
Wi-Fiが地下鉄の最初の路線に最初に登場したとき、私たちはグラウンドホッグデイからヒーローのビルマレーに変身していることに気付きました。 唯一の違いは、彼が2月2日に毎朝目を覚まし、少なくとも1行の列車をキャッチして同じ構成で満たそうとすることでした。 手動で設定するのは悪い考えでした-列車はデポに向けて出発し、数日間そこに立ちました。
医師、これは治療されていますか?
自動ツールがなければ、会社全体が問題のある列車を捕まえて構成を入力するだけでよいことに気付きました。 ほとんどの機器はシスコ製であり、最初に既存のベンダーソリューションを探していました。 Cisco Primeシステムを設定しようとしましたが、いくつかの理由でそれを放棄しました。
1)弊社のような機器の数量に対する高価なライセンス-1万台以上。
2)列車に設置されたRADWIN機器はサポートされていません。
3)ネットワークの詳細に関連する標準的な問題 。
他のオプションを試しましたが、2014年8月に1つの政府決定が発行され、その後、アプローチを変更する必要がありました。 必須の識別システムを実行するには、列車のコントローラーを完全に再構成する必要がありました。
その後、すでにソフトウェア開発部門がありました。 必要な機能を自分で実装してみませんか? 構成のスクリプトが「あふれる」まで、24時間機器に接続しようとするサービスが必要です。 バージョン管理も参照構成もありません。 特定の小さなスクリプトのみを実行します。
ログ:telnet / sshとコマンドの知覚におけるニュアンス
CCNAコースを無駄に受講しなかったことが判明しました。 彼らのおかげで、私はシスコの機器を構成する方法を知っていました。 さらに、コンソールを介して他のアプリケーションと「通信」する個別のサービスを開発した経験がありました。
技術の問題
列車列車の設備は、標準のtelnetおよびSSHプロトコルを使用してコンソールから制御されます。 一部の機器は、SNMPによる監視と管理をサポートしています。 特定の機器は、ネットワークレベルの機能により、固定ネットワークからのアクセスが不十分であるため、CDPを使用してヘッド機器からしかアクセスできません。
理想的な解決策を見つける時間はありませんでした。私たちは最も単純な方法、つまりオペレータがコンソールから手動で入力するものを自動化することに決めました。
これは一般的な概要です。
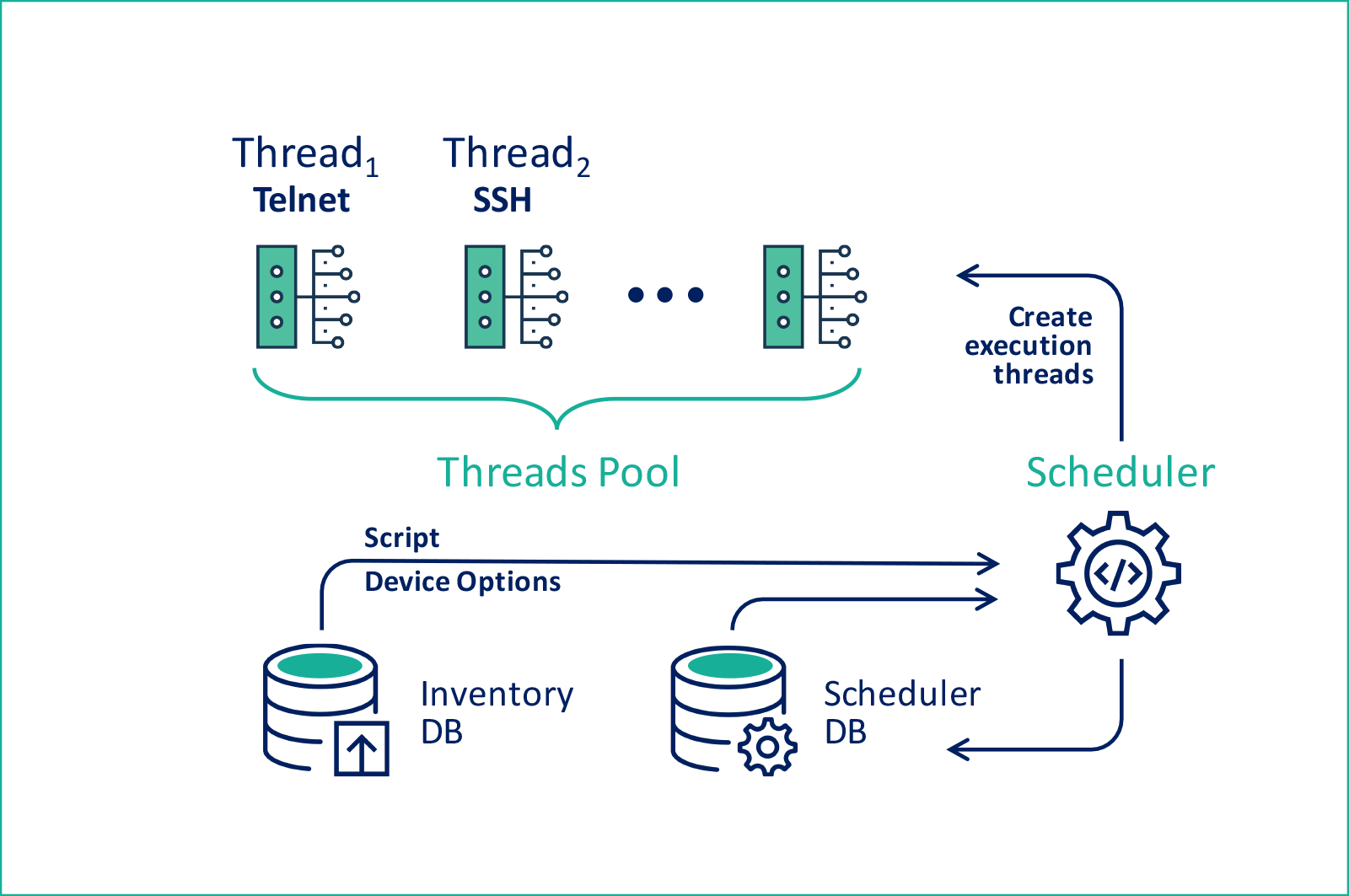
解決策は簡単に思えますが、問題はないはずですが、ないはずです。 彼の作品は、特定のタイプの機器の仕様に影響されました。
技術の問題
