
ニコライ・シヴコ( NikolaySivko 、 okmeter.io )
HeadHunterの動作方法と、動作品質の監視に監視を使用する方法についての講演。
私の名前はニコライ・シヴコです。hh.ruで運営を指揮しています。 このレポートは奇妙と呼ばれていますが、本質的には次のことについて話します。

この会議では、すべてのレポートでモニタリングについて説明します。メトリックを保存する方法ではなく、保存する対象、保存する理由、およびこれから得られる利益を強調します。
遠くから始めましょう-一般的に、会社が管理者を雇う理由と、彼らがどんな種類のビジネスタスクを解決するのか。 次に、管理者がうまく機能しているかどうかを企業がどのように理解しているかという質問を強調します。 KPIを実装しました。これについて少し説明します。 管理者がうまく働くように動機付け、これをビジネスの利益に結び付けようとした方法。 すべての管理者がそれをどのように見るか、つまり 内側から。 バイアスは監視に直接置かれるため、管理者と技術者の両方にとって興味深いものです。 始めましょう。
私たちの状況では、会社のビジネスは、申請者と雇用主を紹介するという事実に関連しています。 これはサイトで発生しています。 したがって、ビジネスがお金を稼ぐために必要な、しかし、もちろん十分でない条件は、サイトが機能することです。

また、ビジネスは、サイトが機能することを保証する責任がある単独の人物である必要があります。 グループの責任は存在せず、特定の地位にいる特定の人が必要です。そこから予測を求め、解決策を要求し、一般に状況を根本的に修正する必要があります。
また、サイトの速度がお金に影響するようなビジネス要件もあります。 そして、予算はすべて予算内で、これは一切ありません。

それから、一般に「サイトが機能する」ことに同意し始めました。それは明確ではないからです。
最初のバージョンでは、私たち、ディレクター、またはそこにいる誰かが、あるシナリオが1分に1回通過した場合にサイトが機能すると信じていることに同意しました。 つまり 応募者が来て、彼はサイトのメインページをロードし、検索を行い、検索で少なくとも1つの空きが見つかると、空きが開きます。 雇用主のシナリオで同様のケース。 そして、これらすべてのために、応答時間のフレームワークがあります-数秒。
このアプローチは私たちのために働いた、これはあなたがすぐに来てやることができるものです。 外部チェックを行うサイトに来て、そこでスクリプトをプログラムすると、処理されます。 何か問題が発生した場合、SMSを受け取ります。 このアプローチは機能しますが、問題があります。 問題は、すべてのケースをキャッチするわけではなく、これらのテストが行うすべての機能をキャッチするわけではなく、チェックが影響しないことです。 したがって、もう少し先に進みました。

これは不完全なオプションです。これは私がビジネスに説明しなければならなかった方法です。これはおおよそ「サイトが機能している」ことを意味します。 この場合、サイトのエラー数は1秒あたり20未満です。 20番は頭から取られます。なぜなら、それ以上ある場合、原則としてすべてが爆発することがわかっているからです。 それらの数が少ない場合、バグがあると想定し、まれなページには500のサイトがあるかもしれません-それらを「バックグラウンドエラー」と呼び、操作はそれらとは何もせず、開発者によって個別に監視されますが、サイトが500 RPS 1の場合、カムは起動しません。
さらに、応答時間の基準があります。最新のサイトは迅速に機能するため、これには余裕があります。 そこには約500ミリ秒あります。実際、メインページは100ミリ秒で、問題が発生した場合は外部チェックを行います。
現在、このシナリオを活用しています。 現在、ログをリアルタイムで監視し、これらのインジケータを見て、トリガーが構成されています。 サイトがこのSLAの外側で機能し始めたら、SMS'kiを取得して行きます。

実際、このビジネス価値は間接的に反映されています。 そして、一般的に言えば、ビジネス指標を見る必要があります。 私たちの場合、これは履歴書、空席、および回答に基づく活動です。 しかし実際には、nginxのアクセスログから間接的に理解できます。 クライアント側で何らかのエラーが発生し、バナーが応答または他の何かを送信するためのフォームに重なる場合があり、nginxの側からはすべてがうまくいきますが、実際にはすべてが悪く、ユーザーが苦しみ、ビジネスは利益を得ません。

