
こんにちは、Habr! 私の名前はAlexander Krasheninnikovです。私はBadooのDataTeamを率いています。 今日は、xargsスタイルでコマンドを分散実行するためのシンプルでエレガントなユーティリティを共有し、同時にその発生のストーリーを説明します。
BI部門は、処理するために複数のマシンのリソースを必要とするデータボリュームを処理します。 ETL (Extract Transform Load)プロセスでは、ビッグデータの世界に馴染みのあるHadoopおよびSpark分散システムがExasol OLAPデータベースとともに使用されます。 これらのツールを使用すると、ディスクスペースとCPU / RAMの両方で水平方向にスケーリングできます。
もちろん、ETLプロセスでは、クラスターに重いタスクがあるだけでなく、より単純な機械もあります。 ギガバイトのRAMや1ダースのハードドライブを引き付けることなく、単一のPHP / Pythonスクリプトによって広範なタスクが解決されます。 しかし、ある晴れた日に、1つのCPUにバインドされたタスクを250の並列インスタンスで実行するように適応させる必要がありました。 小さなPythonスクリプトがネイティブホストの制限を超えて、大きなクラスターに突入する時が来ました!
操作オプション
そのため、問題に対する次の入力条件があります。
- Pythonでの長時間(約1時間)のCPUバウンドタスク。
- さまざまな入力パラメーターを使用してタスクを250回完了する必要があります。
- 実行結果を同期的に取得します。つまり、何かを開始し、待機し、結果に応じて終了コードを終了します。
- 最小実行時間-並列化に十分なコンピューティングリソースがあると考えています。
実装オプション
1つの物理ホスト
起動されたアプリケーションはシングルスレッドであり、1つのCPUコアを100%以上使用しないという事実により、各タスクのfork / execアクションのシーケンスをシームレスに実装できます。
xargsの使用:
commands.list: /usr/bin/uptime /bin/pwd krash@krash:~$ cat commands.list | xargs -n 1 -P `nproc` bash -c /home/krash 18:40:10 up 14 days, 9:20, 7 users, load average: 0,45, 0,53, 0,59
アプローチはフェルトブーツのようにシンプルで、それ自体が証明されています。 しかし、私たちの場合、32コアのマシンでタスクを実行すると、約8時間で結果が得られますが、これは「最小実行時間」という文言には対応していません。
複数の物理ホスト
そのようなソリューションに使用できる次のツールはGNU Parallelです。 xargsと機能が似ているローカルモードに加えて、複数のサーバーでSSHを介してプログラムを実行する機能があります。 タスク(「クラウド」)を実行する複数のホストを選択し、それらの間でコマンドのリストを分割し、タスクを並行して実行します。
マシンのリストとそこで使用できるコアの数を含むnodelist
ファイルを作成します。
1/ cloudhost1.domain 1/ cloudhost2.domain
以下を開始します。
commands.list: /usr/bin/uptime /usr/bin/uptime krash@krash:~$ parallel --sshloginfile nodelist echo "Run on host \`hostname\`: "\; {} ::: `cat commands.list` Run on host cloudhost1.domain: 15:54 up 358 days 19:50, 3 users, load average: 25,18, 21,35, 20,48 Run on host cloudhost2.domain: 15:54 up 358 days 15:37, 2 users, load average: 24,11, 21,35, 21,46
ただし、運用上の機能のため、このオプションも破棄します。クラスターホストの現在の負荷と可用性に関する情報がないため、ターゲットホストの1つが過負荷になるため、並列化が害を及ぼすだけの状況になる可能性があります。
Hadoopベースのソリューション
私たちは、知っていて使用できる実証済みのBIツール、Hadoop + Sparkの束を持っています。 コードをクラスターフレームワークに詰め込むには、2つのソリューションがあります。
Spark Python API(PySpark)
元のタスクはPythonで記述されており、Sparkにはこの言語に適したAPIがあるため、マップにコードを移植してパラダイムを削減することができます。 しかし、適応のコストはこのタスクの枠組みでは受け入れられないため、このオプションを拒否する必要もありました。
Hadoopストリーミング
HadoopのMap / reduceフレームワークを使用すると、JVM互換プログラミング言語だけでなく、記述されたタスクを実行できます。 特定のケースでは、タスクはマップのみと呼ばれます-実行結果は後続の集計の対象にならないため、reduceステージはありません。 タスクの起動は次のようになります。
hadoop jar $path_to_hadoop_install_dir/lib/hadoop-streaming-2.7.1.jar \ -D mapreduce.job.reduces=0 \ -D mapred.map.tasks=$number_of_jobs_to_run \ -input hdfs:///path_for_list_of_jobs/ \ -output hdfs:///path_for_saving_results \ -mapper "my_python_job.py" \ -file "my_python_job.py"
このメカニズムは次のように機能します。
- タスクを完了するために、Hadoopクラスター( YARN )にリソースを要求します。
- YARNは、特定の数の物理JVM(YARNコンテナー)を異なるクラスターホストに割り当てます。
- コンテナー間では、hdfs:// path_for_list_of_jobsフォルダーにあるファイル(a)の内容が共有されます。
- ファイルから独自の行リストを受け取った各コンテナは、my_python_job.pyスクリプトを実行し、STDINでこれらの行を順番に渡し、STDOUTの内容を戻り値として解釈します。
子プロセスを開始する例:
#!/usr/bin/python import sys import subprocess def main(argv): command = sys.stdin.readline() subprocess.call(command.split()) if __name__ == "__main__": main(sys.argv)
そして、ビジネスロジックを実行する「コントローラー」を備えたオプション:
#!/usr/bin/python import sys def main(argv): line = sys.stdin.readline() args = line.split() MyJob(args).run() if __name__ == "__main__": main(sys.argv)
このアプローチは、タスクと最も完全に一致していますが、いくつかの欠点があります。
