独占的に、Rの開発に特化したHackerマガジンの記事の完全版を紹介します。カットの下で、R言語で表形式データを操作する際の最大速度を得る方法を学習します。

注:著者のスペルと句読点が保存されました。
余分な言葉は何ですか? あなたは速度についての記事を読んでいるので、すぐにポイントに行きましょう! プロジェクトが大量のデータを処理していて、テーブルの変換にdata.table
以上の時間data.table
場合、 data.table
はこの問題の解決に役立ちます。 この記事は、R言語にもう少し精通している人や、R言語を積極的に使用しているが、 data.table
パッケージをまだ発見していない開発者data.table
です。
パッケージをインストールする
今日の記事に必要なものはすべて、適切な機能を使用してインストールできます。
install.packages("data.table") install.packages("dplyr") install.packages("readr")
R攻撃
近年、R言語は機械学習環境で当然の人気を得ています。 原則として、この人工知能のサブセクションを使用するには、複数のソースからデータをダウンロードし、それらを使用して変換を実行してトレーニングサンプルを取得し、それに基づいてモデルを作成し、このモデルを予測に使用する必要があります。
言葉で言えば、すべては単純ですが、実際には、「良い」安定したモデルの形成には多くの試みが必要であり、そのほとんどは絶対に行き詰まります。 R言語は、表形式のデータを分析するための効果的なツールであるため、このようなモデルの作成プロセスを簡素化するのに役立ちます。 Rでそれらを使用するには、組み込みのデータ型data.frame
と、それを積極的に使用する膨大な数のアルゴリズムとモデルがあります。 さらに、Rの全能力は、サードパーティのパッケージを使用して基本機能を拡張できることにあります。 執筆時点で、公式リポジトリのそれらの数は8914に達しました。
しかし、彼らが言うように、完璧に制限はありません。 多数のパッケージにより、 data.frame
データ型data.frame
容易になります。 通常、彼らの目標は、最も一般的なタスクの構文を簡素化することです。 すでにdata.frame
をdata.frame
ための事実上の標準となっているdplyr
パッケージを思い出すしかありません。これは、テーブルを操作する際の読みやすさと使いやすさが大幅に向上したためです。
理論から実践にdata.frame
、列a
、 b
持つdata.frame
DF
を作成しましょう。
DF <- data.frame(a=sample(1:10, 100, replace = TRUE), # 1 10 b=sample(1:5, 100, replace = TRUE), # 1 5 c=100:1) # 100 1
必要な場合:
- 列
a
および
のみを選択し、 -
a
= 2および
> 10の行をフィルター処理します -
a
と
合計に等しい新しい列a
作成します。 - 結果を変数
DF2
に書き込み、
pure data.frame
基本的な構文は次のとおりです。
DF2 <- DF[DF$a == 2 & DF$c > 10, c("a", "c")] # DF2$ac <- DF2$a + DF2$c #
dplyr
状況はずっとdplyr
ます。
library(dplyr) # dplyr DF2 <- DF %>% select(a, c) %>% filter(a == 2, c > 10) %>% mutate(ac = a + c)
同じ手順、ただしコメント付き:
DF2 <- # , DF2 DF %>% # DF (%>%) select(a, c) %>% # «a» «» (%>%) filter(a == 2, c > 10) %>% # (%>%) mutate(ac = a + c) # «ac», «» «»
tables- data.table
する別の方法があります。 正式には、 data.table
もdata.frame
であり、多くの場合data.table
について何も知らず、 data.table
で動作する既存の関数およびパッケージで使用できます。 この「改善された」 data.frame
は、多くの典型的なタスクをその祖先よりも数倍速く実行できます。 正当な質問が発生します:キャッチはどこですか? data.table
この「待ち伏せ」はその構文であり、元の構文とは大きく異なります。 同時に、使用の最初の数秒のdata.table
がコードを理解しやすくする場合、 data.table
はコードを黒魔術に変え、 魔術の本を勉強して数年 data.table