実際、2つの部門がパフォーマンスに完全に責任を負うことができます。 私たちの場合、これは運用サービスおよび開発部門です。 これは良くありません、そして、我々はそれを解決する方法を見つけ出し続けます。 開発者はインシデント、SMS'kiを決して購読しません。 管理者は、夜間にSMSを受信するため、有害性に対するプレミアムを受け取ります。 一般的に、ビジネス、運用、および開発者に何が起きているかが明確になるように、一般にそれを解決する方法を決定しようとします。

私たちが最初に考えたのは、管理者がSMSを取得し、修正することです。 彼らは最もクールな開発者の電話を持っています。 彼らは何が起こっているのか理解していない場合、彼らはそれらを呼び出し、一緒に修復します。 ただし、この場合、KPIは管理者自身のパフォーマンスインジケーターです。ここでは、インシデントに対する反応時間のみを区別できます。 私たちはこのように暮らしていました。問題がほとんどなかった数年間、インフラストラクチャにもう少し時間を費やしたとき、私たちは普通に暮らしていました。

その後、それは私たちに合うことをやめました、私たちはビジネスが本当の利益を受け取らないという状況に来ました、そして管理者は彼らのKPI、すなわち すぐに目が覚め、すぐに[OK]をクリックしました。たとえば、問題に対処し始めました。 実際、このサイトは長い間横たわっていました。何故なら、彼らはどれだけ修理するかについての動機付けがなかったからです。
試み2でも試しなかった:

上からのアイデアがありました、側から、私はそれがどこから来たのか覚えていません、管理者は一般に、すべての稼働時間に責任があるべきであるということです。 しかし、私の反論は次のとおりです。「まあ、大きな複雑なアプリケーションがあり、クラッシュし、流れます...管理者は応答できず、影響を与えることができません。これは彼らにとってブラックボックスです。」 彼らは私に答えました。「運用サービスにQA部門全体を配置しましょう。 彼らがテストしたのは、あなたの責任です。」 実際、一般に、優れたQAを行うのは難しく、費用がかかり、現実的ではありません。 最後に、私たちは何もしないと決めました。 私は、人がそれに影響を与えることができるときに、良いKPIができると主張しました。 つまり 「ここでそれを修正したら、良くなった、終わった、ボーナスがもらえる」と彼が理解した場合。
これが私たちがやってきたことです。

すべての稼働時間をクラス、責任領域に分割しました。 問題のいくつかのクラスを割り当てました。 管理者は、自分の責任範囲に実際にあるもの、実際に実行および修正できるものに責任を負います。 他のすべてをどうするかは決まっていませんでしたが、今ではこれは中断された質問です。 私は触れませんが、そこではおおよそ理解できます。

それでは、何をする必要がありますか?
すべてがすべての人に明確で透明になるように、何らかのフレームワーク、条件を設定する必要があります。 「サイトワークス」とは何か、SLAに同意しました。 指標が満たされている場合-すべてがうまくいっていない場合-インシデント。 サイトが完全に正常に機能していない場合、一部の機能は引き続き機能しますが、問題はダウンタイムであり、サイトは完全に稼働しているとは考えていません。
管理者は引き続きインシデントに対応します。 明らかな理由のため。 勤務中の役員を区別しません。少なすぎるため、全員が目を覚ましますが、最初の役員が始まります。 必要に応じて、残りを引き上げます。
インシデントごとに、解析が必須です。 理由の一番下に到達する義務があります。アンダーグラウンドノックなどのように、すべてを知ることはできません。 これをしなければなりません。 次に、どのように実行されたかを示します。
レポート期間があります-四半期、ダウンタイム全体をクラスに分けて修正します。 責任範囲で分けます。 管理者のダウンタイム-特定した問題のクラスはそれに関連しています:

