
今日の複雑な物理プロセスのモデリングは、多くの現代企業によって重要な技術的機会と見なされています。 複雑なモデルを計算できる計算機を作成するために広く使用されているアプローチは、コンピューティングノードが低遅延ネットワークに接続され、独自のOS(通常はGNU / Linuxファミリから)によって管理される汎用サーバーであるクラスターシステムの作成です。
コンピューティングクラスタのシステムソフトウェアに仮想化層を導入すると、数分で「仮想クラスタ」を作成できます。 1つのOpenStackインフラストラクチャ内のこのような仮想クラスターは完全に独立しています。 ユーザーのニーズに応じて、内部のユーザープログラムは変更される可能性があり、ユーザーとの調整は必要ありません。また、ユーザーデータが配置されている論理デバイスは、他の仮想クラスターでは使用できません。
仮想化ソリューションで低遅延ネットワークを維持することは、別個の複雑な問題です。 ほとんどの場合、アプリケーションの場合、最新のKVMベースの仮想化により、計算能力の損失が最小限に抑えられます(1%未満)。 ただし、低遅延ネットワークの特別なテストでは、同期操作での仮想化のオーバーヘッドは20%以下です。
HPCの低遅延ネットワークの重要性
物理プロセスのモデリングに関する現代の問題には、現実的な時間で実際に計算を実行できるように、大量のメモリと計算能力が必要です。 現代のテクノロジーを使用して、1つの古典的なOSの制御下で、1つのシステムでこのような大量のRAMと非常に多くのコンピューティングコアを組み合わせるのは難しく、費用がかかります。
はるかに安価で広く使用されている代替アプローチは、コンピューティングノードが独自のOSによって制御される汎用コンピューターであるクラスターシステムを作成することです。 同時に、クラスターのコンピューティングノードは、いわゆる「並列アプリケーション」の起動、保守、およびシャットダウンを保証する特別なソフトウェアによって同期され、共同で制御されます。 後者は、ネットワーク内の相互作用により互いに同期されたノードのOS内の独立したプロセスです。 さらに、このようなネットワークを「コンピューティングネットワーク」、コンピューティングノード-「クラスターノード」または単に「ノード」、制御ソフトウェア-「クラスターソフトウェア」と呼びます。
最新のプログラミング概念では、データとプロセスに応じて、2つの主要な並列化方法を使用します。 自然現象をシミュレートするには、データの並列化が最もよく使用されます。
- 計算ステップの開始時に、データの一部が異なる計算機に配信され、これらの部分に対していくつかのアクションが実行されます
- 次に、計算機は、次のステップの初期データを取得するために、さまざまな数値スキーム(通常はかなりハードコード化)に従って情報を交換します。
プログラミングの観点から見ると、計算機は、少なくとも1つのプロセッサ、一定量のメモリ、および他の計算機との交換のためのコンピューターネットワークへのアクセスを持つものであれば何でもかまいません。 実際、コンピューターは(比較的小さいとはいえ)コンピューティング能力を備えたコンピューターネットワークの加入者です。 計算機は、プロセス内のスレッド、OS内のプロセス、1つ以上の仮想プロセッサを備えた仮想マシン、および切り捨てられた特殊OSを備えたハードウェアノードなどです。
最新の並列アプリケーションを作成するための最も一般的なAPI標準はMPIであり、これはいくつかの実装に存在します。 マルチプロセッサノード上の同じOS内で並列アプリケーションを作成するように設計されたIntel OpenMP API標準も広く配布されています。 最新のクラスターノードには大量のメモリを備えたマルチコアプロセッサが含まれているため、データの並列化パラダイムのフレームワーク内で「計算機」を決定するための多数のオプションと、並列アプリケーションアプローチに基づくこのパラダイムの実装が可能です。 最も一般的なのは2つのアプローチです。
- 1つのプロセッサコア-1つの計算機
