 こんにちは同僚。 1960年代後半、 リチャードファインマンはカリフォルニア工科大学で一般物理学の講義コースを開催しました。 ファインマンはコースを一度だけ読むことに同意しました。 大学は、講義が歴史的な出来事になることを理解し、すべての講義を記録し、ファインマンがボード上で行ったすべての図面を撮影することを引き受けました。 たぶんこの後、大学は彼の手が触れたすべてのボードを撮影する習慣を続けたのでしょう。 右の写真はファインマンの死の年に撮影されました。 左上隅には、「 作成できないもの、理解できない 」 と書かれています 。 これは物理学者だけでなく、 生物学者にも言われました。 2011年、 クレイグベンターは世界で最初の合成生物、すなわち この生物のDNAは人間によって作成されます。 体はそれほど大きくなく、ただ一つの細胞からです。 ライフプログラムの再現に必要なすべてのことに加えて、クリエーターの名前、彼らの電子メール、およびリチャード・ファインマンからの引用はDNAにエンコードされていました(エラーがありますが、後で修正されました)。 ここでなぜこれがクールなのか知りたいですか? 同僚に招待します。
こんにちは同僚。 1960年代後半、 リチャードファインマンはカリフォルニア工科大学で一般物理学の講義コースを開催しました。 ファインマンはコースを一度だけ読むことに同意しました。 大学は、講義が歴史的な出来事になることを理解し、すべての講義を記録し、ファインマンがボード上で行ったすべての図面を撮影することを引き受けました。 たぶんこの後、大学は彼の手が触れたすべてのボードを撮影する習慣を続けたのでしょう。 右の写真はファインマンの死の年に撮影されました。 左上隅には、「 作成できないもの、理解できない 」 と書かれています 。 これは物理学者だけでなく、 生物学者にも言われました。 2011年、 クレイグベンターは世界で最初の合成生物、すなわち この生物のDNAは人間によって作成されます。 体はそれほど大きくなく、ただ一つの細胞からです。 ライフプログラムの再現に必要なすべてのことに加えて、クリエーターの名前、彼らの電子メール、およびリチャード・ファインマンからの引用はDNAにエンコードされていました(エラーがありますが、後で修正されました)。 ここでなぜこれがクールなのか知りたいですか? 同僚に招待します。
はじめに
何世紀にもわたって、人々は動作原理を説明できないものを作成しようとしてきた。 人工知能の最初の実際のモデルは、まったく神話的ではなく、機能していると理解できるものは、 Rosenblattパーセプトロンでした。 そして、 すべてが回転しました 。 コンピュータービジョンの分野をより詳細に検討してください。 今日、ニューラルネットワークは分類、セグメンテーションなどの問題を完全に解決できますが、どのように解決しますか? ネットワークがサインに学習するものと、それらが意味があるかどうか-これらの問題はほとんど解決されたと考えることができます。 これらの動作の結果により、今日の画像を操作する方法の例を次に示します。 しかし、操作することはそれを作成することではありませんか? たとえば、 このペーパーでは、画像にノイズを追加するとトップニューラルネットワークがミスを犯す原因になることを確認できますが、肉眼では変化は見られません。 ここで、画像を作成できれば、ニューラルネットワークが実際に学習することと、なぜ他のネットワークではないのかを理解するという質問に終止符を打つことができます。 これは、 インターステラーでの方法を思い出してください-重力の特異点を理解する最後のフロンティアは、特異点自体にあります。 フォトリアリスティックな画像のアルゴリズムによる生成の問題は新しいものではありませんが、重要な結果が得られたのはディープラーニングの時代のみです。 今日、これらのアプローチの1つについてお話します。これは、近年の深層学習における主要な成果の1つになっています。 元の記事はGenerative Adversarial Nets(GAN)と呼ばれ、確立された翻訳がない限り、それらをGANと呼びます。 「ジェネレーティブコンペティティブネットワーク」(GSS)または「コンペティティングネットワークの生成」(MSS)という選択肢はどうやら聞こえないようです。
まず、データの可能性を最大化することに基づいて生成モデルの分類を分析します(暗黙的にそれを行うものを含みます。データ生成には他のアプローチがありますが、それらはGANと重複しません)。
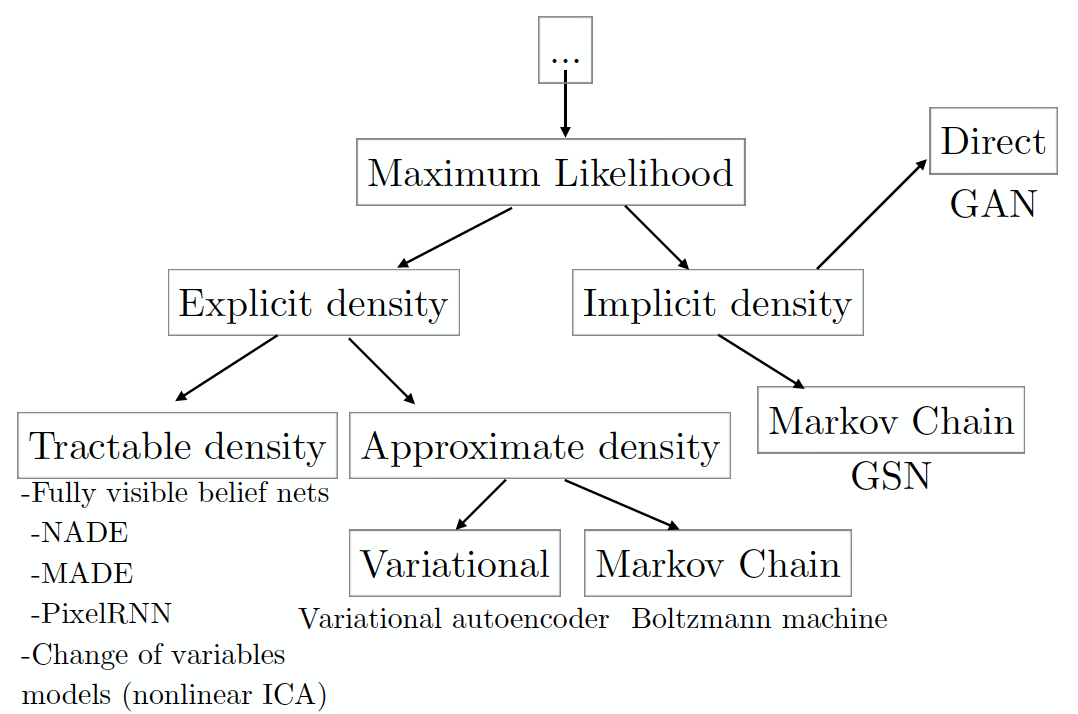
(画像は、2016 NIPS会議でのセミナーに基づいて編集されたGAN の著者による記事から取られています。そこから、以下のいくつかのパラグラフで無料で語り直します)。
最尤法の原則の本質は、以下で構成されるデータセットの尤度を最大化するモデルパラメーターを検索することです。 一般集団から独立して選択された例: 。 通常、計算を簡単にするために、尤度対数は最大化されます。
信頼性の最大化は、真のデータ分布とモデル分布の間のKL発散を最小化することと同じです。
分類法ツリーの各リーフは、特定のモデルに対応し、多くのプラスとマイナスがあります。 GANは、他のモデルの欠陥を平準化することを目的として開発されたため、当然のことながら新しい欠陥が出現しました。 しかし、まず最初に。 左のサブツリーには、データ密度関数の形式が明確に定義されたモデルがあります ( 明示的な密度 )。 そのようなモデルの場合、最大化は非常に明白です。必要な密度形式を尤度対数式に挿入し、勾配上昇を使用して最適なパラメーターセットを見つける必要があります。 。 このアプローチの主な欠点は、シミュレートされたデータ全体を記述するように密度を明示的に表現する必要があるだけでなく、同時に、結果として生じる最適化問題を許容可能な時間で解決できることです。 分布がさまざまなデータ全体を十分に記述し、 扱いやすい密度グループモデルの1つが許容時間内で機能するようにすべてを設計することができれば、幸運です(今のところ、生成された画像の品質を評価する唯一の方法は、人を視覚的に評価することです)。
モデルが平凡な品質の画像を作成する場合、または彼女が勉強している間に年をとる場合、 おそらく密度に近いモデルが問題を解決します( 近似密度シートを参照)。 そのようなモデルは、依然として分布密度の明示的な式を提供する必要があります。 変分法に基づく方法は、より低い尤度スコアを最大化します 、そのような真の信頼性の推定値の受信を保証します。これは、少なくとも取得したものより悪くありません。 多くの計算不可能な分布では、許容可能な時間内に計算可能な下限を見つけることができます。