- 最初の問題は、リリース中の問題です。 これは悪いコードが本番環境に行き、すべてが爆発するかのいずれかです。 この計算手順が間違っているか、何かをレイアウトする時点で500個あるか、何かが愚かです。 リリースの問題として分類します。
- アプリケーションでエラーが発生するのは、アプリケーションが動作して動作し、その後爆発して動作を停止した場合です。 その理由は非常に多様であり、リークから、リクエストがいくつかの邪悪なパラメーターを持つ邪悪なURLに到達し、すべてを適切な場所に配置するという事実に至ります。 そこのどこかで、リモートリソースがハングした、タイムアウトが機能しなかった、など...
- 鉄、ネットワーク、チャネル、DC-これはホスティングに関連するものであり、私たち管理者がこれに責任を負います。 ここでのヒューマンエラーは管理者のみです。なぜなら、製品の開発者はnakosyachitできますが、アクセスできないからです。
- DBAを外部委託しているため、データベースの問題を個別に特定しました。 これは私たちにとって興味深いクラスの問題です;後で結論を出すことができるように、個別に検討したいと思います。
- なんらかの形でこれがないため、計画的なダウンタイムを行いました。 誰にも100%の可用性を保証する人はいませんが、計画されたダウンタイムには制限があり、事前に発表する必要があります。 これは、負荷が非常に弱い時間、通常は夜間に行う必要があります。
- 監視エラーは必要な措置です。時々、ボットが侵入し、1秒あたり50個のエラーが発生し、ユーザーは影響を受けませんでした。これはまったく問題ではなく、誰にも影響しませんでしたが、ログで確認する必要があります。 そして、誤検知、インシデントを削除しないように、このようなクラスを作成したことはありません。実際にはダウンタイムとは見なされませんが、そうです。
管理者。 担当分野には、次の3つのクラスが含まれます。

これは、ホスティングに関連するすべて、人為的エラーに関連するすべて、およびデータベースの問題です。これは、ほとんどホスティングであるため、インフラストラクチャに関するものであり、開発者はこれに対して責任を負いません。
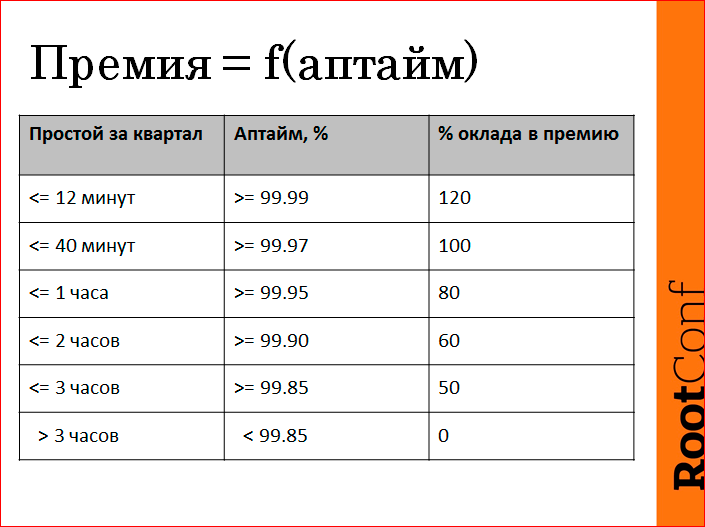
ここで、私たちは本当にKPIの動機を作りました。 人が四半期の終わりに受け取るボーナスは実際には稼働時間の関数ですが、彼の責任の領域にあります。 すべて正直に。 タブレットはそのようなメッセージで構成されていて、四半期に3時間以上横になっているのは残念なので、ボーナスはもらえません。 指標によると、四半期ごとに4ナインを提供すれば、うまくいき、ボーナスを増やすことができます。 そして、中間はどういうわけか比例的に分割されました。 これが2013年1月以来の私たちの生き方です。
一般的に、これで何をするのでしょうか? 実装はどのように行われ、何を学びましたか? 12月の新年に向けて出発する前に、私たちは長時間モニタリングをテストし、それをオンにして、レーキを開始しました。 すべて、すべて、すべてを考慮した場合、自分自身のしきい値を設定し、それに対処する必要があり、本当に働かなければなりませんでしたが、それまでは何を理解していませんでした。
最初の数週間で、私たちは誰もが考えずに市場に参入できるという点でいじくり回していることに気づきました。これは愛情深いサイトでした。 500ポイントすべてがカウントされるため、病気になりません。 考えることを学び、疑わしい場合は、計画的なダウンタイムを取り、夜に何かをします。 かなりの数の問題を本当に解決しました。 また、すべてが正しく行われたことを疑い始め、実際の演習を実施し始めました。 つまり ダウンタイムを宣言し、postgresマスターを釘付けにします。 そして、すべてをデプロイするためにどれだけ管理できるかに注目してください。 レプリカがありますが、私たちはすべてを神聖な方法で消しますが、実際の軍事演習にはケースがあります。

