この投稿の英語版はGitHubにあります 。
したがって、送信されたソリューションの9つは自己学習であることが判明しました。 自己学習の考え方は次のとおりです:すべての単語は最終的な辞書から選択され、非単語がランダムに生成されるため、テストされたプログラムに再び提示された行は、非単語よりも単語である可能性が高くなります。 十分に長いテストでは、辞書内のほとんどの単語は繰り返す時間がありますが、単語以外の場合、ランダムな繰り返しはあまり一般的ではありません。
自己学習ソリューションの動作を観察するために、 1,000,000ブロックでテストしました。 非常に多くのブロックを使用したすべてのソリューションのテストは非現実的ですが、これらの9つは非常に高速であることが判明しました。
以下のグラフは、処理されたブロック数に対する正解の割合を示しています。 水平スケールは対数であることに注意してください。
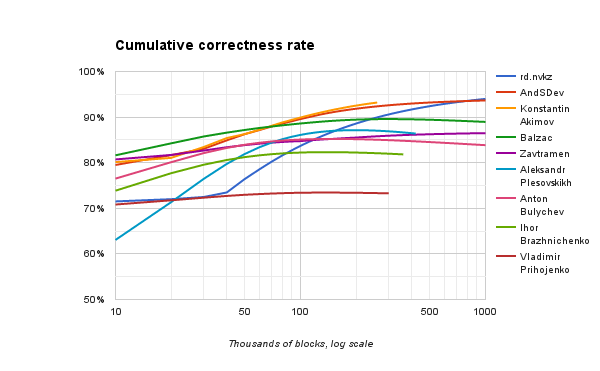
非常に多数のブロックでテストするときの一部のソリューションには十分なメモリがなかったため、100万ブロックのマークに達する前にそれらの行が中断されました。
次のグラフは、正解の累積割合(作業時間全体の平均)ではなく、各ポイントの最後の10,000ブロックのみを示しています。 ここでは、一定量のトレーニングの後、ソリューションがどのように動作するかをよく見ることができます。
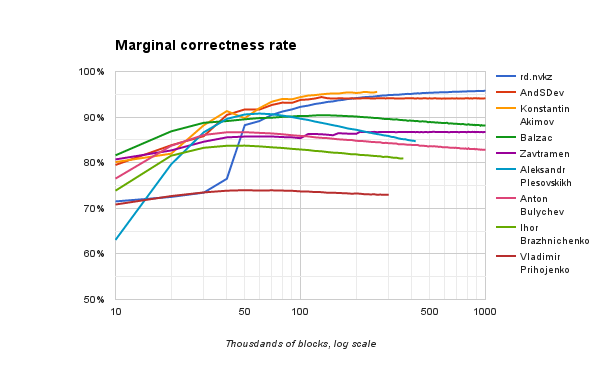
以下は、それぞれ偽陰性と偽陽性の結果の頻度グラフです。 また、作業開始からの累積ではなく、最後の10,000ブロックの動作を考慮します。

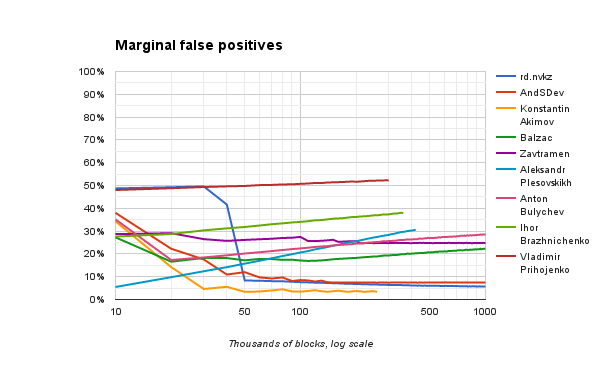
長期トレーニングでのいくつかの決定の結果は、いくらか悪化し始めることに注意してください。 明らかに、これはいくつかの非単語もランダムに繰り返されるという事実によるものであり、アルゴリズムは単語に対してそれらを使用します。 最後のグラフは、増加しているのは誤検知であることを示しています。
GitHubの特別ページでは、1,000,000ブロックの詳細な調査結果を見つけることができます。
調査に基づいて、仮名rd.nvkzおよびAndSDevの下で400 USDの特別賞を参加者に提供することにしました 。 彼らの決定は最高の率に達しました-それぞれ93.99%と93.65%。 さらに、彼らの行動は長期的なトレーニングで悪化することはなく、最初のものでは改善し続けます。 おめでとうございます!
Holaブログをフォローしてください! 新しいコンテストがあります。