しかし、罪を犯したのはキリンではなく、
そして、枝から叫んだ者:
「大きなキリン-彼はよく知っている!」(C)
ビッグデータを使用するために研ぎ澄まされたApache Sparkテクノロジーに迅速に対処する必要がありました。 明確化の過程で、彼は積極的にhabrahabrを使用したので、情報の借金を返して、私の経験を共有しようとします。
つまり、システムをゼロからインストールし、データ処理の問題を解決するコードをセットアップして実際にプログラミングし、ローン金額、金利などの一連の兆候によって銀行顧客の破産の確率を計算するモデルを作成します。
ビッグデータがたくさんあるように思えますが、何らかの理由で、誰もが感じる悪意のある場所を見つけるのは簡単ではありません。 最初にambari オプションを試しましたが、Window7ではネットワークブリッジの設定にエラーがありました。 その結果、Cloudera( CDH )から事前に構成された仮想マシンでバリアントを展開しました。 VirtualBoxをインストールし、ダウンロードしたファイルを実行し、メインパラメーター(メモリ、場所)を指定するだけで、5分後に、 Apache Hadoopの
いくつかの言葉、なぜスパーク。 私が理解しているように、元のMapReduceとの主な違いは、データがディスクにフラッシュされるのではなく、メモリに保持されることです。 しかし、おそらくもっと重要なのは、多くの統計関数の実装と、データのロード/処理のための便利なインターフェースです。
さらに、以下の問題を解決するための実際のコード。 次の形式の本当に大きなデータがあります(これらの2000行をスクロールすることに手が非常に疲れているため)。

デフォルトは他のパラメーターと何らかの形で関係しているという前提があり(最初のパラメーターを除き、尊敬されるIvanov1 ... Nに対する苦情はありません)、線形回帰モデルを構築する必要があります。 始める前に、これが私の最初のJavaコードであり、私自身がアナリストとして働いており、一般的にこれがMavenのセットアップなどの最初のEclipseの起動であることを言及する価値があります。 絶妙な奇跡を待ってはいけません。額の問題の解決策は、何らかの理由で機能した方法です。 行こう:
1. Sparkセッションを作成します。 重要な点-v1.6はCDH配信に含まれていますが、すべてバージョン2.0.0でのみ動作します。 したがって、アップグレードする必要があります。そうしないと、起動時に例外が発生します。
SparkSession ss = SparkSession .builder() .appName("Bankrupticy analyser") .getOrCreate();
2.特別なタイプのJavaRDDにデータをロードします。 基本的に、C#のリストのようなものです。少なくとも、私は自分で説明しました。 ライブラリは多くのことを読み取ることができますが、最初は通常のcsvファイルで十分です。
JavaRDD<Client> peopleRDD = ss.read() .textFile(filename) .javaRDD() .map(new Function<String, Client>() { public Client call(String line) throws Exception { String[] parts = line.split(","); // Client client = new Client(); client.setName(parts[0]); // ( ) client.setYearOfBirth(Double.parseDouble(parts[1])); client.setAmount(Double.parseDouble(parts[2])); client.setTerm(Double.parseDouble(parts[3])); client.setRate(Double.parseDouble(parts[4])); client.setPaid(Double.parseDouble(parts[5])); client.setStatus(Double.parseDouble(parts[6])); // (1 - , 0 – ) return client; } });
Clientは、属性を持つ通常のクラスです(プロジェクトファイル、投稿の最後のリンクにあります)。
3.データの正規化に必要なデータセットを作成します。 正規化しないと、勾配降下法を使用した線形回帰モデルの計算は機能しません。 最初にStandardScalerModel:fit-> transformをねじ込みましたが、データ型に問題がありました。バージョンの違いが原因のようです。 一般に、これまでのところ、回避策がかかりました。つまり、データを選択し、その中で直接正規化を実行します。
