何が変わったのか-今では記事を書くだけでなく、会社のブログでそれを行うことができます。 そして、できれば2回以上。 これでサモピアは終わりました。

私のリポジトリは、 アンカーモデリング方法論に基づいています。 2013年、この方法論の選択は、多くの点で信仰の飛躍でした。 今、ほぼ4年後、ジャンプが成功したと言うことができます。 最初の記事では、アンカーモデリングに関する多くの議論がありました。 現在、これらの議論は真実のままですが、背景に消えていきました。
これまで、Anchor Modeling + Verticaを使用する主な理由は次のとおりです。ほとんど無限の成長が可能です。 ボリューム、フローレート、および多様性の増加-一般に3V(ボリューム、速度、バラエティ)と呼ばれ、ビッグデータを特徴付けるすべて。
ストレージが小さなキノコのピッカーであると想像してください。 それは1つの引数で始まり、それから成長し始め、メートルごとにカバーし、単調なモンスターが得られるまで木を編む...その成長は止まらない...止まらない。
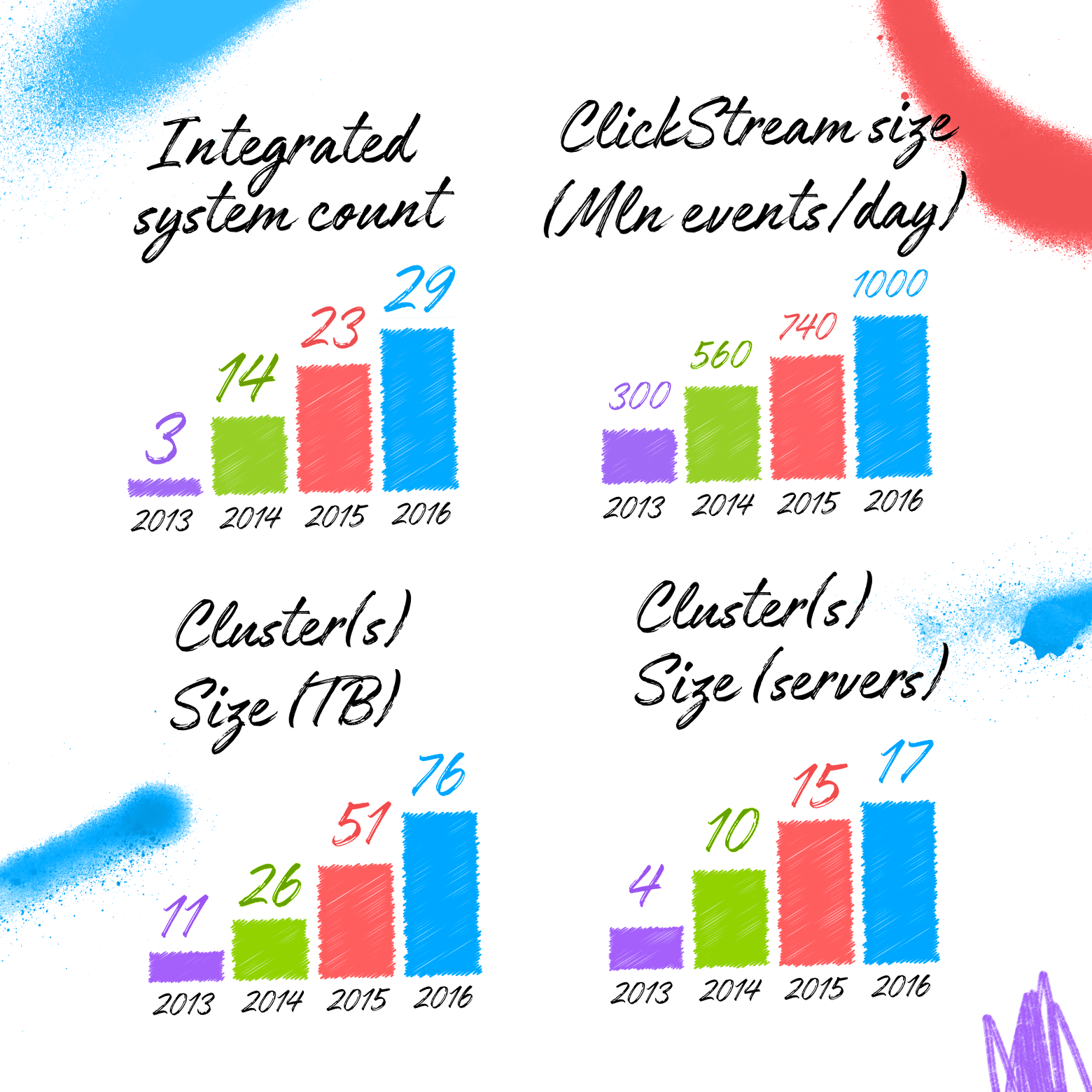
リポジトリアーキテクトのサイトを想像してください。 開始時に、おおよそのデータ量、統合可能なシステム、データ分析アルゴリズムを評価できると便利です。 その後、状況に応じてデータモデルと処理プラットフォームを選択できます。 この場合、Vertica + Anchor Modelingの選択が最適であるという事実ではありません。
エッセンスワン-アンカー

アンカーは名詞であり、現実世界のオブジェクトです。 製品、ユーザー、支払い。 したがって、各名詞には独自のテーブルがあります。 アンカーテーブルには、サロゲートキー(Verticaでは、最適なキーはint )といくつかの技術フィールドのみを格納する必要があります。 概念的には、アンカーは1つのタスクにのみ必要です-一意の各製品/ユーザー/支払いを1回だけ出荷します。 再読み込みを避け、元の記録がどこからどのシステムから来たかを思い出してください。 それだけです
製品/ユーザー/支払いを識別するタスクがどのように解決されるかを理解するために、2番目のエンティティに目を向けます。
エッセンス2-属性

属性は、オブジェクトの属性であるプロパティを格納するためのテーブルです。 商品の名前、ユーザー名とユーザーの生年月日、支払い金額。 オブジェクトの1つのプロパティは1つの属性テーブルです。 オブジェクトの10個のプロパティ(名前、姓、生年月日、性別、登録住所など)-10個の属性テーブル。 すべてがシンプルです。 最初のテーブルの数は非常に怖いですが、単純なので、精神にとっては難しいです。