このようなモデルの主な欠点は、下限と下限の間のギャップが 真の信頼性は大きすぎるかもしれません。 モデルになります 実際のデータ配布ではなく、他のことを学ぶ 。 この問題が発生した場合、設定した密度の近似が成功する最後のチャンスがまだあります- モンテカルロ法 ( マルコフ連鎖モンテカルロ 、MCMC)、すなわち サンプリング。 サンプリングは、このクラスのモデルの主な欠点です。 フレームワークは、いつの日かサンプルが収束することを保証するという事実にもかかわらず このプロセスには、許容できないほど長い時間がかかる場合があります。
絶望から、暗黙の密度関数を持つモデルを直接使用しないモデルを使用することを決定できます。 、およびそこからのサンプルのみがサンプリングされます。 ここでは、サンプリングにモンテカルロ法を使用する必要がある場合は、以前の方法の条件で自分自身を見つけます。または、1つのパスで1つのサンプルを生成するGANを使用できます(これはマルコフ連鎖の1つのステップに相当します)。 したがって、要約すると、GHANが非常に注目に値する理由は次のとおりです。
- 顕著な密度は必要ありませんが、望ましい分布の形が学習されるように行うことができます(この意味で、変分法とGANには関係があります)。
- 低尤度の対数の導出は必要ありません。
- サンプリングする必要はありません(より正確には、サンプリングはありますが、チェーンではなく1つのステップでのみ行われます)。
- 画像は他のモデルよりもよく得られることに気づきました(もちろん主観的評価)。
- このモデルは、上記の分類全体で最も理解しやすいモデルの1つであることを付け加えます。
当然、すべてがそれほどバラ色ではありません。GANの分析の後続の部分では、新しいモデルで発生したすべての新しい問題について学習します。 ガーナが一般に公開された最初の記事から始めましょう。
生成的敵対ネットワーク (2014年6月10日)
偽造者と警察との対立に関する映画の筋書きを想像してください。 両方をニューラルネットワークで置き換えるとどうなりますか? これまでのところ、たった2人の俳優から、ロールプレイングゲームになります。  ジェネレータは、データ(たとえば、画像)を生成するネットワークである偽造品の類似物であり、そのタスクは、対象集団に最も近い画像を生成できるようにすることです。 D iscriminator-警察官の類似物、またはむしろ、偽造者に対する警察の分析部門の従業員。 彼の仕事は、元のコインと偽物を区別することです。 したがって、弁別子はバイナリ分類子にすぎず、実際の画像では1 、偽の画像では0になります。 ここで中国の部屋を思い出す価値があります :最適な識別器が偽物を実際のものと区別できない場合、ジェネレータが実際の画像を生成し始めたと仮定できますか、それとも高品質の偽物ですか? 一般に、モデルは次のようになり、エラーの逆伝播法を使用してエンドツーエンドで学習します。
ジェネレータは、データ(たとえば、画像)を生成するネットワークである偽造品の類似物であり、そのタスクは、対象集団に最も近い画像を生成できるようにすることです。 D iscriminator-警察官の類似物、またはむしろ、偽造者に対する警察の分析部門の従業員。 彼の仕事は、元のコインと偽物を区別することです。 したがって、弁別子はバイナリ分類子にすぎず、実際の画像では1 、偽の画像では0になります。 ここで中国の部屋を思い出す価値があります :最適な識別器が偽物を実際のものと区別できない場合、ジェネレータが実際の画像を生成し始めたと仮定できますか、それとも高品質の偽物ですか? 一般に、モデルは次のようになり、エラーの逆伝播法を使用してエンドツーエンドで学習します。
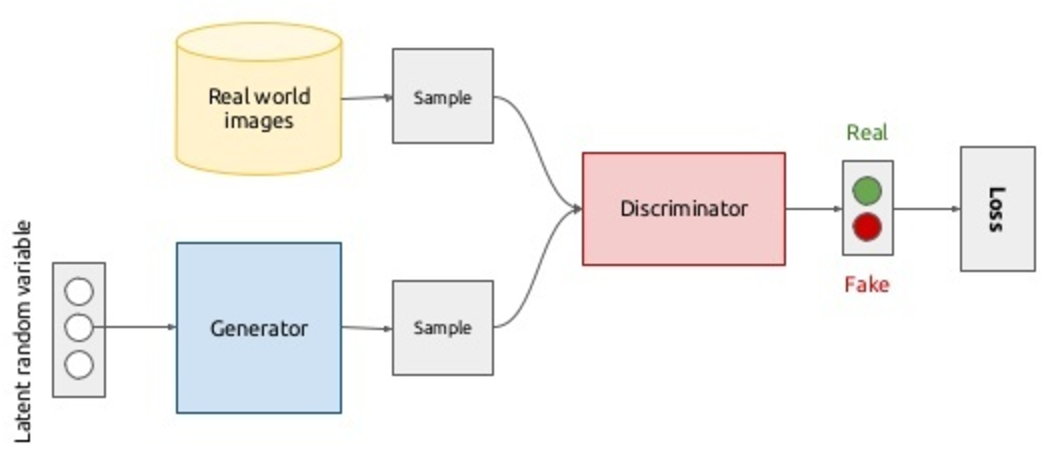
原則として、図の上半分のシナリオではすべてが明確です。実際の画像のデータベースから画像をサンプリングします( )、ラベル1をそれらに割り当て、弁別器を介して駆動します。これにより、実際の画像のクラスに属する確率を取得します。 実画像と生成画像(これについては後で説明します)のサンプルでの弁別器の尤度の対数を最大化することにより、密度を実画像に向かって移動させます。 どこで -ニューラルネットワーク弁別器、および -そのパラメーター。 発電機を訓練するために、発電機の分布を どこで 画像です。 ノイズの特定のアプリオリ分布が導入されます ジェネレーターによって画像空間にマッピングされます: ( -ネットワークジェネレーターのパラメーター)。 はい、あなたはすべてを正しく理解しました、画像はノイズから生成されます。 さらに、このノイズの形状をカスタマイズできます。 2番目のシナリオでは、次の機能が最小化されます。 、つまり 差別者に偽物と実際の画像をできるだけひどく区別してもらいたい。 なぜなら、勾配降下でジェネレーターの重みを更新することを妨げるものは何もないからです。 -微分可能な機能。 上記のすべてを1つの最適化タスクに結合すると、2人のプレーヤー向けの次のミニマックスゲームが得られます。
これは最初の強化トレーニング条件に非常に似ていることに気付くかもしれません。あなたは正しいでしょう。 ジェネレータから弁別器に情報を送信するためのチャネルは、ネットワークを介した直接パスであり、リターンパスは、弁別器からジェネレータに情報を送信する方法です。 アイデアは、ディスクリミネーターからの勾配を単純に反転することにより、エンドツーエンドモデル全体をトレーニングすることです。これにより、ディスクリミネーターがその表面でより高く上昇し、ジェネレーターが自然に下降することができます(著者が勾配反転レイヤーを導入する次の部分を参照)。 しかし、正確にはGANSの場合、このアプローチは機能しません。 弁別器トレーニングの最初の段階では、偽物と実際のデータを区別するのは非常に簡単です(以下の例を参照)。 その後、偽データ 同様に 、勾配の減衰で表現されます。 簡単に言えば、弁別器からの情報はジェネレータに到達せず、ジェネレータは失われません(何も学習しません)。 弁別器は常に最適に近いという仮定の下で、交換 に は減衰の問題を解決しますが、minimaxゲームと新しいmaxmaxの解決策は同じです。
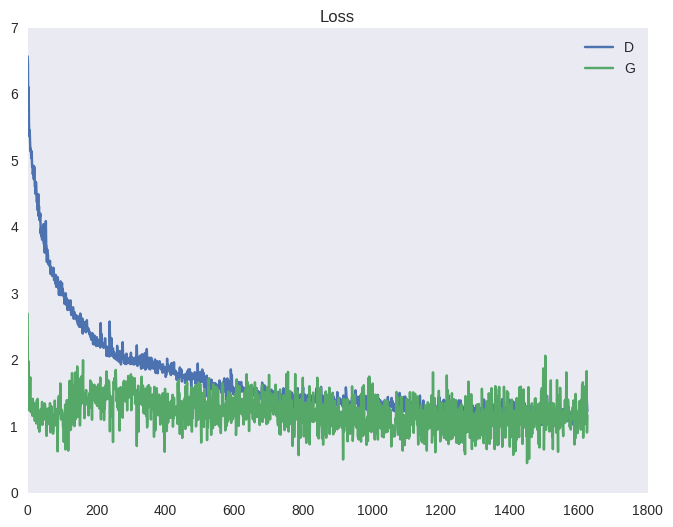
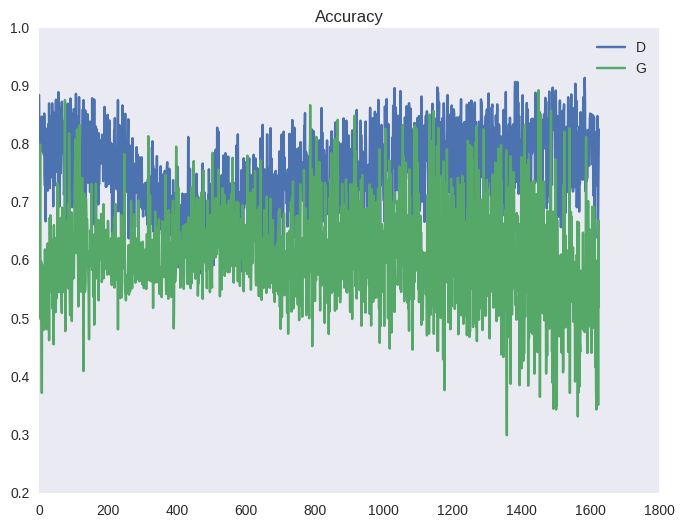
トレーニングの開始時と後の段階でネットワークが提供するサンプルを比較します。