Dataset<Row> clientDF = ss.createDataFrame(peopleRDD, Client.class); clientDF.createOrReplaceTempView("client"); Dataset<Row> scaledData = ss.sql( "SELECT name, (minYearOfBirth - yearOfBirth) / (minYearOfBirth - maxYearOfBirth)," + "(minAmount - amount) / (minAmount - maxAmount)," + "(minTerm - term) / (minTerm - maxTerm)," + "(minRate - rate) / (minRate - maxRate)," + "(minPaid - paid) / (minPaid - maxPaid)," + "(minStatus - status) / (minStatus - maxStatus) " + "FROM client CROSS JOIN " + "(SELECT min(yearOfBirth) AS minYearOfBirth, max(yearOfBirth) AS maxYearOfBirth," + "min(amount) AS minAmount, max(amount) AS maxAmount," + "min(term) AS minTerm , max(term) AS maxTerm," + "min(rate) AS minRate, max(rate) AS maxRate," + "min(paid) AS minPaid, max(paid) AS maxPaid," + "min(status) AS minStatus, max(status) AS maxStatus " + "FROM client)").cache();
4.モデルは、クライアントの名前を詰め込んだJavaRDD形式のデータを受け取ります。 これは、テストケースを美しく表示するための標準です。もちろん、これを人生で行うべきではありませんが、一般に他の目的で必要になる場合があります。
JavaRDD<Row> rowData = scaledData.javaRDD(); // Dataset to JavaRDD JavaRDD<Tuple2<String,LabeledPoint>> parsedData = rowData.map( new Function<Row, Tuple2<String,LabeledPoint>>() { public Tuple2<String,LabeledPoint> call(Row row) { int last = row.length(); String cname = row.getString(0); // - double label = row.getDouble(last - 1); // – double[] v = new double[last]; for (int i = 1; i < last - 1; i++) // v[i] = row.getDouble(i); v[last - 1] = 1; // +intercept return new Tuple2<String, LabeledPoint> (cname, new LabeledPoint(label, Vectors.dense(v))); } });
5.モデルのLabeledPointデータを選択します。
JavaRDD<LabeledPoint> parsedDataToTrain = parsedData.map( new Function<Tuple2<String,LabeledPoint>, LabeledPoint>() { public LabeledPoint call(Tuple2<String,LabeledPoint> namedTuple) { return namedTuple._2(); // 2 <String,LabeledPoint> } }); parsedData.cache();
6.実際のモデルを作成します。
int numIterations = 200; double stepSize = 2; final LinearRegressionModel model = LinearRegressionWithSGD.train(JavaRDD.toRDD(parsedDataToTrain), numIterations, stepSize);
7.実際に主な仕事+結果:
final NumberFormat nf = NumberFormat.getInstance(); // nf.setMaximumFractionDigits(2); JavaRDD<Tuple2<Double, Double>> valuesAndPreds = parsedData.map( new Function<Tuple2<String,LabeledPoint>, Tuple2<Double, Double>>() { public Tuple2<Double, Double> call(Tuple2<String,LabeledPoint> namedTuple) { double prediction = model.predict(namedTuple._2().features()); // System.out.println(namedTuple._1() + " got the score " + nf.format(prediction) + ". The real status is " + nf.format(namedTuple._2().label())); return new Tuple2<Double, Double>(prediction, namedTuple._2().label()); } });
