴリズムである確率的勾配降下法を採用します。 すでに線形回帰で勾配降下に遭遇していますが、確率降下は、作業の速度については、すべてのサンプルが使用されるのではなく、ランダムデータが使用されることを示しています。 そして、それをSVM(サポートベクターマシン)分類方法に適用します。
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame[['target']], test_size = 0.3, random_state = 0) model = linear_model.SGDClassifier(alpha=0.001, n_iter=100, random_state = 0) model.fit(train_data, train_labels) model_predictions = model.predict(test_data) print metrics.accuracy_score(test_labels, model_predictions) print metrics.classification_report(test_labels, model_predictions)
モデルの品質指標を確認します。

実際、メトリックの値の本質を実際に理解することなくモデルを評価できます。精度、精度、再現率が0.85を超える場合、これは良いモデルであり、0.95を超える場合は優れたモデルになります。
要するに、この例で使用されているメトリックは以下を反映しています。
- 精度は、正しいモデル応答の割合を示す主要なメトリックです。 その値は、モデルがすべてのオブジェクトの数に与えた正解の数の比率に等しくなります。 ただし、モデルの品質を完全には反映していません。 したがって、精度と再現率が導入されます。
これらのメトリックは、各クラスの認識品質(虹彩の種類)と合計値の両方の観点から与えられます。 合計値を確認します。
- 精度-このメトリックは、モデルをどれだけ信頼できるか、つまり、「偽陽性」がいくつあるかを示します。 メトリック値は、モデルが正しいと見なす回答の数と、「正しい」とモデルが正しいと見なしたオブジェクトの数の合計(この数値は「true positive」で示されます)の比率に等しいが、実際は正しくなかった(この数値「誤検知」で示されます)。 式の形式:precision =“ true positives” /(“ true positives” +“ false positives”)
- 想起(完全性)-このメトリックは、モデルが一般的に正しい答えをどれだけ検出できるか、つまり、「偽のパス」がいくつあるかを示します。 その数値は、モデルが正しいとみなす回答の比率に等しく、サンプル内のすべての正しい回答の数に対して実際に正しいものでした。 式の形式で:リコール=「真の陽性」/「すべての陽性」
- f1-score(f-measure)は精度とリコールの結合です
- サポート-クラスで見つかったオブジェクトの数だけ
また、重要なモデルメトリック:PR-AUCおよびROC-AUCがあります。たとえば、ここで見つけることができます: 機械学習問題のメトリック 。
したがって、この例のメトリック値は非常に優れていることがわかります。 チャートを見てみましょう。 わかりやすくするために、サンプルを2つの座標で描画し、クラスごとに色付けします。
まず、テストサンプルをそのまま表示します。