- 1つのマルチプロセッサノード-1つの計算機
最初のアプローチを実装するには、実際に作成されたMPIを使用するだけで十分です。 2番目のアプローチでは、MPIがノード間の通信に使用され、OpenMPがノード内の並列化に使用されるMPI + OpenMPバンドルがよく使用されます。
当然、並列アプリケーションが複数のノードで実行される状況では、全体のパフォーマンスはプロセッサとメモリだけでなく、ネットワークパフォーマンスにも依存します。 また、ネットワークを介した交換がマルチプロセッサシステム内の交換よりも遅いことも明らかです。 つまり クラスタシステムは、ほとんどの場合、同等のマルチプロセッサシステム(SMP)よりも低速です。 SMPマシンと比較して為替レートの低下を最小限に抑えるために、特別な低遅延コンピューターネットワークが使用されます。
コンピューティングネットワークの主な機能
特殊なコンピューターネットワークの主な特徴は、待ち時間とチャネル幅(大量のデータの交換レート)です。 大量のデータの転送速度はさまざまなタスクで重要です。たとえば、次のステップの初期データを収集するために、ノードが現在の計算ステップで得られた結果を相互に送信する必要がある場合です。 レイテンシーは、ノードがデータを必要とする他のノードの状態を知るために必要な、同期メッセージなどの小さなメッセージの送信において重要な役割を果たします。 同期メッセージは通常非常に小さい(通常は数十バイトのサイズ)が、論理的な競合とデッドロック(競合状態、デッドロック)を防ぐために使用されます。 高速の同期メッセージは、実際にコンピューティングクラスターとその最も近い相対物、つまりノード間のネットワークが低遅延プロパティを提供しないコンピューティングファームとを区別します。
Intel Infinibandは、今日最も人気のある低遅延ネットワーキング標準の1つです。 現代のクラスターシステムのコンピューターネットワークとしてよく使用されるのは、このタイプの機器です。 Infinibandネットワークにはいくつかの世代があります。 最も一般的なのは、Infiniband FDR標準(2011)です。 QDR規格(2008)は引き続き重要です。 機器サプライヤーは現在、次のInfiniband EDR規格(2014年)を積極的に推進しています。 Infinibandポートは通常、基本的な双方向バスの集合グループで構成されます。 最も一般的なポートは4xです。
最新世代のInfinibandネットワーク機能
| QDRx4 | Fdx4 | EDRx4 | |
| 全帯域幅、GB / s | 32 | 56 | 100 |
| ポート間遅延、μs | 1.3 | 0.7 | 0.7 |
ご存知のように、ゲストシステムがデバイスで動作する場合、仮想化によって特定の遅延が発生します。 この場合、低遅延のネットワークも例外ではありません。 ただし、低遅延(遅延)が最も重要な特性であるという事実により、このようなネットワークの仮想化環境との相互作用は非常に重要です。 さらに、そのスループットは、原則として、幅広い接続パラメーターで仮想化を使用しない場合と同じです。 比較的最近(2011)に作成されたInfinibandの開発における重要なステップは、SR-IOVテクノロジーの使用です。 このテクノロジーにより、Infinibandは物理ネットワークアダプターを仮想デバイスのセット-仮想VF機能に変換できます。 このようなデバイスは、独立したInfinibandアダプターのように見え、たとえば、さまざまな仮想マシンまたは負荷の高いサービスの排他制御に割り当てることができます。 当然、IB VFアダプターは他のアルゴリズムに従って動作し、その特性はSR-IOVサポートが含まれていない元のIBアダプターとは異なります。
ノード間のグループ交換操作
すでに上で述べたように、MPIライブラリは現在最も人気のあるHPCツールです。 MPI APIを実装するためのいくつかの基本的なオプションがあります。