各属性テーブルには、オブジェクトのサロゲートキーが含まれます。これは、対応するアンカーへのリンク、属性値のフィールド、およびオプションで、履歴および技術フィールドの日付です。 したがって、バイヤー(顧客)の名前の属性テーブルはS_Customer_Nameと呼ばれ、Customer_id(代理キー)、Name(属性値)、Actual_date(SC2履歴の日付)フィールドを含む必要があります。 ご覧のとおり、テーブルの名前とそのすべてのフィールドの名前は、コンテンツ(顧客名)によって一意に決定されます。
Verticaはどのようなニュアンスを追加しますか?...簡単です。1つのアンカーのすべての属性テーブルは、サロゲートキーのハッシュ、サロゲートキー、および履歴の日付で並べ替えて、 同じようにセグメント化する必要があります。 同じアンカーの属性テーブル間のすべての結合がMERGE JOIN -Verticaで最も効率的な結合になることが保証される単純なルール。 同様に、このセグメンテーションは、単一の日付でSC2履歴を持つETL操作を提供するために必要なウィンドウ関数の最適性を保証します。
前のセクションでは、オブジェクトを識別するアプローチの説明が発表されました。ユーザーに関する一連のデータが入ってくる-このユーザーが既にアンカーにいるのか、それとも彼が新しいのかをどのように理解するのか? 当然、この質問に対する答えは属性に求められます。 アンカーモデリングの主な利点は、最初にいくつかの属性(名前、姓)を使用し、次に他の属性(名前+ TIN)の使用を開始できることです。 さらに、歴史性を考慮に入れます。
エッセンススリー-ネクタイ

タイは、オブジェクト間の関係を格納するためのテーブルです。 たとえば、買い手が特定の国で国籍を持っているという事実を保存するテーブル。 したがって、テーブルには、左オブジェクトの代理キー(customer_id)、右オブジェクト(country_id)、および必要に応じて履歴日付と技術フィールドを含める必要があります。
Verticaの観点から、次のニュアンスが追加されます。2つのプロジェクションでタイテーブルを作成する必要があります-左サロゲートによってセグメント化され、右サロゲートによってセグメント化されます。 この表の少なくとも1つのJOINがMERGE JOINになるようにします。
