Excel openpyxl
— www.datacamp.com/community/tutorials/python-excel-tutorial
— Karlijn Willems
, .xlsx, xlsm, xltx xltm.
openpyxl using pip. — Python . Python: , , , Python.
, , venv. openpyxl pip, , :
# Activate virtualenv $ source activate venv # Install `openpyxl` in `venv` $ pip install openpyxl
openpyxlをインストールしたら、データのダウンロードを開始できます。 しかし、このデータは正確には何ですか? たとえば、Pythonで取得しようとしているデータを含む本には、次のシートがあります。

load_workbook()関数は引数としてファイル名を取り、ファイルを表すワークブックオブジェクトを返します。 これは、タイプ(wb)を実行することで確認できます。 スプレッドシートが置かれている正しいディレクトリにいることを忘れないでください。 そうしないと、インポート時にエラーメッセージが表示されます。
# Import `load_workbook` module from `openpyxl` from openpyxl import load_workbook # Load in the workbook wb = load_workbook('./test.xlsx') # Get sheet names print(wb.get_sheet_names())
os.chdir()を使用して作業ディレクトリを変更できることを忘れないでください。 上記のコードスニペットは、Pythonで読み込まれた本のシート名を返します。 この情報を使用して、ブックの個々のシートを取得できます。 wb.activeを使用して、現在アクティブなシートを確認することもできます。 次のコードでは、それを使用して、ブックの別のシートにデータをロードすることもできます。
# Get a sheet by name sheet = wb.get_sheet_by_name('Sheet3') # Print the sheet title sheet.title # Get currently active sheet anotherSheet = wb.active # Check `anotherSheet` anotherSheet
一見、これらのWorksheetオブジェクトではほとんど何もできません。 ただし、値を取得する正確なセルを渡す角かっこ[]を使用して、ブックシートの特定のセルから値を抽出できます。
これは、NumPyおよびPandas DataFrames配列の選択、取得、およびインデックス付けに似ていますが、値を取得するために行うことはこれだけではありません。 また、属性値を追加する必要があります。
# Retrieve the value of a certain cell sheet['A1'].value # Select element 'B2' of your sheet c = sheet['B2'] # Retrieve the row number of your element c.row # Retrieve the column letter of your element c.column # Retrieve the coordinates of the cell c.coordinate
値に加えて、セルのチェックに使用できる他の属性、つまり行、列、座標があります。
行属性は2を返します。
列属性を「C」に追加すると、「B」が得られます。
座標は「B2」を返します。
cell()関数を使用してセル値を取得することもできます。 行と列の引数を渡し、受け取りたいセル値に対応するこれらの引数に値を追加します。もちろん、値属性を追加することを忘れないでください。
# Retrieve cell value sheet.cell(row=1, column=2).value # Print out values in column 2 for i in range(1, 4): print(i, sheet.cell(row=i, column=2).value)
注:value属性の値を指定しない場合、<Cell Sheet3.B1>を取得しますが、この特定のセルに含まれる値については何も言いません。
range()関数でループを使用すると、列2に値を持つ行の値を推測できます。これらの特定のセルが空の場合、Noneが返されます。
さらに、get_column_letter()やcolumn_index_from_stringなど、他の値を取得するために呼び出すことができる特別な関数があります。
2つの関数は、すでに多かれ少なかれ、それらを使用して取得できるものを示しています。 ただし、明示的にするのが最善です。前の列の文字は取得できますが、逆の操作を行うか、文字ごとに並べ替えて列のインデックスを取得できます。 仕組み:
# Import relevant modules from `openpyxl.utils` from openpyxl.utils import get_column_letter, column_index_from_string # Return 'A' get_column_letter(1) # Return '1' column_index_from_string('A')
特定の列に値を持つ行の値はすでに取得していますが、1つの列のみに注目せずにファイルの行を表示する場合はどうすればよいですか?