かつてサービス指向アーキテクチャに結び付けられ、いくつかの基本的なサービスと非基本的なサービスに分かれていたため、サイトが機能しないさまざまなサービスをオフにします。 コアではないものを削減し始め、サイトのタイムアウトが誤って行われたため、すべてがうまくいきません。 一般に、私たち全員が第1四半期にどれだけ修正したかという恐怖。

Logrotateは同時に開始されたため、500を与えられました。 クロンの500 ...すなわち レーキしなかったもの。 nginxでは、リトレイとタイムアウトは何らかの形でデフォルトの半分に設定されていました。これはすべてかき集め、修復する必要がありました。 展開を大幅にやり直しました。 私たちは開発者にすべての作業をキューでやり直すことさえ強制しました。 通常、どの行も返済できるようになり、これは誰にも影響しません。
最も難しいことは、すべてのファカプスの理由を見つけることです。 つまり 何が起こっても、あなたは一番下に行く必要があります。 もちろん、最初は不可能でした。ログは私たちが望むほど詳細に書き込まれていません。どうにかして試して、スタンドでいくつかの仮説をチェックし、何らかの負荷をかけなければなりませんでした。 その後、なんとか第1四半期にすべてが落ち着き、ほぼ正常にタスクに対処し始めました。
特に、現在の監視は私たちに適していない。 私たちの要件は、問題が発生したことを見つけることでした。 最も重要な要件。 これは常に確実に機能するはずです。 SLA、すべて、アラート、SMS'ki、すべてを超えている場合。

問題がすべてまたはすべてではなく、どのようなサービスに影響するかを確認するのは文字通り30分です。インフラストラクチャが大きいため、ログを取得する時間がありません。 バックデートを掘るのに十分なメトリックを持っていることが最後のストローを演じたものです。 メトリックが不足していました。 CPUはジャンプしましたが、何が来たのか、誰が来たのか、スクリプトを起動したのか、サーバーで何が起こっていたのか、どのCPUがこのCPUを使用したのでしょうか? これは遡及的に行われなければなりませんでした。問題が発生したため、修理の際に何かを再起動し、どこかで痛いこと、再起動、修正、理由はわかりませんが、彼女を見つけます。 時間は稼働時間に依存するため、問題の解決をスピードアップするには、より多くのお金が必要です。 馬鹿げて加速するために、チャートのログからいくつかの典型的なものを出しました。 そして、拡張のシンプルさは、誰かが何らかの種類の事件を掻き立てたと示唆しているため、このメトリックが次回に役立つことを認識したためです。たとえば、このメトリックはログに書き込まれます-あなたはすぐにそれをグラフにねじ込むことができる必要があります。
私はおそらく会社で働いて7年目です...私たちが全歴史で持っていたもの:

私たちはナギオスを持っていました、そのようなものがありました、フランスの偽物、私は知りません、彼女はまだ生きています、セントロンは呼ばれます、これらはナギオスに描かれたグラフです。 私たちはそれをパッチし、それを捨てて自分で書きました。 その後、Nagiosを曲げて、ポーラーSNMPを作成しました。 この時点で、開発者は、独自の特定のメトリックを描画する必要がある場合、サボテン、グラファイトに何かを送信するスクリプトを見ています...私たちの監視のため、何かをオンにするように依頼するのに長い時間がかかります...
独自の決定。 開発者がいましたが、彼は1年間監視していました。 すべてが順調で、彼は私たちの要件を満たし、それから変更されました。

そして彼らは、コンセプト全体が変わり、要件が変わり、すべてが変わり、世界が変わったので、私たちが再び書く必要があることに気づきました。
さらに、監視の開発に時間を費やす時間がなかったため、監視を行いたくありませんでした。 これは、数字を振ったり、店に入れたりするのが好きな人にとっては非常に興味深い作品です。 実際、他にも多くの作業があり、修正する必要があります。どこかで最適化する必要があります。応答時間のヒストグラムが緑色になると、新しい美しいグラフがあるという事実ではなく、はるかに多くのバズが発生します。 フルスタック、つまり グラファイトやつまようじやつまようじから組み立てれば、解決策を集めることができます。 しかし、それを取り、すべてを集めるために、男性を植える必要があります。 さらに、私たちはそのような決定を下し、それらを収集しましたが、それが壊れたとき、男はもはやそれを修正することにあまり興味がありません。 彼は収集したのでグラフを描きましたが、実際には、データの半分がそこに移動したときに、エージェントのチェックを確認するためにいくつかのログに行く必要があります。 一般的に、恐怖。
そして、私たちは平均以上の要件を抱えており、多くのものを見たいと思っています。