MPIライブラリには、並列コンピューティングの実装に必要な基本機能が含まれています。 HPCアプリケーションにとって重要なのは、プロセス間メッセージング機能、特にグループ同期とメッセージング機能です。 ほとんどの場合、グループは並列アプリケーションのすべてのプロセスを指すことに注意してください。 Webで詳細なMPI APIの説明を簡単に見つけることができます。
MPIの実装に使用されるアルゴリズムの基本は[1]で詳しく説明されており、このトピックに関する多くの記事がここにあります 。 これらのアルゴリズムの有効性の評価は、多数の研究の主題です[2、3、4、5]。 ほとんどの場合、推定はアルゴリズムの理論の漸近解析の方法を使用して構築され、概念に基づいて動作します 接続セットアップ時間 情報の単位率 送信された情報単位の数 関連するプロセッサーの数。
当然、低遅延ネットワークで接続された最新のマルチプロセッサシステムの場合、パラメータ そして 同じノード内で相互作用し、異なるノード、同じマルチコアチップ、異なるプロセッサ上で相互作用するプロセッサの場合は、異なるものにする必要があります。 ただし、 そして コンピューティングクラスタの複数のノードを使用するタスクの場合、コンピューティングネットワークのレイテンシとスループットが値です。
ネットワークの「低遅延」プロパティとこのプロパティのスケーラビリティを最も要求するのは、グループ同期操作であることを理解するのは簡単です。 テストでは、他の著者[6]と同様に、次の3つの操作を使用しました。
放送する
最も単純なグループ操作はブロードキャストです。 1つのプロセスが他の全員に同じメッセージを送信します(Mはデータを含むバッファーを示します。[1]から適応)。

計算プログラムでは、特定の条件、カウントの開始時および反復間のパラメーターを伝播するためにブロードキャストがよく使用されます。 ブロードキャストは、多くの場合、他のより複雑な集合操作の実装の要素です。 たとえば、一部の実装では、ブロードキャストはバリア機能を使用します。 ブロードキャストの実装にはいくつかのオプションがあります。 ハードウェアアクセラレーションを使用しない、ノンブロッキング全二重チャネルスイッチでの最適なブロードキャスト時間は次のとおりです。
全減
all-reduce操作は、計算機グループのメモリにあるデータのパラメーターで指定された結合操作を実行し、その結果をグループのすべての計算機に報告します。 (サイン 指定された連想操作を意味します。 [1]から適応)。

ネットワーク交換の構造に関して、all-reduceはall-to-allブロードキャスト機能に似ています。 この演算は、異なる計算機にあるオペランドの最大値または最小値の合計または乗算、検索に使用されます。 この機能はバリアとして使用される場合があります。 ハードウェアアクセラレーションを使用しないノンブロッキング全二重チャネルスイッチでの最適な全削減動作時間は次のとおりです。
万能
all-to-all操作は、「パーソナライズされたall-to-all」または「total exchange」とも呼ばれます。 この操作中に、各計算機は他の計算機にメッセージを転送します。 すべてのメッセージは一意にすることができます([1]から取得)。
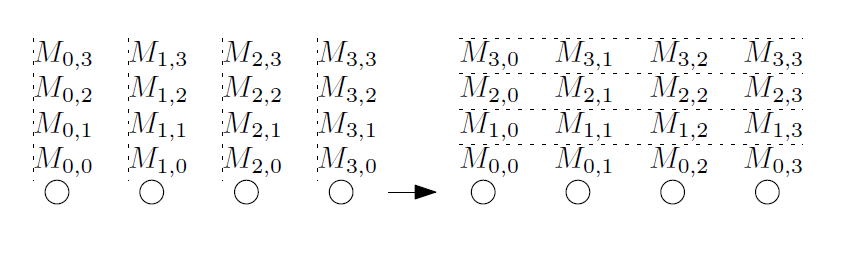
この操作は、フーリエ変換、行列変換、並べ替え、データベースの並列操作など、さまざまなアルゴリズムで集中的に使用されます。 これは、最も「難しい」集団的活動の1つです。 この集合操作の場合、最適なアルゴリズムはキー変数の値の比率に依存します 、 、 送信されたメッセージのサイズ 。 転送量に最適ではなく、小さなメッセージに使用されるハイパーキューブアルゴリズムを使用する場合、推定時間は次のとおりです。
HPC環境をテストする他のアプローチが使用されます。 たとえば、広範囲にわたる問題の計算をシミュレートする統合テストを使用します。 最も一般的な統合テストスイートの1つは、 NAS並列ベンチマークです。 このテストは、仮想HPC環境のテストにも使用されました[7]。
テスト方法