もちろん、別のループを使用します。
たとえば、「A1」と「C3」の間の領域に焦点を当てたい場合、最初の部分は焦点を合わせたい領域の左上隅を示し、2番目は右下隅を示します。 この領域はいわゆるcellObjになり、以下のコードの最初の行に表示されます。 次に、この領域にある各セルについて、このセルに含まれる座標と値を表示することを示します。 各行の終わりに、cellObjのこの領域の行が表示されたことを示す信号を表示します。
# Print row per row for cellObj in sheet['A1':'C3']: for cell in cellObj: print(cells.coordinate, cells.value) print('--- END ---')
リージョンの選択は、リストとNumPy要素の選択、取得、インデックス付けと非常に似ていることに注意してください。ここでは、角括弧とコロンを使用して、値を取得するリージョンを示します。 さらに、上記のループはセル属性をうまく利用しています!
上記を視覚化するために、結果を確認すると、完了したループが返されます。
('A1', u'M') ('B1', u'N') ('C1', u'O') --- END --- ('A2', 10L) ('B2', 11L) ('C2', 12L) --- END --- ('A3', 14L) ('B3', 15L) ('C3', 16L) --- END ---
最後に、インポート結果を確認するために使用できる属性、つまりmax_rowとmax_columnがあります。 もちろん、これらの属性は、データの正しいロードを保証する一般的な方法ですが、それにもかかわらず、この場合、それらは有用であり、有用です。
# Retrieve the maximum amount of rows sheet.max_row # Retrieve the maximum amount of columns sheet.max_column
これはすべて非常にクールですが、特にデータを管理する必要がある場合は、ファイルを操作するための非常に難しい方法であると今あなたが思うことはほとんど聞こえます。
何かもっとシンプルでなければならないでしょう? それだけです!
OpenpyxlはPandas DataFramesをサポートしています。 そして、PandasパッケージのDataFrame()関数を使用して、シートの値をDataFrameに入れることができます。
# Import `pandas` import pandas as pd # Convert Sheet to DataFrame df = pd.DataFrame(sheet.values) , : # Put the sheet values in `data` data = sheet.values # Indicate the columns in the sheet values cols = next(data)[1:] # Convert your data to a list data = list(data) # Read in the data at index 0 for the indices idx = [r[0] for r in data] # Slice the data at index 1 data = (islice(r, 1, None) for r in data) # Make your DataFrame df = pd.DataFrame(data, index=idx, columns=cols)
その後、Pandasにあるすべての機能を使用してデータの管理を開始できます。 ただし、仮想環境にいるため、ライブラリがまだ接続されていない場合は、pipを使用して再度インストールする必要があります。
Pandas DataFramesをExcelファイルに書き戻すには、utilsモジュールのdataframe_to_rows()関数を使用できます。
# Import `dataframe_to_rows` from openpyxl.utils.dataframe import dataframe_to_rows # Initialize a workbook wb = Workbook() # Get the worksheet in the active workbook ws = wb.active # Append the rows of the DataFrame to your worksheet for r in dataframe_to_rows(df, index=True, header=True): ws.append(r)
しかし、それだけではありません! openpyxlライブラリは、Excelファイルへのデータの書き込み、セルスタイルの変更、書き込み専用モードの使用に関する柔軟性を提供します。 これにより、スプレッドシートを頻繁に使用する場合に必ず知っておく必要のあるライブラリの1つになります。
また、データの操作が終了したら、仮想環境を無効にすることを忘れないでください!
では、Pythonスプレッドシートでデータを取得するために使用できる他のライブラリを見てみましょう。
詳細を学ぶ準備はできましたか?
