科学的な高性能コンピューティングの分野におけるFPGAのアプリケーションについて、Habrに聴衆に伝える準備はすべて整っています。 そして、この問題で、ワットあたりのパフォーマンスだけでなく、計算速度の面でもGPU(Nvidia K40)を大幅に上回るパフォーマンスを実現する方法について説明しました。 PCIeを介してホストコンピューターに接続されたザイリンクスVirtex-7 2000tチップは、FPGAプラットフォームとして使用されました。 ハードウェアコンピューティングカーネルを作成するために、C ++言語(Vivado HLS)が使用されました。
カットの下には、元の記事のテキストがあります。 そこに、通常起こるように、最初にこれがすべて必要な理由とモデルを長い説明があり、それを読む意志がない場合は、すぐに実装に進み、必要に応じて後でモデルを見ることができます。 一方で、モデルに精通していなくても、読者はFPGAにどのような複雑な計算を実装できるかの印象を得ることができません。
注釈
このホワイトペーパーでは、C言語Vivado HLSの高レベルトランスレーターを使用して、ザイリンクスVirtex-7プログラマブルロジック集積回路(FPGA)チップでブラウンダイナミクス法を使用したタンパク質微小管解重合の計算のハードウェア実装を検討します。 FPGA実装は、パフォーマンスとエネルギー効率の基準に従って、Intel XeonマルチコアプロセッサおよびNvidia K40 GPUでの同じアルゴリズムの並列実装と比較されます。 このアルゴリズムはブラウン時間で動作するため、多数の正規分布乱数が必要です。 元のシリアルコードは、OpenMPを使用したマルチコアアーキテクチャ、GPU、およびOpenCLを使用して最適化され、FPGAへの実装は、高レベルトランスレーターVivado HLSを介して取得されました。 この論文は、FPGAへの実装がCPUよりも17倍、GPUよりも11倍速いことを示しています。 エネルギー効率(ワットあたりのパフォーマンス)の点では、FPGAはCPUの160倍、GPUの80倍でした。 FPGA加速アプリケーションは、SDKを使用して開発されました。SDKには、完成したFPGAプロジェクトが含まれます。このプロジェクトには、ホストコンピューターとの通信用のPCI Expressインターフェースと、ホストアプリケーションとFPGAアクセラレーターとの通信用のソフトウェアライブラリがあります。 最終開発者からは、Vivado HLS環境でCアルゴリズムのコンピューティングコアを開発するだけで済み、特別なFPGA開発スキルは必要ありませんでした。
はじめに
高性能コンピューティングは、クラスタ化および/またはハードウェアアクセラレータを備えたプロセッサ(CPU)で実行されます-ビデオカード(GPU)またはプログラマブルロジック集積回路(FPGA)上のグラフィックプロセッサ[1]。 最新のプロセッサ自体は、高性能コンピューティングの優れたプラットフォームです。 CPUの利点には、共通のコヒーレントキャッシュメモリを備えたマルチコアアーキテクチャ、ベクトル命令のサポート、高頻度、およびソフトウェアツール、コンパイラ、ライブラリの膨大なセットがあり、高いプログラミングの柔軟性を提供します。 GPUプラットフォームの高性能は、独立したハードウェアコアで数千の並列コンピューティングスレッドを実行する能力に基づいています。 GPU用の定評のある開発ツール(CUDA、OpenCL)を使用して、GPUプラットフォームを使用して計算タスクを実行するためのしきい値を下げることができます。 それにもかかわらず、近年、FPGAは、実世界のコンピューティングを使用するタスクを含むタスクを高速化するためのプラットフォームとしてますます使用されています[2]。 FPGAには、CPUおよびGPUと明確に区別される独自の特性、つまり特定の計算アルゴリズム用のパイプライン化されたハードウェア回路を構築する機能があります。 したがって、FPGAが動作するクロック速度が(CPUおよびGPUと比較して)著しく低いにもかかわらず、一部のFPGAアルゴリズムでより高いパフォーマンスを達成することが可能です[3]-[5]。 一方、動作周波数が低いほど消費電力が少なくなり、ワットあたりのパフォーマンスメトリックを使用する場合、FPGAはCPUおよびGPUよりもほとんど常に効率的です[5]。