弁別器が常に最適に近いことを保証するために、記事の著者は次のトリックを提供します。 各トレーニングの反復では、最初に、固定ジェネレーターを使用して実画像と偽画像からのバッチで弁別器がトレーニングされます。 次に、1つのステップを実行して、固定識別器を使用して偽イメージのバッチでジェネレーターをトレーニングします。 これにより、ディスクリミネーターが常に最適な状態に近づき、ジェネレーターがゆっくりと変更されます。 結果は、不安定な学習をもたらす綱引きゲームです。 以下は、GANコスト関数と精度(判別器がトレーニングフェーズとジェネレータートレーニングフェーズで正しく認識する例の数の平均)の典型的な図です。 上記の例(スポイラーの下)の波紋の形だけでなく、下のグラフでこのようなプルの効果を確認できます。
 |  |

GANの根底にある理論的正当性を評価しましょう。 最初に、著者は、固定ジェネレーターの場合、最適な識別器が次の形式であることを証明します。
そして、彼らはその時点でのジェネレーター関数の汎関数のグローバルな最小値の存在に関する定理を証明します 、また、関数の値 。 最後に、著者は、ジェネレータとディスクリミネータのシーケンシャルトレーニングのプロセスが収束すると主張します。 すべてが非常に良いように思えますが、これらの計算はすべて、可能なすべての関数をジェネレーターとディスクリミネーターの候補と見なした場合にのみ当てはまります。 残念ながら、実際には、すべての関数のスペースで最適化の問題を解決することはできません。また、1つのファミリに限定する必要があります。 この場合、これはニューラルネットワークのファミリーです。 パラメトリックに定義された関数。 そして、これがまさに上記のグラフに描かれているような不安定な振る舞いの理由です。 ニューラルネットワークのパラメーターの空間(およびこれは非常に高次元の実数の空間)で関数を最適化することにより、単純に同じグローバル最適を見つけることができません。 なぜニューラルネットワークなのか? ニューラルネットワークの普遍近似定理が証明されており、これはおそらくこれまでで最も広いクラスの関数であり、その空間でソリューションを検索することができます。
主な記事のレビューを終了するために、収束プロセスとそれがもたらすものの理想的な視覚化を検討します。

- 黒い点の線はデータ分布です ニューラルネットワークを持ち込みたい。
- 緑の線は発電機の分布です 、学習プロセスでは、データの分布に近づきます(トレーニングは順次行われます)。
- 青い線は弁別器の分離面であり、訓練の終了時に、ジェネレーターによって作成された偽物からの実際のデータセットと例を区別できません。
- 矢印はディスプレイを示します 、データ分布の各値に事前分布のポイントを関連付けます。

著者は、4つの実験の結果を示しています。 最初の5列にはジェネレーターからのいくつかのサンプルが含まれ、右側に最も近い実画像があります。 MLPの使用により、複雑なデータセットの結果はまだ印象的ではありません。
このようなトレーニングの4つの特性に注意してください。
- 滑らかでコンパクトな空間が学習されることがわかり(数学の概念と混同しないでください)、ノイズ空間内の類似オブジェクトの逆像も隣り合わせになります(著者は通常のMLPを使用しているため、次のいずれかの記事で美しい視覚化が見られます)たたみ込みネットワーク)、およびアプリオリノイズからの任意のポイントに対して、意味のあるプロトタイプがあります。
- ジェネレーターは、単一の実画像を見ることなく、実物に近い画像を作成することを学習しますが、グラディエントでエンコードされた偽物が検出された理由を弁別器からのみ受信します。
- MCMCを削除しようとしています。 それには多くの時間がかかりますが、最終的には、1ステップでサンプリングを行うモデルが得られましたが、それでも長時間学習し、不安定です(MCMCは少なくとも漸近的に収束しますが、ここではパラメトリック関数の領域では保証はありません);
- モデルは美しいですが、ノイズ空間で実際の画像の逆画像を生成するだけでなく計算したいので、画像から特徴を抽出するのにはまったく適用できません。
バックプロパゲーションによる教師なしドメイン適応 (2014年9月26日)
ガーナは楽しくて熱烈であるが、今のところ役に立たないことは誰にとっても明らかであるように思えた。 人類は特徴を抽出するためにそれらを適応させる方法を知っていましたが、Skolkovoで彼らはGANamの予期せぬ有用なアプリケーションを見つけました。 次のタスクを想像してください。Amazonのような店で実際の写真から服を検索する必要があります。 これを行うには、Amazonを解析するだけで、ラベル付きデータセットを簡単に組み立てることができます。 次に、製品カテゴリごとに各画像にラベルを割り当て、分類器をトレーニングし、ネットワークの任意の表現を使用して検索します。 ただし、小さな問題があります。Amazonのすべての写真は、原則として、ノイズがなく、多くの場合人がまったくいない白い背景のスタジオ写真です。 , , . , , , , , .
Domain Shift – , . , ; , ; , , . , , . - .
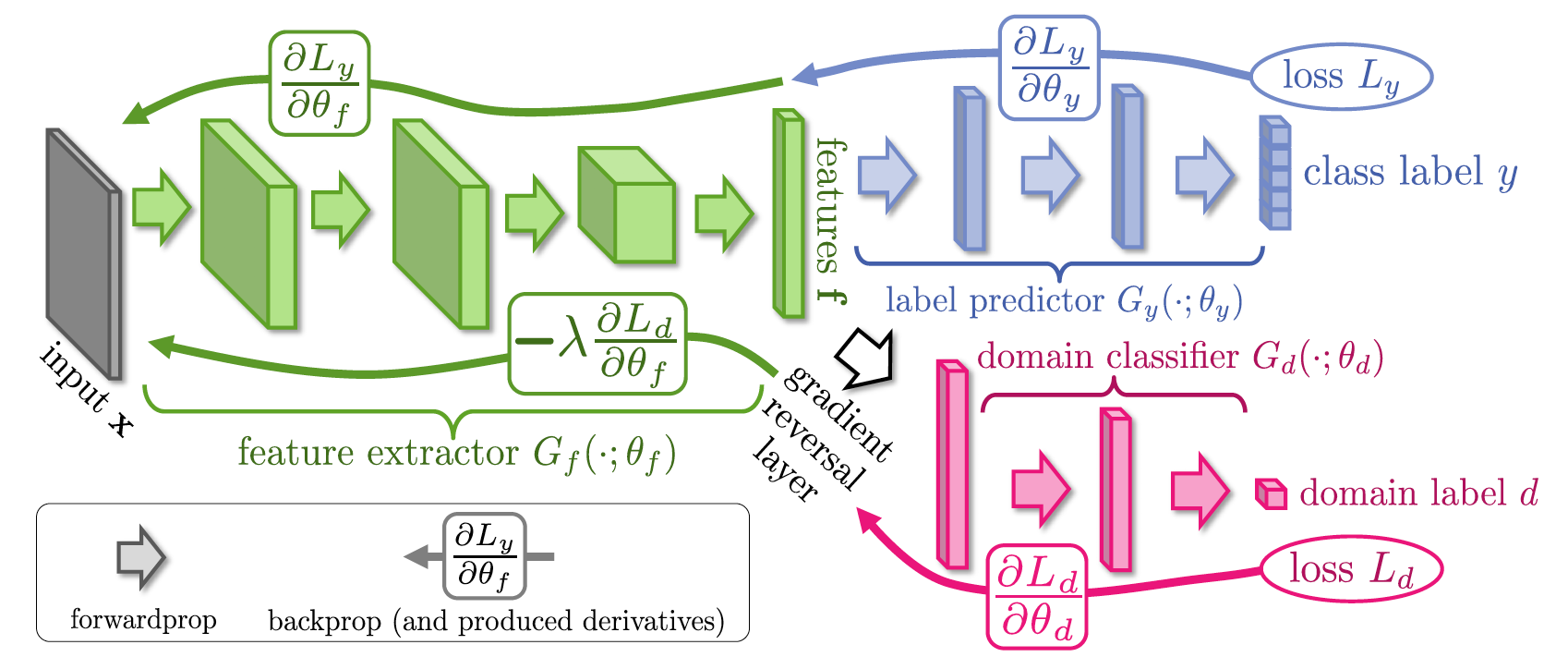
, , f , , Google Inception V1 , , . "" f , "" , .. . , end-to-end, gradient reversal layer, f . , f , , .
対象の写真:
上位3つの回答:



Conditional Generative Adversarial Nets (6 Nov 2014)
, . , , , , .