Excel xlrdファイルの読み取りとフォーマット
このライブラリは、データを読み取り、拡張子が.xlsまたは.xlsxのファイルのデータをフォーマットする場合に最適です。
# Import `xlrd` import xlrd # Open a workbook workbook = xlrd.open_workbook('example.xls') # Loads only current sheets to memory workbook = xlrd.open_workbook('example.xls', on_demand = True)
本全体を調べたくない場合は、sheet_by_name()やsheet_by_index()などの関数を使用して、分析に使用するシートを取得できます。
# Load a specific sheet by name worksheet = workbook.sheet_by_name('Sheet1') # Load a specific sheet by index worksheet = workbook.sheet_by_index(0) # Retrieve the value from cell at indices (0,0) sheet.cell(0, 0).value
最後に、インデックスで示される特定の座標で値を取得できます。
xlwtとxlutilsがxlrdとどのように関連するかについて説明します。
xlrdを使用してExcelファイルにデータを書き込む
XlsxWriterライブラリに加えて、データを含むスプレッドシートを作成する必要がある場合は、xlwtライブラリを使用できます。 Xlwtは、拡張子が.xlsのファイルにデータを書き込んでフォーマットするのに最適です。
ファイルに手動で書き込みたい場合、次のようになります。
# Import `xlwt` import xlwt # Initialize a workbook book = xlwt.Workbook(encoding="utf-8") # Add a sheet to the workbook sheet1 = book.add_sheet("Python Sheet 1") # Write to the sheet of the workbook sheet1.write(0, 0, "This is the First Cell of the First Sheet") # Save the workbook book.save("spreadsheet.xls")
ファイルにデータを書き込む必要がある場合は、手作業を最小限に抑えるために、forループを使用できます。 これにより、プロセスを少し自動化できます。 ブックが作成され、シートが追加されるスクリプトを作成します。 次に、ワークシートに転送される列と値のリストを示します。
forループは、すべての値がファイルに含まれることを確認します。0〜4の範囲の各要素(5は含まれません)でアクションを実行することを指定します。 行ごとに値を入力します。 これを行うには、各サイクルで「ジャンプ」する行要素を指定します。 そして、次のforループがあります。これはシートの列を通過します。 シートの各行に対して列を見て、行の各列に値を入力するという条件を設定します。 行のすべての列に値が入力されたら、使用可能なすべての行が入力されるまで次の行に進みます。
# Initialize a workbook book = xlwt.Workbook() # Add a sheet to the workbook sheet1 = book.add_sheet("Sheet1") # The data cols = ["A", "B", "C", "D", "E"] txt = [0,1,2,3,4] # Loop over the rows and columns and fill in the values for num in range(5): row = sheet1.row(num) for index, col in enumerate(cols): value = txt[index] + num row.write(index, value) # Save the result book.save("test.xls")
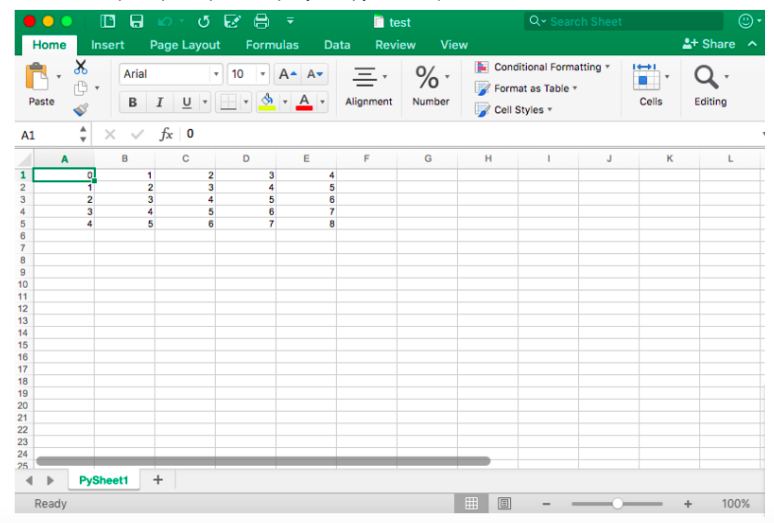
例として、結果のファイルのスクリーンショット:
xlrdとxlwtがどのように相互作用するかを確認したので、次はこれら2つに密接に関連するライブラリxlutilsを見てみましょう。
Xlutilsユーティリティコレクション
このライブラリは基本的に、xlrdとxlwtの両方を必要とするユーティリティのコレクションです。 既存のファイルをコピーおよび変更/フィルタリングする機能が含まれています。 一般的に、これらのケースは両方とも現在openpyxlに該当します。
pyexcelを使用して.xlsまたは.xlsxファイルを読み取る
Pythonでテーブルデータを読み取るために使用できる別のライブラリは、pyexcelです。 これは、.csv、.ods、.xls、.xlsx、および.xlsmファイルのデータを読み取り、処理、および書き込むための1つのAPIを提供するPythonラッパーです。
配列のデータを取得するには、pyexcelパッケージに含まれるget_array()関数を使用できます。
# Import `pyexcel` import pyexcel # Get an array from the data my_array = pyexcel.get_array(file_name="test.xls") , get_dict (): # Import `OrderedDict` module from pyexcel._compact import OrderedDict # Get your data in an ordered dictionary of lists my_dict = pyexcel.get_dict(file_name="test.xls", name_columns_by_row=0) # Get your data in a dictionary of 2D arrays book_dict = pyexcel.get_book_dict(file_name="test.xls")
ただし、2次元配列を辞書に返す場合、つまり、1つの辞書で本のすべてのシートを取得する場合は、get_book_dict()関数を使用する必要があります。
上記のデータ構造、スプレッドシートの配列と辞書の両方で、pd.DataFrame()を使用してデータのデータフレームを作成できることに注意してください。 これにより、データの処理が簡単になります!