高性能コンピューティングを必要とする古典的なアプリケーションの1つは、原子または分子のシステムの動きを計算するために使用される分子動力学法です。 この方法の枠組みでは、原子と分子間の相互作用は、相互作用ポテンシャルを使用したニュートン力学の法則の枠組みで説明されます。 相互作用力の計算は反復的に実行され、システム内の多数の原子/分子と多数の計算された反復が与えられると、計算上の大きな複雑さを表します。 分子動力学計算の高速化は、スーパーコンピューター[6]、クラスター[7]、分子動力学計算専用のマシン[8]-[10]、GPU [11]およびFPGAに基づくアクセラレーターを備えたマシンなど、さまざまなシステムの文献で注目されています[12]-[17]。 FPGAは多くの場合、分子動力学計算用のハードウェアアクセラレータとして競争力のある代替品であることが実証されていますが、現在、FPGAプラットフォームを使用するほうが収益性の高いタスクとアルゴリズムについてのコンセンサスはありません。 この論文では、分子動力学の重要な特別なケースであるブラウン動力学を検討します。 分子動力学と比較したブラウン動力学法の主な特徴は、分子システムがより大まかにモデル化されていることです。 モデリングの基本オブジェクトは、個々の原子ではなく、高分子の個々のドメインまたは高分子全体などの大きな粒子です。 溶媒分子やその他の小分子は明示的にモデル化されておらず、それらの効果はランダムな力として考慮されます。 したがって、システムの次元数を大幅に削減することができ、これにより、モデル計算でカバーされる時間間隔を桁違いに増やすことができます。 ブラウンダイナミクスの問題を加速するための代替プラットフォームと比較して、FPGAの有効性を研究するための文献に記載されている試みを認識していません。 したがって、我々は、ブラウン力学法を使用した微小管解重合のモデリングの問題の例について、この問題の研究に着手しました。 微小管は、チューブリンタンパク質から成り、生細胞の内部骨格の一部である、直径約25 nm、長さ数十ナノメートルから数十ミクロンのチューブです。 微小管の重要な特徴は、その動的な不安定性です。 重合と解重合の段階を自発的に切り替える能力[18]。 この挙動は、主に細胞分裂中の微小管による染色体の捕獲と移動にとって重要です。 さらに、微小管は、細胞内輸送、繊毛と鞭毛の動き、および細胞の形状の維持に重要な役割を果たします[19]。
微小管の仕事の根底にあるメカニズムは数十年にわたって研究されてきましたが、ごく最近では、計算技術の開発により、微小管の挙動を分子レベルで記述することが可能になりました。 Brownianダイナミクス法に基づいて私たちのグループによって最近作成された微小管ダイナミクスの最も詳細な分子モデルは、CPUに基づいて実装され、数秒のオーダーで微小管の重合/解重合時間を計算できるようになりました[20]。 これにより、微小管のダイナミクスの多くの重要な側面が明らかになりましたが、それにもかかわらず、実験的に観察された多くの重要な現象は理論的な説明の範囲外でした。 それらは、数十秒から数百秒の時に微小管で発生します[21]。 したがって、理論と実験を直接比較するためには、微小管ダイナミクスの計算を少なくとも1桁加速することが非常に重要です。
このホワイトペーパーでは、FPGAでのブラウン微小管ダイナミクスの計算を加速する可能性を調査し、パフォーマンスとエネルギー効率の基準に従って3つの異なるプラットフォームで同じ微小管ダイナミクスアルゴリズムを実装することで得られた結果を比較します。
数学モデル
一般的な微小管構造
構造的には、微小管はプロトフィラメントという13の鎖からなる円柱です。

左の図は、微小管モデルの図です。 チューブリンのサブユニットは灰色で示され、それらの間の相互作用の中心は黒い点で示されています。 右側は、チューブリン間の相互作用のエネルギーポテンシャルのビューです。
各プロトフィラメントは、チューブリンタンパク質二量体から構成されています。 隣接するプロトフィラメントは、側方結合によって互いに接続されており、1つのモノマーの長さの3/13の距離だけ互いに対してシフトしているため、微小管はヘリシティを持ちます。 重合中、チューブリン二量体はプロトフィラメントの末端に付着し、微小管のプロトフィラメントは直接立体構造を取る傾向があります。 解重合中、微小管の端のプロトフィラメント間の横方向の結合が破壊され、プロトフィラメントが外側にねじれます。 同時に、チューブリンオリゴマーがランダムに脱落します。
ブラウン動力学を用いた微小管解重合のシミュレーション
ここで使用される微小管の分子モデルは、最初に[20]で提示されました。 この研究の目的はさまざまなコンピューティングプラットフォームのパフォーマンスを比較することであったため、微小管の解重合のみのモデリングに限定しました。