汎用性のために、telnet / SSHプロトコルが選択されましたが、デバイスが回答の「書き込み」を終了し、ユーザーからの入力を待つ時期を正確に理解することは不可能です。 この問題を解決するために、「停止記号」の独自の辞書を作成しました。 コンソールに送信された各コマンドには、エコー、応答タイムアウト、および応答完了の兆候といういくつかの属性がありました。 コマンドを送信した後、サービスの動作を決定しました。 完了のサインは、コンソールのデバイス名に続く特殊文字でした:「>」または「#」
ベースに飛びます!
構成管理システムは、関連する機器のデータベースに基づいている必要があります。 標準の在庫ソリューションを使用しなかったため、メトロの構造に基づいて明確なデータ構造を作成することにしました。
1)機器は車内にそのタイプと番号があります。
2)列車は異なる車から再組み立てされることが多いため、列車のメタエッセンスは、それがライン上にあり、したがって接触している場合にのみ関連します。
3)列車は路線に沿って走っています-モスクワには13があります。
4)装置はさまざまなタイプであり、さまざまな設定があります。
さらに、「仮想」列車を思いつき、それらに固定装置を取り付けました。トンネル内の基地局、局ノードの装置、ネットワークコアです。

すべて計画通り
スケジューラを使用して構成システムを実装することにしました。 別のテーブルで、適用されるスクリプトが指定されます。 これらはすべて、すべての特殊文字と属性とともにそのまま保存されます。 選択を簡単にするために、機器の種類にスクリプトを添付し、継承の兆候を追加しました。
ただし、列車を設定する場合、さまざまなタイプの機器間の関係全体が表示されます。アドレス指定を変更するときにコントローラーの可用性を失わないように、最初に列車ルーターを構成してからコントローラーのみを構成する必要がありました。 スクリプトについては、アクティビティの兆候と「機器が接続されている場合にのみ適用」という基準を追加しました 。 ここでは、サービスロジックのレベルで、特定のIPアドレスに接続するときに機器の可用性パラメーターを更新することを決定しました。
次に、スクリプトを参照し、アクティビティの兆候とパラメーターフィールドを持つタスクのテーブルを導入しました 。 重要なのは、構成を送信するデバイス識別子を選択するSQLクエリのテキストです。 このようなスキームを使用することで、任意のサインで、選択したスクリプトで構成するためにデータベースからデバイスを選択できます。
最後に、 イベントと現在実行中のタスクのテーブルを作成しました 。 イベントはタスクを参照し、継承属性も持っていました。 成功した場合またはエラーが発生した場合に実行される次のイベント、および最後にトリガーされたイベントのフィールドと指定された頻度を設定することができました。 一部のイベントは時間によってトリガーされる必要があり、他のイベントは結果としてのみトリガーされる必要があったため、このフィールドを非アクティブの兆候と組み合わせて拡張タイピングを導入しました。 現在のタスクの表に、機器の識別子、イベント、タスクのバンドル、および最後の実行時間とステータス属性を記録しました。