この作業で説明するパフォーマンステストでは、Intel Xeonプロセッサ64 GB RAMおよびConnectX-3 IBアダプターを搭載したサーバーを使用しました。 OpenMPIが仮想ノードと物理ノードにインストールされ、ノード間の接続はユーティリティperftestとOSUベンチマークを使用してテストされました。
詳細
Intel Xeon E5-2680v2 2.8 GHzプロセッサー(10コア、HyperThreadingがオフ)、64 GBのDDR3標準メモリー、IB Mellanox Technologies MT27500アダプターのConnectX-3ファミリー(ファームウェアConnectX3-rel-2_36_5000)を搭載したIntel H2000JFファミリー(マザーボードS2600JF)のサーバーMellanox SwitchXスイッチを介して接続(36 SX6036 FDRポート)。
OS CentOS Linuxリリース7.2.1511(CentOS 7.2)、カーネル3.10.0-327.18.2.el7.x86_64、2.3.0(CentOS 7ディストリビューションはバージョン1.5.3を使用)に基づいてカスタマイズされたqemu / KVM、Mellanox OFED 3.3ドライバー-1.0.4、qemu-kvmはNUMAモードをサポートしました。
ゲストOS CentOS Linuxリリース7.1.1503(CentOS 7.1)、カーネル3.10.0-229.el7.x86_64、Mellanox ConnectX-3ドライバー。 各仮想マシンは物理サーバー上で唯一のものであり、すべてのプロセッサーと48 GBのRAMを占有し、プロセッサーコアのオーバーコミットはオフにされました。
IBアダプターはSR-IOVサポートモードに切り替えられ、アダプターごとに2つのVFが作成されました。 VFの1つがKVMにエクスポートされました。 したがって、ゲストOSには1つのInfinibandアダプター、ホストOSには2つのmlx4_0およびmlx4_1(VF)のみが表示されていました。
OpenMPIバージョン1.10.3rc4(Mellanox OFED 3.3-1.0.4パッケージに含まれる)が仮想ノードと物理ノードにインストールされました。 ノード間の接続は、perftest 0.19.g437c173.33100ユーティリティを使用してテストされました。
グループテストは、gcc 4.8.5および上記のOpenMPIを使用してコンパイルされたOSUベンチマークバージョン5.3.1を使用して実行されました。 各OSUベンチマークの結果は、多くの条件に応じて、平均100または1000の測定値です。
tunedデーモンには、物理ノードにレイテンシパフォーマンスプロファイルがインストールされています。 仮想ノードではオフになりました。
OS CentOS Linuxリリース7.2.1511(CentOS 7.2)、カーネル3.10.0-327.18.2.el7.x86_64、2.3.0(CentOS 7ディストリビューションはバージョン1.5.3を使用)に基づいてカスタマイズされたqemu / KVM、Mellanox OFED 3.3ドライバー-1.0.4、qemu-kvmはNUMAモードをサポートしました。
ゲストOS CentOS Linuxリリース7.1.1503(CentOS 7.1)、カーネル3.10.0-229.el7.x86_64、Mellanox ConnectX-3ドライバー。 各仮想マシンは物理サーバー上で唯一のものであり、すべてのプロセッサーと48 GBのRAMを占有し、プロセッサーコアのオーバーコミットはオフにされました。
IBアダプターはSR-IOVサポートモードに切り替えられ、アダプターごとに2つのVFが作成されました。 VFの1つがKVMにエクスポートされました。 したがって、ゲストOSには1つのInfinibandアダプター、ホストOSには2つのmlx4_0およびmlx4_1(VF)のみが表示されていました。
