- Ironははるかに高速になり、GPUでモデルを簡単に計算できます
- ニューラルネットワークには優れた無料のフレームワークがたくさんあります
- 以前の誇大広告に麻薬がかかっていたため、企業はビッグデータを収集し始めました。
- 一部の地域のニューロンは人間に近づいており、一部の地域ではすでにいくつかの問題を解決することを超えています(ここでシャベルが販売されている場合、緊急にバンカーを掘る必要があります)
しかし、これを以前と同様に管理することは困難です。より多くの数学があります。 そして、あなたは物理数学部の出身であるか、問題になっているものを理解するために2〜3年以内に座って2〜3千の問題を解決します。 「PHP / JavaScriptで3日間でプログラミングする」という本に目を通すことで、電車の中でインタビューへの道を見つけることは、失敗することはありません。

ウォッカの箱であっても、ニューラルネットワークモデルを「書き落とす」ことはできません。 多くの場合、公開されているモデルが突然うまく機能しないのはデータ上であり、TerverとMatanを理解する必要があります
しかし、yyyyは基本をマスターしたので、興味深い強力なアルゴリズムを実装するさまざまな予測モデルを構築できます。 そして、ここで舌が包み込み、口から落ち始め、彼の左目をつかみます...
理論と実践の美しさ
リレーショナルデータ処理として「AK-47」レベルの領域にまで適用されたこのような一見直感的でさえ、かつて非常に有名なIBM会社はかつて拷問を受け、実際、「言語」の有名な作成者である古いCoddバズーカ用」、4辺すべての散歩用。 どうしたの? Coddは、IBMの分散SQLは悪であり、厳密で不完全ではなく、厳密で美しい理論に準拠していないと主張しました:-)それでも、私たちはこれまでのところSQLを使用しています...
機械学習でも同じことが起きています。 一方では、毎週またはさらに頻繁に、星の王子さまの星座のチューリング空間のハイパーキャシャロットに対するGyroDragonsの突然の勝利についての科学的な出版物が発行されます(ジャイロスコープが生理学的ボールに入れられています)質問の意味を以前のプロトタイプより5%よく理解している人-しかし、実際には、本質を理解するのに気の利いたことではありません 。 同時に、 ニューラルネットワークに対する最強のグループ暴力と、巨大な次元の空間での強化でのトレーニングというまさにアイデアを通じて、彼女は二次元ゲームでアタリを突然打ち始め、おそらく誰もがGoのチャンピオンに対するニューラルネットワークの勝利について長い間知っていました。 一方、ビジネスはこの地域がまだ非常に未加工であり、急速な成長段階にあることを認識し始めており、人々の問題を効果的に解決するために適用できるケーススタディはほとんどありません。 残念ながら、さらに多くの学術的なおもちゃがあります:ニューロンは顔を老化させ、ポルノを生成し(グーグルしないで、1日間効力を失います)、 Webページデザインのグリッチなレイアウトを作成します 。

または、ある日、ニューラルネットワークによって作成されたこの女の子を取り、招待しますか? 素晴らしい経験は、一生思い出に残るでしょう。
そして、パターン認識などのいくつかの分野での真の、途方もない成功は、何百もの層から巨大な畳み込みネットワークを訓練するコストで達成されました-おそらく業界の巨人だけが余裕がある:Google、Microsoft ...状況は機械翻訳でも同様です:大量の非常に大きなデータ量と大きな計算能力が必要です。
同様の状況は、 リカレントニューラルネットワークの場合です 。 「前例のないパワー」と一連のイベントを予測し、ハードドラッグの影響下で作家のナンセンスに類似したテキストを生成する能力にもかかわらず、彼らは非常に、非常にゆっくりと学習し、不均衡なコンピューティングリソースが必要です。
言語ニューラルモデルは今まで以上に興味深いものになりましたが、多くはテキストの大量のコーパスと、計算言語を必要としますが、これはロシア語では特に困難です。 そして物事は前進しており、ロシアだけでなく埋め込みがすでに見つかっていますが、 1000キログラムの聖書とうなり声を上げるゾウの群れを引きずらさずに生産の複雑な言語モデルの一部としてそれらを有効に使用する方法は明らかではありません。

システム管理者を理解せずにHadoopを展開するのは簡単だと思いますか? この群れで良くなり、うなり声を上げます:)
素晴らしい、 本当に素晴らしい 、希望は、数年前に現れた生成的敵対ネットワーク( GAN )によって与えられます。 画像の失われた部分の復元、解像度の向上、顔の年齢の変更、インテリアの作成、バイオインフォマティクスへの適用、一般的なデータへの洞察の取得、特定の条件によるデータの生成など、驚くべき機能にもかかわらず:(例えば、美しい司祭を持つ若い女の子を見たい)むしろ、それはまだ多くの真剣な科学研究者です。
したがって、「ひざの上で」深く学習し、何か役に立つものがすぐに出てくるという事実に頼る価値はありません(「o」の文字を強調)。 あなたは多くのことを知り、「あなたの顔の汗」に取り組む必要があります。
MLビジネスケーススタディ-結論
面倒な理論を捨てて、よく落ち着いて、eコマースとCRMの理論的に有用なアルゴリズムのほんの一握りが残っているのを見ることができます。
- 何かをいくつかのクラスに分類(スパム/非スパム、購入/購入しない、終了/終了しない)
- パーソナライズ:すでに他の人を購入した後、どのような製品/サービスを購入しますか?