- 実行中のタスクのSTDOUTストリームは失われます(通信チャネルとして使用されます)が、タスクの完了後にログを表示できるようにしたいと思います。
- 将来クラスターでさらにタスクを実行する場合は、それらのラッパーを実行する必要があります。
上記の実装オプションの分析の結果、独自の実装オプションを作成することにしました 自転車 製品。
Hadoop xargs
開発したシステムの要件:
- Hadoopクラスターのリソースを最適に使用してタスクのリストを実行します。
- 正常に完了するための条件は、「すべてのサブタスクが正常に機能した場合、失敗した場合」です。
- さらなる分析のためにサブタスクを保存する機能。
- ゼロ以外の終了コードでのオプションのタスク再起動。
実装のプラットフォームとして、Apache Sparkを選択しました。ApacheSparkに精通しており、「調理」の方法を知っています。
仕事のアルゴリズム:
- STDINからタスクのリストを取得します。
- Spark RDD(分散配列)にします。
- 実行コンテナーのクラスターを要求します。
- コンテナ全体にタスクの配列を配布します。
- コンテナごとに、外部プログラムの入力を受け取り、fork-execを生成するマップ関数を実行します。
アプリケーション全体のコードは非常に単純であり、関数コード自体が直接の関心事です。
package com.badoo.bi.hadoop.xargs; import lombok.extern.log4j.Log4j; import org.apache.commons.exec.CommandLine; import org.apache.commons.lang.NullArgumentException; import org.apache.log4j.PropertyConfigurator; import org.apache.spark.api.java.function.VoidFunction; import java.io.IOException; import java.util.Arrays; /** * Executor of one command * Created by krash on 01.02.17. */ @Log4j public class JobExecutor implements VoidFunction<String> { @Override public void call(String command) throws Exception { if (null == command || command.isEmpty()) { throw new NullArgumentException("Command can not be empty"); } log.info("Going to launch '" + command + "'"); Process process = null; try { CommandLine line = CommandLine.parse(command); ProcessBuilder builder = getProcessBuilder(); // quotes removal in bash-style in order to pass correctly to execve() String[] mapped = Arrays.stream(line.toStrings()).map(s -> s.replace("\'", "")).toArray(String[]::new); builder.command(mapped); process = builder.start(); int exitCode = process.waitFor(); log.info("Process " + command + " finished with code " + exitCode); if (0 != exitCode) { throw new InstantiationException("Process " + command + " exited with non-zero exit code (" + exitCode + ")"); } } catch (InterruptedException err) { if (process.isAlive()) { process.destroyForcibly(); } } catch (IOException err) { throw new InstantiationException(err.getMessage()); } } ProcessBuilder getProcessBuilder() { return new ProcessBuilder().inheritIO(); } }
組立
アプリケーションは、Javaの世界の標準ツールであるMavenを使用して構築されます。 唯一の違いは、アプリケーションが実行される環境です。 クラスターにSparkを使用していない場合、アセンブリは次のようになります。
mvn clean install
この場合、結果のJARファイルにはSparkのソースコードが含まれます。 クライアントコードSparkがアプリケーションの起動元のマシンにインストールされている場合、アセンブリから除外する必要があります。
mvn clean install -Dwork.scope=provided
このアセンブリの結果、アプリケーションファイルは大幅に小さくなります(80 MBに対して15 KB)。
打ち上げ
次の形式のタスクのリストを含むcommands.list
ファイルがあるとしcommands.list
:
/bin/sleep 10 /bin/sleep 20 /bin/sleep 30
アプリケーションを起動します。
akrasheninnikov@cloududs1.mlan:~> cat log.log | /local/spark/bin/spark-submit --conf "spark.master=yarn-client" hadoop-xargs-1.0.jar 17/02/10 15:04:26 INFO Application: Starting application 17/02/10 15:04:26 INFO Application: Got 3 jobs: 17/02/10 15:04:26 INFO Application: /bin/sleep 10 17/02/10 15:04:26 INFO Application: /bin/sleep 20 17/02/10 15:04:26 INFO Application: /bin/sleep 30 17/02/10 15:04:26 INFO Application: Application name: com.badoo.bi.hadoop.xargs.Main 17/02/10 15:04:26 INFO Application: Execution environment: yarn-client 17/02/10 15:04:26 INFO Application: Explicit executor count was not specified, making same as job count 17/02/10 15:04:26 INFO Application: Initializing Spark 17/02/10 15:04:40 INFO Application: Initialization completed, starting jobs 17/02/10 15:04:52 INFO Application: Command '/bin/sleep 10' finished on host bihadoop40.mlan 17/02/10 15:05:02 INFO Application: Command '/bin/sleep 20' finished on host bihadoop31.mlan 17/02/10 15:05:12 INFO Application: Command '/bin/sleep 30' finished on host bihadoop18.mlan 17/02/10 15:05:13 INFO Application: All the jobs completed in 0:00:32.258