右側のこの画像では、ターゲットデータの分布を確認でき、左側では、従来のGANの収束プロセスを確認できます。 その結果、モデルは好みのモードを選択し、そこからのみサンプルを生成します。 たとえば、モデルのトレーニングを開始して、MNISTのセットから手書きの数字を生成できます。彼女は、7のみを完全に生成することを学習します。 私が受け取りたいものではありません。 MNISTの場合、ラベル付きデータセットがある場合、著者は、生成された画像だけでなく、そのラベルもジェネレーターとディスクリミネーターに送信することを提案します。
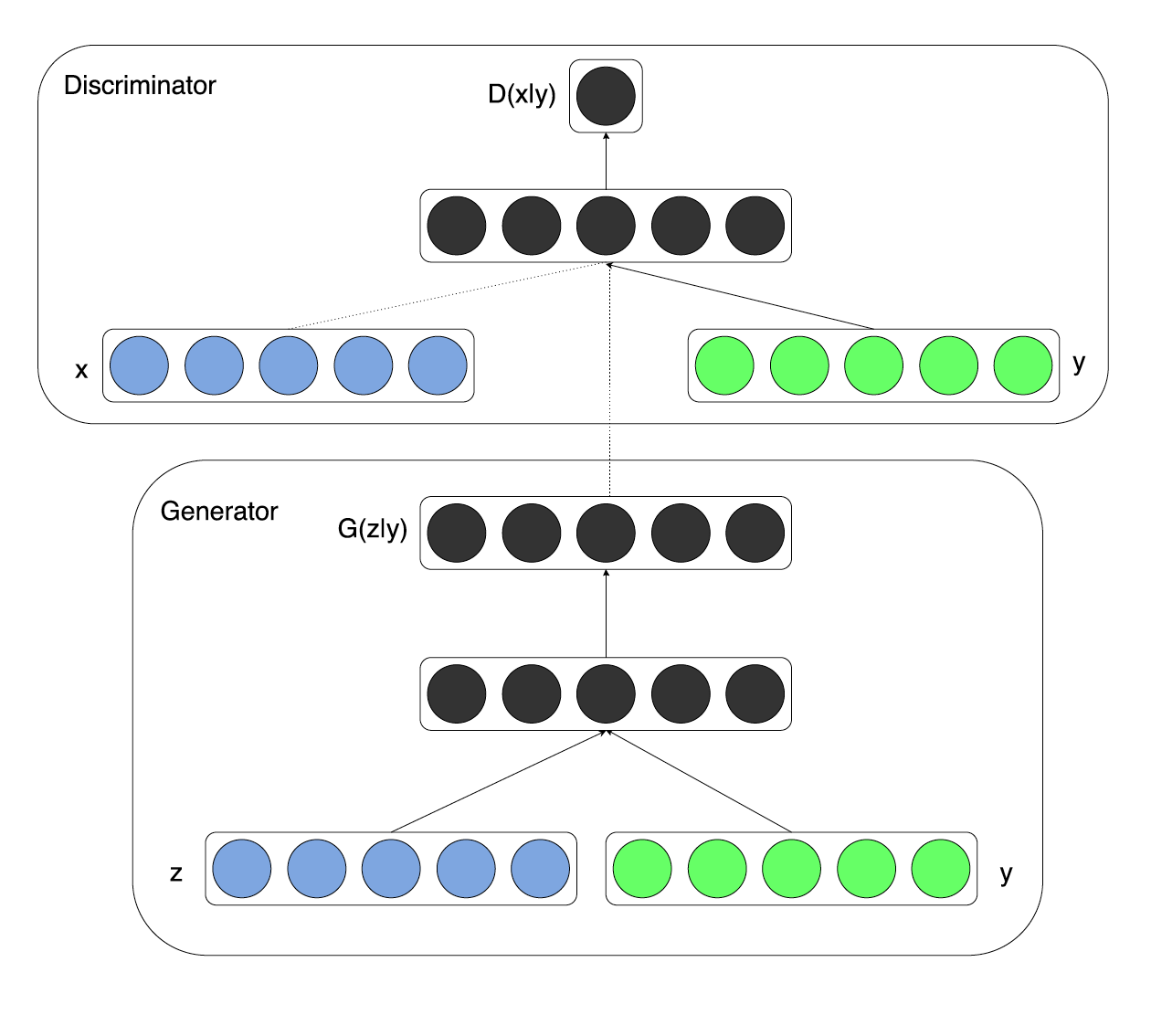
新しいコスト関数と元の関数の間の2つの違いを見つけてください。
その結果、著者は、モードの要素とオブジェクトの他のパラメーターのもつれが解けることを望んでいます。 手書きの数字の場合、変な効果が観察されます。モデルは、ラベル(数字)の情報を(入力ノイズに)特徴ベクトルにエンコードする必要がなくなりました。 すべての情報はすでにタグベクトルにあります 次に、数字の記述スタイルに関する情報が特徴ベクトルにエンコードされます。 次の画像の各行は、同じモードのサンプルです(固定ラベルベクトル)。

