この記事は、毎年リャザン無線工学大学で開催されている「Texas Instruments C66xマルチコアデジタル信号処理プロセッサ」プログラムの継続教育コースの一環として学生に提供される講義と実践資料を反映しています。 この記事は、科学および技術ジャーナルのいずれかでの出版を計画していましたが、検討中の問題の詳細により、マルチコアDSPプロセッサのトレーニングマニュアルの資料を蓄積することが決定されました。 それまでの間、この資料は蓄積され、インターネットに無料でアクセスできる可能性があります。 フィードバックと提案を歓迎します。
はじめに
高性能プロセッサエレメントの生産のための現代産業は、現在、マルチコアアーキテクチャへの移行に関連した特徴的なラウンドを経験しています[1、2]。 この移行は、プロセッサの自然な進化過程よりもむしろ強制的な手段です。 エネルギー効率の急激な低下により、コンピューティング性能の対応する増加に伴う、クロック周波数の小型化および増加の経路に沿った半導体技術のさらなる開発は不可能になりました。 プロセッサテクノロジのメーカーは、この状況からの論理的な方法としてマルチコアアーキテクチャへの移行を検討しました。これにより、プロセッサの処理能力を高めることができました。 このラウンドは、一般的なプロセッサテクノロジー、特に、特定のアプリケーション分野と、計算効率、内部および外部データ転送効率、低消費電力、サイズ、および価格に対する特別な要件を備えたデジタル信号処理プロセッサに一般的です。
リアルタイム信号処理システムの開発者の観点から、デジタルシグナルプロセッサ(DSP)のマルチコアアーキテクチャの使用への移行は、3つの主要な問題で表現できます。 1つ目は、ハードウェアプラットフォームの開発、その機能、特定のブロックの割り当てとそれらの動作モードであり、メーカーによって定められています[1]。 2つ目は、処理アルゴリズムの適応と、マルチコアDSP(MTsSP)での実装のためにシステムを編成する原則です[3]。 3番目は、ICMPで実装されるデジタル信号処理用のソフトウェア(ソフトウェア)の開発です。 同時に、ICSPのソフトウェアの開発には、コア間での特定のコードフラグメントの分散、データ分離、コアの同期、カーネル間のデータおよびサービス情報の交換、キャッシュの同期など、従来のシングルコアアプリケーションの開発といくつかの根本的な違いがあります。
既存の「シングルコア」ソフトウェアをマルチコアプラットフォームに移植する、または新しい「並列」ソフトウェア製品を開発するための最も魅力的なソリューションの1つは、Open Multi-Processing(OpenMP)ツールです。 OpenMPは、主に最も一般的なC言語の標準プログラミング言語に埋め込むことができるコンパイラディレクティブ、関数、および環境変数のセットであり、並列コンピューティングを整理することにより機能を拡張します。 これがOpenMPアプローチの主な利点です。 新しい並列プログラミング言語を発明/学習する必要はありません。 標準コードのコンパイラに単純で明確なディレクティブを追加することにより、シングルコアプログラムは簡単にマルチコアプログラムに変わります。 必要なのは、このプロセッサーのコンパイラーがOpenMPをサポートすることだけです。 つまり、プロセッサーの製造元は、コンパイラーがOpenMP標準ディレクティブを「理解」し、対応するアセンブラーコードに変換することを確認する必要があります。
OpenMP標準は、いくつかの主要なコンピューターメーカーの協会によって開発され、OpenMP Architecture Review Board(ARB)[4]によって規制されています。 さらに、これは汎用であり、特定のメーカーの特定のハードウェアプラットフォーム向けではありません。 ARBは、標準の将来のバージョンの仕様を公開しています[5]。 OpenMP [6]のクイックリファレンスも興味深いものです。
最近、膨大な数の作品が、さまざまなアプリケーションおよびさまざまなプラットフォームでのOpenMPの使用に注がれています[7-12]。 特に興味深いのは、OpenMPの使用に関する基本的な知識を完全に身につけることができる本です。 国内の文献では、これらは情報源です[13-16]。
このペーパーでは、OpenMPのディレクティブ、関数、環境変数について説明します。 この場合、作業の詳細は、デジタル信号処理のタスクに対する方向です。 特定のディレクティブの意味を示す例は、ICSPでの実装に重点を置いています。 ハードウェアプラットフォームとして、8つのDSPコアを含むTexas InstrumentsのMTsSP TMS320C6678プロセッサ[17]を選択しました。 このICSPプラットフォームは、国内市場で最も先進的な需要の1つです。 さらに、このペーパーでは、リアルタイム信号処理タスクに関連するOpenMPメカニズムの内部組織の問題、および最適化の問題を検討しています。
問題の声明
したがって、処理タスクは、同じ長さの2つの入力信号の合計として出力信号を生成することになります。
z(n) = x(n) + y(n), n = 0, 1, …, N-1
標準C / C ++言語でのこのタスクの「シングルコア」実装は、次のようになります。
void vecsum(float * x, float * y, float * z, int N) { for ( int i=0; i<N; i++) z[i] = x[i] + y[i]; }
今、8コアプロセッサTMS320C6678があるとします。 問題は、マルチコアアーキテクチャの機能を使用してこのプログラムを実装する方法ですか?
