この記事で美しいグラフを作成するには、javascriptライブラリHighchartsおよびShinyのラッパーであるJoshua Kunsta highcharterパッケージを使用します 。
このライブラリのすべての製品は、非営利目的での使用は無料です。 商用プロジェクトやサイトの場合は、 これを活用してください 。
highcharterパッケージを使用すると、R内にHighchartsのようなチャートを作成できます。
パッケージには2つの主な機能があります。
-
highchart()
:htmlwidgetsを使用してHighchartチャートオブジェクトを作成します。 ウィジェットは、R Markdown、Shiny、またはその他のアプリケーションで作成されたHTMLページに表示できます。 -
hchart()
:highchart()
を使用して、Rのさまざまなクラスのオブジェクトに対して1つの簡単なコマンドでグラフを描画します。特に、データフレーム、数値、ヒストグラム、文字、密度、係数、ts、mts、xts、stl、ohlc、 acf、予測、予測、ets、igraph、dist、dendrogram、phylo、survfit。
グラフはggplot2の精神でレイヤーごとに構築されますが、+の代わりにコンベア演算子(%>%)を使用します。
パッケージの他の便利な機能:
- テーマ:Economist、Financial Times、Google、FiveThirtyEightなどの組み込みテーマを使用してグラフをカスタマイズできます。
- 拡張機能:モーション、ドラッグポイント、fontawesome、urlパターン、注釈。
このパッケージとHighchartsの機能全体を、いくつかの視覚化の例で説明します。
例1:米国で13日金曜日に生まれた
この視覚化は、FiveThirtyEightの記事に触発されました。 「一部は迷信的すぎて13日金曜日に出産できない」 FiveThirtyEightは、 GitHubのリポジトリにあるいくつかの記事で使用されているデータを親切に提供します 。 具体的には、これらはここからです 。
私たちの目標は、 この特定の視覚化を再現することです。 これを行うには、13日の出生数と各月の6日目と20日目の平均との差を計算し、これらの値を曜日ごとにグループ化する必要があります。 Dplyrとtidyrはこれでうまくいきます。
必要なパッケージをダウンロードします。
library(highcharter) library(dplyr) library(tidyr)
そしてデータ:
births <- read.csv("data/births.csv")
記事で説明されているように、出生数の差を計算し、結果を新しいデータフレーム
diff13
保存します。
diff13 <- births %>% filter(date_of_month %in% c(6, 13, 20)) %>% mutate(day = ifelse(date_of_month == 13, "thirteen", "not_thirteen")) %>% group_by(day_of_week, day) %>% summarise(mean_births = mean(births)) %>% arrange(day_of_week) %>% spread(day, mean_births) %>% mutate(diff_ppt = ((thirteen - not_thirteen) / not_thirteen) * 100)
これは次のようになります。
## Source: local data frame [7 x 4] ## Groups: day_of_week [7] ## ## day_of_week not_thirteen thirteen diff_ppt ## <int> <dbl> <dbl> <dbl> ## 1 1 11658.071 11431.429 -1.9440853 ## 2 2 12900.417 12629.972 -2.0964008 ## 3 3 12793.886 12424.886 -2.8841902 ## 4 4 12735.145 12310.132 -3.3373249 ## 5 5 12545.100 11744.400 -6.3825717 ## 6 6 8650.625 8592.583 -0.6709534 ## 7 7 7634.500 7557.676 -1.0062784
パーセンテージポイントで計算されたパーセンテージ差(
diff_ppt
)は、FiveThirtyEightの記事と一致しない場合があることに注意してください。 これには2つの理由があります。
- FiveThirtyEightでは休日は除外されますが、この分析では除外されません。
- FiveThirtyEightは、それぞれ1994-2003年と2000-2014年の2つのデータファイルを提供します。 これらのファイルの重複する年(2000〜2003年)の出生数はまったく一致しません。 このアプリケーションは、関連する年の社会保障局(SSA)からのデータを使用しますが、FiveThirtyEightが使用したデータは明確ではありません。
hchart()
関数を使用して、このデータの単純なハイチャートから始めましょう。
hchart(diff13, "scatter", x = day_of_week, y = diff_ppt)
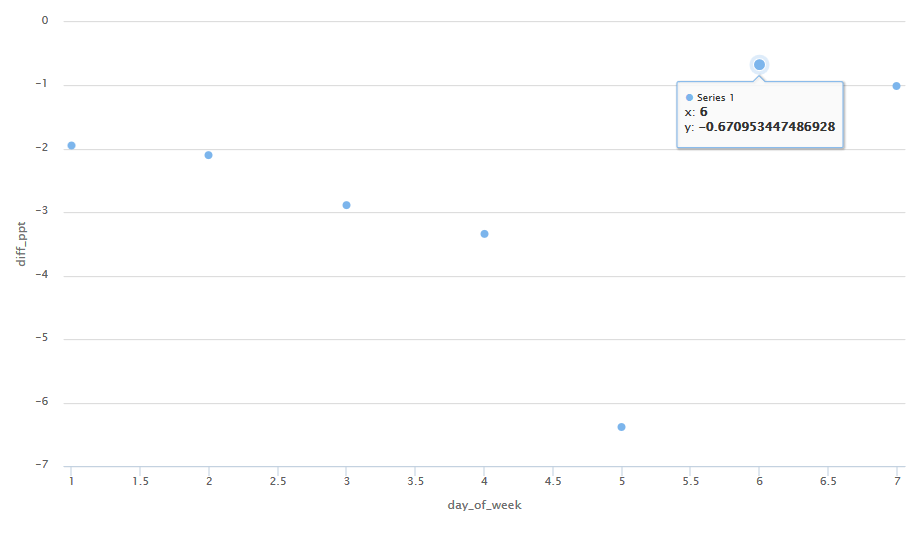
このグラフには多くの優れた機能があります。 たとえば、ポイントの上にマウスを移動すると、構築に使用される実際の値を確認できます。 ただし、グラフをFiveThirtyEightのように表示するには、特定の設定が必要です。 これは、
highchart()
関数などを使用して実現できます。 コンベアオペレーターでレイヤーを分離することに注意してください。
highchart() %>% hc_add_series(data = round(diff13$diff_ppt, 4), type = "column", name = "Difference, in ppt", color = "#F0A1EA", showInLegend = FALSE) %>% hc_yAxis(title = list(text = "Difference, in ppt"), allowDecimals = FALSE) %>% hc_xAxis(categories = c("Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"), tickmarkPlacement = "on", opposite = TRUE) %>% hc_title(text = "The Friday the 13th effect", style = list(fontWeight = "bold")) %>% hc_subtitle(text = "Difference in the share of US births on 13th of each month from the average of births on the 6th and the 20th, 1994 - 2004") %>% hc_tooltip(valueDecimals = 4, pointFormat = "Day: {point.x} <br> Diff: {point.y}") %>% hc_credits(enabled = TRUE, text = "Sources: CDC/NCHS, SOCIAL SECURITY ADMINISTRATION", style = list(fontSize = "10px")) %>% hc_add_theme(hc_theme_538())