深い畳み込みの生成的敵対ネットワークによる教師なし表現学習 (2015年11月9日)
この記事は、理論よりも実用的な価値があります。 著者自身でさえ、この記事の主な貢献は次のとおりであると述べています。
- 通常のニューラルネットワークは畳み込みネットワークに置き換えられ、試行錯誤の結果、 D eep C畳み込みGANのトレーニング方法に関する指示がまとめられました。
- 例により、DCGANトレーニング中に得られた弁別子は、このドメインおよび同様のドメイン上の他の分類子にとって適切な初期化であることが示されています(教師なしの学習タスクから教師付きの学習タスクへの学習の転送);
- フィルターを分析した後、著者は、特定のオブジェクトの描画を担当するフィルターを見つけることができることを示しました。
- ジェネレーターはword2vecに似た興味深いプロパティを持っていることが示されています(以下の例を参照)。
実際、モデル自体に予期しないことはなく、おそらくモデルの指導に関する実験には多くの時間がかかりました-GANとDCGANの記事の間で1年以上が経過しました(もちろん、著者はICLR 2016に特に適応する役割を果たしました) ジェネレータ回路は次のとおりです。
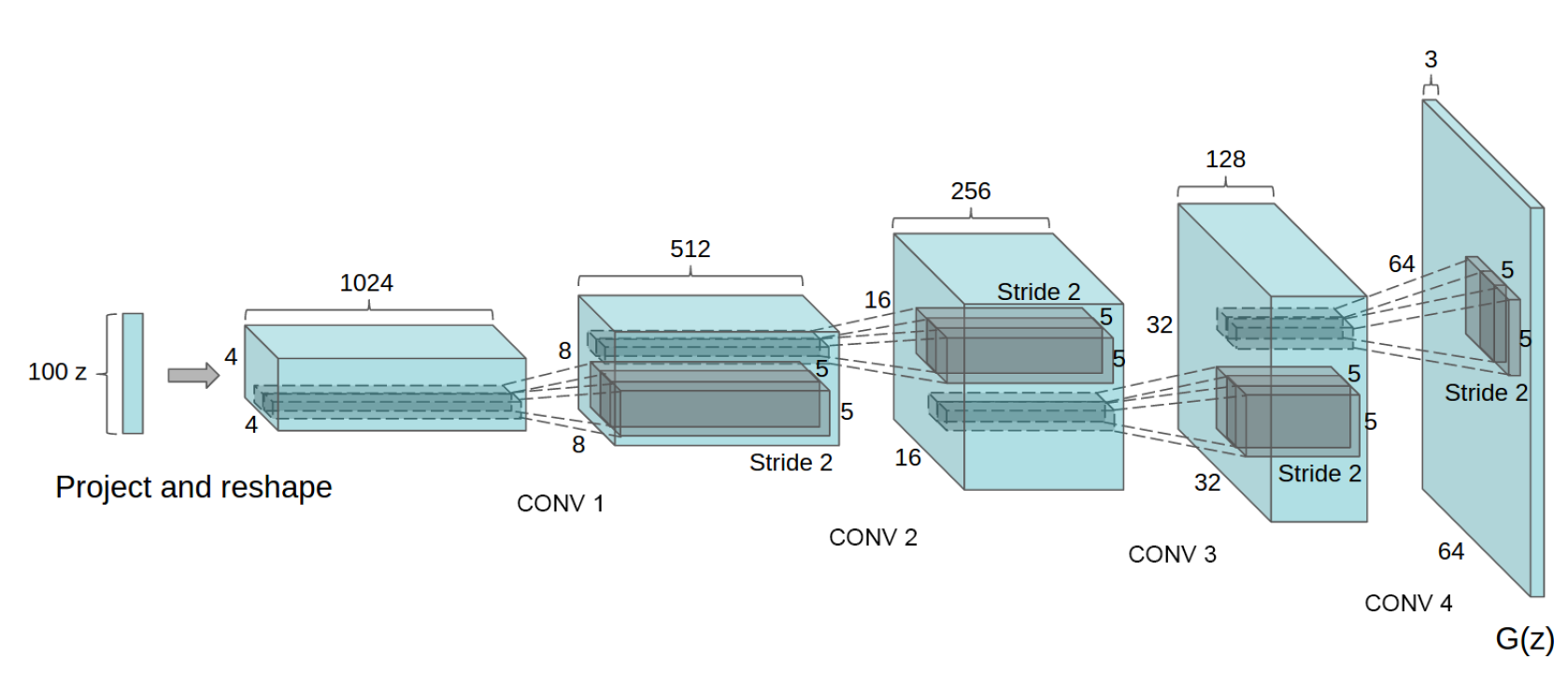
次のポイントは、アーキテクチャの機能に起因する可能性があります。
- ジェネレーターとディスクリミネーターでは、プーリングの代わりに、1より大きいステップの畳み込みが使用されます(それぞれストライドとフラクショナルストライド)。
- バッチ正規化は、ジェネレーターとディスクリミネーターで使用されます。
- 完全に接続されたレイヤーは使用されません。 ネットワークは完全に畳み込みになります。
- ジェネレーターは、出力層(出力のタン)を除くすべての場所でReLUを使用します。
- 弁別器はどこでもLeaky ReLUを使用します。
その結果、暗号面とそれらに対する算術を楽しむことができます。 より正確には、算術は符号の空間で行われ、結果は結果のベクトルから生成されます。

それとは別に、この実験自体の詳細に言及する価値があります。 そもそも、大量の画像をサンプリングする必要があり、その後、手と目で、眼鏡をかけた男性、眼鏡をかけない男性、眼鏡をかけない女性の多くの画像を見つけました。 次に、各グループの特徴ベクトルが平均化され、算術が行われ、結果の特徴ベクトルから新しい画像が生成されます。
最初の記事の説明では、機能空間が滑らかでコンパクトであることが判明したと書いています。 さまざまな反転画像上にあるランダムな点を選択すると、この点の周囲のすべての方向に、現在の画像に似た画像の兆候が現れます。 これで、属性空間内の複数のポイントをランダムに選択し、サンプルを接続するパスに沿ってサンプリングポイントを開始し、各サンプルに対して画像スペース内の画像を描画できます(はい、矢印は冗長です)。
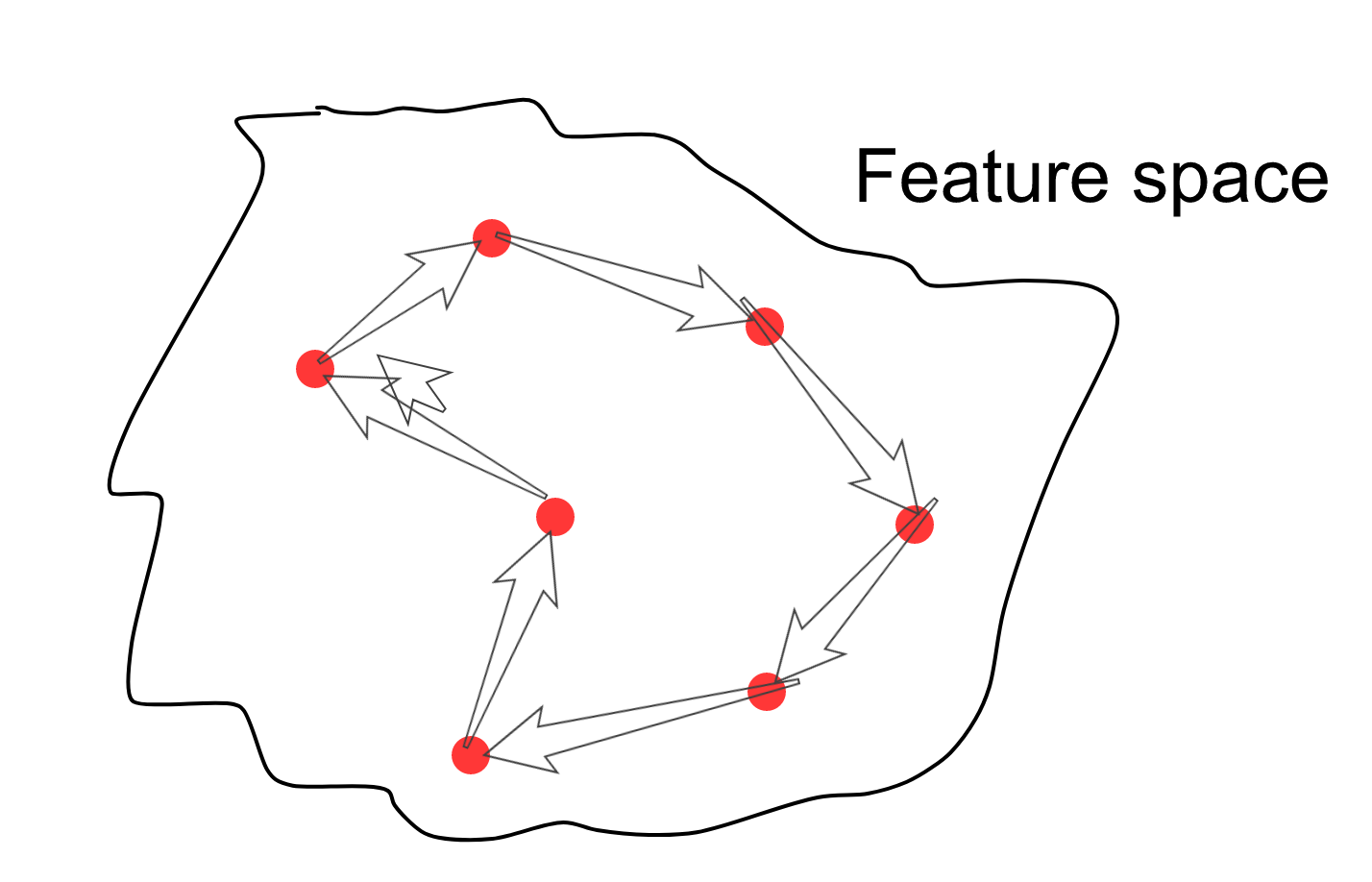
その結果、あるクリープ人から別のクリープ人へのこのような移行が発生します。

一般に、GANには画像から特徴を抽出するメカニズムが明らかに欠けています。 そして、ガーナに関する最初の記事「Adversarial Autoencoders」に続いて、2番目に重要な記事に進みます。
敵対的オートエンコーダー (2015年11月18日)
GANの2番目に重要な記事は、元の記事の1年半後に登場しましたが、これもICLR 2016への調整に関連しています。 。 結果は特別なタイプの自動エンコーダーです。これは、オブジェクトから特徴を抽出できるモデルです。 AAEモデルのトポロジを検討し、そのようなオートエンコーダーの機能のいくつかのプロパティに注意を払ってください。

