この記事は、実際のマイクロコントローラーのプログラミングの実践から取られたタスクの例を使用して、プラグマティストの目を通してプログラムを調べる試みです。 ただし、自動化されたアプローチは、Windowsなどのイベントベースのシステムでドライバーやインタラクティブアプリケーションを作成するために効果的に使用できるため、エンベッダーだけでなく、興味を引くこともあります。
目次。
1.はじめに
2.状態図と遷移。
3.状態図と遷移。 継続
4.自動設計されたプログラムの効率
自動化されたワークショップ-1.「ディスプレイ」の例、OAおよびUAの開発
自動化されたワークショップ-2.例「交差」、OAでのTKの数学的変換
おそらく、デジタルマシンについて聞いたことがないプログラマーはあまりいないでしょうが、聴衆を遮断しないために、その本質を簡単に説明します。 自動機は、次の原則に基づいて構築されたデジタルデバイスです。
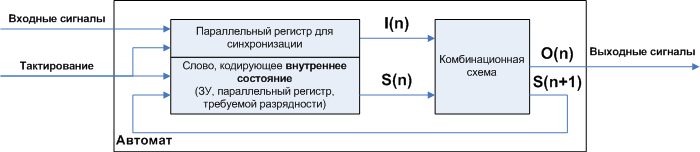
図1.デジタル自動販売機の一般的な構造
どこで:
- 組み合わせ回路(KS)-メモリー要素を含まないデジタル論理回路。 つまり 彼女の状態は彼女の入り口にあるものによってのみ決定されます。
- CC入力は条件付きで2つのグループI(n)-外部信号(マシンの入力)、S(n)-現在のステップでのマシンの内部状態に分けられます。 内部状態は、比fig的に言えば、マシンが外部信号I(n)を信号O(n)に変換する方法を決定する一種の「モード」です。 古典的な組み合わせ回路(入力グループS(n)はありません)には、そのような「モード」が1つしかありません。
- CSの出力も2つのグループO(n)に分割されます。実際に「有用な作業」を実行する信号が出ます。S(n + 1)は次のステップの内部状態です。 つまり、 各ステップで、オートマトンは入力信号I(n)に応じて、所望の出力信号O(n)を計算するだけでなく、次のステップの信号処理モード(つまり、信号I(n + 1))も含みます、必要に応じて、このモードは同じでも異なっていてもかまいません。 言い換えると、 入力信号シーケンスのあらゆる可能性のあるケースに必要なモードを設定できます 。これにより、マシンは「全能」になります。
- 同期の目的で、フィードバック回路内の前のステップに関連するワードと次のステップに関連するワードを分離するメモリデバイス(メモリ、パラレルレジスタ)が導入されています。 記号nとn + 1は、現在のステップと次のステップ、つまり nは時間軸ではなく、一連のステップに対応します。 ステップはクロック信号によって設定され、クロック信号を介して時間軸にリンクされます。 ステップは、定期的なクロック信号ではなく、イベント「signal I Arrival」に接続されている場合があります。
- 同じ目的で、同様のストレージデバイスが入力信号チャネルIに導入されます。
自動機械に精通していない場合、説明をわかりやすくするために、このようなデバイスの利点は明らかではありませんが、本質をよく表す数学的な抽象化があります。 状態図と遷移を使用して 、マシンの動作を明確に説明できます。 以下の図は、エレベータを制御するデバイスの動作を説明しています。 これは非常に簡略化された図で、ドアの開閉、加速/停止のプロセスを考慮していませんが、実際のオブジェクトがマシンを使用してどのようにモデル化されているかを視覚的に表現します。 矢印の上には遷移が起こる条件が書かれており、楕円形では書かれています
state_name / what_will_on_output_auto_at this_ state。