電車のフック
データ構造が設計され、一般的な実装モデルが明確になった後、タスクを完了するプログラムを作成しました。 これは2スレッドソリューションでした。1つのスレッドがデータベース内のアクティブなイベントをチェックし、アクティブなタスクのテーブル内の対応するエントリを作成または変更しました。 2番目のタスクは、アクティブなタスクをすべて実行し、それらを実行しようとしました。 そこで、システムの最初のバージョンが登場しました。
技術の問題
Overbyte ICSとDevart UnidacおよびSecureBridgeコンポーネントを使用して、Embarcadero RAD Studio 2010でサービス全体を作成しました。 最初は、MS Windowsのシステムサービスであり、その構成はXML形式の別のファイルに保存されていました 。
構成の主な欠点は作業速度でした。ほとんどの機器が接続されていませんでした。 また、制御サブネットの構造的特徴により、機器との通信には数秒かかりました。 接続タイムアウトを30秒から2分に設定し、1日で最大20台の列車をキャッチできました。
明らかに、生産性を向上させる鍵はマルチスレッド化です。 マルチスレッドソリューションの開発中に遭遇したすべての困難を省きます(Windowsで同様のことを試みた人は、このことを直接知っています)。 望ましい結果を達成し、6コアの仮想マシンでは、サービスは同時に500を超える機器を処理できました。
次の最適化ステップは、機器の可用性をチェックする「簡単な」タスクを強調することでした。 私は、すべてのタイプの「列車」機器に対して個別のリクエストを作成し、30分ごとに頻度を設定しました。 この時間の間に、1つの列車が線路を離れるか、新しい列車が到着します。 対応する基準を他のタスクに含めたので、過去30分間に接触していた機器の一部だけが尋問されるという事実を達成しました。 そして、このモードでは、すでに運用レベルでのニュアンスに遭遇するまで、十分に長く続きました。
技術の問題
LinuxのようなOSでサービスを再コンパイルしようと何度も試みました。 確かに、私はこの問題を解決しませんでした、なぜなら 本当に必要はありませんでした。 このサービスのみを備えたWindows Server 2012に基づくネイキッドの「仮想マシン」と、CentOS 6用のMariaDBベースのデータベースを備えたスタンドアロンの「仮想マシン」は着実に機能していたため、このような改善に時間を浪費する意味はありませんでした。