簡単に言えば、微小管は、チューブリンモノマーである球状粒子のセットとしてモデル化されました。 モノマーは、対応する放射状平面、つまり 微小管の軸と対応するプロトフィラメントを通る平面内。 したがって、各モノマーの位置と方向は、3つの座標(モノマーの中心の2つのデカルト座標と方向角)によって完全に決定されました。 各モノマーの表面には、4つの相互作用中心がありました。2つの横方向相互作用中心と2つの縦方向相互作用中心です。 チューブリン-チューブリン相互作用のエネルギーは、隣接サブユニットの表面上の相互作用部位間の距離rと、プロトフィラメント内の隣接チューブリンモノマー間の傾斜角に依存していました。 チューブリン二量体間の横方向および縦方向の相互作用は、次の形式のポテンシャルによって決定されました。
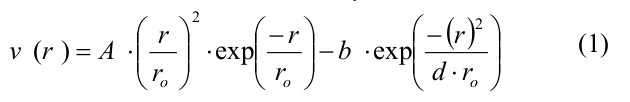
ここで、Aとbはポテンシャル井戸の深さとエネルギー障壁の高さを決定し、r0とdはポテンシャル井戸の幅とポテンシャル全体の形状を定義するパラメーターです。 パラメーターAは、横結合と縦結合に対して異なる値をとったため、横相互作用は縦結合より弱く、他のすべてのパラメーターは両方のタイプの結合で一致しました(パラメーターとその値の完全なリストは、[20]の表1に示されています)。 二量体内部の縦方向の相互作用は、二次エネルギーポテンシャルu_rを持つ連続バネとしてモデル化されました。
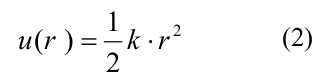
ここで、kはチューブリンとチューブリンの相互作用の結合剛性です。 曲げエネルギーg(χ)は、モノマーの相対回転に関連付けられており、2次の不可解な関数によっても説明されました。

ここで、χはプロトフィラメント内の隣接するチューブリンモノマー間の角度、χ0は2つのモノマー間の平衡角、Bは曲げ剛性です。 微小管の総エネルギーは次のように記述されました。

ここで、nはプロトフィラメント番号、iはn番目のプロトフィラメントのモノマー番号、Knはn番目のプロトフィラメントのチューブリンサブユニットの数、横方向の相互作用v_k_lateralはモノマー間の横方向の相互作用のエネルギー、v_k_longitudinalはダイマー間の縦方向の相互作用のエネルギーです。
システムの進化は、ブラウン動力学法を使用して計算されました[22]。 初期の微小管構成は、各プロトフィラメントに12個のチューブリンモノマーを含む短い「シード」でした。 MT解重合のみを考慮し、平衡角χ0 = 0.2 radのすべてのチューブリンをシミュレートしました。 i番目の反復でのすべてのシステムモノマーの座標は、次のように表されました。
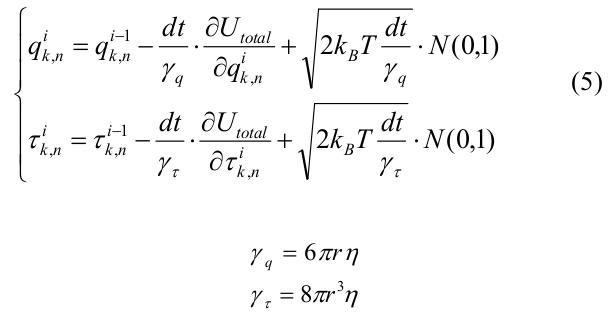
ここで、dtは時間ステップ、U totalは(4)で表され、k_Bはボルツマン定数、Tは温度、N(0,1)はメルセンヌ渦アルゴリズムによって生成された正規分布からの乱数です[23]。 γqとγτは、それぞれ半径r = 2 nmの球に対して計算されたせん断と回転の抵抗の粘性係数です。
独立した座標q {k、n}に関する総エネルギーの導関数は、隣接する二量体と二量体の内部の相互作用エネルギーの横方向、縦方向成分、および曲げエネルギーによって表されました。
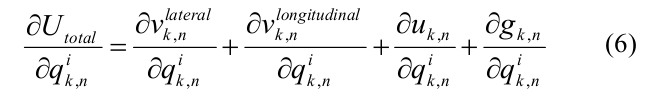
計算を高速化するために、
すべてのエネルギー勾配:
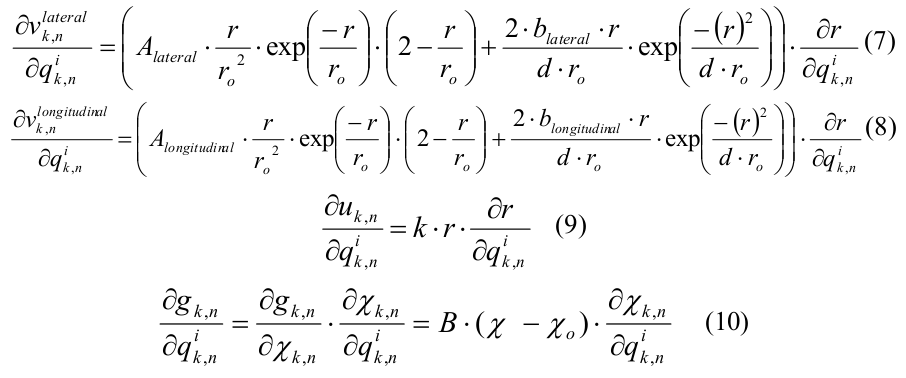
このタスクのサイズは比較的小さいことに注意してください。 モノマーの12層のみを考慮しました。これにより、156に等しい粒子の総数が得られます。ただし、計算の重要性はまったく減りません。 実際の計算では、モノマーの最後の数ワード(10オーダー)の位置を計算するだけで十分です。 微小管の成長に伴い、微小管の端から遠いチューブリン分子は安定した円筒形を形成し、それらを考慮する意味はありません。
計算アルゴリズムの擬似コード
アルゴリズムは、0.2 nsのステップで時間的に反復されます。 分子の3次元座標の配列と、横方向(横方向)および縦方向(縦方向)の相互作用の力の配列があります。 時間の各反復で、分子の2つのネストされたサイクルが順番に実行されます。最初は相互作用力が既知の座標によって計算され、2番目は座標自体が更新されます。 相互作用力を計算するサイクルでは、3つの分子の座標を読み取る必要があります。1つは中央の分子で、2つは隣接しています(「左」と「上」、図2を参照)。計算の結果は、中央と左の分子間の横方向の相互作用の力と、中央の縦方向の相互作用の強さですそしてトップ。
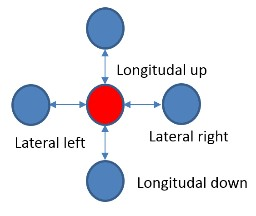