私たちはもうこれをしないと決めました。 そして、私たちは半年間このように成功してきました。 SaaSを採用しました。 まず、プログラムする必要はありません-それは話題です。
第二に、銀行の秘密に関する法律の制約を受けず、監視に個人データがなく、匿名化された指標をそこに送信し、境界外に公開することを嫌がりません。 さて、RPS、だから何? 競合他社でさえ、原則として面白くない。
信頼できる監視を行う余裕はありませんでした。 特に、私たちは全員これに結びついているため、監視が必要です。 SMSからではなく、サポートコールから問題について学ぶ場合、これは恥ずべきことです。
監視にはテストが必要です。これはソフトウェアです。 bazhennoeのリリース、破壊、ロールバック-これもタスクです。 私たちは小さなクライアントではないため、請負業者やサービスを曲げることができます。興味深い仕事があり、興味深い専門知識があり、興味深いフィードバックを提供します。 実際、最終的には、価格タグは強調表示された開発者に匹敵します。この開発者が私をプロジェクトマネージャーとしていたことを考えると、私はQAであり、監視の悪用者です。 つまり 合計すると、サービスはほぼ安価です。
okmeter.ioを使用します。 そして、すべてが私たちに合っています。
さらに、メトリックを保存する方法ではなく、削除する必要があるもの、問題を解決するために検討する必要があるものについて説明します。 メトリックの問題は何ですか? 人々がやって来て、「私たちは今、私たちの核を監視します」と言います。 彼らは主要なサービス、主要なバックエンドを監視し、他のすべては忘れられ、人々がタスクを完了することは非常に困難です。 したがって、ここで何らかのアプローチが必要です。
監視範囲を規制に含めようとしましたが、これは機能しません。この人物は次のように見えます。「ええ、サービスをリリースするには、監視でカバーする必要があります。 Webサービス監視とは何ですか? おそらく彼のポートが開いていることを確認し、それだけです。」 つまり 正式には、要件は満たされていますが、実際には、誰も頭をオンにしませんでした。 もちろん、これは人々を叩く必要があるという事実または他の何かによって解決することができますが、何らかの形でこれを体系的に解決する方が良いです。
一部のサブシステムではメトリックの削除を個別に構成する必要があるため、多くの場合、すべてが削除されるわけではありません。 特に、Javaでjmxを有効にし、postgresで監視ユーザーを有効にする必要があります。
インフラストラクチャは常に変化しています。 つまり サービスが起動され、何かが再生されていた、新しい仮想マシン、新しいサービス、バックエンドがnginxでカバーされている場所、HAproxyがインストールされている場所、多くの操作が緊急モードで行われるため、すべてを追跡することが問題です。 メトリックは収集されているように見えますが、一般的であるため、それらについて遡及的に理解することはできません。 つまり そこで、誰かがIOディスクを食べました。さて、私は戻れません。LinuxログにはCPUが誰を食べていたのかが書かれていません...

このようなアプローチがあります。
設定なしで削除できるものはすべて、常に削除します。 ここで、私たちが私たちのサービスに私たちのために何をするように頼んだかについて話しています。 このコンセプトは私たちから生まれたもので、実装は私たちのものではありません。 おそらく、あなたはあなたの決断にアプローチするだけでしょう。 設定なしで削除できるものはすべて、すべてのマシンから削除されます。 それが必要かどうか-させてください。
エージェントが再調整が必要な場合、またはアクセスが必要な場合、これは監視のアラートです。 管理者は修復アラートをクールに表示します。これは彼らがうまく行っていることです。 電球があります、彼は何かをしました、光は消えました-バズ。 つまり 管理者はこの仕事をうまく行います。 つまり テスト駆動開発のように、テストは落ち、テストは修復され、すべてが問題を解決しました。 この場合、ほぼ同じです。
, , .. , — , URL'. URL' , - . URL, , 1%. . , , .
, autodiscovery, , , TCP, , , . - IP, , , — . , , , .

? , , - . . , . CPU , memory , , . Swap, swap i/o (). — packet rate, . — , inodes, i/o read/write. — read/write, , i/o, .. , i/o. time offset , , . , , . raid , , .

. . , , executable . CPU , .. , user/system; , i/o , /, , swap , swap rate — , , . thread, .