OpenMPIバージョン1.10.3rc4(Mellanox OFED 3.3-1.0.4パッケージに含まれる)が仮想ノードと物理ノードにインストールされました。 ノード間の接続は、perftest 0.19.g437c173.33100ユーティリティを使用してテストされました。
グループテストは、gcc 4.8.5および上記のOpenMPIを使用してコンパイルされたOSUベンチマークバージョン5.3.1を使用して実行されました。 各OSUベンチマークの結果は、多くの条件に応じて、平均100または1000の測定値です。
tunedデーモンには、物理ノードにレイテンシパフォーマンスプロファイルがインストールされています。 仮想ノードではオフになりました。
テストは2つのノード(40コア)で実行されました。 測定は、一連の10〜20回の測定で実施されました。 3つの最小値の算術平均が結果として採用されました。
結果
表に示されているネットワークパラメータは理想的であり、実際の状況では達成できません。 たとえば、 ib_send_latで測定されたInfiniband FDRアダプター(データグラムモード)を備えた2つのノード間のレイテンシは、小さなメッセージに対して0.83μsであり、 ib_send_bwで測定された2つのノード間の有効なスループット(サービス情報なし)は6116.40 MB / s(〜51.3 Gbit / s)。 実際のシステムの遅延とスループットに対するペナルティは、次の要因によるものです。
- スイッチの追加遅延
- ホストOSによる遅延
- プロトコルオーバーヘッドの送信を保証するための帯域幅の損失
次のコマンドを使用して、サーバー上で起動が実行されました。
ib_send_bw -F -a -d mlx4_0
クライアント上:
ib_send_bw -F -a -d mlx4_0 <server-name>
したがって、異なる物理サーバー上にあるゲストOSのペア間のib_send_latは1.10μsのレイテンシを示し( 0.27μsの遅延増加、ネイティブIBと仮想化IBのレイテンシの比は0.75)、 ib_send_bwは6053.6 MB / s(〜50.8 Gbit / s)のスループットを示します、仮想化なしで使用可能なチャネル幅0.99)。 これらの結果は、他の著者によるテストの結果、たとえば[6]とよく一致しています。
ホストOSでは、テストがSR-IOV VFでは機能せず、アダプター自体で機能したことに注意してください。 結果は3つのグラフに表示されます。
- すべてのメッセージサイズ
- 最大256バイトまでのメッセージのみ
- ネイティブInfinibandとVFのテスト実行時間の比率
ブロードキャストテストは、ホストOSとゲストOSの両方で次のように実行されました。
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_bcast
時間の最悪の比率は0.55です。ほとんどのテストでは、比率は0.8を下回っていません。



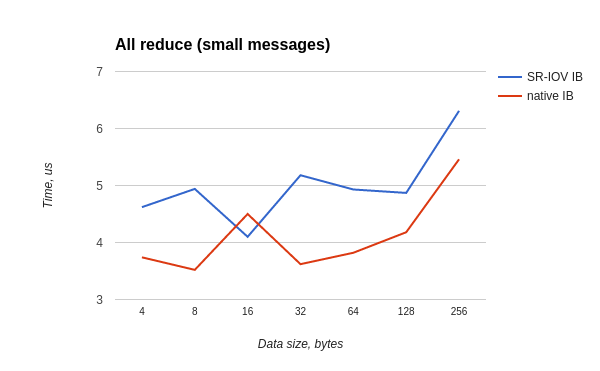
all-reduceテストは、ホストOSとゲストOSの両方で次のように実行されました。
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_allreduce
時間の最悪の比率は0.7です。ほとんどのテストでは、比率は0.8を下回っていません。


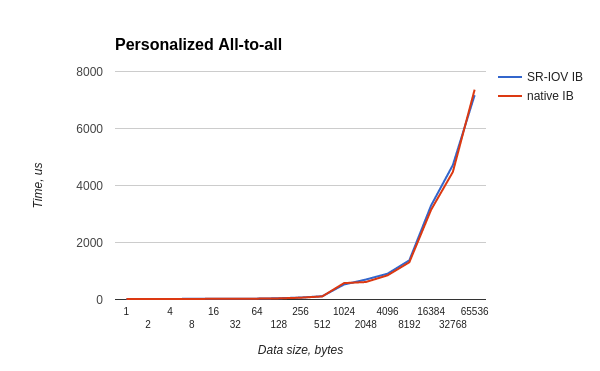
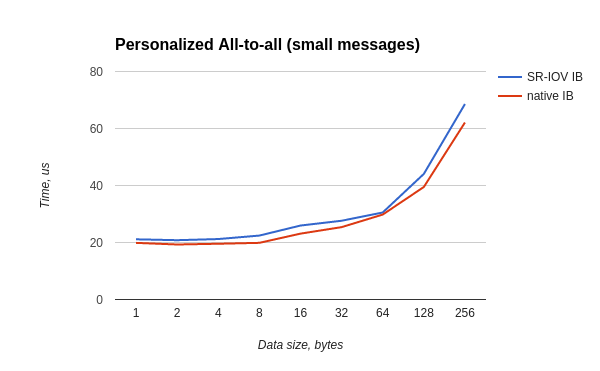
all-to-allテストは、ホストOSとゲストOSの両方で次のように実行されました。
/usr/mpi/gcc/openmpi-1.10.3rc4/bin/mpirun --hostfile mh -N 20 -bind-to core -mca pml ob1 -mca btl_openib_if_include mlx4_0:1 /usr/local/libexec/osu-micro-benchmarks/mpi/collective/osu_alltoall