図2.状態図と遷移の例
上記に加えて、図にムーアのオートマトンが示されています。 そのようなオートマトンの出力の状態は、 現在の状態に依存します。 代替手段はMilesマシンです。 その出力信号は最後に完了した遷移に依存するため、be_on_outputが対応する矢印の上に書き込まれます。 この違いにもかかわらず、マイルズとムーアのマシンは数学的に相互に変換されます。 ムーアオートマトンは認知目的により適していますが、両方の抽象化はプログラミングの実践に役立ちます。そのため、次の部分ではMiliオートマトンを無視しません。
多かれ少なかれ複雑なデジタル回路は、デジタルマシンとまったく同じように設計されています。 なんで? デジタル回路の設計におけるオートマトンアプローチの不可欠性は、オートマトンアプローチの3つの主な利点に貢献します。
- 分解。
- プロセスをステップのシーケンスとしてではなく、すべての可能なステップの組み合わせとして見る。
- 数学
オートマトンは数学的実体であり、その理論は広く深く掘り下げられており、正確な数学的手法を使用して得られたオートマトンを最適化および分析することができます。 この観点から、非自動的な方法でのプログラムの開発は「人文科学の仕事」とみなすことができます。 数学的な方法は、第2部で検討されます。 分解から始めて、説明されている利点を考慮してください。
パート1。建設的な分解。
オートマトンの数学的理論では、分解とは、状態および遷移の複雑なダイアグラム上で動作するオートマトンの作成であり、並列および/またはシリアル接続を持ち、元のオートマトンに追加されるいくつかのシンプルで理解可能なオートマトンです。 これは数学的なため、正確な手順です。
したがって、実用的な自動エンジニアリングを検討します。したがって、最初の部分では、分解とは数学的な分解ではなく、常識に基づいたオートマトンのパーティションを意味します。 2番目の部分では、数学的な分解の例を示します。
オートマトンは通常、 手術室と制御 室に分けられます 。 名前からその意味は明らかです。オペレーティングマシンは「手」、マネージャーは「頭」です。 さらに、パーティションはマルチレベルにすることができます。つまり、オペレーティングマシンをエグゼクティブパーツと管理パーツに分けることができます。 つまり マニピュレータアームは、一般的なコマンド(「オブジェクトを取得」)を各「指」を制御する詳細なコマンドセットに変換する独自の「ミニモブレイン」を持つことができます。 さらに具体的な例は、パイプライン、レジスタ、ALU、およびFPU(オペレーティングマシンとマイクロプログラム)、制御マシンを備えたプロセッサです。
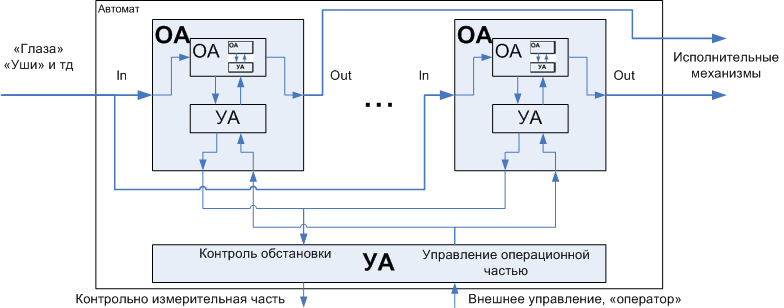
図3.機械の操作と制御への分解
大きなタスクを小さなサブタスクに分割する原理は、実際にはプログラミングの実践で広く普及しています。これはタスクをサブプログラムに分割することです。 ただし、プログラムの自動解釈、つまり 操作部と制御部を備えたオートマトン形式のプログラムオブジェクトの表示により、ソースコードの機械的で素朴な(良い意味での)断片化から逃れることができ、これを行う方法に関する一連の実用的な考慮事項が提供されます。 設計しています。 プログラムについてさらに詳しく話せる例を考えてみましょう。 この例は、いくつかの記事を通して横断的です。
問題の声明
_____________________________________________________________________
b / wグラフィックディスプレイがあるとします。 そのビデオメモリには、各ビットがポイントを表す標準のバイト構成があります。 等幅フォントではなく、異なるフォントでテキストを出力する必要があるとします。

a)

