幸いなことに、多くの機械学習タスクはかなり標準的であり、多くの分野で発生します。 たとえば、写真からの感情の認識。 感情認識の助けを借りて、多くの問題を解決できます:教室で眠っている、または気が散っている学生を追跡し、フォーカスグループの感情的な反応に基づいてコマーシャルをテストし、店内での疑わしい顧客行動を特定して盗難と戦い、クライアントまたは候補者との最適なコミュニケーション方法を決定します採用、アプリケーションの外観をパーソナライズ。 他の多くの人と同様に、感情を認識するタスクは、すでにかなり良いレベルで解決されています。 このタスクだけで 、 Emotient 、 Affectiva 、 EmoVu 、 Nviso 、 Kairos Emotion Analysis API 、 Microsoft Project Oxford 、 Noldus Face Reader API 、 Sightcorp FACE 、 SkyBiometry 、 Face ++など、20を超えるAPIサービスを利用できます。 機械学習APIとAIの総数は計算が難しく、雨の後はキノコのように見え、それらの多くは高い認識/予測品質を備えています。 そのため、標準の機械学習タスクでは、適切なAPIを簡単に見つけることができます。 毎回車輪を再発明する代わりに、必要なすべてのインフラストラクチャとともに、プロジェクトで既製のサービスを使用できます。

既存の機械学習および人工APIは、主要なグループに分類できます。 1つ目は、さまざまな問題を解決するためのAPIパッケージ全体を含む巨大なサービスです。 このようなサービスは、データを保存および前処理するためのインフラストラクチャ、着信データを処理し、オンライン応答を生成するための常時稼働サーバー、モデルの構築と品質の評価、データ、モデル構造、得られた結果の視覚化のための便利で直感的なインターフェースを備えています。 このグループには、 Amazon Machine Learning 、 Microsoft Azure Machine LearningおよびMicrosoft Cognitive Services 、 Google Cloud Prediction APIおよびGoogle Cloud Machine Learning 、 IBM Watson Cloud and AlchemyAPI 、 BigMLなどの大企業のソリューションが含まれます。 このようなサービスの疑いのない利点は、ビッグデータ、高品質のドキュメント、さまざまなプログラミング言語のAPIを操作するための既製のライブラリを操作するための高性能コンピューター、サーバー、インフラストラクチャへのアクセスです。
Amazon Machine Learning、Azure Machine Learning、BigMLなどのこれらのサービスの多くは、シンプルで直感的な使用に焦点を当てています。ユーザーは、機械学習アルゴリズムとデータ前処理の知識を必要とせず、必要なすべてのヒントと説明、視覚化、彼のためにやった。 さらに、これらのサービスは、バイナリおよびマルチクラスの分類と回帰にかなり単純なアルゴリズムを使用します。これは、PythonライブラリとRパッケージを使用して簡単に実装でき、大きな計算能力を必要としません。 適用されたアルゴリズムは、多くの場合十分な柔軟性がありませんが、Kaggleタスクに適用された場合など、依然として非常に良い結果が得られます。 モデルを構築する際、これらのサービスはアルゴリズムのすべての可能なバリエーションを整理しません。 たとえば、BigMLは決定木に焦点を当てていますが、Amazon Machine Learningは確率的勾配降下法に基づいた分類器のみを使用し、ランダムフォレストやその他のアルゴリズムを除外します。 このようなソリューションは、「ダミーの機械学習」に分類できます。ビッグデータを処理するための常時稼働するサービスとインフラストラクチャを必要とすると同時に、機械学習の分野で十分な知識がない開発者やアナリストに役立ちます。 このグループのサービスは独自のデータウェアハウスを提供します;データが大きすぎてロードできない場合は、必要な統計集計を自動的に構築します。 多くのサービスを使用すると、HadoopやSparkなどのサードパーティのサービスとデータソースを接続し、RとPython(Azure Machine Learningなど)でスクリプトを統合できるため、より柔軟になり、より幅広いタスクに使用できます。
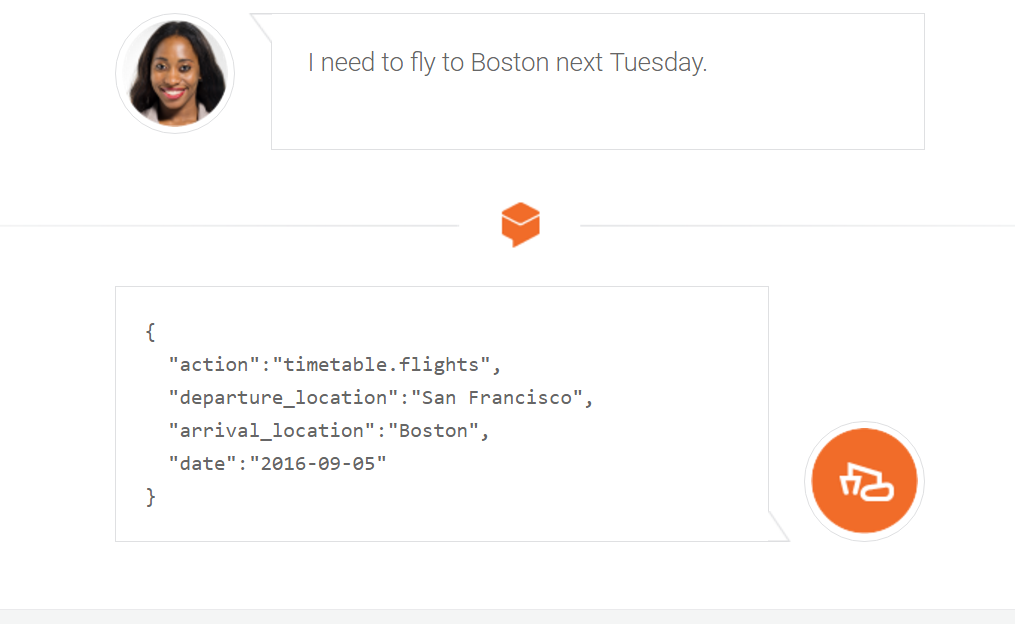
