
CDRデータベースを作成するためのセットアップの説明にはほとんどのスペースがありません。 原則として、それはすべて、SQLコマンドを引用することと、コンソールに投げた場合に「すべてが問題ない」という約束に帰着します。
たとえば、Googleの最初のリンクでは、次の方法でタブレットを作成することを推奨しています。
CREATE TABLE `cdr` ( `calldate` datetime NOT NULL default '0000-00-00 00:00:00', `clid` varchar(80) NOT NULL default '', `src` varchar(80) NOT NULL default '', `dst` varchar(80) NOT NULL default '', `dcontext` varchar(80) NOT NULL default '', `channel` varchar(80) NOT NULL default '', `dstchannel` varchar(80) NOT NULL default '', `lastapp` varchar(80) NOT NULL default '', `lastdata` varchar(80) NOT NULL default '', `duration` int(11) NOT NULL default '0', `billsec` int(11) NOT NULL default '0', `disposition` varchar(45) NOT NULL default '', `amaflags` int(11) NOT NULL default '0', `accountcode` varchar(20) NOT NULL default '', `userfield` varchar(255) NOT NULL default '' ); ALTER TABLE `cdr` ADD INDEX ( `calldate` ); ALTER TABLE `cdr` ADD INDEX ( `dst` ); ALTER TABLE `cdr` ADD INDEX ( `accountcode` );
データベース内の少なくとも2つのインデックスが役に立たないことがすぐにわかります。 これらはコールデートとアカウントコードです。 1つ目は、1秒ごとにレコードを追加すると、インデックスサイズがデータベース自体のレコード数に等しくなるためです。 はい、このインデックスはソートされており、検索を高速化するためにいくつかの方法を適用できますが、効果的ですか? 2番目のインデックス(アカウントコード)は、だれもほとんど使用しません。 実験ベース-8000万件のレコードを持つデータベース。
リクエストを実行します:
SELECT * FROM CDR WHERE src=***** AND calldate>'2016-06-21' AND calldate<'2016-06-22'; /* Affected rows: 0 : 4 : 0 1 query: 00:09:36 */
ほぼ10分待ちます。
言い換えれば、報告が問題になります。 もちろん、タブレットを批准することはできますが、最適化を実行するのに十分な場合にそのような犠牲を払う必要があります。
注意! 本番環境では絶対にしないでください! ベースのコピーでのみ! ベースは1時間から数時間ロックされ、異常終了中にデータ損失が発生する可能性があります!
したがって、効率的なCDRストレージの成功への2つのステップ:
- 期間ごとのサンプリングを高速化するパーティション
- 効果的なインデックス作成
ステップ0.ストレージエンジンの選択
実際には、MyISAMとINNODBの2つの一般的なオプションがあります。 このテーマのHolivachenieは無限に長くなる可能性がありますが、実際のベースでエンジンを比較すると、MyISAMが有利になりました。
これにはいくつかの理由があります。
- 経験の浅い管理者によるクリーンなサーバーセットアップでは、大量のインデックスを作成する際により正確に動作するのはMyISAMです。 INNODBにはチューニングが必要です。 そうしないと、インデックスを再構築できないという興味深いエラーが表示される場合があります。
- 固定行オプションを有効にすると、MyISAMは追加のプロパティを取得します。
- サーバーがクラッシュしてもクラッシュしない
- MySQLサーバーをバイパスして、外部アプリケーションから直接ファイルを読み取る機能。これは便利です
- ランダムな回線アクセス速度は、すべての回線が同じ長さであるという事実により高速です
言い換えれば、MyISAMはロギング(IMHO)に最適です。
それについて詳しく見てみましょう。
手順1.パーティション。
データベースを補完するか、データベースから読み取ることを考えると、特定の時間間隔を読み取るときにヒットの可能性のある数を減らすために、データベースを一度にファイルに分割することが効果的です。 当然、何らかのキーでベースを壊す必要があります。 しかし、何のために? 間違いなく、時間であるべきですが、コールデートに基づいてベースを打つことは効果的ですか? したがって、次のステップで役立つ追加のフィールドを導入しないと思います。 つまり、日付。 ただの日付、時間なし。