図 2.微小管モデルにおける相互作用するサブユニットの配置
その結果、このサイクルの後、すべての分子間のすべての相互作用力が計算されます。 既知の力を使用して座標を更新するサイクルでは、座標の変化が計算され、ブラウン運動を考慮するためにランダムな加算が考慮されます。 したがって、アルゴリズムの擬似コードは次のように記述できます。
: M = {x, y, teta}. . : M K for t in {0.. K-1} do for i in {0.. 13} // for j in {0.. 12} do // Mc <- M[i,j] Ml <- M[i+1,j] Mu <- M[i,j+1] // (7, 8, 9, 10) F_lat[i,j] <- calc_calteral(Mc, Ml) F_long[i,j] <- calc_long(Mc, Mu) end for end for for i in {0.. 13} for j in {0.. 12} do // (5) M[i,j] <- update_coords(F_lat[i,j], F_long[i,j]) end for end for end for
CPUおよびGPUでのソフトウェア実装
CPUの実装
OpenMPライブラリを使用して、Ubuntu 12.04を実行しているIntel Xeon E5-2660 2.20GHz CPUにコードを並列化しようとしました。 並列セクションは、時間サイクルの前に始まりました。 相互作用力の計算と座標の更新のサイクルは、omp for schedule(静的)ディレクティブを使用して並列化され、サイクル間にバリア同期が挿入されました。 相互作用力と分子座標を含む配列は、各ストリームに対してプライベートと宣言されました。
CPUに計算を実装すると、タスクのサイズが効果的に並列化できないことがわかりました。 1回の反復の実行時間の並列スレッド数への依存は、単調ではありませんでした。 1回の反復での最小計算時間は、2つのスレッド(CPUコア)のみを使用して取得されました。 これは、ストリームの数が増えると、ストリーム間でデータをコピーし、それらを同期する時間が長くなるという事実によって説明されます。 同時に、問題のサイズは非常に小さいため、コアの数を増やすことによる利得はこのオーバーヘッドを超えます。 同時に、実験は、サイズの増加(弱いスケーリング)に対して問題のスケーリングが不十分であることを示しました。 問題のサイズと並列スレッドの数が同時に増加しても、計算時間はほぼ同じままでした。 その結果、このCPUでの最良の結果は、2つのCPUコアを使用した場合、時間の反復ごとに22μsでした。 相互作用の力の計算が複雑であるため、コードはベクトル化されませんでした。
GPUの実装
Nvidia Tesla K40グラフプロセッサでOpenCL実装を開始しました。 相互作用力と座標更新を計算するサイクルは並列化され、メインサイクルは時間的に反復されました。 2つのオプションが実装されました-1つおよびいくつかのワークグループがあります。 最初のケースでは、1つの作業項目が各分子に割り当てられました。 各ストリームには、フロー分子の力と座標が計算されるタイムサイクルがありました。 この場合、力の計算後および座標の更新後にバリア同期が使用されました。 この場合、ホストの参加は計算に必要ではなく、コアの管理と起動にのみ関与していました。
2番目のケースでは、2つのタイプのフローがあり、1つでは1つの分子の力が単純に計算され、2つ目では-座標が更新されました。 メインタイムループはホスト上にあり、タイムループの各反復でカーネルの開始と同期を制御しました。
1つのグループのフローとそれらの間のバリア同期を使用した計算で、最高のパフォーマンスが得られました。 擬似乱数ジェネレーターを使用しない場合、5μs以内に1回の反復が計算されました。すべてのフローに1つのジェネレーターが使用された場合、動作時間は9μsに増加し、共有メモリーがいっぱいになると、7つの独立したジェネレーターがオンになり、計算時間は時間の1つの反復は14μsで、CPUでの実装よりも1.57倍高速でした。
GPUコアの負荷は1つのマルチプロセッサ(SM)の7%でしたが、擬似乱数ジェネレーターのフォース、座標、データバッファーの配列が配置された合計メモリは100%でした。 つまり 一方で、GPUを完全にロードするにはタスクサイズが明らかに小さかった一方で、タスクサイズが増加した場合、グローバルDDRメモリを使用する必要があり、生産性の向上に限界が生じる可能性がありました。
FPGA実装
プラットフォームの説明