1つの解決策は、8つの別個のプログラムを開発し、それらを8つのコアに個別にロードすることです。 これには、メモリ内の配列の位置、カーネル間の配列の部分の分離など、共同実行ルールを考慮する必要がある8つの個別のプロジェクトが存在します。 さらに、コアを同期する追加プログラムを作成する必要があります。1つのコアがアレイの一部の形成を完了した場合、これはアレイ全体の準備ができていることを意味しません。 すべてのコアの完了を手動で確認するか、すべてのコアからフラグを送信して1つの「メイン」コアの処理を完了する必要があります。これにより、出力配列の準備状況に関する適切なメッセージが表示されます。
説明したアプローチは正確かつ効果的ですが、実装するのは非常に難しく、いずれにしても開発者は既存のソフトウェアを大幅に改良する必要があります。 ソースコードへの最小限の変更で、シングルコアからマルチコアへの実装に移行できるようにしたいと考えています。 これがOpenMPが解決する問題です。
OpenMPの初期設定
プログラムでOpenMPを使用する前に、明らかに、この機能をプロジェクトに接続する必要があります。 TMS320C6678プロセッサの場合、これはプロジェクト構成ファイルと使用するプラットフォームを変更すること、およびプロジェクトプロパティにOpenMPコンポーネントへのリンクを含めることを意味します。 この記事では、特定のハードウェアプラットフォームに固有のこのような設定は考慮しません。 より一般的な初期OpenMP設定を検討してください。
OpenMPはC言語の拡張機能であるため、プログラムにディレクティブと機能を含めるには、この機能の説明ファイルを含める必要があります。
#include <ti/omp/omp.h>
次に、処理するコアの数をコンパイラー(およびOpenMP機能)に伝える必要があります。 OpenMPはカーネルではなく、並列スレッドで動作することに注意してください。 並列フローは論理的な概念であり、コアは物理的なハードウェアです。 特に、複数の並列スレッドを1つのコアに実装できます。 同時に、コードの真の並列実行は、当然、並列スレッドの数がコアの数と一致し、各スレッドが独自のコアに実装されていることを意味します。 将来的には、これがまさに状況のように見えると仮定します。 ただし、並列スレッドの数とその実装のカーネル番号は一致する必要がないことに注意してください!
OpenMPの初期設定に、次のOpenMP関数を使用して並列スレッドの数を割り当てます。
omp_set_num_threads(8);
コア(スレッド)の数を8に設定します。
並列ディレクティブ
したがって、上記のプログラムのコードを8コアで実行する必要があります。 OpenMPでは、次のようにコードにparallelディレクティブを追加するだけです。
#include <ti/omp/omp.h> void vecsum (float * x, float * y, float * z, int N) { omp_set_num_threads(8); #pragma omp parallel { for ( int i=0; i<N; i++) z[i] = x[i] + y[i]; } }
すべてのOpenMPディレクティブは、次の形式の構造の形式で発行されます。
#pragma omp <_> [[(,)][[(,)]] …].
私たちの場合、オプションを使用しません。並列ディレクティブは、中括弧で強調表示された次のコードフラグメントが並列領域を参照し、1つではなく指定されたコア全体で実行する必要があることを意味します。
1つのメインコアまたはリーディングコア(マスターコア)で実行されるプログラムを取得し、パラレルディレクティブで強調表示されているフラグメントは、リーディングカーネルとスレーブカーネルの両方を含む特定の数のコアで実行されます。 結果の実装では、同じサイクルの加算ベクトルが8コアですぐに実行されます。
OpenMPでの並列コンピューティングの典型的な組織構造を図1に示します。
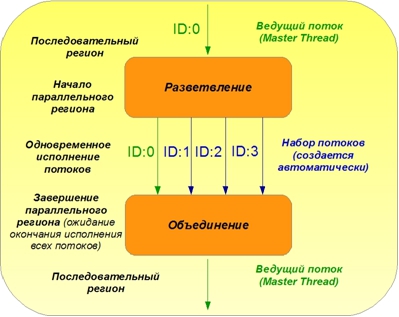
図1. OpenMPでの並列コンピューティングの原理
プログラムコードの実行は常に、マスタースレッドの1つのコアで実行される順次領域から始まります。 対応するOpenMPディレクティブで示される並列領域の開始点で、ストリームセット(並列領域)のOpenMPディレクティブに続くコードの並列実行の編成が行われます。 簡単にするために、図には4つの並列フローのみが示されています。 並列領域の終わりで、フローは結合され、互いの作業の完了を待ってから、順次領域が再び続きます。
したがって、プログラムを実装するために8つのコアを使用することができましたが、すべてのコアが同じ作業を行うため、このような並列化には意味がありません。 8つのコアが8回同じ出力データ配列を形成しました。 処理時間は短縮されていません。 明らかに、作業を異なるコアに分割する必要があります。
アナロジーを描きましょう。 8人のチームを作りましょう。 それらの1つがメインです。 残りは彼のアシスタントです。 彼らはさまざまな活動のリクエストを受け取ります。 主な従業員は注文を受け入れて実行し、可能な場合はアシスタントを接続します。 従業員が最初に取り組んだ作業は、テキストを英語からロシア語に翻訳することでした。 チームリーダーは作業を開始し、ソーステキストを取り、辞書を準備し、各アシスタントのテキストをコピーして、同じテキストを全員に配布しました。 翻訳が完了します。 タスクは正しく解決されます。 ただし、7人のアシスタントがいることによる利益はありません。 まったく逆です。 同じディクショナリ、コンピューター、またはソースコードを共有する必要がある場合、タスクを完了するのに時間がかかることがあります。 OpenMPは最初の例でも機能します。 仕事の分離が必要です。 各従業員は、一般的なテキストのどの部分を自分が翻訳すべきかを示す必要があります。
配列を合計する問題のコンテキストでカーネル間で作業を分割する明らかな方法は、カーネルの数に応じてカーネル間でサイクルの反復を分散することです。 コードが実行されているカーネルを見つけ、この数に応じてループの反復範囲を設定するには、並列領域内で十分です。
#include <ti/omp/omp.h> void vecsum (float * x, float * y, float * z, int N) { omp_set_num_threads(8); #pragma omp parallel { core_num = omp_get_thread_num(); a=(N/8)*core_num; b=a+N/8; for (int i=a; i<b; i++) z[i] = x[i] + y[i]; } }
