, , , kaggle , Data Science, , .
.
UPD: «» .

1. « …» —
, , , .
, , Data Science Cognitive class () (Data Science from Scratch) ( ).
, :
- Cognitive class – Data Science , .
- – , , - , , , (, pandas) , Python , «» kaggle ( ).
Data Science , « », - , «» , - …
2. «… » — kaggle
, kaggle , , .
, kaggle , . , , ( , - ).
, , , ( , ), - , - .
, , - ( ).
, (« !»).
, , , , Titanic: Machine Learning from Disaster «», .
, — , , Data Science
( , , Data Science , - , , )
«Overview» , kaggle , FAQ Tutorials. , ( ) .
FAQ: .
- , *ba-dum-tss*.

Tutorials: , « » , ( ) . 3 :
- ( ), , .
- DataCamp
- .
R Python. , Excel.
, , «Data». , , , . , , , .
, ( «Kernels»), .
.
?
( R) ( Python), , Python.
Python , - , - , , « » .
3. « , …» — Python
, , — , . : "Kaggle Python Tutorial on Machine Learning". ( ).
? - codecademy, . , Python. , , , , (, )
:
- ;
- (Decision Trees). , kaggle;
- Random Forest . kaggle;
チュートリアルは簡単で、最大で2時間ほどかかります。
各チャプターを完了した後、コースを受講すると、有料アカウントを取得するように求めるウィンドウがポップアップ表示され、その後、コースを続行します(閉じるボタンに気付かなかった、おそらくそこにある)、気になる場合は、ツールを使用して削除できます「要素コードの表示」(ほとんどの最新のブラウザで利用可能)、「モーダル」などの単語を含むクラスのDivを削除する必要があります。たとえば、「モーダルコンテナ」です。ウィンドウが消えた後、結果を安全に送信して次へ進むことができます章。
コースが非常に有益であるとは言えませんが、ノートブックで実験したときにPythonでのデータ分析用のライブラリに関する最も最小限の(直接小さな)アイデアを提供します(以下について)、それらから多くのトリックを借りました。
パート4.「...海でどれほど危険か」-Pythonでメモ帳を持っている人
インタラクティブコースを修了した後、ノートブックを掘り下げようとせずに彼が提供するデータセットを送信した場合、自分を尊重しないことにしました。
ちなみに、このプラットフォームでは、好きなノートブックを「フォーク」して実験したり、自分でコードをダウンロードしてコンピューターで選択したりすることができます。
すでに述べたように、ノートブックはたくさんあるので、覚えやすいと思われるものを選ぶことにしました(翻訳するために、朝の2時に英語のテキストの「足元」を少しもしたくありませんでした)。 だから、私は「からコードを借りすることにしましたScikitレスを学習して機械学習Etpuスタートからフィニッシュまで 」、著者は高い予測精度を約束しませんが、主なものは、勝つためにはなく参加することではありません。
正直なところ、元の形で少なくとも1つのソリューションを使用するために、私の手は上がりませんでした、私は少なくとも少しコードを掘り、自分の手で数行を書いてみましたので、インタラクティブなチュートリアルとこのノートブックのコードからひどいモンスターを得ました
そのため、コンピューターでコードを編集することにしました(以前の記事でAnacondaをインストールしただけではありません)。 他の誰かが、何か Jupyterは、コードの各セクションは、単一のセルに私に挿入されている(しかし、より良いではない、その後、彼は警告を発行しますノートにそれを駆動したい場合には全体が、それが起こった非常に恥ずべきである、あなたのコードをアップロードされません何か、これは悪いロールモデルです)。
まず、データ宣言を盗みました。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn import tree %matplotlib inline data_train = pd.read_csv('data/train.csv') data_test = pd.read_csv('data/test.csv') data_train.sample(5)
それから、私はコードを借用して図のペアを作成しました。 出発点の異なる男性と女性の生存率の関係が示されました。
sns.barplot(x="Embarked", y="Survived", hue="Sex", data=data_train);