FPGAの計算は、NPO Rostaが製造したRB-8V7プラットフォームで行われました。 1Uラックマウントユニットです。 このユニットは、8つのザイリンクスVirtex-7 2000T FPGAクリスタルで構成されています。 各FPGAには、1 GBの外部DDR3メモリと、内部PCIeスイッチへのPCI Express x4 2.0インターフェイスがあります。 ユニットには、光ケーブルを介したホストコンピューターへのPCIe x4 3.0インターフェイスが2つあり、ホストコンピューターにインストールされた特別なアダプターに接続する必要があります。
ホストコンピューターとして、Ubuntu 12.04 LTS OSで実行されているIntel Xeon E5-2660 2.20 GHz CPUを搭載したサーバーを使用しました。OpenMPを使用したCPUでの計算と同じです。 ホストCPUで実行されているソフトウェアは、RB-8V7ユニットをPCI Expressバス経由で接続された8つの独立したFPGAデバイスとして「認識」します。 次に、CPUと1つのFPGA XC7V72000Tのみの相互作用について説明しますが、システムではFPGAを独立して並行して使用できます。
FPGAアクセラレーションアプリケーションは、SDKと次のモデルを使用して開発されました。 メインプログラムはホストコンピューターのCPU(以下、単にCPUと呼びます)で実行され、最も計算量の多い手順でFPGAアクセラレーターを使用します。 CPUはFPGAに接続された外部DDRメモリを介してアクセラレータにデータを転送し、FPGAのコンピューティングコアの動作も制御します。 コンピューティングコアは、C / C ++で事前に作成され、検証され、Vivado HLSツールを使用してRTLコードに変換されます。 コンピューティングコアのRTLコードはメインのFPGAプロジェクトに挿入され、PCI Expressコア、DDRコントローラー、チップ上のバスなど、必要な制御およびデータ転送ロジックを既に実装しています(図3)。 メインFPGAプロジェクトは、ボードサポートパッケージ(BSP)と呼ばれることもあり、機器メーカーによって開発されており、ユーザーが変更する必要はありません。 開始後、HLSコンピューティングコア自体がDDRメモリにアクセスし、そこから処理のために入力データバッファーを読み取り、そこに計算結果を書き込みます。 C ++言語のレベルでは、メモリアクセスは、ポインタ型の計算カーネルのトップレベルの関数の引数を介して発生します。
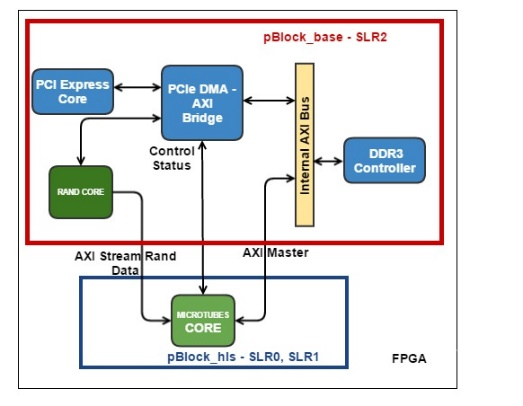
図 3. FPGAプロジェクトのブロック図。 BSPに含まれるブロックは、青と黄色でマークされています。 緑はコンピューティングHLSコアを示します。 プロジェクトコアをブロック(pBlocks)に分割することも、トレース中に空間的制約を課すために示されています。
高速化されたアプリケーションを作成するために、いくつかのステップで構成される方法論が開発されました。 最初に、元のシリアルコードがVivado HLS環境でコンパイルされ、この方法でコンパイルされたコードが参照シリアルコードの出力を変更しないことが検証されました。 次に、主要な計算部分と加速に適した部分がこのコードから割り当てられました。 この部分は、ラッパー関数を使用してメインコードから分離されました。 その後、このような関数の2つのコピーが作成され、両方の部分の結果のコンプライアンスをチェックするロジックが作成されました。 最初のコピーはVivado HLSのアルゴリズムのリファレンス実装であり、2番目はRTLコードへの変換用に最適化されました。 最適化には、動的配列の代わりに静的配列を使用する、HLSカーネルへの入力/出力に特別な関数を使用する、メモリを節約する方法、計算結果を再利用するなど、コードの書き換えが含まれます。 変更のたびに、関数の結果が参照実装の結果と比較されました。 別の最適化方法は、論理的な動作を変更しないが、RTLコードの最終的なパフォーマンスに影響を与える特別なVivado HLSディレクティブの使用です。 この段階では、回路パフォーマンスや使用リソースなど、CをRTLに変換する満足のいく予備的な結果が得られるまで滞在する必要があります。
次の段階は、メインプロジェクトのコンテキスト外で開発されたコンピューティングコアをVivadoシステムに実装することです。 ここでのタスクは、開発されたコンピューティングコア内で既に離婚したデザインの一時的なエラーをなくすことです。 この段階で一時的なエラーが発生した場合は、他の実装パラメーターを適用するか、前の段階に戻ってC ++コードを変更するか、他のディレクティブを使用します。