カーネル番号は、OpenMP関数omp_get_thread_num();によって読み取られます。 この機能は、並列領域内ではすべてのコアで同じように実行されますが、異なるコアでは異なる結果が得られます。 これにより、並列領域内で作業をさらに分割することが可能になります。 簡単にするために、サイクルNの反復回数はカーネル数の倍数であると仮定します。 カーネル番号の読み取りは、特別なカーネル番号レジスタ(TMS320C6678プロセッサのDNUMレジスタ)の各コアの存在に基づくハードウェアに基づいて行うことができます。 アセンブラコマンドやCSLチップサポートライブラリの機能など、さまざまな方法でアクセスできます。 ただし、OpenMPアドインが提供する機能を利用できます。 ただし、ここでは、OpenMPのカーネル番号と並列領域番号が異なる概念であるという事実に再び注意を払う必要があります。 たとえば、3番目の並列スレッドは、たとえば5番目のコアで実行されます。 さらに、次の並列領域で、または同じ並列領域を通過するときに、たとえば4番目のコアで3番目のスレッドを実行できます。 などなど。
8コアで実行されるプログラムがありました。 各コアは入力配列の独自の部分を処理し、出力配列の対応する領域を形成します。 各従業員はテキストの1/8の部分を翻訳し、理想的には、問題を解決するのに8倍の加速を得ることができます。
ForおよびParallel forディレクティブ
最も単純なディレクティブparallelを検討しました。これにより、複数のコアで並行して実行する必要があるコード内のフラグメントを選択できます。 ただし、このディレクティブは、すべてのカーネルが同じコードを実行し、作業の分離がないことを意味します。 私たちは自分でそれをしなければなりませんでした。
並列領域内の作業がカーネル間でどのように分割されるかを自動的に示し、場合によっては追加のforディレクティブを使用します。 このディレクティブはfor型のループの直前の並列領域内で使用され、カーネル間でループの繰り返しを分散する必要があることを示します。 並列ディレクティブとforディレクティブは別々に使用できます。
#pragma omp parallel #pragma omp for
また、レコードを削減するために、1つのディレクティブで一緒に使用できます。
#pragma omp parallel for
配列の例でディレクティブfor parallelを使用すると、次のプログラムコードになります。
#include <ti/omp/omp.h> void vecsum (float * x, float * y, float * z, int N) { int i; omp_set_num_threads(8); #pragma omp parallel for for (i=0; i<N; i++) z[i] = x[i] + y[i]; }
このプログラムを元のシングルコア実装と比較すると、違いはごくわずかであることがわかります。 omp.hヘッダーファイルを接続し、パラレルスレッドの数を設定し、1行(パラレルforディレクティブ)を追加しました。
注釈1.推論で意図的に隠すもう1つの違いは、変数iの宣言をループから関数変数を記述するセクションに、より正確にはコードの並列領域から順次領域に転送することです。 このアクションを説明するには時期尚早ですが、これは基本的なものであり、プライベートオプションと共有オプションに関するセクションで後ほど説明します。
備考2.ループの繰り返しはカーネル間で分割されると言いますが、どのように正確に分割されるかは述べていません。 どのコアで実行されるサイクルの具体的な反復は何ですか? OpenMPには、並列スレッドに反復を分散するためのルールを設定する機能があります。これらの機能については後で説明します。 ただし、以前に検討した方法で手動でのみ特定のカーネルを特定の反復に固定することができます。 確かに、通常、このようなバインディングは必要ありません。 サイクルの反復回数がカーネル数の倍数でない場合、カーネル全体の反復の分散が実行され、負荷が可能な限り均等に分散されます。
セクションと並列セクションのディレクティブ
コア間の作業の分離は、データの分離に基づいて、またはタスクの分離に基づいて行うことができます。 アナロジーを思い出してください。 すべての従業員が同じこと(テキストを翻訳している)をしているが、それぞれが異なるテキストを翻訳している場合、これは最初のタイプの作業区分、つまりデータ分離を意味します。 従業員がさまざまなアクションを実行する場合、たとえば、1つはテキスト全体を翻訳し、もう1つは彼の辞書で単語を探し、3つ目は翻訳テキストを入力します。 調査した並列ディレクティブとforディレクティブにより、データを分割して作業を共有できました。 カーネル間でタスクを分離すると、セクションディレクティブを実行できます。これは、forディレクティブの場合のように、パラレルディレクティブとは独立して、または一緒に使用してレコードを削減できます。
#pragma omp parallel #pragma omp sections
そして
#pragma omp parallel sections
例として、3つのプロセッサコアを使用するプログラムを提供します。各コアは、入力信号xを処理する独自のアルゴリズムを実行します。
#include <ti/omp/omp.h> void sect_example (float* x) { omp_set_num_threads(3); #pragma omp parallel sections { #pragma omp section Algorithm1(x); #pragma omp section Algorithm2(x); #pragma omp section Algorithm3(x); } }
共有、プライベート、デフォルトのオプション
検討のために新しい例を選択します。 2つのベクトルのスカラー積を計算します。 この手順を実装する単純なCプログラムは次のようになります。
float x[N]; float y[N]; void dotp (void) { int i; float sum; sum = 0; for (i=0; i<N; i++) sum = sum + x[i]*y[i]; }
実行結果(16要素のテスト配列の場合)は等しいことが判明しました。
[TMS320C66x_0] sum = 331.0
parallel forディレクティブを使用して、このプログラムの並列実装に進みましょう。
float x[N]; float y[N]; void dotp (void) { int i; float sum; sum = 0; #pragmaomp parallel for { for (i=0; i<N; i++) sum = sum + x[i]*y[i]; } }
実行結果:
[TMS320C66x_0] sum= 6.0
プログラムは間違った結果を出します! なんで?