2番目のグラフは、乗客が住んでいたクラスと同じ関係を示していますが、すでに相対的です。
sns.pointplot(x="Pclass", y="Survived", hue="Sex", data=data_train, palette={"male": "blue", "female": "red"}, markers=["*", "o"], linestyles=["-", "--"]);
グラフィックは元のノートブックにあるため、写真をアップロードしません。
それから、私は自分が悪くないと判断し、自分の図表を考え出そうとしました。
私は同伴者のステータスと滞在クラスが18歳未満の子供の生存確率に何らかの影響を与えるかどうかを確認することにしました。
このサンプルは計算を甘やかすことに関与していないため、データのコピーを作成し、データを必要な形式に変換しました。
data_train2=data_train.copy() data_train2=data_train2[data_train2["Age"] <= 18] data_train2.Parch = data_train2.Parch.fillna("nanny") data_train2["Parch"][data_train2["Parch"] != 0] = 'parrents' data_train2["Parch"][data_train2["Parch"] != 'parrents'] = 'nanny'
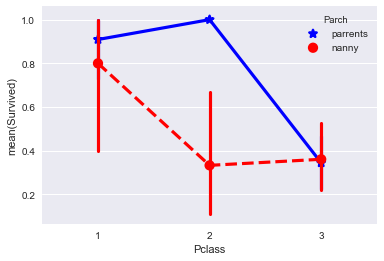
最後に、何かが起こった。 この図は、乳母の代わりに親がいた2人目の乗客クラスの子供がはるかに頻繁に生存したこと、または5日後にデータ分析をマスターすることができないため、私が間違っていたことを除いて何も言わないことを示しています)
計算された部分に移りましょう。 今後、変更を確認するためにソリューションをkaggleに2回アップロードしたと言います。
そのため、インタラクティブチュートリアルのコードのバージョンはあまり便利ではないことに気付き、同じコードを大量に作成しないようにするために、メモ帳の作成者である関数を記述するバリアントを借りることにしました。
def simplify_Age (df): df.Age = data_train.Age.fillna(0) def simplify_Sex (df): df["Sex"][df["Sex"] == 'male'] = 0 df["Sex"][df["Sex"] == 'female'] = 1 def simplify_Embarked (df): df.Embarked = df.Embarked.fillna(0) df["Embarked"][df["Embarked"] == "S"] = 1 df["Embarked"][df["Embarked"] == "C"] = 2 df["Embarked"][df["Embarked"] == "Q"] = 3 def simplify_Fares(df): df.Fare = df.Fare.fillna(0)
これらの関数は、データを後でデジタル形式に変換できるように、データをデジタル形式に変換します。
さらに、トレーニング済みモデル(data_train)およびテストモデル(data_test)にこれらの関数を適用しました
simplify_Age(data_train) simplify_Sex(data_train) simplify_Embarked(data_train) simplify_Fares(data_train) simplify_Age(data_test) simplify_Sex(data_test) simplify_Embarked(data_test) simplify_Fares(data_test)
ツリーに目標を割り当てた
target = data_train["Survived"].values
さらに分割されたアクション
# 2. , ( ) data_train["Family"]=data_train["Parch"]+data_train["SibSp"] data_test["Family"]=data_test["Parch"]+data_test["SibSp"]
最初のモデルのオプション。 ここで何が起こっているのか完全にはわかりませんが、明らかに、彼が作成したツリーと予測に大きく貢献するパラメーターを理解できます。
# features . features = data_train[["Pclass", "Sex", "Age", "Fare"]].values d_tree = tree.DecisionTreeClassifier() d_tree = d_tree.fit(features, target) print(d_tree.feature_importances_) print(d_tree.score(features, target))
次に、最初のモデルのテストデータセットの予測を作成し、csvに保存します。