YARN GUIを使用して作業を完了した後、開始したアプリケーションのログを取得できます( uptime
例):
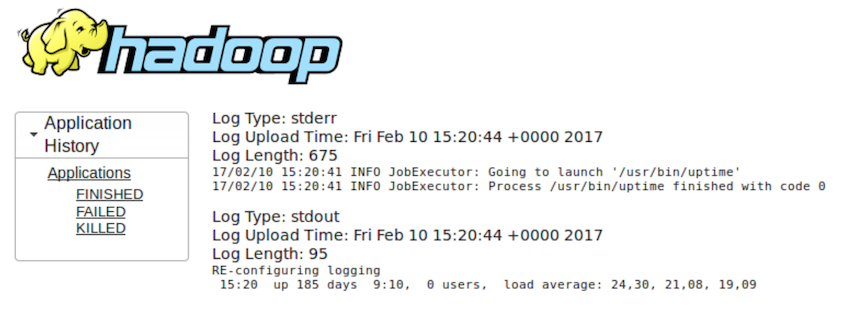
コマンドを実行できない場合、プロセス全体は次のとおりです。
akrasheninnikov@cloududs1.mlan:~> echo "/bin/unexistent_command" | /local/spark/bin/spark-submit --conf "spark.master=yarn-client" --conf "spark.yarn.queue=uds.misc" --conf "spark.driver.host=10.10.224.14" hadoop-xargs-1.0.jar 17/02/10 15:12:14 INFO Application: Starting application 17/02/10 15:12:14 INFO Main: Expect commands to be passed to STDIN, one per line 17/02/10 15:12:14 INFO Application: Got 1 jobs: 17/02/10 15:12:14 INFO Application: /bin/unexistent_command 17/02/10 15:12:14 INFO Application: Application name: com.badoo.bi.hadoop.xargs.Main 17/02/10 15:12:14 INFO Application: Execution environment: yarn-client 17/02/10 15:12:14 INFO Application: Explicit executor count was not specified, making same as job count 17/02/10 15:12:14 INFO Application: Initializing Spark 17/02/10 15:12:27 INFO Application: Initialization completed, starting jobs 17/02/10 15:12:29 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 1 times 17/02/10 15:12:29 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 2 times 17/02/10 15:12:30 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 3 times 17/02/10 15:12:30 ERROR Application: Command '/bin/unexistent_command' failed on host bihadoop36.mlan, 4 times 17/02/10 15:12:30 ERROR Main: FATAL ERROR: Failed to execute all the jobs java.lang.InstantiationException: Cannot run program "/bin/unexistent_command": error=2, No such file or directory at com.badoo.bi.hadoop.xargs.JobExecutor.call(JobExecutor.java:56) at com.badoo.bi.hadoop.xargs.JobExecutor.call(JobExecutor.java:16) at org.apache.spark.api.java.JavaRDDLike$$anonfun$foreachAsync$1.apply(JavaRDDLike.scala:690) at org.apache.spark.api.java.JavaRDDLike$$anonfun$foreachAsync$1.apply(JavaRDDLike.scala:690) at scala.collection.Iterator$class.foreach(Iterator.scala:727) at org.apache.spark.InterruptibleIterator.foreach(InterruptibleIterator.scala:28) at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1$$anonfun$apply$15.apply(AsyncRDDActions.scala:118) at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$1$$anonfun$apply$15.apply(AsyncRDDActions.scala:118) at org.apache.spark.SparkContext$$anonfun$37.apply(SparkContext.scala:1984) at org.apache.spark.SparkContext$$anonfun$37.apply(SparkContext.scala:1984) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66) at org.apache.spark.scheduler.Task.run(Task.scala:88) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
おわりに
開発したソリューションにより、元の問題のすべての条件に準拠することができました。
- 要件(カーネルの数)-最大レベルの並列化に従って、Hadoopからカーネルを取得してアプリケーションを実行します。
- リソースを発行する場合、ホストの負荷と可用性が考慮されます(YARN APIによる)。
- 実行するすべてのタスクのSTDOUT / STDERRの内容を保存します。
- 元のアプリケーションを書き換える必要はありませんでした。
- 「一度書くだけで、どこでも実行できる」©Sun Microsystems-開発したソリューションを使用して、他のタスクを実行できるようになりました。
結果の喜びは非常に大きかったので、私たちはあなたとそれを共有するしかありませんでした。 Hadoop xargsのソースコードはGitHubで公開されました 。