この質問に答えるには、変数の値がシーケンシャル領域とパラレル領域でどのように接続されているかを理解する必要があります。 OpenMPのロジックについて詳しく説明します。
dotp()関数は、0番目のプロセッサコアのシーケンシャル領域として実行を開始します。 同時に、配列xおよびyは、変数Iおよびsumと同様に、プロセッサメモリ内で編成されます。 parallelディレクティブに達すると、OpenMPユーティリティ関数が機能し、コアの後続の並列操作を整理します。 カーネルは初期化され、同期され、データが準備され、一般的な開始が行われます。 変数と配列はどうなりますか?
OpenMPのすべてのオブジェクト(変数と配列)は、共有(共有)とプライベート(プライベート)に分けることができます。 共有オブジェクトは共有メモリに配置され、並列領域内のすべてのコアによって同じ基盤で使用されます。 共通オブジェクトは、順次領域内の同じ名前のオブジェクトと一致します。 それらはその意味を保持したまま、シーケンシャルからリージョンに平行に移動し、変更なしに戻ります。 並列領域内のそのようなオブジェクトへのアクセスは、すべてのコアに対して同じ基盤で実行され、共有の競合が発生する可能性があります。 この例では、変数xとyの配列はデフォルトで共通であることが判明しました。 すべてのコアがバッテリーと同じ変数合計を使用することがわかりました。 その結果、いくつかのコアがバッテリーの同じ電流値を同時に読み取り、それらに部分的な寄与を追加し、新しい値をバッテリーに書き込む状況が時々発生します。 同時に、最後に記録したコアは他のコアの結果を消去します。 このため、この例では間違った結果が出ました。
一般変数とプライベート変数を使用する原理を図2に示します。
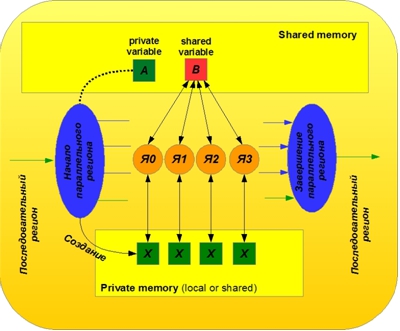
図2.パブリック変数とプライベート変数を操作するOpenMPの図
プライベートオブジェクトは、コアごとに個別に作成された元のオブジェクトのコピーです。 これらのコピーは、並列領域の初期化中に動的に作成されます。 この例では、ループ反復カウンターとしての変数iはデフォルトでプライベートと見なされます。 並列ディレクティブに到達すると、この変数の8つのコピー(並列スレッドの数による)がプロセッサメモリに作成されます。 プライベート変数は、各コアのプライベートメモリに配置されます(ローカルメモリに配置することも、一般に、変数の宣言方法やメモリの構成方法に応じて配置することもできます)。 プライベートコピーは、シーケンシャルリージョンのソースオブジェクトに決して関連付けられません。 デフォルトでは、ソースオブジェクトの値は並列領域に転送されません。 オブジェクトのプライベートコピーが、並列領域実行の開始時にどのようになっているかはわかりません。 並列領域の最後で、プライベートコピーの値は、これらの値を順次領域に転送するための特別な措置が講じられない限り、単に失われます。これについては後で説明します。
どのオブジェクトをプライベートと見なすべきか、どのオブジェクトを共通と見なすかをコンパイラーに明示的に伝えるために、OpenMPディレクティブとともに共有およびプライベートオプションが使用されます。 一般またはプライベートに関連するオブジェクトのリストは、対応するオプションの後に括弧で囲まれたカンマで示されます。 この場合、変数iとsumはプライベートであり、配列xとyは共有されている必要があります。 したがって、次の形式の構造を使用します。
#pragma omp parallel for private(i, sum) shared(x, y)
並列領域を開くとき。 これで、各コアには独自のバッテリーがあり、蓄積は互いに独立して行われます。 さらに、初期値が不明なので、バッテリーをゼロにリセットする必要があります。 さらに、各コアで得られた特定の結果をどのように組み合わせるかという問題が生じます。 1つのオプションは、8セルの特殊な共通配列を使用することです。各コアは結果を並列領域内に配置し、並列領域を離れた後、メインコアはこの配列の要素を合計して最終結果を形成します。 次のプログラムコードを取得します。
float x[N]; float y[N]; float z[8]; void dotp (void) { int i, core_num; float sum; sum = 0; #pragma omp parallel private(i, sum, core_num) shared(x, y, z) { core_num = omp_get_thread_num(); sum = 0; #pragma omp for for (i=0; i<N; i++) sum = sum + x[i]*y[i]; z[core_num] = sum; } for (i=0; i<8; i++) sum = sum + z[i]; }