# test_features = data_test[["Pclass", "Sex", "Age", "Fare"]].values prediction = d_tree.predict(test_features) submission = pd.DataFrame({ "PassengerId": data_test["PassengerId"], "Survived": prediction }) print(submission) submission.to_csv(path_or_buf='data/prediction.csv', sep=',', index=False)
.csvフォルダーから取得し、kaggleに戻って[予測を送信]をクリックすると、 0.689の信頼性が得られます。 良いとは言えませんが、それが最初の予測です! この後、あなたは超能力についての人気のテレビ番組で仕事に行くことができます。
最後の部分で説明する理由により、モデルの品質についてあまり心配せず、インタラクティブなデータキャンプコースからモデルを改善するためのテクニックを適用しませんでした(そして、そこにあります)。
それでも、記事をもっと見やすくするために、1つの小さな改善点を分析しましょう。
上記で、コメント付きのコードを提案しました:「#B2。 2番目のモデルのセルは、最初のモデルでは使用されなかった後のコードの前に移動します。「コメントの後の2行のコードをすぐに挿入できます(害はありませんが、良好です)。
これらの線が私たちにとって退屈なのはなぜですか? 家族(姉妹、兄弟、両親など)の存在が生存にどのように影響するかを確認することにしました(アイデアは主にインタラクティブチュートリアルから取られています)。 「サテライト」フィールドと「相対」フィールドを組み合わせて(私の無料翻訳)、「家族」フィールドを得ました
行を置き換えますfeatures = data_train [["Pclass"、 "Sex"、 "Age"、 "Fare"]]。値とtest_features = data_test [["Pclass"、 "Sex"、 "Age"、 "Fare"、 "Family »]]。次の値:
features = data_train[["Pclass", "Sex", "Age", "Fare","Family"]].values test_features = data_test[["Pclass", "Sex", "Age", "Fare","Family"]].values
彼らは家族の影響力のパラメーターを追加しましたが、それ以外はすべて変更されません。
私が理解しているように、印刷コマンド(d_tree.feature_importances_)は、モデルの最終結果に対する各パラメーターの寄与度を示しています。
次のものが得られます。
1. [0.08882627 0.30933519 0.23498429 0.29841084 0.06844342]。
2. 0.982042648709-これは近似モデルの精度のようです
1行目では、配列内の位置は「Pclass」、「Sex」、「Age」、「Fare」、「Family」に対応しています。 そのため、家族に関するパラグラフはあまり天気を立てないことがわかりますが、好奇心のために、更新された結果をkaggleにアップロードします。
そして、私たちのモデルは、予測の精度をわずかに高めましたが、今では0.72727です。 そして、この結果はすでにランキングで6800位の地域にあります=)
質問があるかもしれませんが、2行目の予測精度は0.98以上になる可能性がありますか?テストサンプルで0.72を得たのはなぜですか? どうやら、その理由は、データセットdata_trainの選択を予測するためにモデルが「再トレーニング」されている、つまり、あまりにもシャープであり、data_testセットをチェックするときに必要な柔軟性が示されていないことにあります この問題は、「ツリー」のパラメーターを調整することで解決する必要があります。これは、前述のインタラクティブコースで述べられていますが、この記事のフレームワーク内では行いませんでした。 私たちは単純な人です。0.72で十分なので、最後の部分に進みましょう。
パート5.「アイスバーグ対向船」-結論
私は考えたことがありませんでしたが、データの中毒を探して予測を試みることは魅力的で非常にエキサイティングなチャンスです! ゼロから始めるのは難しいという事実にもかかわらず、そして私が理解しているように、仲間の分野でのスキルのほとんど完全な欠如。 分析、統計、確率理論の適用が複数回繰り返されます。一般に、初期段階では、プロセスは中毒性があります。
3つの記事の例からわかるように、最初からこのテーマに完全に興味を持ち、Pythonファンであれば、一般概念の理解に大きなダメージを与えることなくCognitive Classオプションをスキップできることを示しました(ただし、無料で、原則として1日間可能です) 2つを費やしてください。ツールをご覧ください)。
それでも、これら3つの記事の資料を準備する過程で、私は耐え難いほど苦痛にならないためには、より高いレベルのトレーニングに進まなければならないことに気付きました。
したがって、少なくとも「ロシア語で」コース「コースラでホストされる専門機械学習とデータ分析」に登録することは理にかなっていると思うので、あいまいな用語の翻訳について困惑する必要はありません。
したがって、ランダムな好奇心がより深刻なものに発展する恐れがあります。数か月後には、コースを終えると、尊敬する読者と彼の印象を共有します。
すべての人に良い! あなたの回に負担をかける幸運を!