搾取、心のないあなた...小麦粉
ネットワークが存在する数年にわたって、160以上のスクリプトを作成して適用しました。それらの多くは、複雑な依存関係を持ち、同じ機器に一貫したアプリケーションが必要でした。 基本的に、アクセスリストを構成し、QoSルールを変更しましたが、承認とDHCPに関連する重要な変更もありました。
その結果、構成システムの欠陥のために、列車はまったく異なる方法で構成された機器で移動しました。 ユーザーは、デバイスが正しく構成されていないという理由だけでWi-Fiが機能しなかった電車に乗ることができました。 ほとんどの場合、状況はすぐに修正されましたが、特定された問題に対するサポートサービスへの大量の要求が消えないマークを残しました。
他の問題は、物理的に欠陥のある機器の交換でした。 操作により、機器が「デフォルト」設定の新しい機器に変更されました。これは、現在のサービス提供システムと互換性がない可能性があります。 自動コンフィギュレーターはそのようなエラーを修正しませんでした、なぜなら 機器が正しく構成されていると信じていました。 時間が経つにつれて、これは重大な問題になりました。ユーザーはこの理由だけでWi-Fiなしで電車に乗ることができました。 解決策は、多くのスクリプトとルールを運用に移すことでしたが、ヒューマンファクターをキャンセルした人はいませんでした。
SIシステム:一般的な構成要件、機器のバージョンマーカー
次に、ハードウェア構成を必要な状態にする「参照スクリプト」を思い付きました。 そして、完全な幸福のために、機器に直接構成ラベルを保存する方法を考え出すことが必要でした。 コントローラについては、空のACLを使用し始めました。 たとえば、2015年1月1日のバージョンでは、「v2015010101」という名前のACLを作成しました-このパラメーターは読みやすく、データベースでスクリプトを直接使用するためのログの実装されたストレージにより、サービススクリプトによって機器から収集された情報に基づいてクエリを作成できました。 最終的な構成スキームは次のとおりです。
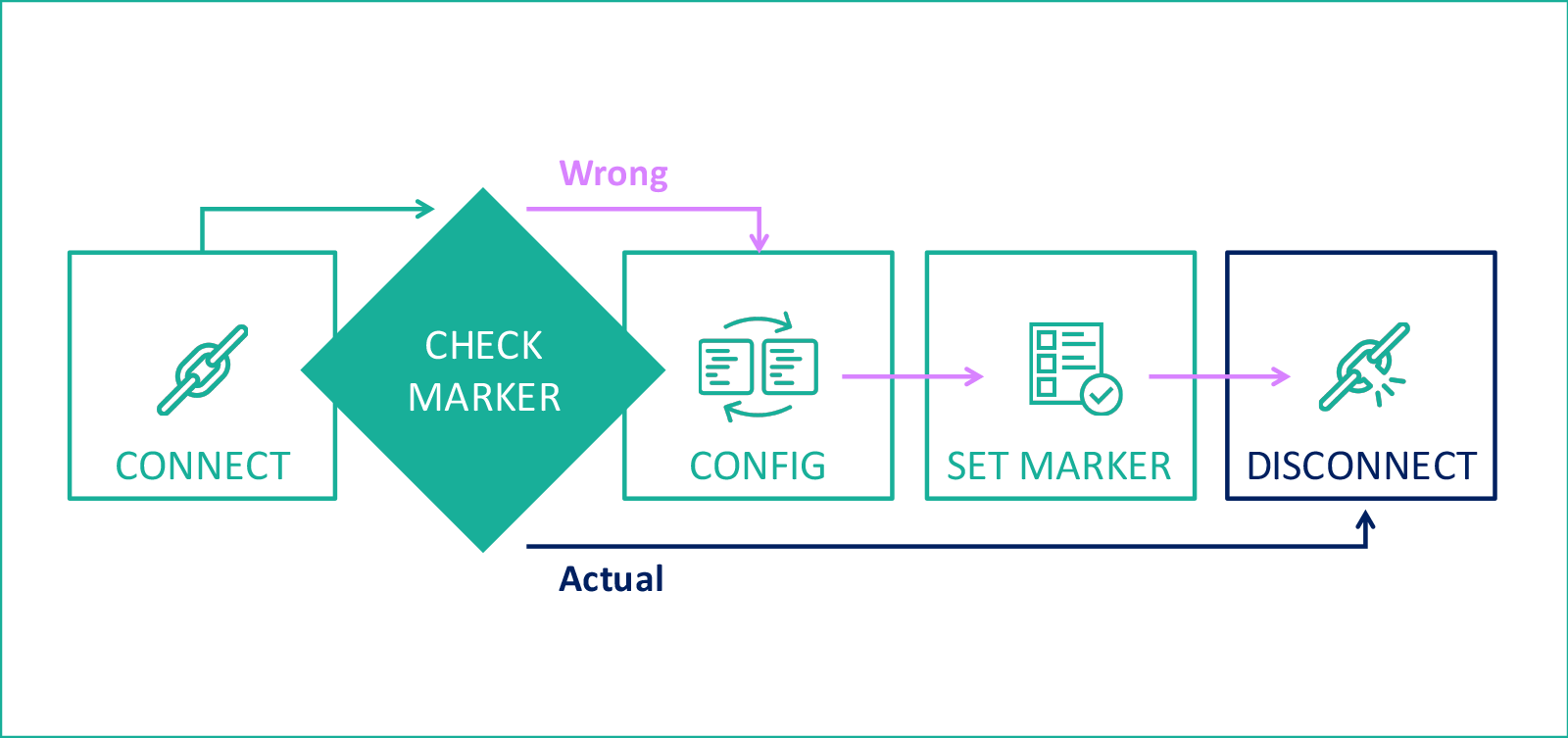
技術の問題
ルーターの場合、フラッシュ上の空のディレクトリをマーカーとして使用し始めました。 一般に、スクリプトの全体的な構造は次のようになります。
shフラッシュ:
...現在の構成のマーカーが存在するかどうか結果を確認し、マーカーがない場合はさらに先へ進みます...
削除/再帰的/強制フラッシュ:v2016071001
削除/再帰的/強制フラッシュ:v2016101001
...ここで古いマーカーはすべて削除されます...
削除/再帰的/強制フラッシュ:v2016111101
conf t