実行結果:
[TMS320C66x_0] sum= 331.0
プログラムは正しく動作しますが、少し面倒です。 さらに単純化する方法について説明します。
興味深いのは、並列領域の初期化中にOpenMP配列名をプライベートオブジェクトとして指定すると、変数の場合と同じように動作することです。これらの配列のプライベートコピーが動的に作成されます。 これは、簡単な実験を行うことで確認できます。プライベートオプションを使用して配列を宣言し、この配列へのポインターの値をシリアルおよびパラレル領域で出力します。 9つの異なるアドレスが表示されます(コアの数-8)。
次に、配列の要素の値が互いに関連していないことを確認できます。 また、同じ並列領域を続けて入力すると、配列のプライベートコピーのアドレスが異なる場合があり、デフォルトでは要素値は保存されません。 これはすべて、並列領域を開いたり閉じたりするOpenMPディレクティブが非常に面倒であり、特定の実行時間を必要とするという事実につながります。
並列領域を開くためのディレクティブでオブジェクトのタイプ(パブリック/プライベート)が明示的に示されていない場合、OpenMPは[5]で説明されている特定のルールに従って「動作」します。 OpenMPオブジェクトはデフォルトとして説明されていません。 タイプがプライベートであるか共有であるかは、OpenMP操作のパラメーターの1つである環境変数によって決まります。このパラメーターは、操作中に設定および変更できます。例外は、ループ反復カウンターとして使用される変数です。デフォルトではプライベートと見なされます。確かに、この規則はforやparallel forなどのディレクティブにのみ適用されるため、これらの変数には特に注意を払うことをお勧めします。
この点で、デフォルトオプションを使用すると便利です。このオプションを使用すると、ルールが適用されるオブジェクト(デフォルトのタイプ)を指定できます。同時に、このオプションのパラメーターとしてnoneを選択した場合、変数はデフォルトの型を受け入れられないことを意味します。つまり、並列領域で発生したすべてのオブジェクトの型の必須の明示的な指示が必要です。
#pragma omp parallel private(sum, core_num) shared(x, y, z) default(i)
または:
#pragma omp parallel private(i, sum, core_num) shared(x, y, z) default(none)
削減オプション
8つのコアにスカラー積を実装する考慮された例では、1つの欠点に注意しました。コアの部分的な結果を結合するにはコードを大幅に変更する必要があり、面倒で不便です。同時に、openMPの概念は、シングルコアからマルチコアへの実装、またはその逆への移行における最大の透明性を意味します。前のセクションで説明したプログラムを簡素化するために、削減オプションを使用できます。
削減オプションを使用すると、カーネルの結果を結合する必要があることをコンパイラーに伝えることができ、そのような結合の規則を設定できます。削減オプションは、多くの最も一般的な状況に対応しています。オプションの構文は次のとおりです。
reduction ( : )
identifier-プライベートな結果を結合するどの操作を実行するかを決定します。特定の結果を表す変数の初期値を設定します。
オブジェクトのリスト—カーネルの操作の特定の結果を定式化するために使用される変数の名前
現在OpenMP標準で提供されている削減オプションを使用するためのすべての可能なオプションを表1に示します。
可能な操作識別子:+、*、-、&、|、^、&&、||、max、min
対応する変数の初期値:0、 1、0、0、0、0、1、0、このタイプの最小値、このタイプの最大値。
スカラー製品プログラムでは、sum変数に識別子「+」を指定した縮約オプションを使用します。
float x[N]; float y[N]; void dotp (void) { int i; float sum; #pragma omp parallel for private(i) shared(x, y) reduction(+:sum) for (i=0; i<N; i++) sum += x[i]*y[i]; }
実行結果:
[TMS320C66x_0] sum= 331.0
プログラムは正しい結果を提供すると同時に、非常にコンパクトに見え、元の「シーケンシャル」コードとの最小限の違いのみを含みます!