次の段階では、メインプロジェクトとその時間的および空間的制限とともに、コンピューティングコアを実装する必要があります。 この段階では、一時的なエラーがないようにすることも必要です。 それらが観察された場合、計算回路の周波数を変更したり、チップ上の回路の配置に他の空間的制限を課したり、再び取り上げたりすることができます。
C ++コードの変更および/または他のディレクティブの使用。
開発の最終段階は、ハードウェアで実際に実行し、CPUで参照モデルを使用して得られた結果のコンプライアンスのチェックです。 短時間で実行されますが、長時間実行すると(CPUとの比較ではすでに問題がある場合)、FPGAソリューションは正しい結果を提供すると考えられています。
Vivado HLSの環境で作業する
2つのVivado HLSコアが作業に使用されました(図3):微小管の分子動力学アルゴリズムを実装するメインコア(MTコア)、および擬似乱数を生成するためのコア(RANDコア)。 次の理由により、アルゴリズムを2つのコアに分割する必要がありました。 Virtex-7 2000T FPGAは、市場のVirtex-7ファミリで最大のFPGAチップです。 実際には、さまざまな化合物によって基板上に接続され、単一のチップ本体に結合された4つのシリコン結晶で構成されています。 ザイリンクスの用語では、このような水晶はそれぞれSLR(スーパーロジック領域)と呼ばれます。 このような大規模なFPGAを使用する場合、SLRの境界を越える回路には常に問題があります。 ザイリンクスでは、SLR境界の両側の回路にレジスタを挿入することをお勧めします。
MTコアとRANDコアの両方を含む完全なHLSコアは、1つのSLRで利用可能なものよりも多くのハードウェアリソースを必要としたため、独立したシリコンクリスタルの境界を越えるチェーンがありました。 C ++からRTLへの変換の段階では、Vivado HLSはどの回路がその後境界を越えるかについて何も知らないため、事前に追加の同期レジスタを挿入することはできません。 したがって、コアを2つに分割し、空間的に異なるSLRに制限し、RTLレベルでコア間のインターフェイス回路に同期レジスタを挿入することにしました。
MTコア
このアルゴリズムはFPGAでの実装に非常に適しているため、メモリからの比較的少量のデータ(2つの分子の座標)の場合、相互作用力の複雑な関数を計算する必要があり、長いコンピューティングパイプラインを構築することが可能です。
図 4. MTカーネルハードウェアコンピューティング手順のブロック図。 緑色は、分子の座標を保存するためのハードウェアメモリブロックを示します。 計算フォースコンベヤと座標更新、および計算の中間結果を保存するためのSave Regsブロックが指定されています。 擬似乱数は、別のHLSカーネルから座標更新パイプラインに到着します。
各分子、すなわち チューブリンモノマーは、隣接する4つのみと相互作用します(図2)。 時間内の各反復で、最初に相互作用力を計算し、次に分子の座標を更新する必要があります。 相互作用力を計算する関数には、多くの算術演算子、指数演算子、三角関数演算子が含まれます。 最初のタスクは、これらの機能のパイプラインを合成することでした。 作業データ型はfloat型でした。 Vivado HLSは、約130クロックサイクルのレイテンシで、200 MHzの周波数で動作するパイプラインの形式でこのような関数を合成しました。 同時に、コンベヤーはシングルサイクルでした(つまり、初期化間隔が1になっています)。つまり、入力の各ステップで新しい分子の座標を取得し、最初の遅延(レイテンシ)の後、サイクルごとに更新された力値を出力できます。 出力相互作用力を使用して座標を更新し、これもパイプライン化されました。 各分子の各座標を更新するには、別のHLSコアから取得した独立した擬似乱数正規分布数が必要でした。 3つの分子(「現在」、「左」、「上」)を取得すると、パイプラインを組み合わせて力を計算し、1つの分子のすべての計算を実行する1つのコンベヤーで座標を更新できます。 このようなコンベアのレイテンシは191クロックサイクルでした(図4)。
アルゴリズムは、サイクル内のすべての分子を実行します。 サイクルの各反復では、3つの分子の座標を持つ必要があります。1つの分子は「現在」と見なされ、「左」と「右」の分子もあります。 したがって、これら3つの分子間の相互作用の力が計算されます。 さらに、現在の分子の座標を更新するとき、相互作用力の左と上の成分は現在の反復での計算から取得され、下と右の成分は境界条件またはローカルレジスタファイルSave Regsからの以前の反復から取得されました(図4)。