時間の最悪の比率は0.87です。ほとんどのテストでは、比率は0.88を下回っていません。

議論
テストで提示されたグラフのギザギザの形状は、一方ではあまり多くのテストを選択した結果ではありませんが、他方では、プロファイリングプログラムで使用される最小の測定値を選択する方法の望ましい効果です。 このメソッドの理論的根拠は、コードフラグメントがその最大速度より速く実行できないことであり、テストコードの実行と同時にシステムで発生する可能性のあるすべてのプロセスは、速度に影響を与えないか、速度を落とします。 仮想化されたテストが非仮想化されたテストよりもわずかに速く(2-5%加速)実行される場合、一見矛盾する結果が存在するのは、IBアダプターのドライバーとファームウェアの機能に起因する必要があります。これには、まず独自の最適化スキームがあり、次に、まだ少し両方の場合で異なる動作をします(データバッファーサイズ、割り込み処理機能など)。
最新の仮想化テクノロジーの機能は、仮想化レイヤーがない状況と比較して、追加の遅延ソースを導入します。 HPCにとって重要なのは、このような遅延の3つのタイプです。
- ネットワークの遅延を遅くします。 特定のケースでは、仮想機能モードSR-IOVでのInfinibandのスローダウン。 この遅延は、この作業の中心テーマであり、上記で説明されています。
- 仮想化シェルの外部のプログラムとサービスは、プロセッサ時間を必要とする場合があり、カウントアプリケーションのキャッシュをリセットします。 これは、仮想化シェルの下で実行されているアプリケーションのカウントにさまざまな非同期化と遅延を導入するためのかなり複雑な方法です。 このような体系的な干渉は、あらゆる種類の「極端な」プログラム、または誤って最適化されたプログラムにとって非常に不快なものです。 もちろん、仮想化レイヤーがなければ、プログラムのカウントが速くなることを理解する必要があります。 ただし、実際に最も重要なケースでは、最新のマルチコアノード上の仮想化シェルの外側に制御コードが存在することによるパフォーマンスの低下は数パーセントを超えず、ほとんどの場合1%未満です。 さらに、仮想化シェルの外部の負荷を処理するプロセッサコアを分離して修正することを可能にする多数のアプローチがあり、それらを仮想化環境から除外します。 その結果、仮想化シェル内のプロセッサコアとそのキャッシュへの影響を最小限に抑えることができます。
- 仮想APICを使用する場合、ハイパーバイザーへの出口が多数あり、これは遅延(数十マイクロ秒)の点で非常に高価です。 この問題は、マルチコア仮想マシンに対するリクエストの増加に関連して最近急務となっており、さまざまな会議や専門出版物、たとえば[8、9]で注目されています。 このような遅延は、ゲストのSR-IOVデバイス(この場合はInfiniband)からの割り込みを配信するとき、およびプロセッサコアがスリープ状態(IPI)から起動するとき、たとえばメッセージを受信するときに発生します
著者の意見では、割り込み処理の仮想化ペナルティを減らす最も急進的な方法は、vAPICをサポートするIntelプロセッサーを使用するか、ノードのカウントにコンテナー仮想化(LXCなど)を使用することです。 KVMで割り込みを処理するときに発生する遅延の重要性は間接的に[7]にも示されています。著者は、割り込みの数の増加とテストの仮想化バージョンのパフォーマンスの大幅な低下との関係を確立しています。
遅延データを評価することは困難です。最初の例外を除いて、いくつかの理由により[1]で与えられたものと同様の単純な式を使用します。
- 最初の主なものは、遅延データがカウントタスクのアルゴリズムと非同期に表示されることです。これは仮想化環境で動作します
- 2番目の理由は、これらの遅延が計算ノード全体の「履歴」に依存していることです。これには、カウントタスクのアルゴリズムと仮想化ソフトウェア(キャッシュ、メモリ、コントローラーのステータス)が含まれます