b)
c)
図4.ディスプレイモジュールの要件
フォント内のすべての文字は同じ高さですが、フォントは同じ行を表示するプロセスで「オンザフライ」で変更できます。 同様に、属性を変更できます-太字、斜体、下線。 パラメーターを制御するには、 esc-sequencesを使用します 。これには、制御文字「\ n」、改行、つまり 1行のテキストをディスプレイの複数の行に表示できます。 たとえば、テキスト:
"Text 1 \033[7m Text 2 \033[27m \033[1m Text 3 \033[21m \n Text 42"
図に示すように表示されます(図4、b)
テキストは長方形で囲まれた領域に表示され(図4、c)、オフセットがある場合があります。 出力領域の座標は、親しみやすさではなく、ピクセル単位で設定されます。これは、出力領域を超えることを意味する負の座標です。 出力領域を超えるテキストはクリップされます。
プロトタイプを使用して、これらすべてを実装する関数を作成する必要があります
void Out_text(int x0, int y0, int x1, int y1, int x_shift, int y_shift, char * Text);
これは、すべてのテキスト操作にとって重要な基本機能です。printf関数の操作、仮想ウィンドウの実装、クリープラインなどです。
_____________________________________________________________________
オートマトン(つまり、実装されているプロセスのモデル)のコンパイルは、一般から特定まで、上から下へ実行されますが、逆にモデルとそのソフトウェア実装の詳細な調査は下から行われます。 これは通常、最低レベルがアクチュエーターに直接結び付けられているため、特定のフレームワークに入れられ、「操作」の可能性が制限されるという事実によって決定されますが、このレベルではより高いレベルがより柔軟であり、それらのフレームワークは基礎の実装に従います自動機。
ソフトウェア実装の作成プロセスは反復的であり、最初にモデルの最下位レベル( 上から下に開発)が実装され、次に次のレベルが開発され、基礎となるものが並行して調整され、その後、開発が必要に応じて基礎となるものがより高いレベルに移動します。 適切な設計には、 追加に限定されて、基礎となるレベルの最小限の処理が必要です。 プログラムコードの形式でのオートマトンの最終実装は、すべてのオートマトンのコンパイル後に実行されますが、それにもかかわらず、アルゴリズムの概要はオートマトンの設計と並行して実行されます。 基礎となる計算はすべて、実例としてプログラムをコンパイルした後ではなく、設計の重要な段階としてプログラムコードを作成する前に実行されました。 それでは、開発に取り掛かりましょう。
問題の条件から次のように、一般的な場合の最初の文字シーケンスは次のようになります。Text1 control1 Text2 control2 Text3 control3 Text4 control4 Text5 \ 0
テキストブロックを互いに分離するesc-sequence、翻訳の文字、および行末を制御します。 テキストをブロックに分割すると、1つのブロック内で最大数の同一の設定(テキストの高さや行頭の座標など)を使用できるため便利です。
OA-UAのペアの開発は、常にOAの開発から始まります。 OAは、マシンが管理するプロセスのすべての側面をシミュレートするという試みに基づいて構築されています。 ディスプレイの場合、いくつかの独立した側面があります。テキストを制御シーケンスで区切られたブロックに分割し、ビデオメモリにフラッシュされるバッファにグラフィックデータを収集します。 したがって、オートマトンは、図に示す2つのサブオートマトンで構成されます。 5。
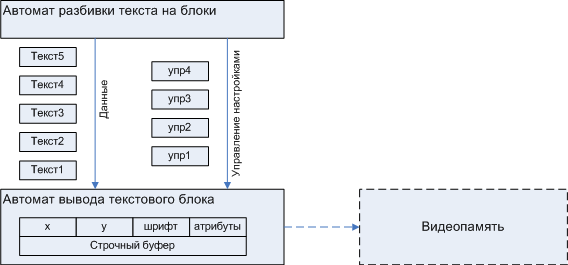
図5.初期パーティション
テキストブロックを組み立てるための中間バッファの必要性は、ディスプレイの多くの場合、次のようなプロトコルに従って、RAMと比較して帯域幅が制限された通信チャネルを介して実行されるという事実によるものです。
- 最初にWrite_byteコマンドを送信します(ディスプレイ上のバイト座標)
- その後、確認を受け取ることができます
- そして、その後でのみバイトを送信できます。
同時に、ディスプレイは連続したバイトストリームを連続して受け入れ、ラインごとのビデオメモリを満たします。 この機能により、バッファー内の行が収集され、バイトのストリームごとにビデオメモリに送られます。
各テキストブロックは、テキストブロックの座標x 、 y (出力ウィンドウに対する)、テキストブロックのx、y座標に対するオフセットx_shift 、 y_shift 、フォントと、反転または非反転、点滅、太字、斜体、下線などの属性によって特徴付けられます。
ブロックブレーカー
ブロッキングマシンの動作部分は、バイトの入力ストリームで構成され、ブロックに分割されます。 不要なコピーを避けるために、テキストブロックは2つのポインターText_beginおよびText_endとしてテキストブロック出力マシンに渡される元の文字列の一部です。

