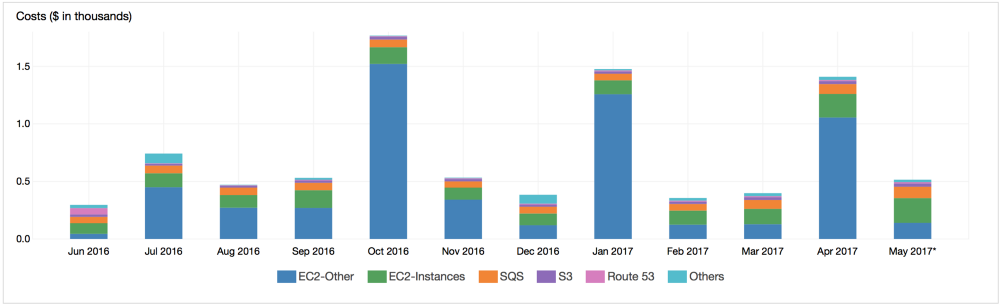
過去12か月間のAWS Cronitorの費用
Cronitorが 2015年1月にAWSに移行してから最初の30日間で、ホスティング、データ転送、ドメイン名に対して535ドルの支払いを回収し、64.47ドルを支払いました。 それ以来、サービスの消費量を増やし、インスタンスをアップグレードし、サービスを追加しました。 高価な拳銃であるというAWSの評判にもかかわらず、アカウントは収益の12.5%のままでした。 自分で見てください。
安価なAWSによる打撲傷
すぐに、私たちのアイデアにいくつかの見込みがあることが明らかになりました。 私たちは、サイドプロジェクトから本格的な中小企業に水準を引き上げる必要があることに気付きました。 目標は高可用性ではなく、単一の2 GB Linodeでの以前の構成と比較した場合の可用性の向上のみでした。 受信したテレメトリを失うことなく、データベースを再起動したかっただけです。 特別なことは何もありません。 最初のインストールは非常に簡単でした:
- エルブ
- SQS
- 両方ともus-west-2にある、Webアプリケーションとデータ収集を備えたt2.smallインスタンスのペア
- MySQLが動作する1つのm3.mediumインスタンスと、障害を検出してアラートを送信したデーモン
ダウンタイムはほとんどなく、移行を2時間で完了し、本当に満足しています。 ビールを注いだ。 お祝いのツイートが始まりました。
喜びは短命でした。
問題1:ELBが失敗する
ユーザーは、タスク、プロセス、およびデーモンが動作するときにテレメトリpingを送信します。 今日のNTPを使用すると、平均的なサーバーの時間は非常に正確になり、毎秒、毎分、毎時、一日の始めにトラフィックが急増し、基本トラフィックの100倍を超えます。
移行の直後に、ユーザーは定期的なタイムアウトについて不平を言うようになったため、サーバー構成とELBログの履歴を再確認することにしました。 トラフィックのジャンプが1秒あたり100リクエスト未満であるため、問題はELBにあるという考えを捨て、独自の構成でエラーを探し始めました。 最後に、サービスを継続的にpingするテストを実行しました。 UTC 00:00の少し前に開始し、真夜中の少し後に終了し、ELBログにまったく該当しないリクエストの失敗を確認しました。 個別のインスタンスが使用可能であり、要求キューは作成されませんでした。 ロードバランサーレベルで接続が切断されていることが明らかになりました。おそらく、トラフィックのジャンプが大きすぎて短すぎて、より大きな負荷にウォームアップできないためです。 AWSテクニカルサポートプランのコストが高いため、ELBのサイズを手動で増やすように依頼することはできなかったため、代わりにDNSを使用して循環クエリを実行し、ロードバランサーの必要性を完全に排除することにしました。
学んだ教訓:
- 復元力のあるロードバランサーなどのクラウドベースのソリューションは、通常、通常の中規模の使用向けに設計されています。 あなたが平均とどう違うかを考えてください。
問題2:CPUローンの残高を知る
公式ウェブサイトによると、負荷が時折増加する場合、負荷スパイクをサポートするT2インスタンスのラインは費用対効果が高くなります。 しかし、そこに書きたいと思います:CPUの25%の一定の負荷でインスタンスを実行すると、CPUクレジットの残高が枯渇し始め、それが終了すると、本質的にRasperry Piの処理能力が得られます。 これに関する警告は表示されず、CPU%は電力の低下を反映しません。 初めて、ローンの残高を使い果たしたため、他の何らかの理由で接続が切断されたと判断しました。
学んだ教訓:
- 何かが非常に安く提供されている場合、これには十分な理由があり、これを理解する必要があります
- T2インスタンスは自動スケールグループでのみ使用する必要があります
- 念のため、クレジット残高が100を下回った場合に警告するCloudWatch通知を作成してください
問題3:小さな活字で書かれていること
昨年のre:Inventカンファレンスで、Amazonはリザーブドインスタンスサービスを更新しました。GoogleCloudからのより有利な条件に対応する可能性があります。 プレスリリースでは、リザーブドインスタンスはより安価で、ゾーン間で転送できると述べています。 これはすごい!
10月に最後のT2インスタンスを閉じるときが来たとき、これらの安価で柔軟性の高い12か月の予約で新しいM3を展開しました。 4月にいくつかの大規模な顧客が現れた後、インスタンスのレベルを再びM4.largeに上げることにしました。 10月の予約から6か月が残っていたので、いつものように販売することにしました。 そして、これらの安価で柔軟性の高い予約の価格は、あなたがそれらを転売することはできないということであるという厳しい真実を学びました。
学んだ教訓:
- 何かが非常に安く提供されている場合、これには十分な理由があり、これを理解する必要があります
- オファーの条件を常に2回読んでください。 AWSの請求は非常に複雑です。
実際のAWS価格の確認
今日、私たちのインフラストラクチャは非常にシンプルなままです。
- クラスターM4.largeは着信テレメトリを収集します
- M3.mediumクラスターはWebアプリケーションとAPIを提供します
- 監視デーモンと警告システムを備えたワーカーM4.large
- MySQLおよびRedis用のM4.xlarge
SQS、S3、Route53、Lambda、SNSなど、多くのマネージドサービスを引き続き使用します。
弾性計算
すべてのサービスで事前予約を部分的に使用しています。
インスタンスの場合と同様に、毎月の請求書の2/3がセキュリティで保護されたIOPS(1秒あたりの入出力操作)に費やされていることに気付くかもしれません。 契約の単なる記録であるほとんどのクラウドメトリックで保証されたIOPSとは異なり、これはコストのかかる実際のサービスです。 また、ディスクパフォーマンスが重要なホストのEC2予算のかなりの部分を占めます。 IOPSを支払わない場合、タスクはキューに入れられ、リソースの解放を待ちます。