システム内のN分子の数は少なかった(13プロトフィラメントx 12分子= 156分子)。 各分子には12バイトが必要です。 このスキームでは、それぞれm4とm2の合計2つの座標m1とm2の2つの配列を使用しました。このデータは、HLSカーネル内に実装された内部メモリFPGA(BRAM)に簡単に配置できました。 このスキームは、偶数回の反復で座標が配列m1から読み取られ(そしてm2に記録され)、奇数回の反復でその逆も行われるように配置されました。 アルゴリズムの観点からは、1つの座標配列で読み取りと書き込みを行うことはできましたが、Vivado HLSは、同じクロックサイクルで同じハードウェア配列を読み書きできる回路を作成できませんでした。これは、シングルサイクルパイプラインに必要です。 したがって、独立したメモリブロックの数を2倍にすることが決定されました。
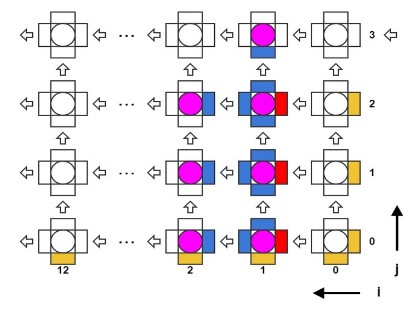
図 5.微小管内のチューブリンの相互作用のコンベヤー計算のスキーム。
サイクルごとに3つの分子の座標を更新できる3つの完全な平行コンベヤーを実現できることが判明しました(図5)。 次に、アイドルパイプラインを回避するために、ローカルメモリへのスループットを増やし、各サイクルで7つの分子の座標を読み取る必要がありました。 この問題は、ソースC ++コードを実質的に変更することなく簡単に解決されましたが、特別なディレクティブを使用するだけで、
元のデータ配列を4つの独立したハードウェアに物理的に分割する
メモリブロック。 なぜなら FPGAのBRAMメモリはデュアルポートであるため、4つのメモリブロックからサイクルごとに8つの値を読み取ることができます。 しかし、3つのコンベヤーはサイクルごとに7分子の座標を必要とするため(図5を参照)、これで問題は解決しました。
#pragma HLS DATA_PACK variable=m1, m2 #pragma HLS ARRAY_PARTITION variable=m1, m2 cyclic factor=4 dim=2
| 期間 | L | II | ブラム | DSP | Ff | ね | 廃棄 |
|---|---|---|---|---|---|---|---|
| 5 ns | 191ビート | 1拍 | 52 | 498 | 282550 | 331027 | 絶対 |
| 2% | 23% | 11% | 27% | 相対 |
タブ。 1:3つの完全なパイプラインを備えたHLSスキームのパフォーマンスと利用率
表の中。 図1は、HLS回路の使用率(つまり、消費するFPGAハードウェアリソースの量、Virtex-7 2000Tチップの絶対および相対単位)とそのパフォーマンスを示しています。 Lは、回路の遅延または遅延、つまり 最初の入力データをパイプラインに供給してから最初の出力を受け取るまでのクロックサイクル数.IIはパイプラインの初期化間隔(またはスループット)です。これは、後続のデータをパイプライン入力に供給することができるクロックサイクル数を意味します。
処理は、回路の実装のための絶対値(FFトリガーまたはLUTテーブルの数)と、クリスタル内のこのリソースの合計量の両方で行われます。 表からわかるように。 フルパイプラインの1レイテンシーLは191クロックサイクルに等しく、各パイプラインはすべての分子の3分の1を処理する必要があり、これはT(FPGA)=(L + N / 3)* 5ns = 1.2μsに等しい1反復の計算時間の理論的推定値を与えます
テーブルから。 図1は、クリスタル内に未使用のロジックがまだたくさんあることも示していますが、並列パイプラインの数をさらに増やすことは実用的ではありません。 第2項のみが減少し、初期遅延は操作中に依然として大きな貢献をします。 同時に、ロジックの量を増やすと、Vivadoでのプロジェクト開発の次の段階で回路の配置とトレースが複雑になります。
カーネルRAND
示されているように、アルゴリズムは分子のブラウン運動を考慮します。その計算方法の1つは、時間の各反復で座標の変化に通常のランダム加算を追加することです。 反復ごとに多くの正規分布乱数が必要です。各N 3個の数値は、420 10 ^ 6個の数値/秒のストリームを提供します 。 このようなストリームはホストからロードできないため、FPGA内でオンザフライで生成する必要があります。 これには、CPUの参照コードのように、Mersenne vortex generatorが選択されました。これにより、均一に分布した擬似乱数が得られます。 次に、Box-Muller変換がそれらに適用され、正規分布シーケンスが出力で取得されました。 Mersenne vortexの元のオープンソースコードは、1クロックサイクルの初期化間隔でハードウェアパイプラインを取得するように変更されました。 アルゴリズムにはサイクルごとに9個の通常の数値が必要です。したがって、RANDコアには10個の独立したメルセンヌ渦発生器が含まれていました。 Box-Muller変換では、2つの正規分布を得るために2つの均一に分布した数値が必要です。 表の中。 図2は、RANDカーネルの処理を示しています。