図6.ブロックブレーカーOAの説明
ブレークダウンマシンは、対応するオートマトン変数に直接アクセスすることにより、テキストブロック出力 オートマトンの設定を制御します。
テキストをブロックに分割するためのオートマトンは非常に単純なOAです。オートマトンは存在せず、ポインタと変数変数のセットのみがありますが、一般的な原則、つまり2番目のオートマトンを開発する際に役立つ原則- テキストブロックを出力するためのオートマトンを検討します
OAが開発された後、それに必要な制御オートマトンを構成するのは簡単です
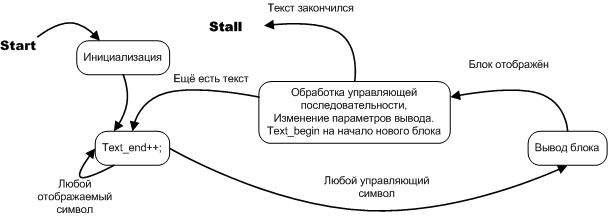
図7.テキストブレーカーの状態図
この場合の制御オートマトンは、アルゴリズムグラフ図と状態図の両方の観点からよく説明されていますが、オートマトンについて説明しているため、状態図を使用します。 状態図は、タスクの「自動化」を強調するだけでなく、通常のソフトウェアアルゴリズムを記述するより便利な代替方法であるという点で有用です。 問題の本質を見ると、状態図は広義のソフトウェアプロセスを記録する自然な形であり、アルゴリズムのグラフ図は、ほとんどの場合明白で、個別に必要としない実装機能をすでに含んでいる人工的な構造です記録された。 さらに、実装のこれらの機能自体(細かい詳細である場合)が主なアイデアを隠すことがあり、本当に重要な詳細とともに最前線に突き出ています。 次のパートでは、グラフ図で示されるアルゴリズムと状態図で示されるアルゴリズムの違いを示す良い例を示します。 状態図は、単純にプログラムコードに変換されます。
テキストブロック出力機
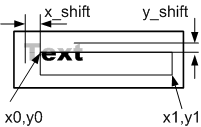
上記のように、制御シーケンスは次のテキストブロックの出力の座標も指定できます。 現在のテキストブロックの座標は、x、y変数によって設定されます。

図8.テキストブロックを表示するときに使用される座標
図の説明。
x_max、y_max-表示サイズ
x0、y0、x1、y1-出力ウィンドウの座標、Out_text関数のパラメーター
x_shift、y_shift-オフセットは、正と負の値を取り、すべてのテキストブロックの位置に影響します。
x、y-現在のテキストブロックの出力の座標。escコマンドで変更できます。 座標は、出力ウィンドウに相対的です。
前述のように、テキストは最初にラインバッファに出力され、その後、ラインバッファの内容がビデオメモリにコピーされます。
この例では5x7フォントを使用していますが、説明されているモジュールは任意のサイズの文字の処理をサポートしています。 その結果、大きな文字列アセンブリバッファが必要になる場合があり、これは多くの場合、エンベッダにとって重要な要素です。 バッファを最小化するには、一連の並列レジスタの代わりに、「垂直スキャン」を実行するものを使用できます。テキストブロック全体の垂直スキャン、つまり 行は、1ピクセルの高さとテキストブロック全体の幅で表示されます。

図9.テキストブロック出力の垂直スキャン
正しく実装された場合、このアルゴリズムのバリアントのパフォーマンスは、並列レジスタのパフォーマンスとほぼ同じですが、オーバーヘッドが依然として必要ですが、1文字あたり3バイトですが、幅256ピクセルの文字と高さ24ピクセルの文字を保存するラインバッファーは不要です。
これらの関係から、どの場合に節約が重要になるかを推定することができます。 この記事では、フルラインバッファーを使用したオプションをより単純なものと見なし、「実用的な」オプションの検討はこの記事の範囲外とします。
OA-UAペアの開発は常にOAの開発から始まり、OAの開発は最低レベルから始まるため、テキスト出力マシンのOAを構成します。
画面に文字を表示するためのオペレーティングマシンは、テキスト文字列が収集されるバッファで構成されます。 文字の幅はバイトの幅と等しくないため、新しい文字にはそれぞれ多少のシフトがあります。 シフトを実行するには、シフトレジスタを使用します。 ラインバッファが個々のラインに対応する並列レジスタのセットである場合、シフトレジスタには1つ必要です。 図からわかるように、2つのエンドツーエンドカウンターCurrent_byteとCurrent_shiftがあり、文字ごとに増加して、シフトの量とシフトされた文字を配置する場所を決定します。

図10 a。 テキストブロックレンダリングオートマトンの操作の説明。
ラインバッファに収集されたテキストは、ビデオメモリにスローされます。
説明された操作マシンの制御マシンは