画像の上部には、従来の自動エンコーダーがあります。 エンコーダー(エンコーダー)によって生成された分布を どこで データ配布から取得 (たとえば、手書きの数字のセットMNISTから)。 したがって、デコーダ どこで 自動エンコーダーの隠れ層の完全な(限界)分布から取得されます。 デコーダーの出力には、自動エンコーダーのコストの通常の関数があります。これにより、デコーダーの出力がエンコーダーの入力になります。
左下には、以前のノイズ分布からのサンプルジェネレーターがあります。 これは、分析的に定義された多次元正規型の分布と、未知の性質、ブラックボックスの分布の両方になります。 どのように機能するかはまだわかりませんが、そこからサンプリングできます。 隠れ層のアプリオリ分布を 。 GAN弁別器は、右側の画像の下部にある隠しレイヤーに添付されます。 弁別器のタスクは、先験的なキャラクターの分布から例を区別することです およびエンコーダーによって生成された分布からの例 。 このような競争力のある自動エンコーダーをトレーニングするプロセスでは、弁別器はエンコーダーパラメーターを勾配で変更し、分布が 分布が近づいている 。 したがって、エンコーダは暗黙的な事前分布を学習するか、ネットワーク内でエンコードされた暗黙の事前分布が与えられたと言いますが、その形状を分析的に取得することはできません。
その結果、2つのコスト関数を備えた自動エンコーダーが得られます。データ品質の標準と、隠れ層の品質の GANです。 モデルは、次のシナリオに従って確率的勾配降下法によって学習されます。
- リカバリフェーズ:オートエンダートレーニングの通常の反復。その間、イメージリカバリのエラーを最小限に抑えるために、エンコーダとデコーダのパラメータが更新されます。
- 正則化フェーズ:エンコーダーとディスクリミネーターの更新を繰り返します。 次に、通常のGANのトレーニングシナリオで説明されている2つのフェーズで構成されます。 最初に、固定ジェネレーターを使用して実際のサンプルと偽のサンプルからバッチで弁別器をトレーニングするいくつかのステップを実行し、次に、固定判別器を使用して偽イメージからバッチでジェネレーターをトレーニングする1ステップを実行する必要があります。
このようなトレーニングの後、ネットワークが画像をデータ空間から指定した分布にマッピングすることを学習できることを期待できます。また、観測空間で適切な画像を見つけるために、コード上の指定された分布の任意のポイントについて学習することを期待できます。
投稿の最初に、生成モデルの分類ツリーがあります。これは、明示的に指定された隠れ層の分布を近似する変分オートエンコーダー(VAE)に注意してください。 VAEは、負のデータ尤度対数の上限を最小化します。
ロシア語に翻訳すると、コスト関数には回復エラーと、エンコーダー出力の分布が与えられたアプリオリと異なるという事実に対するペナルティの両方が含まれています 。 最後の行の2番目の2つのメンバーはレギュラライザーであるため、非表示層の分布は特定の形状になります。 レギュラーがなければ、これは通常の自動エンコーダーになります。 AAEでは、明示的に定義された分布を含むKL正則化の代わりに、GANが使用されます。GANは、隠れ層からサンプラーによって指定された分布へのサンプルの経験的な不一致に対して罰金を科します。 この特定のサンプラーは、明示的に指定された分布または経験的であることを思い出します。