...次に基本的な構成コードが表示されます...
終わり
wr
...スクリプト、新しいマーカーを保存するコマンドを閉じます...
mk v2017080101
shフラッシュ:
...現在の構成のマーカーが存在するかどうか結果を確認し、マーカーがない場合はさらに先へ進みます...
削除/再帰的/強制フラッシュ:v2016071001
削除/再帰的/強制フラッシュ:v2016101001
...ここで古いマーカーはすべて削除されます...
削除/再帰的/強制フラッシュ:v2016111101
conf t
...次に基本的な構成コードが表示されます...
終わり
wr
...スクリプト、新しいマーカーを保存するコマンドを閉じます...
mk v2017080101
「参照スクリプト」の導入は、承認前に利用可能なサービスの形成と一致したため、構成は週に数回変更される可能性がありました。 開発されたシステムは、列車で利用可能なすべての機器の構成を数分で変更できます。 この時点で、ユーザーは数分間Wi-Fiを完全に失いました。これには、Wi-FiネットワークのSSIDが「シャイニング」しなくなったことが含まれます。
バーストはインフラストラクチャにも影響しました。その時点で接続していたすべてのユーザーは、構成が完了した後、自発的にネットワークに再接続しました。 これにより、負荷の増加率に敏感なサービスが低下する可能性があります。
その結果、回路を再度変更しました。 現在、リファレンススクリプトは毎日午前中に開始され、地下鉄が開通し、電車に乗り、ネットワークに接続するだけの機器を「キャッチ」します。 使用可能な試行回数は、metroが閉じるまでにスクリプトが機能しなくなるように構成されています。 したがって、列車は、ネットワークユーザーに大きな影響を与えることなく、路線に乗るときにチェックおよび調整されます。 この決定により、機器の可用性に関する二次調査を中止し、自動コンフィギュレーターのリソース消費を約5倍削減できました。
スイスのナイフよりも良い
ほぼ3年間の使用で、サービスは4回アップグレードされました。これは、サンクトペテルブルクのメトロネットワークへの移植時の最後のアップグレードです。 再起動なしの最長稼働時間は6か月以上で、再起動はサービス自体を更新する必要性に関連していました。 このサービスを使用して、コントローラー、ルーター、および無線機器のファームウェアをセットアップおよび更新し、車のスイッチを構成し、トンネル機器のファームウェアをリロードし、劣化が発生した場合にステーションノードの機器のインターフェイスを自動的に再起動しようとしました。 開発されたシステムは非常に成功したことが判明したため、これまでのところ、新しいソリューションに対する重要なニーズはありませんでした。
また、空席もあります。