図10 b。 テキストブロックレンダリングオートマトンの制御マシン。
// int Current_shift, Current_byte; // u1x * Text; u1x * Text_end; tFont * Current_font; // Width - u1x * Symbol_array; int Width; // int Line_width; //////////////////////////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////////////////////////// inline void Out_text_block () { Clear_line_buffer(); // while(Text < Text_end) { Width = Current_font->Width_for(*Text); Symbol_array = Current_font->Image_for(*Text); Line_width -= Width; // , if(Line_width <= 0) break; // 10 Out_symbol(); // Current_byte, Current_shift . Current_shift += Width; Current_byte += (Current_shift >> 3); Current_shift = Current_shift & 0x7; Text ++; }// while(Text < Text_end) Finalize: Out_line_buffer_in_videomemory(); return; }// inline void Out_text_block ()
ご注意 実際の設計では、この関数の変形はうまくいきませんでした。ここでは、わかりやすくするためだけに説明します。
このモデルでは推論プロセスを一般的に説明していますが、図11に示すことができる機能の一部は考慮していません。

図11.ラインバッファーおよびビデオバッファーへの出力の機能の説明。
この図から、ラインバッファとビデオメモリの両方にバイト編成があり、出力ウィンドウがビデオメモリのバイト境界と一致しないことがわかります。 つまり、バイトコピーを実行できるように、ラインバッファーへの出力は初期インデントを使用して行う必要があります。
さらに、テキストはウィンドウの境界の外側に左にシフトできます。この場合、テキストの一部は表示されず、テキストの表示された部分の境界は通過できるため、文字の一部が表示され、一部は表示されません。
言い換えれば、ラインバッファに出力するための操作オートマトンを開発する場合、次のことを考慮する必要があります。
a)オーバーラップするバイトがあります-ビデオメモリからの古いデータとラインバッファからの新しいデータの両方を含むバイトなので、ビデオメモリとバッファからのラインの交差するバイトは相補マスクによってマスクされ、その後、交差するバイトのデータはまたはによってオーバーレイされます。 交差しないバイトデータは、ビデオメモリ全体にコピーされます。
b)文字列バッファへのテキストの出力は、常に文字列バッファのゼロバイトから始まりますが、常にゼロ位置から始まるわけではなく、多くの場合、インデントCurrent_shift initialから始まります。
c)テキストは、x座標の値に関連付けられた初期シフトに加えて、左境界を超えてシフトでき、それを超えるテキストの部分は表示されません。
d)テキストを右側に表示できます。これには追加のマスキングが必要であり、適切なサイズで同じ文字を左右に表示できます。
操作オートマトンをコンパイルするときは、説明されているすべてのポイントを考慮する必要があるため、次の抽象化に移ります。 これ(抽象化のコンパイル)もオートマトンアプローチの一部です。これは、オートマトン理論から直接は従いませんが、問題の明確な視覚的表現を無視すべきではありません。 この抽象化は、テキストの場所に関するさまざまなオプションを描いた後に生まれました。
文字列のすべての文字はカテゴリに分類されます:

図12.出力ウィンドウを基準にした位置に応じて、画面に表示される文字のカテゴリ。
各カテゴリには独自の処理モードがあります。
- 出力ウィンドウに該当しない文字(1)は、単に無視されます。
- 出力ウィンドウに部分的または完全に落ちた最初の文字(2)は、出力領域を超えて突き出ているピクセルを切り取るために、タイプ3と比較して追加の左シフトが必要になる場合があります。 ドロップされたバイトとビットは単に失われます。

図13.初期シフトメカニズムの説明。 数字は、文字画像のピクセルのシーケンス番号を示します。
- タイプ(2)のシンボルと同様に、出力領域に完全に収まるシンボル(3)は、右へのシフトを必要とします。その値は、シンボルの座標に依存します。
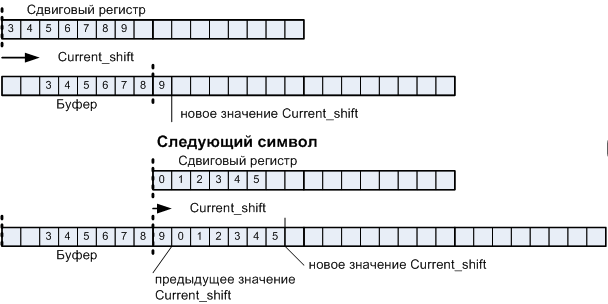
図14.滑りせん断機構の説明
最初の文字については、左シフトと右シフトが実行されるため、お金を節約する機会があります-「ドロップアウト」ピクセルの追加マスキングを使用して、対応する値の差によって実際のシフトを実行します。 マスクは表形式で取得されるため、実際には追加の計算は必要ありませんが、このアプローチでは、最初の文字の各バイトに対して最大7個のオフセットを保存できます。これにより、文字サイズ16 * 24で最大336個のオフセットを保存できます。

