チェックポイントの設定に関する前回の投稿とは異なり、これはサーバーのセットアップ方法に関するガイドではありません。 実際、設定できるものはほとんどありませんが、アプリケーションレベルでのいくつかの決定(データ型の選択など)がどのようにページ全体の記録と相互作用するかを説明します。
部分録音/破損ページ
では、全ページ記録とは何ですか? postgresql.confからのコメントにあるように、これは部分的なページ書き込みから回復する方法です-PostgreSQLは8kBページ(デフォルト)を使用しますが、スタックの他の部分は異なるチャンクを使用します。 Linuxファイルシステムは通常4kBページを使用します(より小さいページを使用できますが、x86では4kBが最大です)。ハードウェアレベルでは、古いドライブは512Bセクターを使用し、新しいドライブはより大きなチャンク(通常4kB、または8kB)。
したがって、PostgreSQLが8kBページを書き込むとき、残りのストレージレイヤーは、それを個別に処理される小さな断片に分割できます。 これは、レコードの原子性の問題です。 8キロバイトのPostgreSQLページは、ファイルシステムの2つの4kBページに分割し、次に512Bセクターに分割できます。 さて、サーバーがクラッシュするとどうなりますか(停電、カーネルエラーなど)?
サーバーがそのような障害に対処するように設計されたストレージシステム(キャパシタを備えたSSD、バッテリーを備えたRAIDコントローラなど)を使用している場合でも、カーネルはすでにデータを4kBページに分割しています。 データベースが8kBのデータページを書き込んだ可能性がありますが、障害の前にその一部のみがディスクに到達しました。
この観点から、これはおそらくこれがまさにトランザクションログ(WAL)を持っていると思い、あなたは正しいと思うでしょう! そのため、サーバーの起動後、データベースは(最後に実行されたチェックポイントから)WALを読み取り、変更を再度適用してデータファイルが正しいことを確認します。 シンプル。
しかし、トリックがあります-回復は盲目的に変更を適用せず、多くの場合、データページなどを読み込む必要があります。 これは、データの破損を修正するために、データが破損していないことを意味するため、内部的に少し矛盾しているように見えます。
ページ全体の記録は、このパズルのちょっとした解決策です。チェックポイント後に初めてページを変更すると、ページ全体がWALに書き込まれます。 これにより、リカバリ中に、このページに関連付けられた最初のWALエントリにページ全体が保存され、データファイルから潜在的に破損したページを読み取ることがなくなります。
記録的な増加
もちろん、これのマイナスの結果はWALのサイズの増加です。8kBページの1バイトを変更すると、WALに完全に書き込まれます。 ページの完全な記録は、チェックポイントの後の最初の記録でのみ発生します。つまり、チェックポイントの頻度を減らすことは状況を改善する1つの方法です。実際、チェックポイントの後のページの完全な記録の小さな「爆発」があり、その後、終了する前に比較的少ない完全な記録が発生します。
UUIDとBIGSERIALキー
アプリケーションレベルで行われた設計決定との予期しない相互作用がまだいくつかあります。 主キー、UUIDまたはBIGSERIALを持つ単純なテーブルがあり、そこにデータを書き込むと仮定しましょう。 生成されるWALのサイズに違いはありますか(同じ行数を書き込むと仮定します)?
どちらの場合もほぼ同じサイズのWALを期待するのは理にかなっていますが、次の図は実際には大きな違いがあることを明確に示しています。
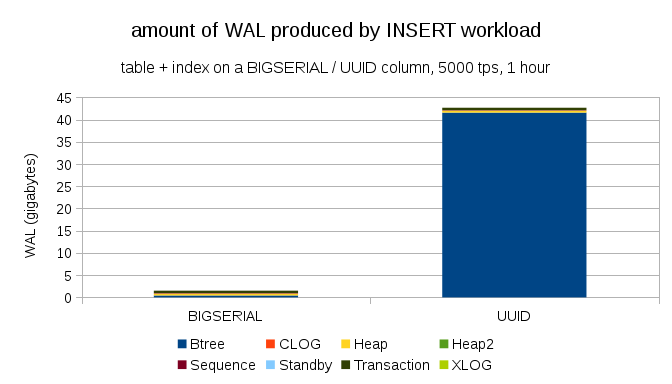
ここに示されているのは、毎時5,000回の挿入までクロックされた、毎時テストから得られたWALのサイズです。 BIGSERIALを主キーとして使用すると、UUIDが40GBを超える間、2GBのWALが発生しました。 違いは明白であり、ほとんどのWALは主キーの後ろのインデックスに関連しています。 WALのエントリのタイプを見てみましょう。

明らかに、レコードの大部分はフルページ画像(FPI)です。 全ページ記録の結果。 しかし、なぜこれが起こっているのでしょうか?