また、低遅延ネットワークを介して多数のパケットを送信する場合、特に大きなメッセージを断片化する場合、複雑な法則に従って割り込みの生成速度が増加し、メッセージ送信速度の長さ、および履歴に対する重要な依存関係が現れる可能性があることを理解することも重要です仮想化ソフトウェアスタック。
従来のクラスターコンピューティングシステムの作成者は、コンピューティングタスクの干渉を排除するために多大な努力を払っています。
- すべての不要なOSサービスのシャットダウン
- すべてのネットワーク交換の最小化
- ノードの他の割り込みソースを最小限に抑える
仮想化とクラウドソフトウェアの組み合わせの場合、高性能コンピューティングのこの最適化パスの始まりに過ぎません。
結論
一般的に使用される3つのMPI操作(ブロードキャスト、すべて縮小、パーソナライズされたすべてのすべて)のセットの比較テストでは、qemu / KVMベースの仮想化環境とSR-IOVテクノロジーを使用すると、テスト時間が平均20%増加することが示されました(最悪の場合、16および32Kbのブロードキャストパケットでは80%です。 このパフォーマンスの低下は顕著ですが、連続体力学、分子動力学、信号処理などに関連するほとんどの並列アプリケーションにとって重要ではありません。 仮想化環境の使いやすさ、計算フィールドを迅速に拡張し、それを構成する機能により、カウント時間の増加の可能性のあるコストが補償されます。
1つのノードから別のノードのメモリへの高速ランダムアクセスを必要とするタスクの場合、このような遅延は重要です。 ほとんどの場合、仮想化クラスターを効果的に使用してこのような問題を解決することはできません。
実際には、コンピューティングプログラムのパフォーマンスの低下は、示されている値よりもはるかに小さいことがよくあります(最大20%)。 これは、ほとんどの場合、適切に作成され、広く使用されているプログラムが依然として計算機内のデータを読み取り、処理し、同期またはデータ転送操作を実行しないためです。 結局のところ、並列コードの作成者は常に、コンピューター間の同期と転送の必要性を最小限に抑えるようなアルゴリズムと実装手法の選択に努めています。
文学
詳細
- A.グラマ、A。グプタ、G。カリピス、V。クマール。 並列コンピューティング入門、第2版。 アディソン・ウェスリー2003
- R.タクール、W。グロップ。 スイッチドネットワークでのMpi集団通信のパフォーマンスの改善、2003
- R.タクール、R。ラベンセイフナー、W。グロップ。 MPICHでの集団通信操作の最適化。 高性能コンピューティングアプリケーションの国際ジャーナル-2005-Vol 19(1)-pp。 49-66。
- J.Pješivac-Grbović、T。Angskun、G。Bosilca、GE Fagg、E。Gabriel、JJ Dongarra。 MPI集合操作のパフォーマンス分析。 クラスターコンピューティング-2007-Vol。 10-p。127。
- BSパーソンズ。 柔軟なノード間通信と不均衡認識を備えた階層型アルゴリズムにより、MPI集合通信を加速します。 Ph。 D.コンピューター科学に関する論文、パデュー大学、米国、2015年
- J.ホセ、M。リー、X。ルー、KCカンダラ、MDアーノルド、DKパンダ。 InfiniBandクラスターでの仮想化のSR-IOVサポート:初期の経験。 クラスターに関する国際シンポジウム、2011年5月
- A.クドリャフツェフ、V。コシェレフ、A。アベティシアン。 KVMとPalaciosを使用した最新のHPCクラスター仮想化。 ハイパフォーマンスコンピューティング(HiPC)会議、2012
- D.マトラック。 KVMメッセージパッシングパフォーマンス。 KVMフォーラム、2015
- R.ヴァンリエル KVM対 メッセージパッシングスループット、コンテキストスイッチングのオーバーヘッドの削減。 Red Hat KVMフォーラム2013
素材は、アンドレイ・ニコラエフ、デニス・ルネフ、アンナ・サブボティナ、ウィルヘルム・ビットナーによって作成されました。