TCP. listen socket, , IP , IP . : ESTABLISHED, TIME_WAIT, CLOSE_WAIT IP, . RTT. RTT , , , , selective TCP, , , , . , , , . « ethernet », « , — , — ». listen backlog' accept . .

Nginx. nginx , , . , nginx. , , . nginx, , access_log, , , access_log' . , log_format , , upstream_response_time, , , , . , log_format, , , access_log . RPS , URL, , . .

Jvm. — Jvm. Jvm , , JMX. JMX — . - (assandra), , cassandra. heap, GC, memory pools, threads. , . , JMX , - , - GC, , . 問題。

Postgres. Postgres. . , . . , , pg_stat_statements, sql-, . — . , , . - , . , , .
.
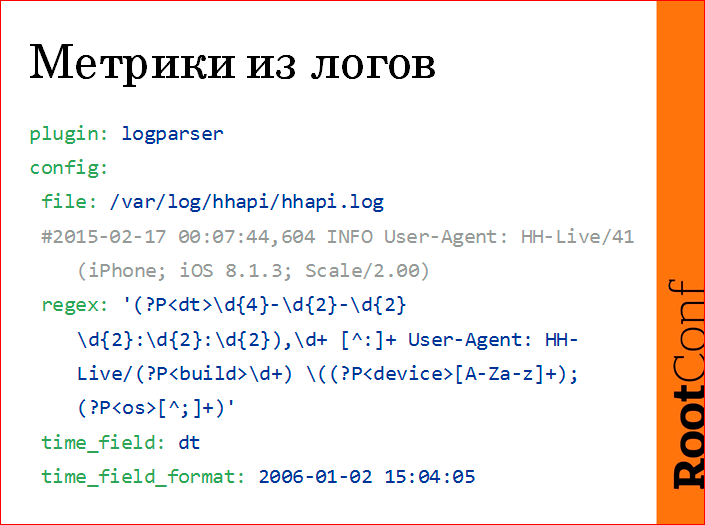
, regex , .

API . , (iphone, ipad ..), .
:
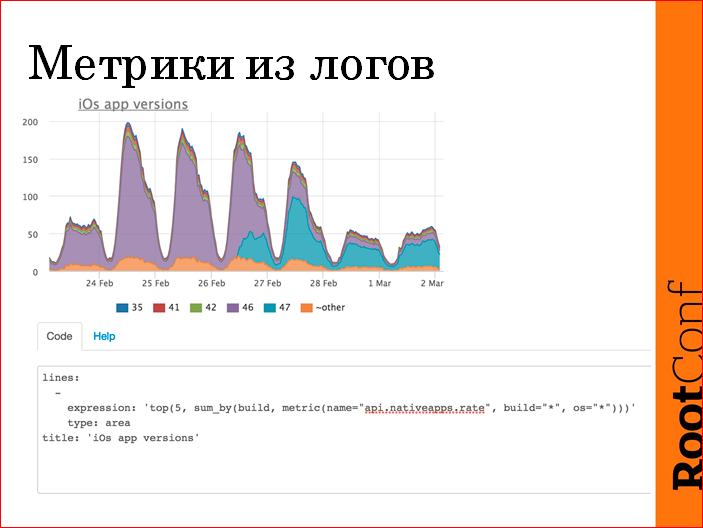
, value , , , . , , 47- . . , . , .
SLQ. , , .

, sql- , - , value…, — . , . , resume.changes.count.
:
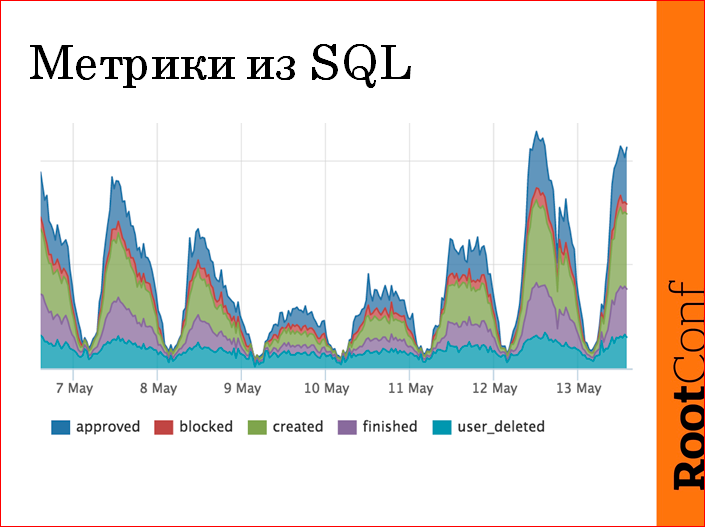
つまり , . - - — , — . , , , . , , , 4 , , , . , , - ( , , , HR') . , , 4 10 . .
. . .