タイトル:13日金曜日
小見出し:アメリカの各月の13日の出生数と1994年から2004年の6日と20日の平均出生数の差
0X軸に沿ったラベル:月曜日、火曜日、水曜日、木曜日、金曜日、土曜日、日曜日
0Y軸の署名:差、パーセンテージポイント
この視覚化の便利な機能はツールチップでもあります。 また、テーマを使用すると、グラフの外観を簡単に変更できます(この場合、
hc_theme_538()
テーマを使用すると、オリジナルにはるかに近づきます)。 また、ソースデータを変更せずに、ラベル(たとえば、曜日の名前)を簡単に変更できます。
例2:13日金曜日、米国で生まれた、双方向性
highcharterパッケージはhtmlwidlgetsを使用するため、Shinyとの互換性もあります。 Shinyアプリケーション内でハイチャートを作成するには、
renderHighchart()
関数を使用します。
以前に作成された視覚化を拡張し、チャート上のデータが取得される年の範囲、そのタイプおよびテーマをカスタマイズできるアプリケーションを作成しました。 スクリーンショットを以下に示します。アプリケーション自体とそのソースコードは、 こちらで表示できます 。

何を恐れる
ハイチャートの最も魅力的な機能は、組み込みのカスタマイズ可能なツールチップとスケーリングです。 しかし、これらの関数が役立つかどうかは、特定のケースごとに異なります。
たとえば、大量のデータに従ってグラフを作成する場合、ツールチップはあまり良くありません。 2013年10月にニューヨークのさまざまな空港で行われるこの着陸遅延とロサンゼルスへの出発のスケジュールをご覧ください。 グラフの左下部分にポイントが蓄積されると、ツールチップの利便性が低下します。
library(nycflights13) oct_lax_flights <- flights %>% filter(month == 10, dest == "LAX") hchart(oct_lax_flights, "scatter", x = dep_delay, y = arr_delay, group = origin)

ただし、ポイント数を減らすためにデータを少しグループ化すると、この機能が再び役立つ場合があります。 たとえば、次の例では、出発の遅延の15分間隔でフライトをグループ化し、これらの間隔の着陸の遅延の中央値を表示します。
oct_lax_flights_agg <- oct_lax_flights %>% mutate(dep_delay_cat = cut(dep_delay, breaks = seq(-15, 255, 15))) %>% group_by(origin, dep_delay_cat) %>% summarise(med_arr_delay = median(arr_delay, na.rm = TRUE)) hchart(oct_lax_flights_agg, "line", x = dep_delay_cat, y = med_arr_delay, group = origin)

おわりに
Highchartsはきめ細かい高品質のWebグラフィックを提供し、highcharterパッケージによりRユーザーはこれを最大限に活用できます。 パッケージで利用可能な機能に興味がある場合は、highcharterパッケージのページをご覧になることを強くお勧めします。コード例のあるHighcharts、 Highstock 、 Highmapsのチャートが多数あります。 また、いくつかの設定の構文を確認する必要がある場合、 Highchartsオプションページは非常に便利です。