次に、モデルが予測したように。 境界上のポイント(赤で囲んだ部分)が誤って分類されていることがわかります。
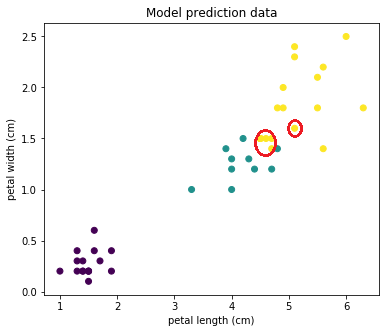
しかし同時に、ほとんどのオブジェクトは正しく予測されています!
相互検証
どういうわけか非常に疑わしい良い結果...何が間違っているのでしょうか? たとえば、誤ってデータをトレーニングサンプルとテストサンプルに分割しました。 このランダム性を除去するために、いわゆる交差検証が使用されます。 これは、データがトレーニングサンプルとテストサンプルに数回分割され、アルゴリズムの結果が平均化される場合です。
10個のランダムサンプルでアルゴリズムの動作を確認しましょう。
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame['target'], test_size = 0.3) model = linear_model.SGDClassifier(alpha=0.001, n_iter=100, random_state = 0) scores = cross_validation.cross_val_score(model, train_data, train_labels, cv=10) print scores.mean()
結果を見ます。 予想通り悪化しました: 0.860909090909
最適なアルゴリズムパラメーターの選択
アルゴリズムを最適化するために他に何ができますか? アルゴリズム自体のパラメーターを選択してみてください。 alpha = 0.001、n_iter = 100がアルゴリズムに転送されることがわかります。 それらに最適な値を見つけましょう。
from sklearn import grid_search train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame['target'], test_size = 0.3) parameters_grid = { 'n_iter' : range(5,100), 'alpha' : np.linspace(0.0001, 0.001, num = 10), } classifier = linear_model.SGDClassifier(random_state = 0) cv = cross_validation.StratifiedShuffleSplit(train_labels, n_iter = 10, test_size = 0.3, random_state = 0) grid_cv = grid_search.GridSearchCV(classifier, parameters_grid, scoring = 'accuracy', cv = cv)grid_cv.fit(train_data, train_labels) print grid_cv.best_estimator_
出力では、最適なパラメーターを持つモデルを取得します。
SGDClassifier(alpha = 0.00089999999999999998、average = False、class_weight = None、
イプシロン= 0.1、eta0 = 0.0、fit_intercept = True、l1_ratio = 0.15、
learning_rate = '最適'、loss = 'hinge'、n_iter = 96、n_jobs = 1
ペナルティ= 'l2'、power_t = 0.5、random_state = 0、shuffle = True、verbose = 0、
warm_start = False)
アルファ= 0.0009、n_iter = 96であることがわかります。 モデルでこれらの値を置き換えます。
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame['target'], test_size = 0.3) model = linear_model.SGDClassifier(alpha=0.0009, n_iter=96, random_state = 0) scores = cross_validation.cross_val_score(model, train_data, train_labels, cv=10) print scores.mean()
少し良くなりました: 0.915505050505
サインを選択して作成します
兆候を試す時間です。 モデルからあまり重要でない特徴、つまり「sepal length(cm)」と「sepal width(cm)」を削除しましょう。 モデルに進みます:
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['petal length (cm)','petal width (cm)']], iris_frame['target'], test_size = 0.3) model = linear_model.SGDClassifier(alpha=0.0009, n_iter=96, random_state = 0) scores = cross_validation.cross_val_score(model, train_data, train_labels, cv=10) print scores.mean()
少し良くなりました: 0.937727272727
アプローチを説明するために、新しいサインを作成しましょう。花びらの葉の領域と何が起こるかを見てみましょう。
iris_frame['petal_area'] = 0.0 for k in range(0,150): iris_frame['petal_area'][k] = iris_frame['petal length (cm)'][k] * iris_frame['petal width (cm)'][k]
モデルの代替:
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['petal_area']], iris_frame['target'], test_size = 0.3) model = linear_model.SGDClassifier(alpha=0.0009, n_iter=96, random_state = 0) scores = cross_validation.cross_val_score(model, train_data, train_labels, cv=10) print scores.mean()
おもしろいですが、この例では、花びらの花びらの面積(または、花びらが長方形ではなく「幅による長さの積」であるため、面積でさえない)がアイリスの多様性を最も正確に予測することがわかります: 0.942373737374
おそらくこれは、変数「花びらの長さ(cm)」と「花びらの幅(cm)」がアイリスをクラスに非常にうまく分割し、その製品がクラスを線に沿って「引き伸ばす」という事実によって説明できます。

モデル最適化の主な方法に精通しました。今度は、クラスタリングアルゴリズム(教師なしの機械学習の例)を検討します。
クラスタリング-K-means
クラスタリングの本質は非常に簡単です-既存のオブジェクトをグループに分割して、類似したオブジェクトがグループに含まれるようにする必要があります。 現在、モデルをトレーニングするための正しい答えがありません。そのため、アルゴリズム自体は、オブジェクトの場所の「近接度」に従ってオブジェクトをグループ化する必要があります。
たとえば、最も有名なK-meansアルゴリズムを考えてみましょう。 K-meansと呼ばれるものは何もありません。 この方法は、クラスターのK中心を見つけることに基づいているため、クラスターからそれらが属するオブジェクトまでの平均距離は最小になります。 最初に、アルゴリズムはK個の任意の中心を決定し、次にすべてのオブジェクトがこれらの中心に近接して分散されます。 オブジェクトのK個のクラスターを取得しました。 さらに、これらのクラスタでは、オブジェクトまでの平均距離に応じて中心が再計算され、オブジェクトが再配布されます。 このアルゴリズムは、クラスターの中心が特定のデルタだけシフトしなくなるまで機能します。
train_data, test_data, train_labels, test_labels = cross_validation.train_test_split(iris_frame[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']], iris_frame[['target']], test_size = 0.3) model = KMeans(n_clusters=3) model.fit(train_data) model_predictions = model.predict(test_data) print metrics.accuracy_score(test_labels, model_predictions) print metrics.classification_report(test_labels, model_predictions)
結果を確認します。