:
- , . , , .
- -, , — , 100 . , Hadoop' . , , , .
- , . Zabbix : « , , ». , . .
- .

Critical — , . Critical , . , , , CPU , . SMS' , «Critical CPU» .
critical — , . , , . — , , , - warning , . , , , .
, , 20-50 warning' .

, , SMS, - : «, , recovery, ». , , . , 10 , , , SSH, . つまり , , . . , SMS, , , , recovery .
, , warning'. — , , , , .. , .

: , , , , , , - , , , . , , . , . つまり , Zabbix - , , , , . CPU - … , CPU — , , . CPU.
, :

, critical warning nginx, , timeout', .
open file usage — , 25 «too many open files» . , . - , , . , , , , , .
LISTEN backlog. , , . , LISTEN . - - Redis , . , - , .
, usage. IO , 10 . . , -.
raid. , - consistency check, raid IO, , - , - , write . , .

- nginx, haproxy , . つまり : «, -, - -». : « nginx». nginx , , . - nginx, , , . , , , - - , .
- - — warning.
- JVM, Postgres .. — warning.
- Heap usage > 99% — warning . out of memory Java, , , . , , . driven .
time offset .
, ?

SMS. JIRA. . , - workflow. , . , JIRA «» — « ». ? , , JIRA : «, , , , . ». : « , ». . 素晴らしい。
:
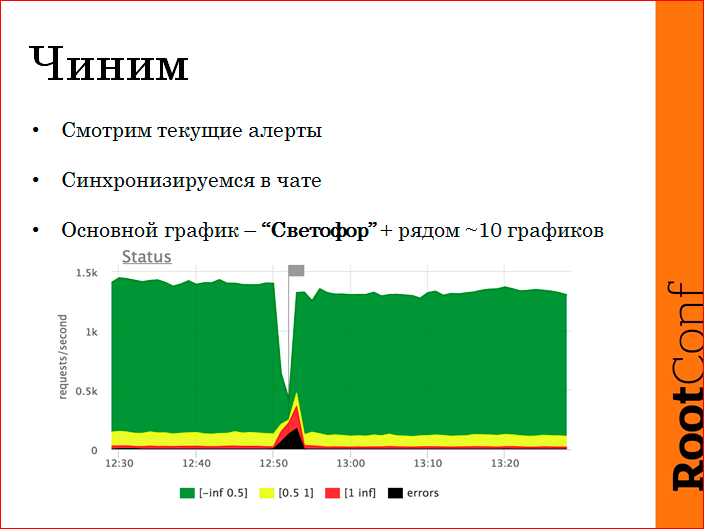
, . , JIRA , , , .
, — . — RPS. - 2000 RPS — , . — , — , , — , — . , , , .
, , , URL , .
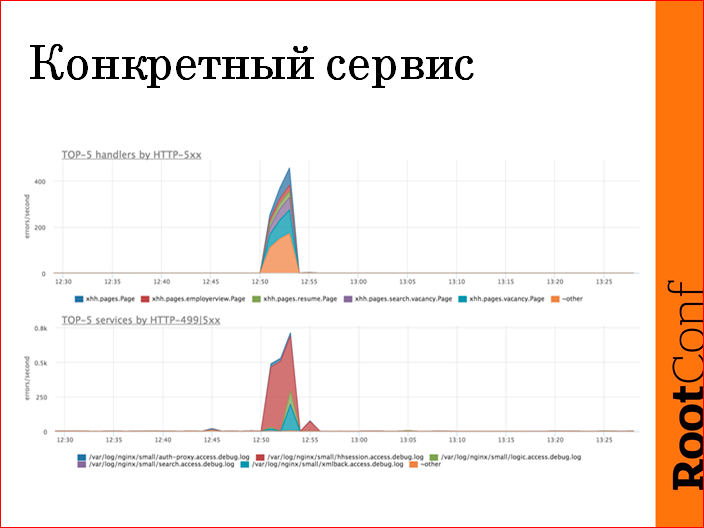
, , , , 40, 40 areas , « 5 , ». — , hhsession , . T.O. scope , , , , .
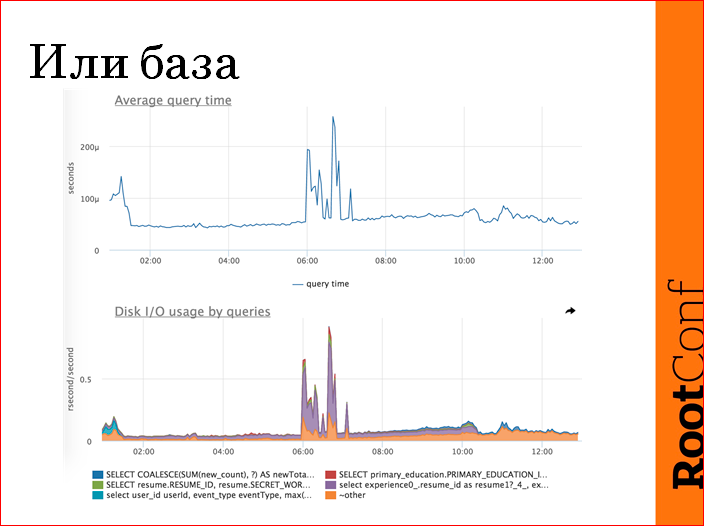
, — , . . , , , — , -. — . , DBA, , , , -, - ..