図15.ダブルシフト例外
シフトレジスタから、データはラインバッファにダンプされます。ラインバッファは、テキストブロックの出力の開始前にリセットされます。 データはまたはによってオーバーレイされます。

図16.ラインバッファの充填。
出力領域を超えて右に伸びるラインバッファのビット(カテゴリ2および3に属する可能性があり、アポストロフィでマークされている)は、画面の右側に収まらない文字の部分をさらにクリッピングする必要があります。

図17.文字2 'および3'の処理。
ファイナライズには、ラインバッファーからビデオメモリへの情報のコピーが含まれ、極端なバイトが交差する場合(上記参照)、ビデオメモリーから情報が読み取られ、ビデオメモリの対応するマスクでマスクされますビデオメモリにコピーされました。
上記に示したように、ソフトウェア実装のグラインドは最終段階で行われますが、モジュール全体が最適化プロセスで二重シフトを排除するというアイデアが既に生じたという事実にもかかわらず、明確にするために、最終的な形でソースコードを提供しますデバッグされたため、Out_symbol関数をわずかに変更するだけで済みました。 同じことがStart_lineおよびEnd_line変数の使用にも当てはまります。これは、上流のOut_text関数を開発する場合にのみ表示されますが、同時にそれらを追加してもOut_symbol関数の外観にわずかにしか影響しません。
ソースのフルバージョンは、Display.h / Display.cppファイル内のリンクにあります。 コンパイルされた例(Project1.exe)もあります。 Builder 6の下のプロジェクト自体
class tShift_register Symbol_buffer; vector< tShift_register > Line_buffer; // int Start_line, End_line; int Left_shift, Current_shift, Current_byte; // Width - u1x * Symbol_array; int Width; int bytes_Width; // bytes_Width, int bytes_Width_after_shift; inline void Out_symbol () { for(int Current_line = Start_line; Current_line <= End_line; Current_line++) { Symbol_buffer.Clear(); //////////////////////// // 2 3 Out_symbol, if(Left_shift)// 2 { // 8 int Start_symbol_byte = Left_shift >> 3; // void tShift_register::Load(int Start_index_in_destination, u1x * Source, int Width); Symbol_buffer.Load(0,Symbol_array + bytes_Width * Current_line + Start_symbol_byte,\ bytes_Width - Start_symbol_byte); // .15 // void tShift_register::Shift(int Start, int End, int Amount); Symbol_buffer.Shift (0, bytes_Width_after_shift, Current_shift - (Left_shift & 7) ); Symbol_buffer[0] &= Masks_array__left_for_line_buffer[ Current_shift ]; // .16 Line_buffer[Current_line].Or(Current_byte, &Symbol_buffer[0], bytes_Width_after_shift ); } else // 3 { Symbol_buffer.Load(0,Symbol_array + bytes_Width * Current_line, bytes_Width); // .14 Symbol_buffer.Shift(0, bytes_Width_after_shift, Current_shift); // .16 Line_buffer[Current_line].Or(Current_byte, &Symbol_buffer[0], bytes_Width_after_shift ); } }// for(int Current_line = Start_line, Current_line <= End_line, Current_line++) }// inline void Out_symbol ()
次に、制御機に目を向けます。 彼の仕事のアルゴリズムは、上記のOAの説明から直感的に明らかです。 既に述べたように、状態図は、最小限の詳細で図面を詰まらせることなく本質を示すことができる自然で最小限の記述アルゴリズムであるため、UAのアルゴリズムは状態図の形式で記述します。