を使用して数日間練習するdata.table
で、新しい構文のアイデアとコード簡素化の原則を完全に理解するdata.table
ができdata.table
。
data.tableを試す
data.table
を操作するには、そのパッケージを接続する必要があります。
library(data.table) #
さらなる例では、これらの呼び出しは省略され、パッケージが既にロードされていると見なされます。
データは非常に頻繁にCSVファイルからダウンロードされるため、この段階では既にdata.table
は驚くかもしれません。 より測定可能な見積もりを表示するために、かなり大きなCSVファイルを使用します。 例は、最後のKaggleコンテストの 1 つからのデータです。 そこには、サイズが1.27 GBのCSVトレーニングファイルがあります。 ファイル構造は非常に単純です。
-
row_id
イベント識別子。 -
x
、y
座標; -
accuracy
-精度; -
time
-時間; -
place_id
組織識別子。
基本関数R- read.csv
を使用して、このファイルのダウンロードにread.csv
時間を測定してみましょう(このため、 system.time
関数を使用します)。
system.time( train_DF <- read.csv("train.csv") )
リードタイムは461.349秒です。 コーヒーを飲むのに十分...将来data.table
を使用したくない場合でも、組み込みのCSV読み取り機能を使用するdata.table
てください。 基本的な機能よりもはるかに効率的にすべてが実装される優れたreadr
ライブラリがあります。 例での作業を見て、パッケージを接続しましょう。
library(readr)
次に、CSVからデータをロードする機能を使用します。
system.time( train_DF <- read_csv("train.csv") )
ランタイム-38.067秒-前の結果よりも大幅に高速です! data.tableで可能なことを見てみましょう。
system.time( train_DT <- fread("train.csv") )
実行時間は20.906秒で、これはreadr
場合のほぼ2倍、ベースメソッドの場合の20倍です。
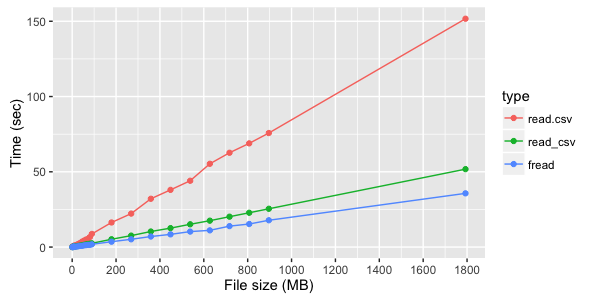
この例では、さまざまな方法のダウンロード速度の差が非常に大きいことが判明しました。 使用される各メソッド内では、時間はファイルサイズに線形に依存しますが、これらのメソッド間の速度の違いは、ファイル構造(列の数とタイプ)に大きく依存します。 以下は、ファイルのアップロード時間のテスト測定です。
3つのテキスト列を持つファイルの場合、 fread
の明らかな利点fread
見られます。
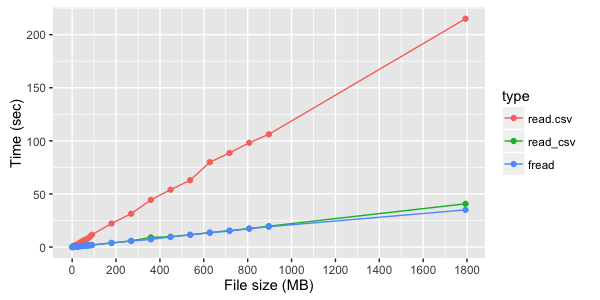
ただし、デジタル列が読み取られない場合、 fread
とread_csv
それほど目立ちません。
ファイルからデータをロードした後、 data.table
を続ける場合、 fread
すぐにそれを返します。 データをロードする他の方法では、 data.table
からdata.frame
を作成する必要がありますが、これは簡単です。
train_DF # data.frame train_DT <- data.table(train_DF) # data.table `data.frame`
data.table
速度の最適化の大部分data.table
、参照によるオブジェクトの操作によって実現され、メモリ内のオブジェクトの追加コピーは作成されません。つまり、時間とリソースが節約されます。
たとえば、 data.table
からdata.frame
を作成する同じタスクは、単一の「ポンピング」コマンドで解決できますが、変数の元の値は失われることに注意してください。
train_DF # data.frame setDT(train_DF) # DF data.table
それで、データをダウンロードしました。今度はそれらを使用します。 DT
変数は既にdata.table
をロードしていると想定しています。 パッケージの作成者は、 DT[i, j, by]
のメインブロックに次の表記を使用します。
- i-文字列フィルター。
- j-
DT
の内容に対する列の選択または式の実行。 - by-データをグループ化するためのブロック。
data.frame
DF
を使用した最初の例を思い出してください。そして、その上でさまざまなブロックをテストします。 data.table
からdata.frame
作成するdata.table
から始めましょう:
DT <- data.table(DF) # data.table data.frame
ブロックi-文字列フィルター
これは最も理解しやすいブロックです。 data.table
行をフィルタリングするのにdata.table
、他に何も必要ない場合、残りのブロックは省略できます。
DT[a == 2] # a == 2 DT[a == 2 & c > 10] # a == 2 c > 10
ブロックj-列を選択するか、data.tableの内容に対して式を実行します
このブロックは、フィルター処理された行でdata.table
の内容を処理します。 リストlist
で必要な列を指定するだけで、必要な列を返すことができlist
。 便宜上、同義語list
ドットとして入力されます(つまり、 list (a, b)
同等.(a, b)
)。 data.table
存在するすべての列は「変数」として使用できます。行のように列を操作する必要はなく、 data.table
を使用できます。
DT[, list(a, c)] # «» «» DT[, .(a, c)] #
作成する追加の列を指定して、必要な値を割り当てることもできます。
DT[, .(a, c, ac = a+c)]
これらすべてを組み合わせると、さまざまな方法で解決しようとした最初のタスクを実行できます。
DT2 <- DT[a == 2 & c > 10, .(a, c, ac = a + c),]
列の選択は、ブロックjの機能の一部にすぎません。 また、既存のdata.table
変更できます。 たとえば、(前の例のように)新しいコピーではなく、既存のdata.table
新しい列を追加する場合は、特別な構文:=
を使用してこれを実行できます。
DT2[, ac_mult2 := ac * 2] # DT2 ac_mult2 = ac * 2
同じ演算子を使用して、列をNULL
設定することで列を削除できNULL
。
DT2[, ac_mult2 := NULL] # DT2 ac_mult2
参照によるリソースの操作は、異なる列を持つ同じテーブルのコピーを作成することを避けるため、電力を大幅に節約し、はるかに高速です。 ただし、参照による変更はオブジェクト自体を変更することを理解する必要があります。 別の変数にこのデータのコピーが必要な場合は、これが別のコピーであり、同じオブジェクトへのリンクではないことを明示的に示す必要があります。
例を考えてみましょう:
DT3 <- DT2 DT3[, ac_mult2 := ac * 2] #
DT3
のみを変更したように見えるかもしれませんが、 DT2
とDT3
は1つのオブジェクトであり、 DT2
に目を向けると、そこに新しい列が表示されます。 data.table
はソートを含むリンクを使用するため、 data.table
は列の削除と作成だけに適用されません。 したがって、 setorder(DT3, "a")
を呼び出すと、 DT2
影響DT2
。
コピーを作成するには、次の機能を使用できます。
DT3 <- copy(DT2) DT3[, ac_mult2 := NULL]
これで、 DT2
とDT3
は異なるオブジェクトになり、 DT3
から列を削除しDT3
。
by-データをグループ化するためのブロック
このブロックは、 group_by
パッケージのgroup_by
やSQLクエリ言語のGROUP BY
などのデータをグループ化します。 グループ化してdata.table
にアクセスするためのロジックは次のとおりです。
- ブロックiは、完全な
data.table
から行をフィルタリングします。 - ブロックごとに、ブロックiでフィルタリングされたデータを必須フィールドにグループ化します。
- 各グループに対して、ブロックjが実行され、データを選択または更新できます。
ブロックは、 by=list( )
で埋められby=list( )
が、jブロックと同様に、 list
はドットに置き換えることができます、つまり、 by=list(a, b)
by=.(a, b)
by=list(a, b)
同等です。 1つのフィールドのみでグループ化する場合は、リストの使用を省略して、 by=a
直接記述することができます。
DT[,.(max = max(c)), by=.(a,b)] # «a» «b» «max» «» DT[,.(max = max(c)), by=a] # «a» «max» «»
data.table
をdata.table
することを学ぶ人の最も一般的な間違いは、おなじみのdata.frame
構造をdata.table
data.frame
することdata.table
。 これは非常に苦しい場所であり、エラーを探すのに多くの時間を費やすことができます。 変数DF2