もちろん、これはUUIDの固有のランダム性によるものです。 新しいBIGSERIALはシーケンシャルであるため、btreeインデックスの同じブランチに書き込まれます。 最初のページの変更のみがページ全体のエントリを引き起こすため、このような少数のWALエントリはFPIです。 UUIDはまったく別の問題です。もちろん、値は完全に一貫しておらず、各挿入はインデックスの新しいブランチに分類される可能性があります(インデックスが非常に大きい場合)。
データベースはこれで特別なことを行うことができません-負荷は本質的にランダムであり、大量の全ページエントリが発生します。
もちろん、BIGSERIALキーを使用しても同様の記録の増加を達成することはそれほど難しくありません。 異なるタイプの負荷が必要です。たとえば、更新、レコードのランダム更新により分布が変更されます。図は次のようになります。
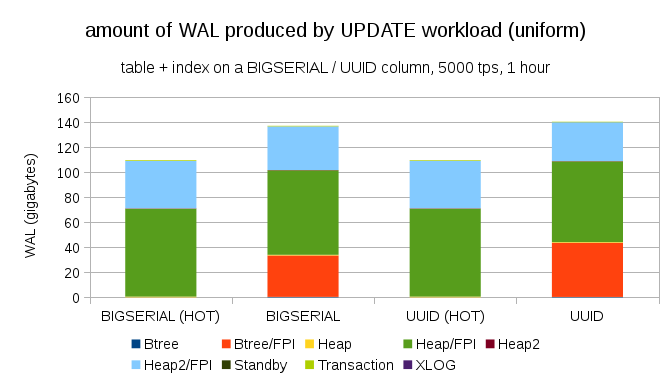
突然、データ型の違いがなくなりました-どちらの場合もアクセスはランダムに行われ、生成されるWALのサイズはほぼ同じになります。 もう1つの違いは、WALのほとんどが「ヒープ」に関連付けられていることです。 インデックスではなくテーブル。 HOT UPDATE最適化(インデックスに触れることなく更新)の可能性のために「HOT」ケースが再現されました。これにより、インデックスに関連するすべてのWALトラフィックがほぼ完全に排除されます。
しかし、ほとんどのアプリケーションがデータセット全体を変更しないことに抗議することができます。 通常、データのごく一部のみが「アクティブ」です。過去数日間、フォーラムでのメッセージ、オンラインストアでの未解決の注文などに興味があります。 これは結果にどのように影響しますか?
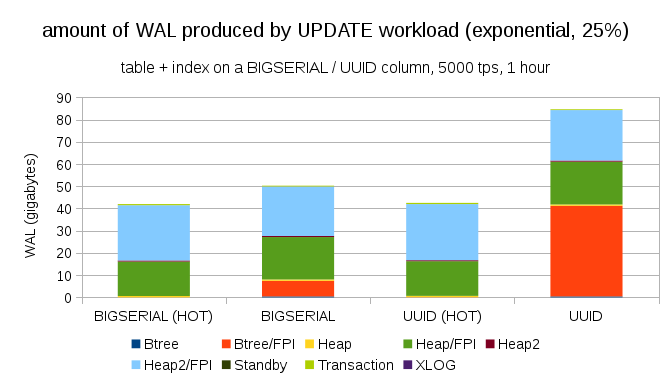
幸いなことに、pgbenchは不均等な分布をサポートしています。たとえば、データセットの1%〜25%の時間に関する指数分布では、図は次のようになります。
分布をさらに非対称にし、データの1%〜75%の時間に関して:
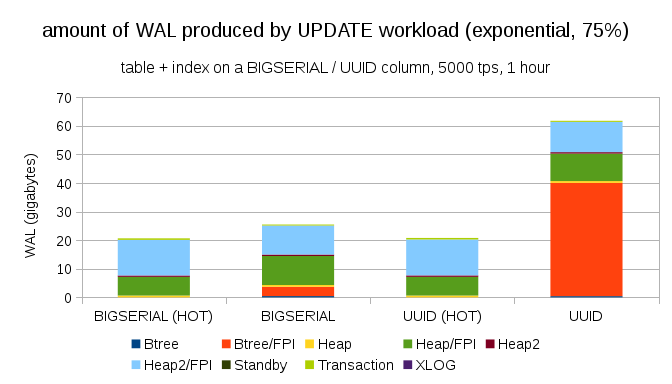
これは、データ型の選択がどれだけの違いを引き起こす可能性があるのか、ホットアップデートを設定することがどれほど重要かを示しています。
8kBおよび4kBページ
もう1つの興味深い質問は、PostgreSQLの小さなページを使用してWALトラフィックをどれだけ節約できるかです(カスタムパッケージのコンパイルが必要です)。 最良の場合、8kBページではなく4kBのみを記録するため、これによりWALを最大50%節約できます。 更新が均等に分散される負荷の場合、次のようになります。
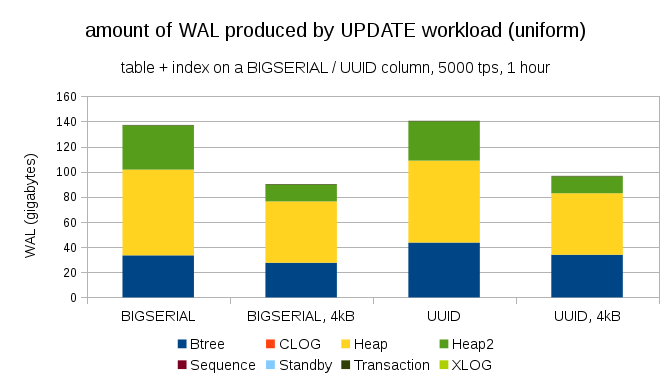
一般的に、節約量は50%程度ではありませんが、約140GBから約90GBへの減少は依然として顕著です。