図18.状態図は、古典的なグラフ図の優れた代替手段です。
この状態図で記述されたアルゴリズムを使用すると、古典的な構造構造(ループとブランチ)で構成されるプログラムコードを簡単に作成できます。 この有向グラフは一般に周期的ではないため(つまり、以前の状態への遷移が含まれないため)、これは特に難しくありません。 例外は、ループで簡単に展開されるループのペア(タイプ1およびタイプ3の状態)です。ただし、ノードを巡回する巡回パスを持つより複雑なグラフで記述されているマシンでも、構造プログラムを作成できますが、一見するとこのタスクは扱いにくく面倒に思えるかもしれません。強調してください:状態図は、プログラムプロセスの観点から完全に同一の状態ブロックを処理するため、その関係は明確かつ明確に定義されているため、goto演算子を使用して、言語の構造に違反することなく状態を切り替えることができます。つまり、goto演算子を使用してオートマトンの状態間の遷移を行う場合、これはループとブランチと同じ、それ自体が新しい構造です。この構造は状態間の遷移、およびそれはプログラミングツールを豊かにします。同時に、このプログラム構造のフレームワーク外でgoto演算子を使用することは、構造化されていない、つまり プログラムコードの構築元となる標準構造の破壊。これは重要なポイントです。人々がそれに慣れて恐れることをやめるには時間がかかるかもしれませんが、新しい構造設計がプログラマーのツールキットで正当な位置を占めると信じたいです。
class tShift_register Symbol_buffer; vector< tShift_register > Line_buffer; tVideomemory Videomemory; // int Start_line, End_line; // int Left_shift, Current_shift, Current_byte; // u1x * Text; u1x * Text_end; tFont * Current_font; // Out_text_block // Width - u1x * Symbol_array; int Width; int bytes_Width; // bytes_Width, int bytes_Width_after_shift; // // int Line_width; //////////////////////////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////////////////////////// //////////////////////////////////////////////////////////////////////////////// inline void Out_text_block () { Clear_line_buffer(); //////////////////////////////////////// // Type_1: // while(Text < Text_end) { Width = Current_font->Width_for(*Text); // if(Left_shift >= Width) { Left_shift -= Width; Text++; } else goto Type_2; }// while(Text < Text_end) // return; //////////////////////////////////////// Type_2: // Current_byte = Current_shift >> 3; Current_shift = Current_shift & 7; Symbol_array = Current_font->Image_for(*Text); bytes_Width = (Width + 7) >> 3; bytes_Width_after_shift = (Width + Current_shift + 7) >> 3; Line_width -= (Width - Left_shift); // ? if(Line_width <= 0) { Width -= Left_shift; goto Type_4; } Out_symbol(); // Left_shift Width -= Left_shift; Left_shift = 0; // Text++; //////////////////////////////////////// Type_3: // ? while(Text < Text_end) { // Current_byte, Current_shift . Current_shift += Width; Current_byte += (Current_shift >> 3); Current_shift = Current_shift & 0x7; // Width = Current_font->Width_for(*Text); Symbol_array = Current_font->Image_for(*Text); bytes_Width = (Width + 7) >> 3; bytes_Width_after_shift = (Width + Current_shift + 7) >> 3; Line_width -= Width; // ? if(Line_width <= 0) goto Type_4; Out_symbol(); Text++; }// while(*Text < Text_end) Current_shift += Width; Current_byte += (Current_shift >> 3); Current_shift = Current_shift & 0x7; // goto Finalize; //////////////////////////////////////// // 4 2' 3' Type_4: Out_symbol(); Current_shift += (Width + Line_width); Current_byte += (Current_shift >> 3); Current_shift = Current_shift & 0x7; for(int Current_line = Start_line; Current_line <= End_line; Current_line++) { Line_buffer[Current_line][Current_byte] &= Masks_array__right_for_line_buffer[Current_shift]; } Finalize: Out_line_buffer_in_videomemory(); return; }// inline void Out_text_block ()
このアルゴリズムは簡単で有機的で、文字通り1対1で、アセンブラーで実装されています。
Start_line、End_line、Left_shift、Current_shift、Current_byteなどの初期値は、ブロック出力プロセスの初期化段階で設定されます。これは、自動ブロッキングマシンで発生します。これがどのように起こるか考えてみましょう。 1行を1つのブロックではなく複数のブロックで表示できることを思い出してください。したがって、各ブロックを表示するときは、図8に示すパラメーターを扱います。
各テキストブロック(x、y)の座標は個別に設定できます(escシーケンス、ただし違いがあります-カーソルの座標は親しみではなくピクセルで設定されます)。これらは、出力ウィンドウの座標(x0、y0、x1、y1)に対して相対的にカウントされます。オフセットx_shift、y_shiftは、各テキストブロックの座標に影響します。出力ウィンドウに完全に収まるすべてのテキストブロックは、負のオフセットが指定されている場合でもトリミングされません。出力ウィンドウに収まらないもののみがカットされます。負のバイアス自体は、テキストブロックをトリミングするための基準ではありません。説明した動作を実装するために、各テキストブロックの出力には、次の変換が伴います。
パラメータの水平方向の計算を図に示します。 19

図19.水平方向のパラメーター計算の説明
値x_shiftは表示されていませんが、xに追加することで補正されます。パラメータx_byteおよびStart_shiftは、ビデオメモリへの出力中に使用されます。これは、図4に示すスキームに従って実行されます。 20