シミュレーションの観点からの重要なニュアンス-アンカーモデリングは、データボルトでは通信(リンク)のためにデータ(サテライト)をハングさせることができ、アンカーモデリングではアンカーでのみデータ(属性)をハングさせることができるという点で、データボルトとは大きく異なります重要-NOT)。 この一見過剰な制限により、実際の物理世界をより正確にモデル化することができます。 たとえば、Data Vaultのプロパティとの従来の関係は、プロパティが販売額である顧客に製品を販売するという事実です。 アンカーモデリングにより、少し考えて、顧客の製品を販売するという事実は現実の要素ではなく、抽象化であることを理解できます。 現実の世界の要素は、番号、日付などのチェック(紙)です。 したがって、アンカーモデリングでは、説明されている例は3つのアンカー(バイヤー、チェック、製品、および2つのタイ:バイヤーチェックとチェック製品)によって記述されています。
(注意深い読者は、セクションの冒頭の例の写真でさえ完全に正確ではないことに気付くでしょう。市民権の事実は特定の文書(パスポート)によって修正され、パスポートでアンカーを介して指定されたデータを提示することがより正確です)。
合計-アンカーモデリングで4年
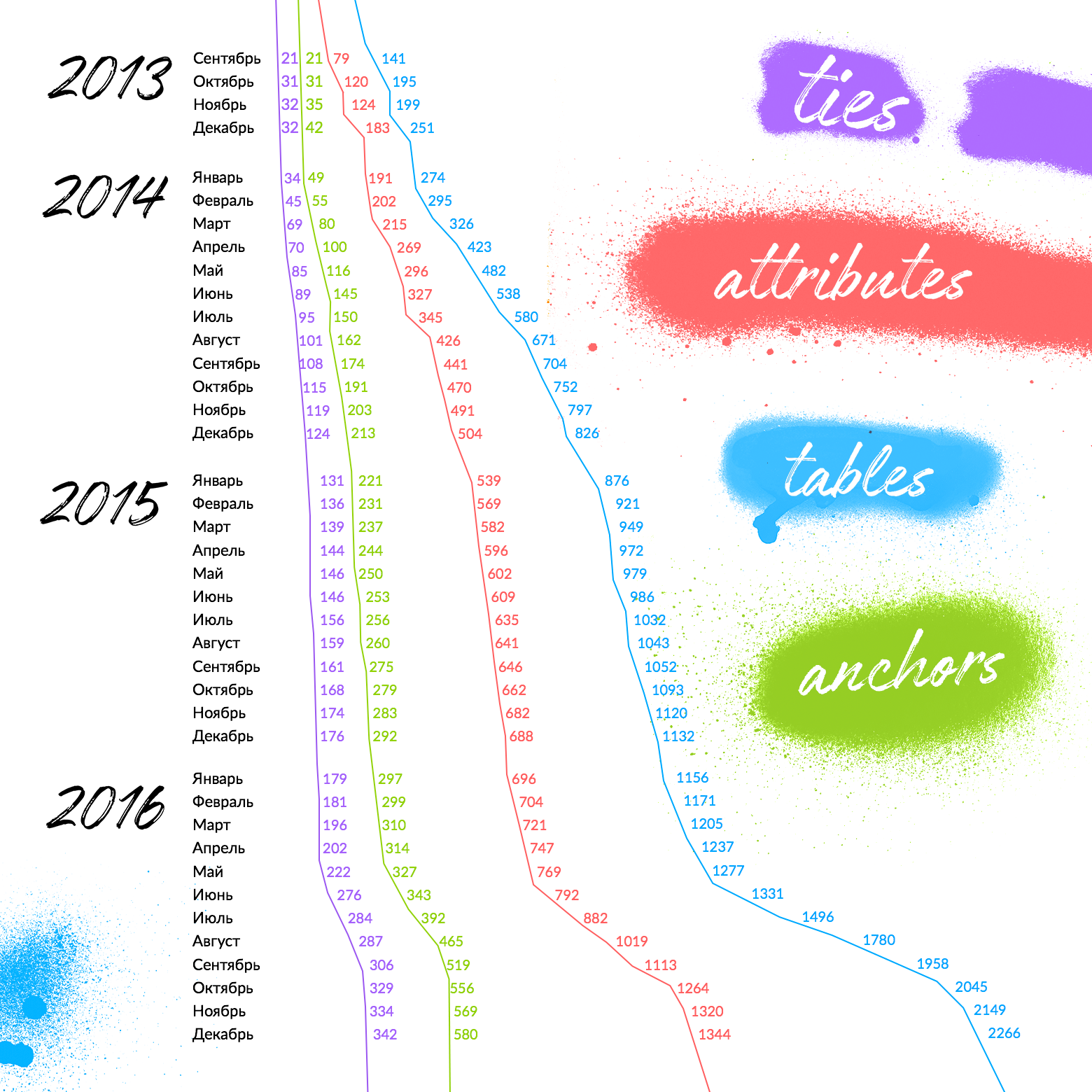
初めてAnchor Modelingを読むと、恐ろしくなります。
テーブルにdrれるのは怖いです。 恐怖は公正であり、それ自体を止めさせないことが重要です。 上の図は、4年にわたるAvitoの各タイプのテーブル数の増加率を示しています(右のグラフは、アンカー+属性+タイの合計数です)。
この記事の最初のグラフを思い出させてください。2016年末のAvitoストレージには、29を超えるソースシステムのデータが含まれていました。 ご覧のとおり、多くのテーブルがあります。 しかし、それほど恐ろしくはありません。 テーブルの数の大きなジャンプが最初に発生し、その後、古いテーブルの再利用の増加により、成長率が低下したと言えます。 2016年末のテーブル数の急激な増加は、異常に多数の新しいシステムの接続によって説明され、システムのサイズにかかわらず、まだ拡張できることを示しています。
多数のテーブルを恐れる2番目の理由は、外部アナリストによる分析の複雑さです。
この恐怖に対処する方法については、次の記事で説明します。 今回、彼女がさらに3年待たなくて済むことを願っています。その間、 セミナー 、 会議 、 ウェビナーでトピックに関するスピーチの録音を学習できます。
PS。 Larsは、アンカーモデリングのニュアンスを理解したい人のためのオンラインコースを修了しました。
anchor.teachable.com/courses/enrolled/124660 お勧めです。 Avitoの事例に関するビデオも1つあります:)。