OpenMP Sync
マルチコアプロセッサで発生する主な問題の1つは、コアの同期の問題です。複数のコアが1つの一般的な問題を同時に解決する場合、原則として、アクションを調整する必要があります。あるコアが別のコアよりも早くいくつかの機能を実行し始めると、一般的な作業の結果が不正確になることがあります。すべてのカーネルが1つの共通変数で動作するようにしたときに、すでにこの問題に部分的に遭遇しました。矛盾は間違った結果をもたらしました。
一般的な場合、カーネルの同期は、プログラムコードの特定のポイントですべてのカーネルまたはその必要な部分が作業を停止し、特定のポイント(同期ポイント)に到達することを他のカーネルに通知し、他のすべてのカーネルがこのポイントに到達するまで作業を続行しないという事実から成ります同期。 1つの並列フラグメントを完了すると、ニュークリアスは互いに待機し、次のフラグメントに移動して作業を調整します。コア(または並列スレッド)の同期は、実行可能なプログラムコードによる同期だけでなく、データによる同期も意味することに注意することが重要です。キャッシュの同期があります:キャッシュで変更されたデータのメインメモリへの戻り。これは非常に重要なポイントです。OpenMPコンセプトのカーネルは主に共有メモリで動作し、そのフラグメントは各コアのローカルメモリにキャッシュされます。その結果、最初のコアのキャッシュと共有(メイン)メモリの非同期化により、1つのコアによって変更された共有変数の値が他のコアによって正しく読み取られない場合があります。
OpenMPには、暗黙的と明示的の2種類の同期があります。暗黙的な同期は、並列領域の終わり、およびomp for、ompセクションなどを含む並列領域内に適用できるいくつかのディレクティブの終わりで自動的に発生します。この場合、キャッシュの同期も自動的に行われます。
問題を解決するためのアルゴリズムが、自動同期が提供されない並列領域内のプログラムのそれらのポイントでカーネルを同期する必要がある場合、開発者は明示的な同期を使用できます-特別なディレクティブを使用してOpenMPコンパイラに、プログラムのこのポイントで同期が必要であることを明示的に示します これらのディレクティブのメインを検討してください。
バリア指令
バリアディレクティブは次のように記述されます。
#pragma omp barrier
並列領域内の並列OpenMPストリームの同期ポイントを明示的に設定します。以下は、ディレクティブの使用例です。
#define CORE_NUM 8 float z[CORE_NUM]; void arr_proc(void) { omp_set_num_threads(CORE_NUM); int i, core_num; float sum; #pragma omp parallel private(core_num, i, sum) { core_num=omp_get_thread_num(); z[core_num]=core_num; #pragma omp barrier sum = 0; for(i=0;i<CORE_NUM;i++) sum=sum+z[i]; #pragma omp barrier z[core_num]=sum; } for(i=0;i<CORE_NUM;i++) printf("z[%d] = %f\n", i, z[i]); }
このプログラムでは、次の状況をシミュレートしました。信号の処理に、z配列でデータを生成するステップ、z配列でデータを処理するステップ、z配列で処理結果を記録するステップを含めます。プログラムの場合、最初の段階で、各コアは共有メモリにあるz配列の対応するセルにその番号を書き込みます。さらに、すべてのコアは入力配列の同じ処理を実行します。つまり、要素の合計を見つけます。次に、すべてのカーネルが、カーネル番号に対応するz配列のセルに結果を書き込みます。結果として、配列内のすべてのセルは同じでなければなりません。ただし、これはバリアディレクティブがなければ発生しません。配列zのすべてのセルは異なり、一般的には任意です。第1段階から第2段階に移行すると、カーネルはお互いを待たずに、まだ準備ができていないデータの処理を開始します。2番目の段階から3番目の段階に移行すると、カーネルは結果をz配列に書き込み始めますが、他のカーネルはこの配列の値を読み取って処理に使用できます。両方のバリアディレクティブの存在のみが、プログラムの正しい実行と、z配列のすべての要素での同じ計算結果の記録を保証します。実行可能コードによる同期は、データの同期-キャッシュ同期も意味します。
重要な指令
重要なディレクティブは次のように書かれています。
#pragma omp critical [ ]
また、一度に1つのコアのみが実行できる並列領域内のコードを選択します。
, . . , , , , . , . , . , , : , , ; .