図20.ビデオメモリへの出力。
引き出しプロセスは明らかですが、説明は不要ではありません。
- 左のバイトが交差する場合、ビデオメモリの対応するバイトが読み取られ、マスクされ、ラインバッファーの左端のバイトに重ねられます(ラインバッファーへの出力プロセスで既にマスクされています)。
- 右端のバイトが交差する場合、ビデオメモリの対応するバイトが読み取られてマスクされ、ラインバッファの右端のバイトに重ねられます(パッドマスクによってマスクされます)。
- その後、ラインバッファー全体がストリームによってビデオメモリにコピーされ、ラインバッファーのラインStart_lineがバッファーのラインyに移動し、図20に示すように、それぞれEnd_lineとy + End_line-Start_lineまで続きます。
Start_lineおよびEnd_lineパラメーターは、以下に示す考慮事項に基づいて決定されます。
図 21。

図 21.パラメーターの垂直方向の決定。
// // //////////////////////////////////////////////////////////////////////////////////// if(x1 < x0) { int temp = x0; x0 = x1; x1 = temp; } if(y1 < y0) { int temp = y0; y0 = y1; y1 = temp; } if(x0 < 0) { x_shift += x0; x0 = 0; } if(y0 < 0) { y_shift += y0; y0 = 0; } if(x1 > x_max) { x1 = x_max; } if(y1 > y_max) { y1 = y_max; } // inline bool Init_text_block() { // //////////////////////////////////////////////////////////////////////////////////// x += ( x0 + x_shift); y += ( y0 + y_shift); // //////////////////////////////////////////////////////////////////////////////////// if (x < x0) { Left_shift = x - x0; x = x0; } else { Left_shift = 0; } if(x >= x1) return false; x_byte = x >> 3; Start_shift = Current_shift = x & 7; Current_byte = 0; Line_width = x1-x; // //////////////////////////////////////////////////////////////////////////////////// if (y < y0) { Start_line = y0 - y; y = y0; } else Start_line = 0; if(Start_line >= Current_font->Height()) return false; if( (Current_font->Height() - Start_line) < ( y1 - y) ) End_line = Current_font->Height() - 1; else End_line = Start_line + (y1 - y) - 1; return true; }
実際には、座標x0、y0、x1、y1によって制限される出力ウィンドウ全体ではなく、テキストブロックのコンテンツのみが表示されることに注意してください。必要に応じて、ウィンドウ全体を個別に事前クリーニングできます。
ソーステキストのブロックへの自動分割。
状態と遷移図はすでに図7に示されています。
/////////////////////////////////////////////////////////////////////////////////// /////////////////////////////////////////////////////////////////////////////////// /////////////////////////////////////////////////////////////////////////////////// /////////////////////////////////////////////////////////////////////////////////// /////////////////////////////////////////////////////////////////////////////////// /////////////////////////////////////////////////////////////////////////////////// // void Out_text_block (); inline void Control_processing (); void Out_text (int arg_x0, int arg_y0, int arg_x1, int arg_y1, int arg_x_shift, int arg_y_shift, unsigned char * argText) { // // ... while(*Text_end) { ////////////////////////////////////// state__Inside_text_block: while(1) { switch(*Text_end) { // case '\0': case '\n': goto state__Out_text_block; } Text_end++; } ////////////////////////////////////// state__Out_text_block: if( (Text_begin != Text_end) && Init_text_block()) Out_text_block(); Text_begin = Text_end; ////////////////////////////////////// state__Control_processing: if(*Text_end == 0) return; // Control_processing(); }//while(*Text_end) }//void Out_text (int arg_x0, int arg_y0,
そのため、一般的には問題の解決策が見えます。リンクにより、プログラムのソースと作業バージョン(Project1.exeファイル)を確認できます。解決されていない唯一の問題は、ESCシーケンスを解析してコマンドを実行するControl_processing関数の構造です。これは別のタイプのオートマトンに基づいています。これは、上記で検討したものとは著しく異なりますが、同時にソフトウェアオートマトンの古典であるシンボリックオートマトンです。このようなオートマトンの実装については、次のいずれかの部分で検討します。
1つの記事のフレームワーク内で、Automataプログラミングのような多目的なトピックを説明することは不可能です。この記事は入門書であり、最初の一連の記事のスケッチです。読者に「プログラミングのオートマトン文化」を紹介したいと思います。オートマトンアプローチの中心的な要素は、状態図と遷移を使用して、時間内に発生するプロセスを記述するためのオートマトンメソッドです。これは、アルゴリズムを記述するための代替形式です。次の記事では、状態図と遷移について説明します。