この画像では、AAEとVAEを使用して、例が隠された空間にどのように分類されるかを比較しています。 1行目では、隠された空間は2次元のガウス分布であり、2行目では10のガウス分布が混合しています。 右側では、作成者は隠されたスペースからポイントをサンプリングし、手書きの数字の対応する画像を描画します。すべてが本当にコンパクトで滑らかであることがわかります。
また、この記事では、将来的に他の多くのモデルの基礎を形成する、より歪んだAAEベースのモデルについても説明します。
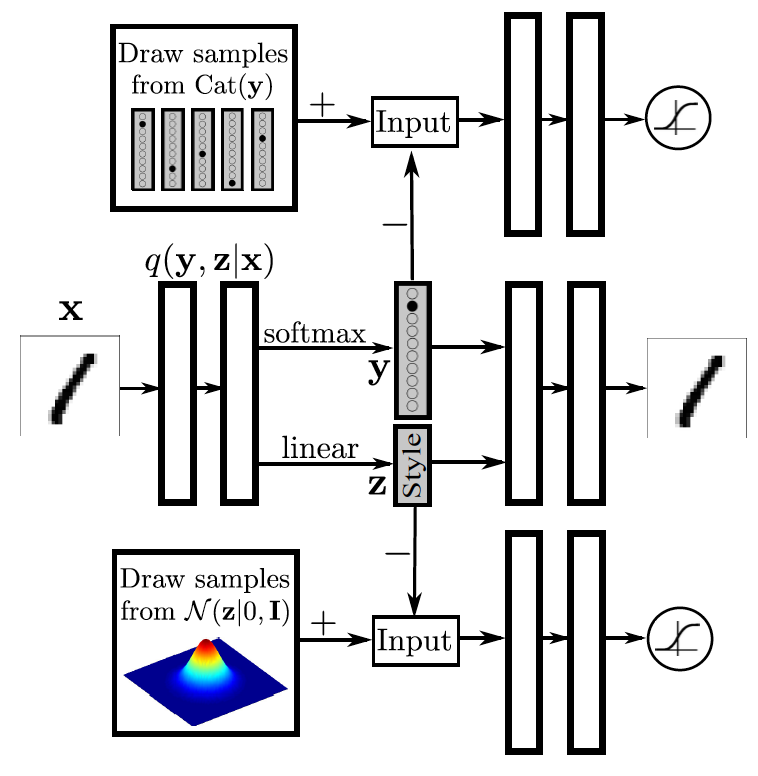
このモデルは、条件付きGANに非常に似ていますが、裏返しになっています。 自動エンコーダーの中央部には、2つのベクトルで構成される非表示のビューがあります。 最初は、クラスメンバーシップの確率分布を表示します。 2番目は、スタイルの表現を表示します(数字自体が図のスペルから削除された場合に他に何が残るか)。 上部には、クラスを表すためのGAN部分があります。これは、エンコーダー(ジェネレーター)によって発行されたクラスの分布を、この図の実際のワンホットエンコーディングに近づけようとします。 下位のGANは、スタイル情報をあらゆる分布(この場合はガウス分布)に絞り込もうとしています。 その結果、クラスとスタイルに関する情報が解明されます。 たとえば、クラスを修正し、さまざまなスタイルで数値を生成できます。 またはその逆に、スタイルを修正し、異なる数字を描画します。 記事でそのような例を挙げていないことは注目に値しますが、この分析の次の記事では、この実験は非常に成功しています。
このようなモデルは、多くのラベルの付いた例と多くのラベルの付いた例がある場合に便利です(よくあることです)。 次に、ラベルのない例では、トップGANは使用されません。
この記事の後、占星術師は数年のGANを発表しました。 一般に、AAE以降のすべての記事は、より工学的で理論的なものに分類できます。 前者は、AAEのもつれを解くスタイルに似たさまざまなトポロジを活用する傾向があります。 後者は、GANの理論的特徴により重点を置いています。 いくつかの理論記事と工学記事を検討します。 実際の実装に取り組むことを決定した人にとって、2016 NIPS会議でのGANに関するチュートリアル:GANのトレーニングのための改善されたテクニックに基づいて、GANの著者による記事を見ることが非常に役立ちます。
InfoGAN:生成的敵対的ネットを最大化する情報による解釈可能な表現学習 (2016年6月12日)
この記事は理論的なグループの記事の代表であり、著者は学習プロセスに情報的および理論的な制限を追加することで、隠れた要因をよりよく解明しています。 著者は、スタイルと書かれたキャラクターの解体に成功したこと、関心のあるオブジェクトの画像の背景、ヘアスタイル、感情、自撮りデータセットに眼鏡があるという事実について報告しています。 また、著者は、教師なしのトレーニングモードで得られた特性は、教師とのトレーニングで得られた特性と品質において同等であると主張しています。 著者は、生成モデルが教師なしの教育分野における支配的なモデルであることを忘れずに、オブジェクトを作成する能力はオブジェクトの構造の完全な理解を必要とし、その結果、因子の解明が改善されることを思い出します。
要するに、これらの魅力はすべて、観測と自動エンコーダーの内部表現からの特徴の特定のサブセットとの間の相互情報を最大化することによって達成されます。 従来のGANは隠された表現のベクトルに制限を課さないため、理論上、ジェネレータは非常に非線形または接続された方法で因子を使用し始めることができるため、どの要素もセマンティック属性に責任を負いません( 固有顔を思い出してください )。 InfoGANの詳細に進む前に、元のGANの目的関数を思い出させてください。
モデルのトポロジは、条件付きGANで説明されているモデルと同一であり、非表示層は2つの部分に分かれています。 -致命的なノイズ、 -オブジェクトに関するセマンティック情報を含むベクトル。 潜在的な要因は独立していると考えています。 。 新しいモデルのジェネレーターは次のように記述できます。 。 通常のガーナでは、ジェネレーターはセマンティックコードを無視するように制限されていません 、そして決定するかもしれません 、おそらく来ない。 来たくないので、著者は、情報理論的な正則化をコスト関数に追加することを提案します。 正規化の考え方は、隠された表現の意味部分とジェネレーターの分布の間の相互情報を最大化することです。 。
相互情報とは何かを思い出してください。 2つの確率変数を考えます そして 相互情報:
変数について取得した「情報量」を測定します 変数を観察する対象 。 言い換えれば、相互情報量は、2番目の変数を観察するときの最初の変数の不確実性の変化を表します。 相互情報がゼロの場合、2番目の変数には最初の変数に関する情報は含まれません。 私たちの場合、もっと 、生成された画像には非表示レイヤーに関する詳細情報が含まれています。 それ以外の場合、イメージはセマンティックベクトルを完全に無視し、元のGANのようにノイズベクトルのみに依存します。 生成された例では エントロピー 以下のように再定式化できる相互情報の定義の2番目の式を参照してください。生成プロセス中、セマンティックレイヤーに関する情報は失われません。 したがって、このようなcなGANの新しいコスト関数は、現在InfoGANと呼ぶことができ、次のようになります。
しかし、残念ながら、このような最適化の問題は、事後分布が必要になったという事実により、自明ではなくなります。 。 そして、ここに変分推論の魔法があります。 簡潔にするために、 その後:
KLの発散は負ではなく、隠されたセマンティックレイヤーのエントロピーは一定であると見なされ、相互情報のより低い変分境界が取得されます。 下限値を最適化することにより、関数自体の値を最適化しますが、推定値と実際の値の間のギャップは発散とエントロピーによって決定されます。 そしてもちろん、配布 ニューラルネットワークになります。 ジェネレーターに入力された隠れベクトルを認識する別の識別器をモデルに追加する必要があることがわかりました。 変分的な相互情報を持つこのすべての魔法は、別のニューラルネットワークをもたらしました。 著者は、2つの弁別器の畳み込み層を手探りし、出力で完全に接続されたいくつかの層のみを異なるものにすることを推奨しています。 InfoGANには次のトポロジがあります。
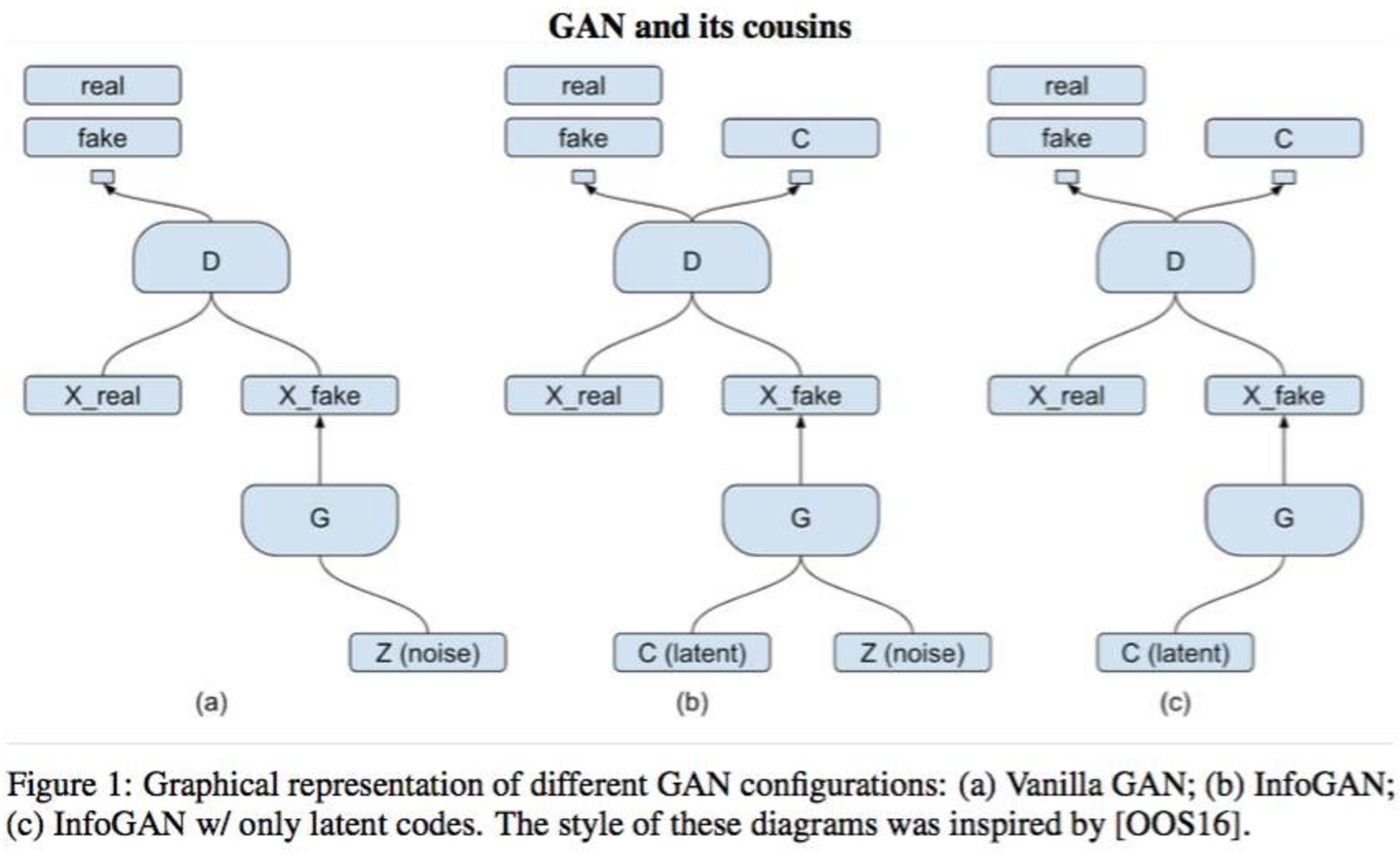
したがって、弁別器は2つの機能を実行します。偽物からの実例の認識と因子のベクトルの復元 (またはタグ)。 実際の例がラベルなしで与えられた場合、隠された意味表現を認識するネットワークは単に使用されません。 InfoGANは通常のGANと同じように見えるかもしれません。 標識を取得することはできませんが、InfoGANを一種のAAEに作り直そうとすることで、読んだ資料を統合することができます。
MNISTの実験では、10個の手書き数字のベースであり、1つのカテゴリ変数がセマンティック記述として非表示層として使用されます そして2つのノイズ 。

各列には、固定カテゴリのサンプルが含まれていますが、ランダムノイズコンポーネントが含まれています。 各行で、逆も同様です。 左側はInfoGANの結果です。セマンティック変数にはラベルに関する情報が含まれていることがわかります(覚えていますが、ラベルはトレーニングに参加していません)。 右側には普通のGANがあり、解釈はありません。

, , InfoGAN'. , , , .