「アラーム月」の意味を尋ねないでください。
SQS
SQSを広範囲に使用して、着信テレメトリpingとシステムステータスチェックサービスからの結果をキューに入れます。 移行の数か月後、1つの最適化を行いました-最大バッチ測定値。 メッセージの数ではなく、リクエストの数に対して支払うので、これによりコストが削減され、メッセージ処理が大幅に高速化されます。
移行中、SQSがデータ収集パイプラインの唯一の障害ポイントであることが心配でした。 リスクを回避するために、各ホストで小さなデーモンを起動して、障害発生時にSQS書き込みをバッファリングして再試行しました。 メッセージバッファリングは2.5年に1回だけ必要だったため、1)実行する価値は100%ありました。 2)SQSはus-west-2リージョンで信じられないほどの信頼性を証明しています。

ラムダ
当社のHealthchecksサービスは 、以下にリストされている地域のLambda Workersに一部組み込まれています。 Lambdaには寛大な無料レベル(無料ティア)があり、これは各地域に個別に適用されることに注意してください。 現時点では、無料利用枠は「無期限」と宣伝されています。

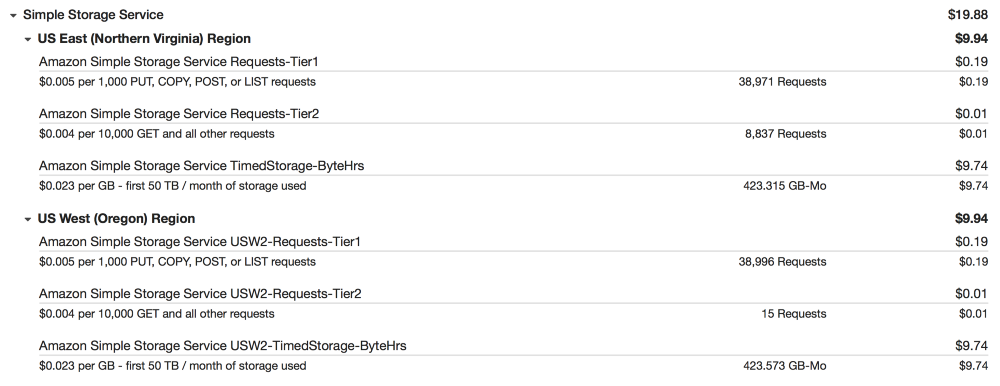
S3
データベースイメージのバックアップコピーを作成し、災害発生時の回復のためにus-east-1でレプリケーションを行ってS3にログオンします。
AWSに対する専門家のアドバイスは、災害復旧の場合、EBSバックアップとスナップショットが不可欠ですが、リージョンの真に深刻な混乱は通常、単一のサービスに限定されないということです。 インスタンスを起動できない場合、ファイルを別のリージョンにコピーできない可能性が高くなります。 だから、事前に十分にやってください!
結論として
AWSで大規模な企業プロジェクトや投資プロジェクトを扱ったことがあるので、ここで大企業を始められることを個人的に保証できます。 彼らは素晴らしいツールと素晴らしいオブジェクトを作成しましたが、それらはすべて一緒に取り扱われ、あなたが触れたものすべてのためにあなたからお金を取ります。 これは危険です。食欲を抑え、制限する必要がありますが、必要に応じて、注文によってリソースが利用可能になったときに、中小企業をより多くのものに成長させる機会が与えられます。 一時停止して、それがどの程度健康であるかを考えてから、再び仕事に戻ることもあります。