全ページ記録が必要ですか?
部分的な記録のすべての危険性を説明した後、これは露骨に思えるかもしれませんが、少なくともいくつかのケースでは、全ページ記録をオフにすることは実行可能なオプションです。
まず、Linuxファイルシステムがまだ部分書き込みに対して脆弱かどうか疑問に思います。 このパラメーターは2005年にリリースされたPosqtgreSQLバージョン8.1で導入されたため、多くのファイルシステムの改善によりこの問題が解決された可能性があります。 これは、おそらくどのようなワークロードに対しても普遍的なアプローチではありませんが、いくつかの追加条件(たとえば、PostgreSQLで4kBページを使用する場合)で十分でしょうか? さらに、PostgreSQLは8kBページの一部のみを上書きするのではなく、フルページのみを上書きします。
最近、部分的なレコードを呼び出そうとして、多くのテストを行いましたが、単一のケースを引き起こすことさえできませんでした。 もちろん、これは問題が存在しないという証拠ではありません。 しかし、そうであっても、チェックサムは十分な保護になります(これは問題を解決しませんが、少なくとも破損したページを指します)。
第二に、現代のシステムの多くはストリーミングレプリケーションを使用するレプリカに依存しています-ハードウェア障害(かなり時間がかかることがあります)後にサーバーが再起動するのを待たずに、回復にさらに時間を費やすのではなく、システムは単にホットスタンバイに切り替わります。 破損したマスターのデータベースがクリーニングされた(そして、新しいマスターから複製された)場合、部分的なレコードは問題になりません。
しかし、このアプローチを推奨し始めると、「データがどのように破損したかわかりません。システムでfull_page_writes = offにしただけです!」 redditのヘビで、毒ではありません」)。
おわりに
完全なページレコードを直接設定することはほとんどできません。 多数のロードの場合、完全なレコードのほとんどはチェックポイントの直後に発生し、その後は次のチェックポイントまで消えます。 そのため、チェックポイントを設定して、互いに頻繁にフォローしないようにすることが非常に重要です。
アプリケーションレベルのソリューションの中には、テーブルとインデックスへの書き込みのランダム性を高めるものがあります。たとえば、UUIDは本質的にランダムであり、通常のロードでも挿入からランダムインデックスの更新に変わります。 例で使用されているスキームは非常に簡単でした。実際には、セカンダリインデックス、外部キーなどがあります。 BIGSERIALをプライマリキーとして使用する(およびUUIDをセカンダリキーとして残す)と、少なくともレコードの増加を減らすことができます。
私は、異なるカーネル/ファイルシステムでページを完全に書く必要性について議論することに本当に興味があります。 残念ながら、大量のリソースは見つかりませんでした。関連情報がある場合はお知らせください。