信号処理の場合、状況は同様です。特定のコードフラグメントを複数のコアで同時に実行できないことを処理アルゴリズムが示唆している場合、そのようなフラグメントはcriticalディレクティブによって区別できます。このディレクティブの適用例は次のようになります。
#define CORE_NUM 8 #define N 1000 #define M 80 void crit_ex(void) { int i, j; int A[N]; int Z[N] = {0}; omp_set_num_threads(CORE_NUM); #pragma omp parallel for private (A) for (i = 0; i < M; i++) { poc_A(A, N); #pragma omp critical for (j=0; j<N; j++) Z[j] = Z[j] + A[j]; } }
このプログラムでは、配列Aの処理(配列)と配列Zの処理結果の蓄積が1サイクルでM回繰り返され、マルチコア実装に移行すると、処理サイクルの反復が8コアに分散されます。この場合、配列Aはプライベート配列として、つまり各コアで独立して処理されます。これらの手順には依存関係がないため、処理はすべてのコアで並行して実行できます。蓄積すると、すべてのコアの作業結果が共通のZ配列に結合されます。コアを同期するための特別な措置が取られない場合、並列スレッドは1つの共通リソースにアクセスし、互いの作業にエラーを導入します。エラーを防ぐために、この場所で並列スレッドが実行されるのを防ぐことができます。リソース(この場合はコードの一部)を引き継ぐ最初のコアが完全にそれを所有し、すべてのステップを完了するまで。残りのコアは、コードのクリティカルセクションの開始時にリソースが解放されるのを待ちます。実際、並列領域内の順次処理に移行しています。
コードでは、クリティカルセクションを次の構造に置き換えます。
#pragma omp critical (Z1add) for (j=0; j<N; j++) Z1[j] = Z1[j] + A[j]; #pragma omp critical (Z2mult) for (j=0; j<N; j++) Z2[j] = Z2[j] * A[j];
現在、2つの重要なセクションがあります。1つは、核の仕事の結果を合計することによって組み合わせることです。もう1つは、乗算です。両方のセクションは1つのコアでのみ同時に実行できますが、異なるセクションは異なるコアで同時に実行できます。領域名がクリティカルディレクティブデザインに追加された場合、別のカーネルがこの領域で動作する場合のみ、カーネルはコードへのアクセスを拒否されます。リージョンに名前が割り当てられていない場合、他のカーネルがどのリージョンでも接続されていなくても、他のカーネルがそれらのリージョンのいずれかで動作する場合、カーネルはクリティカルリージョンを入力できません。
アトミックディレクティブ
アトミックディレクティブは次のように記述されます。
#pragma omp atomic [read | write | update | capture]
前の例では、異なるコアが同じ領域から同時にコードを実行することは禁止されていました。しかし、これは綿密な調査では合理的に思えないかもしれません。結局のところ、共有リソースへのアクセスの競合は、異なるカーネルが同じメモリセルに同時にアクセスできるという事実にあります。 1つのコードのフレームワーク内で、異なるメモリセルにアクセスしても、結果が歪むことはありません。 atomicディレクティブを使用すると、カーネルの同期をメモリ要素にバインドできます。彼女は次の行でメモリ操作はアトミックである-不可解であることを指摘します:カーネルが何らかのメモリセルで操作を開始すると、最初のコアが動作を終了するまで他のすべてのカーネルに対してこのメモリセルへのアクセスが閉じられます彼女。アトミックディレクティブには、オプションを示すメモリで実行される操作の種類:読み取り/書き込み/変更/キャプチャ。上記の例は、atomicディレクティブを使用すると、次のようになります。
#define CORE_NUM 8 #define N 1000 #define M 80 void crit_ex(void) { int i, j; int A[N]; int Z[N] = {0}; omp_set_num_threads(CORE_NUM); #pragma omp parallel for private (A) for (i = 0; i < M; i++) { poc_A(A, N); for (j=0; j<N; j++) { #pragma omp atomic update Z[j] = Z[j] + A[j]; } }
理論的には、アトミックディレクティブを使用すると、サイクルの完全な順次実行から、要求された配列要素の数が異なるコアで一致する場合に個々のメモリアクセス操作のみの順次実行に進むため、処理時間が大幅に短縮されます。ただし、実際には、このアイデアの有効性は、その実装方法によって異なります。たとえば、アトミックディレクティブを使用したカーネル同期が、ループの各反復で共有メモリにあるフラグの読み取りに減ると、ループの実行時間が大幅に増加する可能性があります。言い換えると、クリティカルディレクティブの場合、サイクル実行時間はMxT1プロセッササイクルになります。ここで、Mはコアの数、T1は1つのコアのサイクル時間です。アトミックディレクティブの場合、サイクルタイムはT2プロセッササイクルになります。この場合、アトミックディレクティブを含むサイクルには追加の同期コードが含まれ、時間T2は時間T1のM倍以上になることがあります。
この記事では、OpenMPの主要な構成要素である、マルチコアプロセッサに実装するためのソフトウェアのコンパイラによる自動並列化に使用される高レベルプログラミング言語(C / C ++)の拡張機能について説明しました。この記事の特徴は、デジタル信号処理システムのオリエンテーションと、Texas Instrumentsの8コアDSP TMS320C6678でのサンプルプログラムの実行の説明です。 OpenMPの主な利点は、シングルコアからマルチコア実装への移行が容易なことです。データ交換や同期を含むすべてのコアインタラクションタスクは、コンパイル段階で接続される標準OpenMP関数によって実行されます。ただし、開発の利便性は、通常、結果のソリューションの効率の低下につながります。この記事では、OpenMPのツーリングコストについては説明しません。これに別の仕事を捧げることが計画されています。
それにも関わらず、OpenMPディレクティブのコストは非常に高く、単位と数万クロックサイクルで測定されます。したがって、並列化は比較的高いレベルでのみ意味があります。並列領域内で計算負荷が大きく、ほとんどの場合、カーネルは相互作用せずにタスクを処理します。
OpenMP標準は共通のイデオロギーを規定していることにも注意する必要があります。OpenMPの有効性は、特定のプロセッサプラットフォーム用のOpenMP関数の実装に依存します。そのため、プロセッサTMS320C6678用にTexas Instrumentsが開発したOpenMP 1および2のバージョンは大きく異なります。2番目のバージョンは、多数のハードウェアメカニズムを使用してニュークリアスの相互作用を加速し、最初のバージョンよりもはるかに効果的です。その後の作業では、OpenMP機能を実装するための主要なメカニズムを明らかにする予定です。これらの機能に関連するコストを分析します。OpenMPディレクティブの実装のテスト時間の見積もりを生成します。このメカニズムの使用効率を改善するためのアドバイスを作成します。
文学
1. G. Blake, RG Dreslinski, T. Mudge, «A survey of multicore processors,» Signal Processing Magazine, vol. 26, no. 6, pp. 26-37, Nov. 2009.