Unsupervised Cross-Domain Image Generation (7 Nov 2016)
, , . , "" ( — ). ( ) — , . . , S ource T arget, , . , . , , . , -: , S T T. Domain Transfer Network. , , . , . - , 、つまり 。 , , MSE. perceptual loss, style transfer .
, , . , Adversarial Autoencoder f-constancy loss, , AAE :
. , , - .
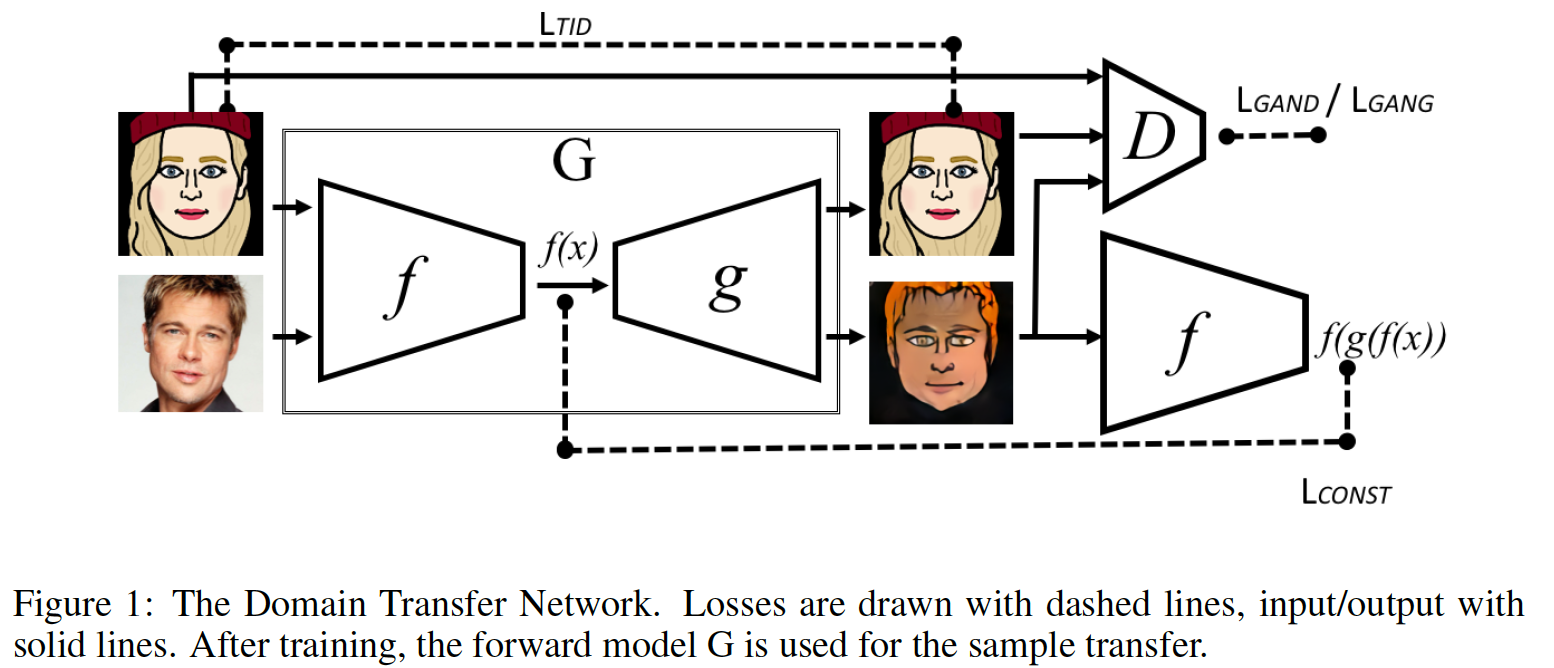
発電機 、つまり - : 。 .
, :
- T
- S
- T
:
-
- T , -
-
- f-constancy loss, S
-
- T ,
-
- total variation loss , —
- , DeepFace. http://bitmoji.com/ , , ( Facebook ). , , : ( ); , , ( ); — .

- 実在の人々の絵文字:ワット:

, . , FB . (, , 100 , , , ). , - "" .
Unrolled Generative Adversarial Networks (7 Nov 2016)
. , , . , . , , : . , . , .. , . , , . おそらく。 "" — , . , そして それに応じて。 :
:
:
( ) ( ), :
, ( ), , . - - :
, . , , - , . , , , , . :
, ( ); , , , , 回。 , .
, .. 。 . , . , , . , . で (.. , ), , , . , , . , , , . , , ( ), .

Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (30 Mar 2017)
, , . .
, X Y, , . , , .
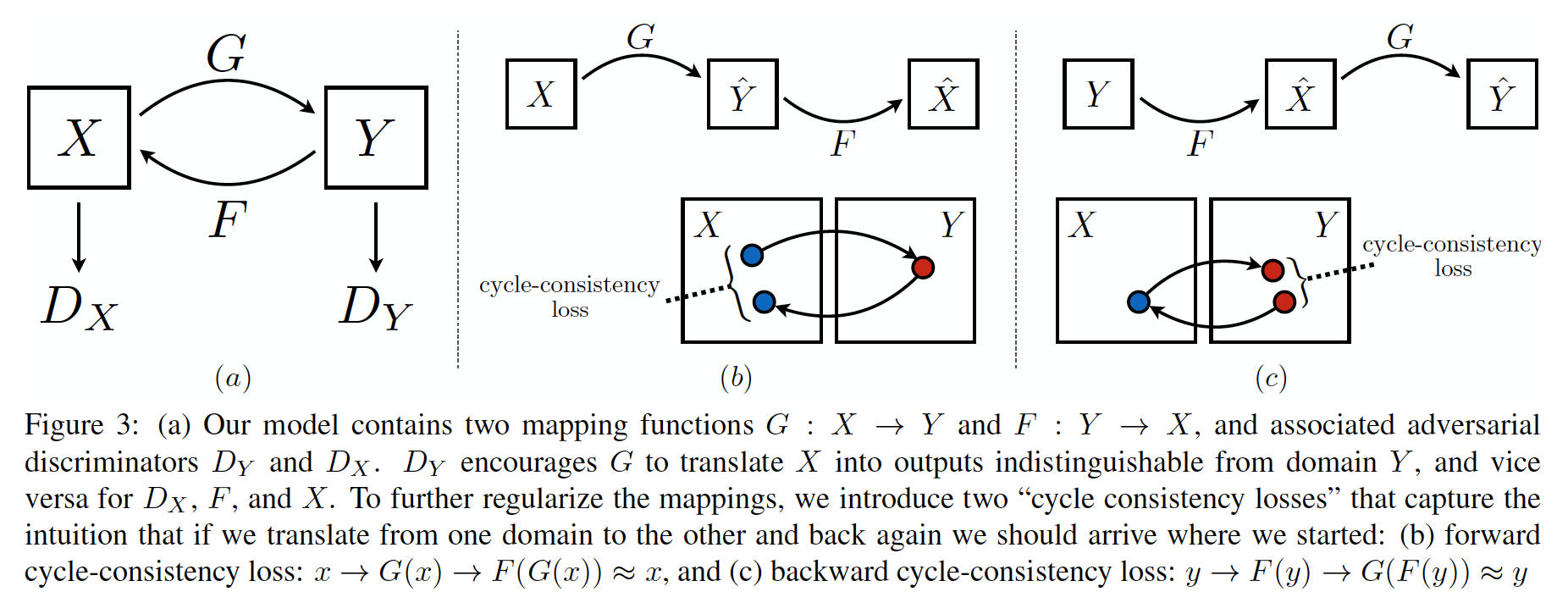
- そして , , , (, ), . , , , , , 。 ( , , — ):
 |  |

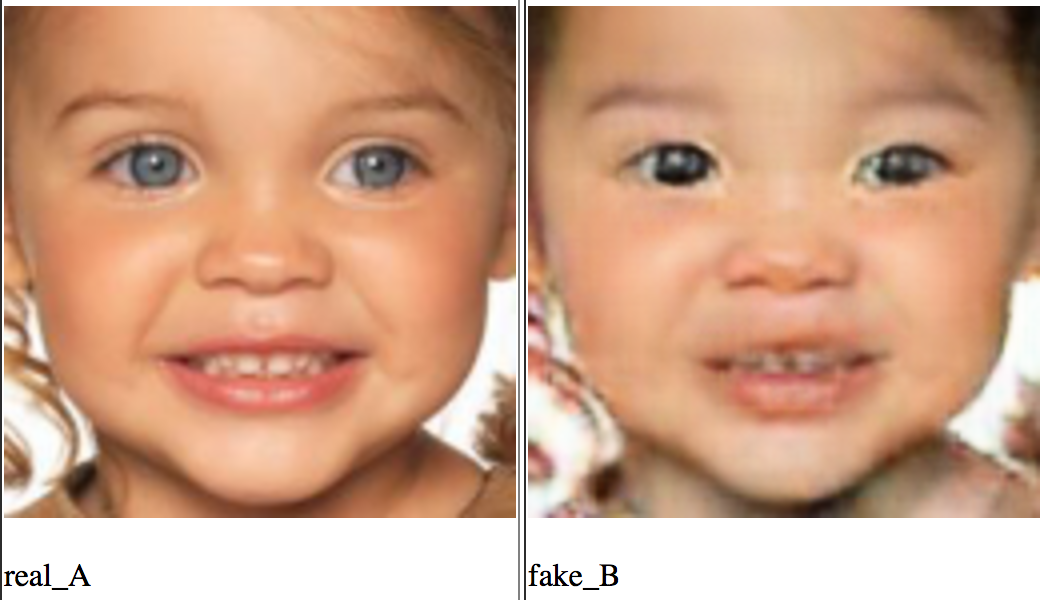


PS: , , consistency loss , VGG , style transfer.
, .
おわりに
. . , , :
- https://github.com/zhangqianhui/AdversarialNetsPapers
- https://github.com/nightrome/really-awesome-gan
- https://github.com/wiseodd/generative-models
- MIT .
- , , reinforcement learning
:

: bauchgefuehl , barmaley_exe , yorko , ternaus movchan74 .