最後に、get_records()関数のおかげで、pyexcelで簡単にレコードを取得できます。 関数にfile_name引数を渡すだけで、辞書のリストを取得できます。
# Retrieve the records of the file records = pyexcel.get_records(file_name="test.xls")
pyexcelでファイルを書く
このパッケージを使用してデータを配列にロードするように、配列をスプレッドシートに簡単にエクスポートすることもできます。 これを行うには、save_as()関数を使用して、配列とターゲットファイルの名前を引数dest_file_nameに渡します。
# Get the data data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # Save the array to a file pyexcel.save_as(array=data, dest_file_name="array_data.xls")
注:区切り文字を指定する場合は、引数dest_delimiterを追加して、「」の間の区切り文字として使用する文字を渡すことができます。
ただし、辞書がある場合は、save_book_as()関数を使用する必要があります。 2次元辞書をbookdictに渡し、ファイル名を指定すれば、すべて問題ありません。
# The data 2d_array_dictionary = {'Sheet 1': [ ['ID', 'AGE', 'SCORE'] [1, 22, 5], [2, 15, 6], [3, 28, 9] ], 'Sheet 2': [ ['X', 'Y', 'Z'], [1, 2, 3], [4, 5, 6] [7, 8, 9] ], 'Sheet 3': [ ['M', 'N', 'O', 'P'], [10, 11, 12, 13], [14, 15, 16, 17] [18, 19, 20, 21] ]} # Save the data to a file pyexcel.save_book_as(bookdict=2d_array_dictionary, dest_file_name="2d_array_data.xls")
上記のコードスニペットに印刷されているコードを使用する場合、辞書のデータ順序は保存されないことに注意してください!
.csvファイルの読み取りと書き込み
パンダ以外のCSVファイルにデータをロードして書き込むことができるライブラリを探している場合は、csvライブラリをお勧めします。
# import `csv` import csv # Read in csv file for row in csv.reader(open('data.csv'), delimiter=','): print(row) # Write csv file data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] outfile = open('data.csv', 'w') writer = csv.writer(outfile, delimiter=';', quotechar='"') writer.writerows(data) outfile.close()
NumPyには、CSVファイルに含まれるデータを配列に読み込むことができるgenfromtxt()関数があり、これをDataFramesに配置できることに注意してください。
最終データ検証
データの準備ができたら、最後のステップを忘れないでください。データが正しくロードされていることを確認してください。 データをDataFrameに配置する場合、次のコマンドを実行することにより、インポートが成功したかどうかをすばやく簡単に確認できます。
# Check the first entries of the DataFrame df1.head() # Check the last entries of the DataFrame df1.tail()
注:Pandas DataFramesとしてファイルをアップロードする場合は、DataCamp Pandasチートシートを使用してください。
データが配列内にある場合、次の配列属性を使用して確認できます:shape、ndim、dtypeなど:
# Inspect the shape data.shape # Inspect the number of dimensions data.ndim # Inspect the data type data.dtype
次は?
おめでとうございます。これで、PythonでExcelファイルを読み取る方法がわかりました。 環境にスプレッドシートのデータがある場合、本当に重要なこと、つまりデータ分析に集中できます。
トピックをさらに深く掘り下げたい場合は、PyXllに慣れてください。PyXllを使用すると、Pythonで関数を記述し、Excelで呼び出すことができます。