- 数値への回帰:パラメータに従って車の価格を決定し、車の価格、その特性に従ってクライアントの潜在的な収入を決定します
- 何かを複数のグループにクラスタリングする
- GANを使用してビジネスデータセットを強化するか事前トレーニングする
- あるシーケンスの別のシーケンスへの変換:次のベストオファー、顧客ロイヤルティサイクルなど

「金髪」の頭には(これは集合的なイメージで、女の子は気分を害することはなく、「金髪」のような男性がいます)脳はなく、2本の耳は細い糸で直接つながっています。 糸を切ると、耳が落ちて床に落ちます
一方、ビジネスマネージャーは、「まあ、これらのアルゴリズムのアプリケーションを見つけてください。ファンには提供しないでください!」という言葉を使って、数学の教科書を朝から晩まで開発者に投げ込むしかありません。少なくともpythonでは、適切なコードを記述できます。
テクニカルサポートでニューラルネットワークを使用する方法とその理由
一方で、ニューラルネットワークをトレーニングするのに十分な収集済みの「ビッグデータ」(数万例)がすでにあるという事実に導かれ、他方では、事前に質問や提案で顧客からのリクエストの流れを常に定期的に分類するビジネスタスクがあります責任のある従業員への後続のルーティングのためのトピックの特定のリスト(数十)。
ニューロンを選択するアルゴリズムを選択する
トートロジーについては申し訳ありませんが、テキスト分類: ベイジアン分類 、 ロジスティック回帰 、 サポートベクトルマシンの古典的で有名なアルゴリズムを検討しましたが、ニューラルネットワークを選択しました。これが理由です。
- レイヤーの因数分解と非線形性により、プレーンワイドモデルよりも少ないレイヤーでより複雑なパターンを近似できます。
- 十分な数のトレーニングサンプルを備えたニューラルネットワークは、「設計どおり」の新しいデータでより適切に機能します( 一般化の方が優れています)
- ニューラルネットワークは、古典的なモデルよりもうまく機能し、テキストを事前解析して、それらから単語と文の間の意味関係を分離するモデルよりも優れています。