2. LJ Karam, I. AlKamal, A. Gatherer, GA Frantz, «Trends in multicore DSP platforms,» Signal Processing Magazine, vol. 26, no. 6, pp. 38-49, 2009.
3. A. Jain, R. Shankar. Software Decomposition for Multicore Architectures, Dept. of Computer Science and Engineering, Florida Atlantic University, Boca Raton, FL, 33431.
4. Web- OpenMP Architecture Review Board (ARB): openmp.org .
5. OpenMP Application Programming Interface. Version 4.5 November 2015. OpenMP Architecture Review Board. P. 368.
6. OpenMP 4.5 API C/C++ Syntax Reference Guide. OpenMP Architecture Review Board. 2015年。
7. J. Diaz, C. Muñoz-Caro, A. Niño. A Survey of Parallel Programming Models and Tools in the Multi and Many-Core Era. IEEE Transactions on Parallel and Distributed Systems. – 2012. – Vol. 23, Is. 8, pp. 1369 – 1386.
8. A. Cilardo, L. Gallo, A. Mazzeo, N. Mazzocca. Efficient and scalable OpenMP-based system-level design. Design, Automation & Test in Europe Conference & Exhibition (DATE). – 2013, pp. 988 – 991.
9. M. Chavarrías, F. Pescador, M. Garrido, A. Sanchez, C. Sanz. Design of multicore HEVC decoders using actor-based dataflow models and OpenMP. IEEE Transactions on Consumer Electronics. – 2016. – Vol. 62. – Is. 3, pp. 325 – 333.
10. M. Sever, E. Çavus. Parallelizing LDPC Decoding Using OpenMP on Multicore Digital Signal Processors. 45th International Conference on Parallel Processing Workshops (ICPPW). – 2016, pp. 46 – 51.
11. A. Kharin, S. Vityazev, V. Vityazev, N. Dahnoun. Parallel FFT implementation on TMS320c66x multicore DSP. 6th European Embedded Design in Education and Research Conference (EDERC). – 2014, pp. 46 – 49.
12. D. Wang, M. Ali, ―Synthetic Aperture Radar on Low Power Multi-Core Digital Signal Processor,‖ High Performance Extreme Computing (HPEC), IEEE Conference on, pp. 1 – 6, 2012.
13. . . , . . . - . ., 2007, 138 .
14. . . . . . , 2006, 90 .
15. .. . OpenMP. . 2009 , 78 .
16. .. . OpenMP. .: 2012, 121 .
17. TMS320C6678 Multicore Fixed and Floating-Point Digital Signal Processor, Datasheet, SPRS691E, Texas Instruments, p. 248, 2014.
2. LJ Karam, I. AlKamal, A. Gatherer, GA Frantz, «Trends in multicore DSP platforms,» Signal Processing Magazine, vol. 26, no. 6, pp. 38-49, 2009.
3. A. Jain, R. Shankar. Software Decomposition for Multicore Architectures, Dept. of Computer Science and Engineering, Florida Atlantic University, Boca Raton, FL, 33431.
4. Web- OpenMP Architecture Review Board (ARB): openmp.org .
5. OpenMP Application Programming Interface. Version 4.5 November 2015. OpenMP Architecture Review Board. P. 368.
6. OpenMP 4.5 API C/C++ Syntax Reference Guide. OpenMP Architecture Review Board. 2015年。
7. J. Diaz, C. Muñoz-Caro, A. Niño. A Survey of Parallel Programming Models and Tools in the Multi and Many-Core Era. IEEE Transactions on Parallel and Distributed Systems. – 2012. – Vol. 23, Is. 8, pp. 1369 – 1386.
8. A. Cilardo, L. Gallo, A. Mazzeo, N. Mazzocca. Efficient and scalable OpenMP-based system-level design. Design, Automation & Test in Europe Conference & Exhibition (DATE). – 2013, pp. 988 – 991.
9. M. Chavarrías, F. Pescador, M. Garrido, A. Sanchez, C. Sanz. Design of multicore HEVC decoders using actor-based dataflow models and OpenMP. IEEE Transactions on Consumer Electronics. – 2016. – Vol. 62. – Is. 3, pp. 325 – 333.
10. M. Sever, E. Çavus. Parallelizing LDPC Decoding Using OpenMP on Multicore Digital Signal Processors. 45th International Conference on Parallel Processing Workshops (ICPPW). – 2016, pp. 46 – 51.
11. A. Kharin, S. Vityazev, V. Vityazev, N. Dahnoun. Parallel FFT implementation on TMS320c66x multicore DSP. 6th European Embedded Design in Education and Research Conference (EDERC). – 2014, pp. 46 – 49.
12. D. Wang, M. Ali, ―Synthetic Aperture Radar on Low Power Multi-Core Digital Signal Processor,‖ High Performance Extreme Computing (HPEC), IEEE Conference on, pp. 1 – 6, 2012.
13. . . , . . . - . ., 2007, 138 .
14. . . . . . , 2006, 90 .
15. .. . OpenMP. . 2009 , 78 .
16. .. . OpenMP. .: 2012, 121 .
17. TMS320C6678 Multicore Fixed and Floating-Point Digital Signal Processor, Datasheet, SPRS691E, Texas Instruments, p. 248, 2014.