| ブラム | DSP | Ff | ね | 廃棄 |
|---|---|---|---|---|
| 30 | 41 | 48395 | 64880 | 絶対 |
| 1.2% | 9% | 0.1% | 5.3% | 相対 |
タブ。 2:RANDコアの廃棄
このようなコアには水晶のDSPリソースのかなりの部分が必要であり、このコアはMTコアを持つ1つのSLRに配置するのが難しいことがわかります。 少なくともDSPリソースに対する2つのコアの使用率は、1つのSLR(25%)が収容できる31%以上です。
疑似乱数ジェネレーターを選択してVivado HLSで合成する方法の詳細については、同僚の記事https://habrahabr.ru/post/266897/を参照してください。
ビットストリームの作成
コンピューティングコアをVivadoに統合した後、プロジェクトはIPブロックの配置に関して空間的な制限を受けました。 使用されているVirtex-7 2000T FPGAには、4つの独立したシリコンクリスタル(SLR0、SLR1、SLR2、SLR3)があります。 , MT SLR, (pBlock): pBloch_hls MT pBlock_base (. 3). pBlock_hls SLR0 SLR1, pBock_base – SLR2. , , ( SLR) .
, , .
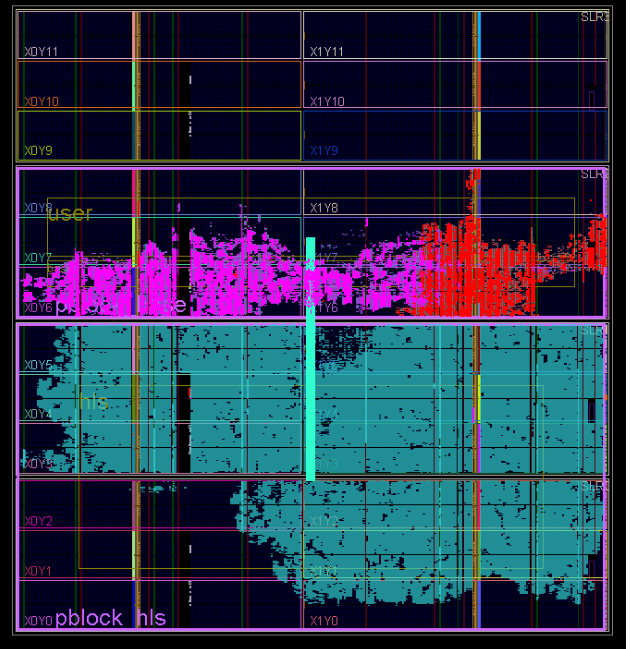
Board Support Package (PCIe core, DDR3 Interface, Internal AXI Bus), — MT HLS , — RAND.
結果
性能
(CPU, GPU FPGA) . 10^7 , . GPU FPGA - .
. , , CPU 1. . 3, , – .
| プラットフォーム | , | 性能 |
|---|---|---|
| CPU | 22 | 1 |
| GPU | 14 | 1.6 |
| FPGA | 1.3 | 17 |
タブ。 3:
, GPU CPU 1.6 , FPGA CPU 17 . , FPGA GPU 11 . FPGA 1.3 1.2 - PCI Express.
. CPU – Intel Power Gadget. GPU — Nvidia-smi. FPGA – - , RB-8V7. . 4.
| プラットフォーム | , | Ex | Ex_rel |
|---|---|---|---|
| CPU | 89.6 | 0.011 | 1 |
| GPU | 67 | 0.023 | 2 |
| FPGA | 9.6 | 1.77 | 160 |
タブ。 4:
, . ( ) , :
, :
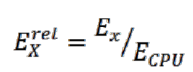
, x = {CPU, GPU, FPGA}.
, FPGA , FPGA . , FPGA .
議論
FPGA [12]–[17]. CAAD , ProcStar-III ( Gidel), FPGA Altera Stratix-III SE260. PCI Express -. , 26 CPU Apoal. [24] LAMMPS FPGA. . , . Maxwell, Intel Xeon FPGA Xilinx Virtex-4 [25]. , Maxwell. , 13 . - , CPU SDRAM, FPGA 96% . , , 8-9 .
FPGA . - , FPGA 17 CPU 11 GPU. . , .
FPGA . , .
FPGA . , [26] RTL . , Altera Xilinx (Altera SDK for OpenCL Xilinx Vivado HLS). C/C++ (Xilinx) OpenCL (Altera) . , FPGA [27]–[29]. , [28] Vivado HLS Xilinx Zynq-7000. CPU, 7 . , HLS RTL . Vivado HLS , FPGA. FPGA .
, ! pdf- ,