- 人間の脳内のアルコールの効果( dropout )に似た正則化を使用する場合、ニューラルネットワークは適切に収束し、再トレーニングの影響をあまり受けません。
その結果、かなりシンプルになりましたが、結局のところ、実際のアーキテクチャでは非常に効果的でした。
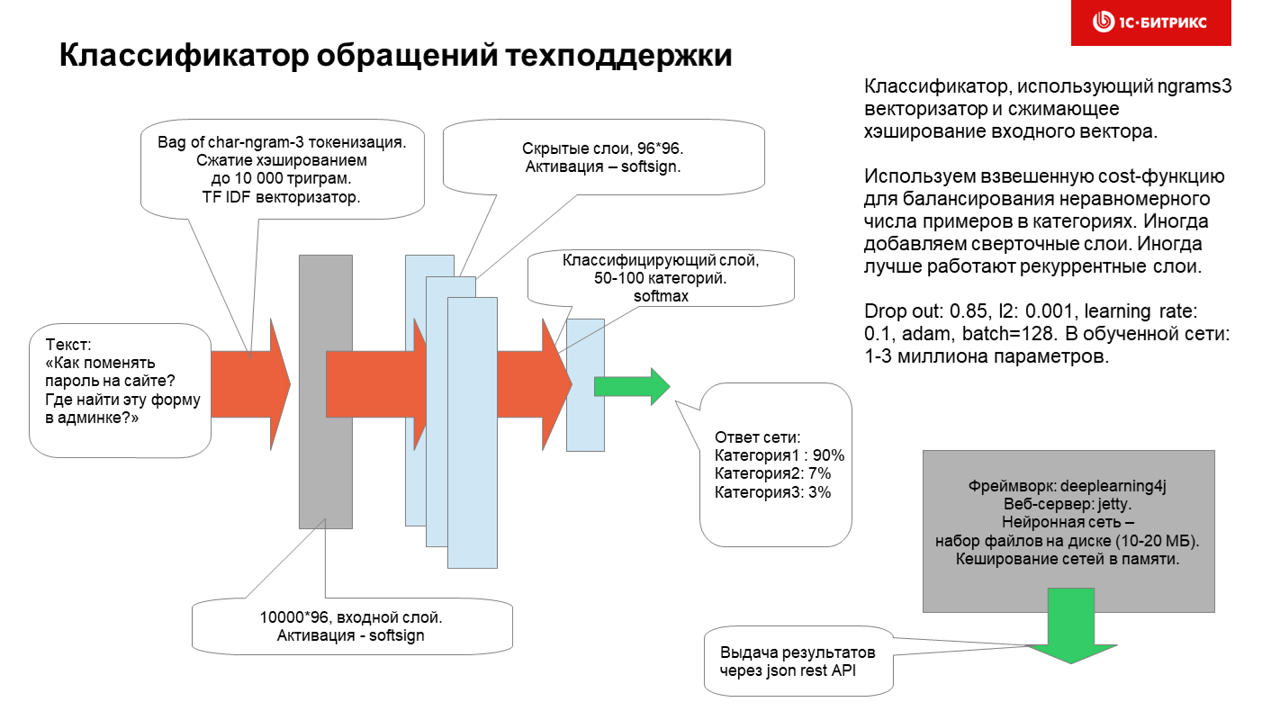
ニューラルネットワークを1時間半学習し(GPUを使用せず、GPUがはるかに高速です)、トレーニングデータセットのカテゴリに〜100kの質問をバインドします。
カテゴリの分布は非常に不均一ですが、カテゴリが不十分なトレーニングサンプル(見出しの数十から数百)に重みを割り当てる実験では、ニューラルネットワークのパフォーマンスは特に向上しませんでした。
市民は言語の山でネットワーク入り口に送られますが、それには以下が含まれる場合があります。
- PHPコード
- レイアウト
- マットリマットスラング
- 問題、タスク、アイデアの説明
- 製品内のファイルへのリンク
データが事前に処理されておらず、char3 ngramsがそのまま作成されている場合、ニューラルネットワークがより適切に機能することが判明しました。 この場合、タイプミスに対する抵抗は問題なく機能し、ファイルへのパスの小さな部分、コード、または任意の言語のテキストの1つまたは2つの単語を入力でき、見出しは非常に適切に決定されます。
内側から外側への仕組みは次のとおりです。
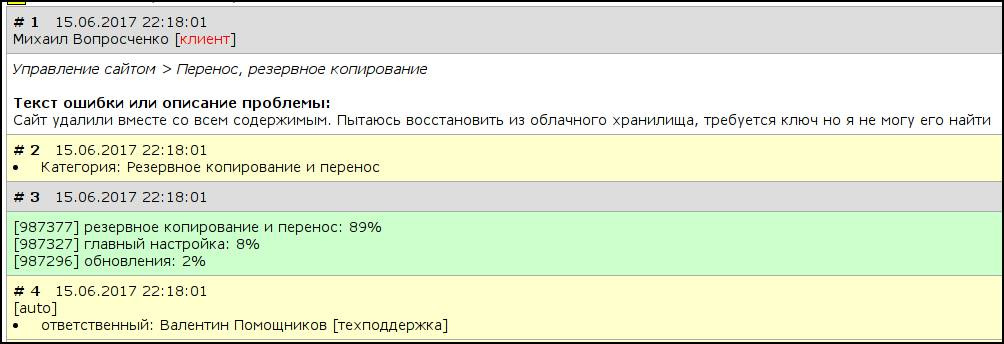
ニューラルネットワークの分類が不確実または間違っている場合-人によって保険がかけられ、上訴は手動で再割り当てされます。 分類精度はまだ85%であり、もちろん増やすことができます。しかし、現在のソリューションでも多くの工数が削減され、顧客サービスの品質が向上し、ニューラルネットワークはポルノ世代のおもちゃではない例です-彼らは人々の隣で働くことができますと非常に役立ちます。