デフォルトのパラメーターを使用しても、非常に良好であることがわかります。精度、精度、再現率は0.9を超えています。 写真で確認してください。 適切な結果が表示されますが、常に正確な結果ではありません。


アルゴリズムには欠点があります-その操作のために、検索するクラスターの数を指定する必要があります。 そして、それが不十分な場合、アルゴリズムの結果は役に立たなくなります。 クラスターの数、たとえば5を設定するとどうなるか見てみましょう。
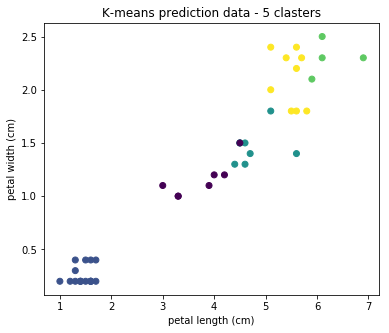
実際には、結果は適用されないことがわかります。 最適なクラスター数を決定するためのアルゴリズムが存在しますが、この記事ではそれらについて詳しく説明しません。
アイリスの研究に関する結論
そこで、Irisovの例を使用して、機械学習の3つの主要な方法である回帰、分類、クラスタリングを検証しました。 アルゴリズムの最適化と結果の視覚化を実施しました。 非常に良い結果が得られましたが、これは特別に準備されたデータセットで期待されていました。
完全なPythonノートブックはGithubにあります。 Telecomに渡します。
テレコム
Telecomには、データ分析の助けを借りて、他の分野(銀行、保険、小売)で解決できるタスクがあります。
- 加入者の流出の予測(Churn Prevention);
- 不正防止
- 類似のサブスクライバーの識別(サブスクライバーベースセグメンテーション);
- クロスセリング(クロスセール)および販売量の引き上げ(アップセール);
- 環境に強く影響するサブスクライバー(Alphaサブスクライバー)の識別。
- 加入者によるネットワークリソースの消費の予測:トラフィック量、通話数、SMS;
- ネットワークを最適化するための加入者の動きの調査。
- 課金システムは、加入者の支払いと費用、関税、個人データに関するデータを保存します。
- 加入者が訪れたサイトに関するデータは、 DPI機器から抽出されました。
- ベースステーションから、加入者の位置を含むジオデータを取得できます。
- サービス機器は、加入者による通信サービスの消費に関するデータを生成します。
私の目標は、加入者トラフィック管理システムが生成するデータを使用して解決できるタスクを決定することでした。 課金システムが加入者のトラフィックを正しく評価するには、誰が/どこで/いつ/どのタイプのトラフィック量を消費したかを知る必要があります。 この情報は、いわゆるCDR(Call Data Record)ファイルの形式で機器から取得されます。 IMSIおよびMSISDN加入者識別子、CELL ID基地局の正確な位置、 IMEI加入者機器識別子、セッションタイムスタンプ、および消費されたサービスに関する情報は、csv形式でこれらのファイルに書き込まれます。
機密性を維持するために、すべての研究データは非個人化され、形式に準拠したランダムな値に置き換えられました。 データを見てみましょう:

このデータにどの機械学習アルゴリズムを適用できますか? たとえば、一定期間のサブスクライバによるさまざまなタイプのトラフィックの消費を集計し、クラスタリングを実行できます。 次のようなものが得られるはずです。
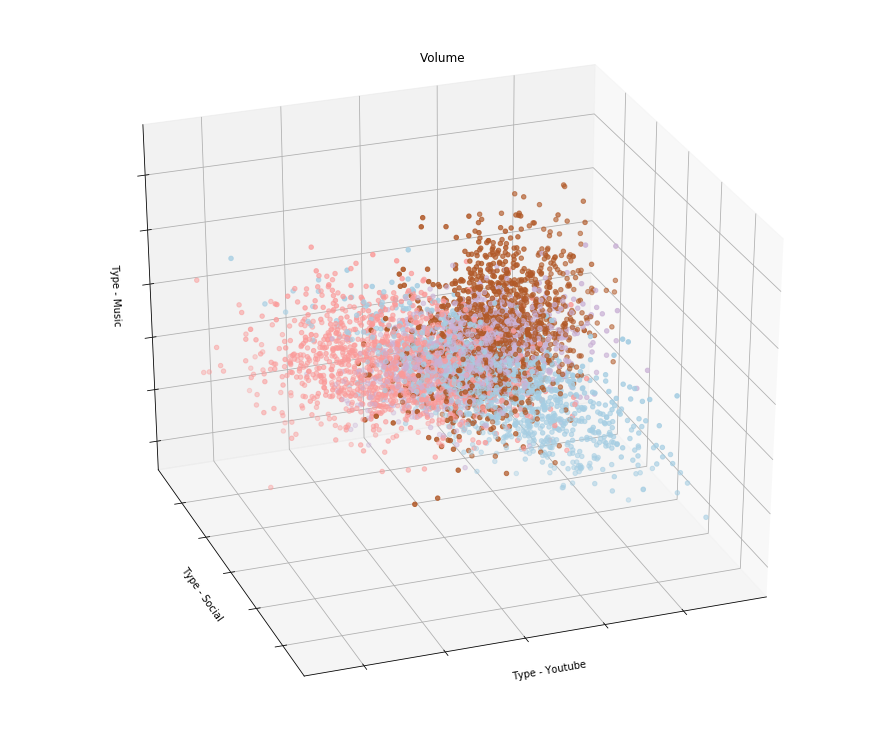
すなわち たとえば、クラスタリングの結果、サブスクライバーがさまざまな方法でYouTubeを使用するグループ、ソーシャルネットワーク、音楽を聴くグループに分割されていることが示された場合、関心を考慮した料金を設定できます。 通信事業者は、トラフィックのタイプごとに支払いを区別して料金表を発行することでこれを行っていると思います。
利用可能なデータで他に何を分析できますか? 加入者の機器にはいくつかのケースがあります。 オペレーターは、加入者のデバイスのモデルを知っており、たとえば、特定のサービスをSamsungユーザーのみに提供できます。 または、ベースステーションの座標がわかっている場合は、Samsung携帯電話の分布のヒートマップを描画できます(実際の座標はないため、 マップは現実に関連していません)。
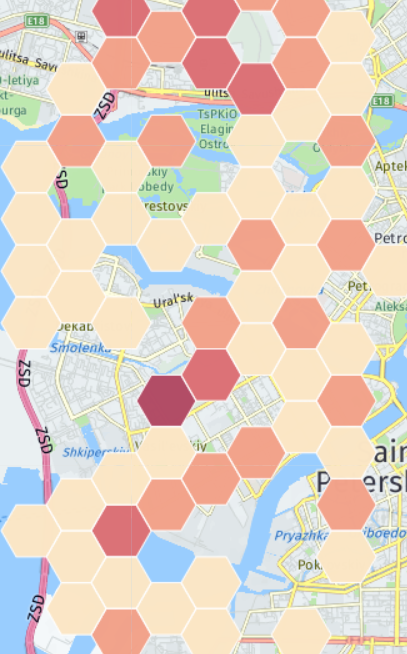
特定の地域では、他の地域よりもパーセンテージが高くなることがあります。 その後、この情報をサムスンに提供して、プロモーションを実施したり、スマートフォンの販売のためのサロンを開いたりすることができます。 次に、加入者がインターネットにアクセスするデバイスの上位モデルを確認できます。

現在の状況を隠すために、時代遅れのIMEIデータベースが採用されましたが、これはアプローチの本質を変えません。 リストは、ほとんどのデバイスがApple、モデム、Samsungであり、Meizu、Micromax、Xiaomiが最後に表示されることを示しています。
実際、これらはすべて、短期間で見つけることができるソースデータのアプリケーションです。 もちろん、これらのデータによると、さまざまな統計や時系列を調べたり、排出量を分析したりすることができますが、機械学習を使用して依存関係を明らかにするために...残念ながら、私はまだこれを行う方法を見つけていません。
したがって、テレコムのデータ調査に関する結論は次のとおりです。テレコムオペレータのタスクに対する完全なソリューションには、利用可能なすべての情報システムからのデータが必要です。すべてのデータにアクセスできるだけで、モデルのコストを効果的に削減できます。
一般的な結論
- 初期データ分析では、魔法はありません。すべては、直感的なレベルで理解および適用できるいくつかの単純なアルゴリズムに基づいています。
- しかし、もちろん、統計、機械学習、プログラミングアルゴリズムの経験と深い知識によってのみ解決できる複雑なタスクが残っています。