. , , . downtime .
. , , . , JIRA , , . -, workflow.
JIRA :
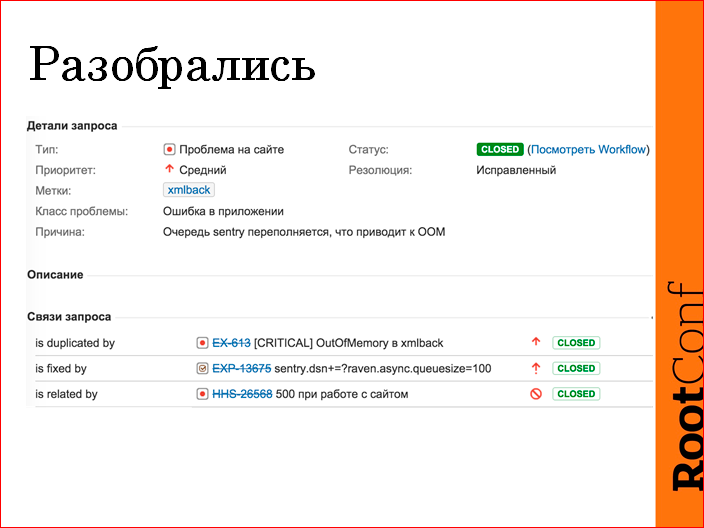
, « ». sentry. . Java out of memory. Fixed by — , , sentry. — ticket . , , , .

. . , , , , , .. これは重要です。
リリースに問題がある場合は、自動テストまたは計算手順の変更の結果である可能性があります。
原則として、アプリケーションの問題は開発のタスクに変換されます。
鉄/ネットワーク-何かを修正することは常に可能というわけではありませんが、タスクを開始する必要があり、可能性を減らし、将来のダウンタイムを減らし、そこで何らかの形で自己修復を提供できます。つまり合計ダウンタイムを削減するためのいくつかの手段。

そして、監視を忘れないでください。メトリックを追加したり、メトリックをより詳細にしたり、新しいトリガーを追加したり、クールなグラフィックを作成したりできます。
連絡先
» NikolaySivko
» n.sivko@gmail.com
»会社ブログヘッドハンター
»ブログ会社okmeter.ioを
このレポートは、Operation Conferenceおよびdevops RootConfでの最高のスピーチの1つのトランスクリプトです。
また、これらの資料の一部は、高負荷システムHighLoadの開発に関するオンライントレーニングコースで使用されますガイドは、特別に選択された文字、記事、資料、ビデオのチェーンです。 私たちの教科書にはすでに30以上のユニークな資料があります。 接続してください!
さて、主なニュースは、 RootConfを含む8つのカンファレンスを含む春祭り「 Russian Internet Technologies 」の準備を開始したことです 。 もちろん、私たちは貪欲なビジネスですが、今ではコスト価格でチケットを販売しています-あなたは価格の上昇に追いつくことができます