このアストロドロイドの頭には非常に強力なニューラルネットワークはありませんが、それでも、時にはミスを犯し、映画のサガの6パート(または7パート)よりも多くのメリットをもたらします
今後の計画
現在、Kerasで他のテキスト分類子アーキテクチャを実験しています:
-再発ネットワークに基づく
-畳み込みネットワークに基づく
-バッグオブワードに基づく
多層分類器は、1つのホットキャラクターベクトル(シェルシンボルの小さな辞書から)が入力される入力で最適に機能し、次にグローバル最大/平均プーリングパスを持つ1D畳み込みのいくつかの層とsoftmaxを持つ通常のフィードフォワード層が出力にあります。 この分類子は完全な方法で教えることができず、 バッチ正規化でさえ助けにはなりませんでした(女の子をあまり見ていないし、教師に耳を傾ける必要がありました)-しかし、層ごとに順番に学習することで適切に訓練することはまだ可能でした。 どうやら、Javaのテンソルの代わりに、Keras / python / Tensorflowのテンソルをプロダクションで使用する方法を見つけたときに、このアーキテクチャを展開して戦い、マネージャーとクライアントをさらに幸せにします。
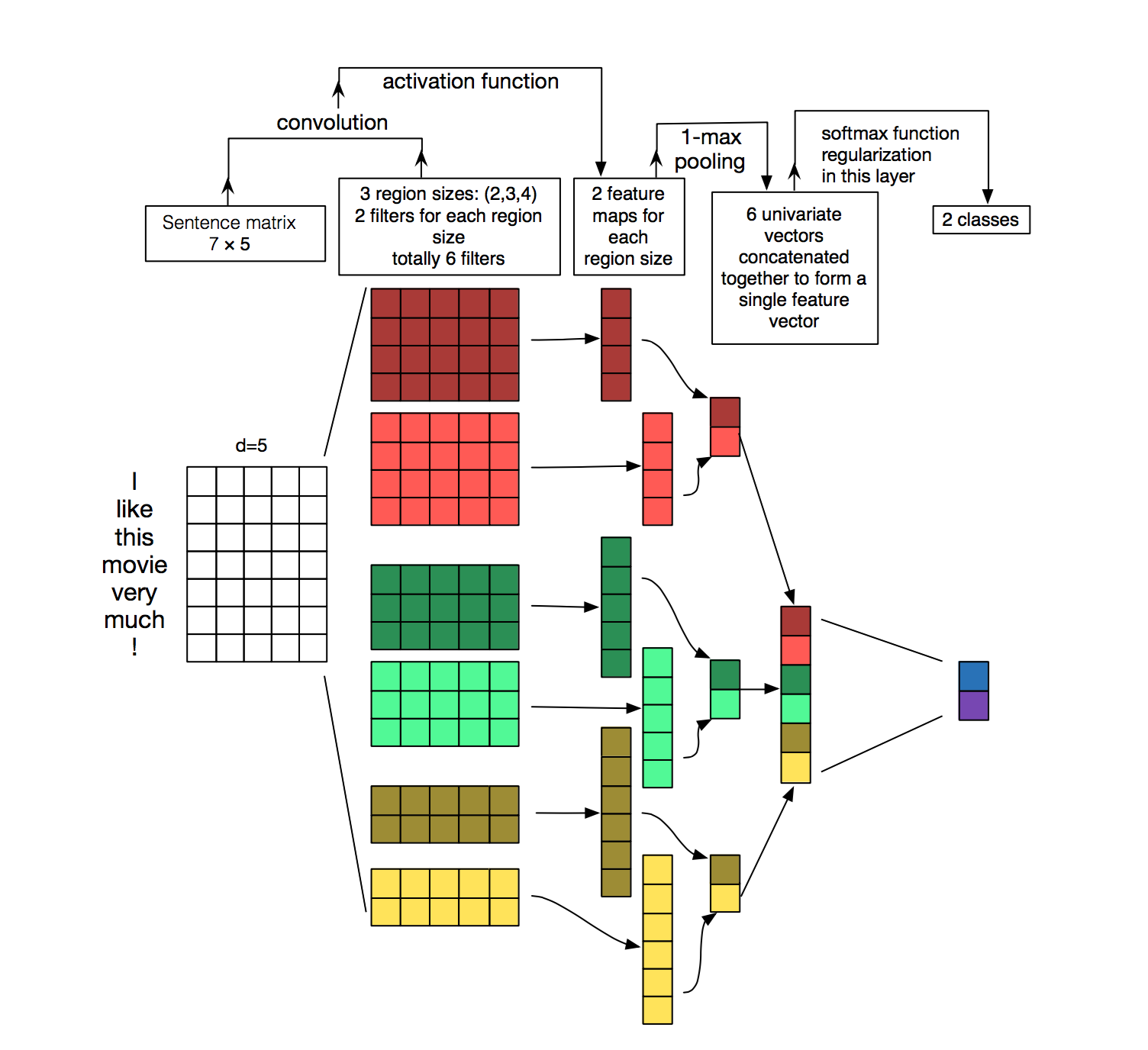
誰もが1D畳み込みを理解しているわけではありません。 私たちは、1-2-3-nの文字の連鎖を定義するカーネル(畳み込みカーネル)、「ala」マルチnrgamモデルを作成したと言うことができます。 私たちの場合、ウィンドウ9での1D畳み込みが最適に機能します。
投稿の最後に、親愛なる友人たち、MLとニューロンの前でシャッフルしないでください。それらを自由に使用してモデルを使用、構築、トレーニングしてください.AIがどのように効果的に機能するか、AIが人々からルーチンを削除し、サービスの品質を向上させる方法をご覧になると思います。 皆さん、そして最も重要なことには、ニューラルネットワークの急速な収束に幸運を! 優しくキスします。