( data.frame
)とDT2
( data.table
)にまったく同じデータがある場合、これらの呼び出しは完全に異なる値を返します。
DF2[1:5,1:2] ## ac ## 1 2 95 ## 2 2 94 ## 3 2 92 ## 4 2 80 ## 5 2 65 DT2[1:5,1:2] ## [1] 1 2
その理由は非常に簡単です。
-
data.frame
のロジックは次のとおりですdata.frame
DF2[1:5,1:2]
は、最初の5行を取得し、それらの最初の2列の値を返す必要があることを意味します。 -
data.table
のロジックは異なりますdata.table
DT2[1:5,1:2]
は、最初の5行を取得してブロックjに渡す必要があることを意味します。 ブロックjは1
と2
返すだけです。
フォーマットdata.frame
でdata.table
にアクセスする必要がある場合、追加のパラメーターを使用してこれを明示的に指定する必要があります。
DT2[1:5,1:2, with = FALSE] ## ac ## 1: 2 95 ## 2: 2 94 ## 3: 2 92 ## 4: 2 80 ## 5: 2 65
実行速度
この構文を理解することが理にかなっていることを確認しましょう。 大きなCSVファイルを使用した例に戻りましょう。 train_DF
data.frame
に、 train_DF
train_DT
にそれぞれロードされます。
使用例では、 place_id
は長整数( integer64
)ですが、これは「推測」されているだけです。 他のメソッドはこのフィールドを浮動小数点数としてロードし、 place_id
内のplace_id
フィールドを明示的に変換して速度を比較する必要があります。
install.packages("bit64") # integer64 library(bit64) train_DF$place_id <- as.integer64(train_DF$place_id)
データ内の各place_id
への参照の数を計算するplace_id
があるとします。
通常のdata.frame
秒かかりました。
count <- train_DF %>% # train_DF group_by(place_id) %>% # place_id summarise(length(place_id)) #
同時に、 data.table
は2.578秒で同じことを行います。
system.time( count2 <- train_DT[,.(.N), by = place_id] # .N - , )
タスクを複雑にしましょう-すべてのplace_id
、 x
とy
で中央値place_id
計算し、逆の順序で数量でソートします。 data.frame
したdplyr
は、27.386秒でこれをdplyr
できます。
system.time( count <- train_DF %>% # train_DF group_by(place_id) %>% # place_id summarise(count = length(place_id), # mx = median(x), # x my = median(y)) %>% # y arrange(-count) # count )
data.table
管理がはるかに高速-12.414秒:
system.time( count2 <- train_DT[,.(count=.N, mx = median(x), my = median(y)), by = place_id][order(-count)] )
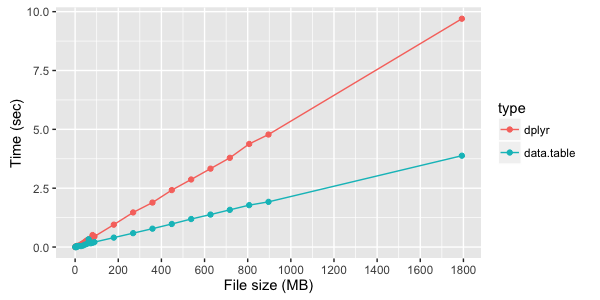
dplyr
とdata.table
をdplyr
して簡単なデータグループ化の実行時測定をテストします。
結論の代わりに
これはdata.table
の機能の表面的な説明にすぎませんが、このパッケージの使用を開始するには十分です。 現在、 dtplyr
パッケージのdtplyr
。これはdplyr
実装として位置付けられていますが、これまでのところまだ非常にdata.table
ものです(バージョン0.0.1)。 いずれにしても、追加の「ラッパー」を使用する前に、 data.table
の機能を理解する必要data.table
あります。
著者について
Stanislav Chistyakovは、クラウドテクノロジーと機械学習の専門家です。
著者からのWWW
パッケージに含まれている記事を読むことを強くお勧めします。
ハッカーマガジンのWWW
R言語のトピックは、このジャーナルで最初に取り上げられたものではありません。 関連記事へのリンクをいくつか提供します。