cdrを更新する前に、追加の日付フィールドを導入し、プレートの非常に単純なトリガーを作成します。
BEGIN SET new.date=DATE(new.calldate); END
したがって、このフィールドでは日付のみを取得します。 そしてすぐにプレートを年ごとにパーティションに分割します:
ALTER TABLE cdr PARTITION BY RANGE (YEAR(date)) (PARTITION old VALUES LESS THAN (2015) ENGINE = MyISAM, PARTITION p2015 VALUES LESS THAN (2016) ENGINE = MyISAM, PARTITION p2016 VALUES LESS THAN (2017) ENGINE = MyISAM, PARTITION p2018 VALUES LESS THAN (2018) ENGINE = MyISAM, PARTITION p2019 VALUES LESS THAN (2019) ENGINE = MyISAM, PARTITION p2020 VALUES LESS THAN (2020) ENGINE = MyISAM, PARTITION p2021 VALUES LESS THAN (2021) ENGINE = MyISAM, PARTITION p2022 VALUES LESS THAN (2022) ENGINE = MyISAM, PARTITION p2023 VALUES LESS THAN (2023) ENGINE = MyISAM, PARTITION pMAXVALUE VALUES LESS THAN MAXVALUE ENGINE = MyISAM)
完了しました。現在、日付範囲で選択を行うと、MySQLはデータベース全体を何年もシャベルする必要がなくなります。 小さなプラスがすでにあります。
ステップ2.ベースにインデックスを付けます。
実際、これは最も重要なステップです。 実験では、90%のケースで(必要に応じて)3列のインデックスが必要であることが示されています。
- 日付
- src
- dst
日付
MySQLは一度に1つのインデックスしか使用できないため、一部の管理者は複合インデックスを作成しようとします。 ルールとして範囲を選択する必要があるため、その有効性はそれほど高くありません。この場合、複合インデックスはMySQLによって無視されます。 FullScanが発生します。 頬骨の動作を修正することはできませんが、スキャンの行数を最小限に抑え、使用するインデックスをエンジンに選択させることができます。 一方では、インデックスの最大の詳細が必要です。他方では、反復する範囲を取得するために、できるだけ少ない操作を費やす必要があります。 そのため、calldateではなく、日付フィールドでインデックスを使用することをお勧めします。 インデックス内の要素の数は、データベースが開始された時点からの日数に等しくなります。これにより、データベースは必要な行にすばやくジャンプできます。
データベースを支援する別の方法があります-ファイルを開く前にファイル内の行の位置を計算できるようにすることです。 このために、固定行を使用できます。 ファイル内の行の位置は、列挙ではなく、行番号に行の長さを掛けて計算されます。 当然、そのアプローチには犠牲者がいます-ベースはより多くのディスクスペースを占有します。 以下に例を示します。

ベースのサイズは18 GBから53.8 GBに増加しました。 行うかどうかは各管理者の選択ですが、サーバー上のスペースが許せば、これは別のプラスになります。
src、dst
最適化の余地がわずかにあります。 より正確には、一瞬:
たとえば、ソフトフォンでテキスト番号を使用しない場合、これらのフィールドはBigIntに変換できます。これは、インデックス付けと選択にも非常に良い効果があります。 しかし、私たちのようにテキスト番号を使用する場合、この最適化はあなたのためではなく、パフォーマンスを低下させる必要があります。
ケーキのチェリーとして-私たちは興味のないフィールドをきれいにし、フィールドのサイズを私たちの場合に期待されるように設定します。 私はこのようになった:
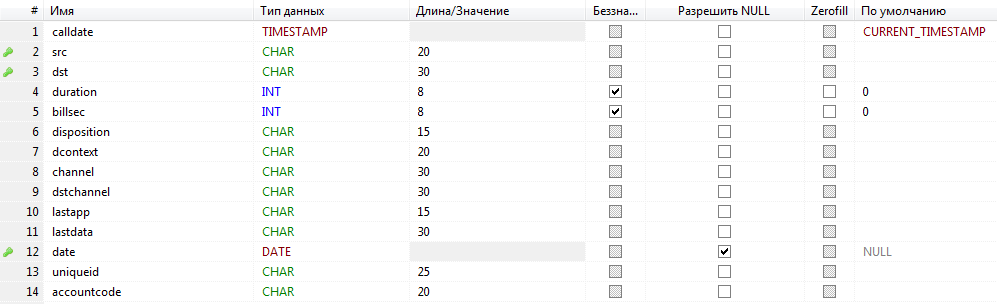
さて、最後のリクエスト:
SELECT * FROM CDR WHERE src=***** AND date='2016-06-21'; /* Affected rows: 0 : 4 : 0 1 query: 0,577 sec. */
増加は2桁です。
まだ範囲の例:
SELECT * FROM CDR WHERE src=***** AND date>'2016-09-01' AND date<'2016-09-05'; /* Affected rows: 0 : 1 : 0 1 query: 3,900 sec. */