8.そして、エラーの平均二乗を計算します(7項から)。
double MSE = new JavaDoubleRDD(valuesAndPreds.map( new Function<Tuple2<Double, Double>, Object>() { public Object call(Tuple2<Double, Double> pair) { return Math.pow(pair._1() - pair._2(), 2.0); } }).rdd()).mean();
この場合、出力は次のようになります。
Ivanov1983のスコアは0.57です。 実際のステータスは1です
Ivanov1984のスコアは0.54です。 実際のステータスは1です
Ivanov 1985はスコア-0.08を獲得しました。 実際のステータスは0です
Ivanov1986のスコアは0.33です。 実際のステータスは1です
Ivanov。1987はスコア0.78を獲得しました。 実際のステータスは1です
Ivanov 1988のスコアは0.63です。 実際のステータスは1です
Ivanov1989のスコアは0.63です。 実際のステータスは1です
Ivanov 1990は0.03のスコアを獲得しました。 実際のステータスは0です
Ivanov1991のスコアは0.57です。 実際のステータスは1です
Ivanov 1992のスコアは0.26です。 実際のステータスは0です
Ivanov 1993のスコアは0.07です。 実際のステータスは0です
Ivanov 1994はスコア0.17を獲得しました。 実際のステータスは0です
Ivanov 1995は0.83のスコアを獲得しました。 実際のステータスは1です
Ivanov 1996はスコア0.31を獲得しました。 実際のステータスは0です
Ivanov 1997はスコア0.48を獲得しました。 実際のステータスは0です
Ivanov 1998はスコア0.16を獲得しました。 実際のステータスは0です
Ivanov 1999は0.36のスコアを獲得しました。 実際のステータスは0です
Ivanov 2000のスコアは-0.04です。 実際のステータスは0です
16/11/21 21:36:40 INFO実行者:ステージ176.0(TID 176)でタスク0.0を終了しました。 3194バイトの結果がドライバーに送信されました
16/11/21 21:36:40 INFO TaskSetManager:localhost(1/1)で432ミリ秒でステージ176.0(TID 176)でタスク0.0を終了しました
16/11/21 21:36:40 INFO TaskSchedulerImpl:タスクがすべて完了したTaskSet 176.0をプールから削除
16/11/21 21:36:40 INFO DAGScheduler:ResultStage 176(App.java:242での平均)は0.433秒で終了しました
16/11/21 21:36:40情報DAGScheduler:ジョブ175終了:App.java:242での平均、0.452851秒かかりました
トレーニングエラー= 0.11655428630639536
これをExcelの分析ソリューションと比較するのが理にかなっています。
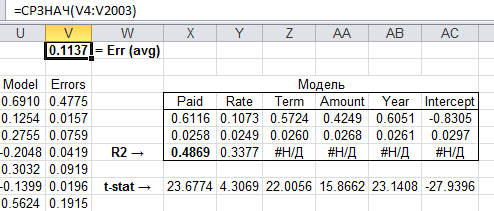
ご覧のとおり、結果は非常に近く、モデルが適切であることが判明し、テストサンプルに対して設定できます。 ソースデータを含むプロジェクトコードは、 ここからダウンロードできます 。
一般に、ビッグデータに関する誇大広告は非常に過剰なものであることに注意してください(このような大きなデータ)。 私にとって最も価値のあることはボリュームではなく、このデータを処理する方法です。 つまり TF-IDFの組み合わせ-ニューラルネットワーク-ALSは、限られたボリュームで創造的に作業できる場合、驚くべき結果をもたらすことができます。 問題は、おそらくマネージャーがビッグデータの魔法の言葉の予算を使い果たす可能性があり、研究目的のためにリソースを費やすことは普通の会社にとって長すぎる計画期間を必要とすることです。
この考えを理解するために、Hadoopエコシステム動物園(Hive、Pig、Impalaなど)が豪華であることを明確にします。 私自身は、マクロ経済モデリングのために、ニューラルネットワーク(複数のサーバーでのマルチスレッドアプリケーションの同時実行と結果の同期と集計)で分散コンピューティングシステムを開発しており、この経路上にあるおおよその熊手を理解しています。 はい、これらの技術に代わるものがないタスクがあります-たとえば、原始的な、しかし野生のデータボリュームのオンラインストリーミング処理(相対的に言えば、モスクワのセルラー加入者のトラフィックのある種の分析)。 ここで、 Apache StormまたはSpark Streamingは驚くべきことをします。
しかし、年間100万人の顧客に関するデータの配列がある場合は、10回(または100回)ごとにランダムにサンプリングしてスコアリングのモデルを構築すると、完全な配列とほぼ同じ結果が得られます。 言い換えると、ボールの女王の代わりに、データマイニングが継娘になりましたが、おそらく一時的なものです。 興奮はおさまりますが、現在Hadoopクラスター上で動き回っている実験的アプローチが広がり、「小さな」データの調査の見通しを最初に実現した人たちは大々的になります。