残りの最大の機械学習およびAI APIパッケージでは、主に画像処理と自然言語に関連するディープラーニングに基づいて、独立した実装に非常に複雑なモデルとアルゴリズムを使用できます。 ディープラーニングのタスクは非常に複雑であることが多く、高度な理論的知識と、トレーニングとモデルの使用のために大きな計算能力が必要です。 この場合、APIの使用は、機械学習に精通している人にとっても特に適切です。 このようなAPIサービスの機能の範囲は非常に広いです。 たとえば、ビデオおよび画像分析の分野でのMicrosoft Cognitive Servicesの機能には、画像の説明(画像の説明(画像に表示されている人またはもの、出来事))、分類、種類の決定(写真または画像)、アダルトコンテンツの識別、主要な色の決定、写真の検索が含まれますたとえば、有名人、ロゴ、オブジェクトなどの特定の人々は、ほぼリアルタイムでビデオで起こっていることを分析し、画像上のテキストを認識し、サムネイルを生成し、動きを検出して追跡します。 人の識別、性別、年齢、姿勢の決定、写真やビデオに写っている人々のメガネ、あごひげ、その他の顔の特徴、写真による検証(データベースの画像とカメラの画像の比較)、同じ人々の写真のグループ化、あいまいなビデオの安定化サムネイルフレームを作成します。 音声と自然言語分析の分野でのこのサービスの機能はこれまでのところ英語に限定されていますが、他の多くのサービスはロシア語をサポートしています。たとえば、Facebookが買収した完全無料のwit.aiとロシアの競合他社api.ai (自然言語、音声からテキストへの変換)、 IBM AlchemyAPI (テキスト調性分析、エンティティとキーワードの識別)、 Google Natural Language API (テキスト分類、リンクグラフ、テキストからの情報の抽出、調性分析、私たち 狂気、洞察抽出;機械翻訳技術Google翻訳を使用してロシア語をサポートし、ディープラーニングとword2vecを使用します。 利用可能なAPIのリストは絶えず更新され、一部のサービスは非常に興味深いものを提供し、他のパッケージツールには表示されません。 たとえば、IBM WatsonはPersonality Insightsツールを提供します。このツールを使用すると、Twitterの投稿、ソーシャルネットワーク、またはその他のテキストソースに基づいて、個人の性格特性、ニーズと価値、意図、およびその他の特性を判別できます。 残念ながら、ロシア語はまだサポートされていません。
上記の最大のパッケージAPIサービスに加えて、個々の問題を解決することを目的とした多くの機械学習および人工知能APIがあります。 たとえば、 Diffbotを使用すると、サイトのページを自動的にスキャンし、 そこから必要な情報(テキスト、画像、ビデオ、製品情報、コメントなど)をきれいに構造化された方法で抽出し、ページを分類することもできます。 ページ構造の分析、機械学習、人工知能、自然言語処理、マシンビジョンなどの幅広い技術を使用しています。 サービスのウェブサイトには、さまざまなプログラミング言語からのAPIを操作するために利用できる35以上のライブラリがあります。 Restbは、疾患診断、コンテンツフィルタリング、生物学的研究、ブランドの決定、製造年、車の内装の種類など、幅広いクラスのコンピュータービジョンの問題を解決するためのAPIを提供します。 clarifaiサービスを使用すると、画像と動画のタグのセットを作成できます 。 Deepomaticは画像を分類することができ、画像認識と視覚的な検索機能を備えたチャットボットを作成することもできます。 たとえば、そこで選択した衣料品店の楽屋で写真を撮ると、チャットボットは、これらの服とうまく組み合わせることができる品揃えから他のモデルを自動的に選択します。 Deepomaticに基づいた決定により、ポスターに関する映画の情報、携帯電話のカメラで撮影した写真による展覧会の絵画や彫刻に関する情報の検索、ディスクのアルバムカバーの撮影による音楽のダウンロードなどが可能になります。

機械学習と人工知能APIに基づいて、多くの商業的に成功した製品が作成されました。 たとえば、 フォードはGoogle Prediction APIを使用して、時間、速度、旅行スケジュール、およびそのドライバーに典型的なルートの履歴に基づいてドライバーが選択するルートを予測し、燃費を最適化します。 LifeLearn SofieアプリケーションはIBM Watsonサービスを使用し、検査の結果に基づいて医学文献のコレクションをスキャンすることにより、獣医が疾患と治療計画を識別するのを支援します。 情報は、音声認識を通じて自然言語アプリケーションに送信されます。 獣医学では、患者が症状を表現できないため、そのようなアプリケーションの使用が特に重要です。獣医師は医学の本や雑誌を勉強する時間がないことが多く、時には獣医師がこれまで出会ったことのない品種や動物種を扱う必要があります。 VRadは、現在Salesforce Salesforce Einstein CRMモジュールの一部であるMetaMindサービスAPIを通じて詳細なトレーニングを正常に適用して、生命を脅かす異常、特に脳出血を特定する速度と精度を向上させています。
もちろん、ビジネス、アプリケーション開発、スタートアップの作成において、機械学習APIとAIの成功したアプリケーションの例ははるかに多くあります。そのため、まだ必要なすべてのテクノロジーを所有しておらず、実装でお金を稼いでいない場合でも、ビジネスのアイデアを実現することを妨げるものは何もありません。 毎月の数が少ないリクエスト(数千)で、考慮されるサービスのほとんどは無料で使用できるため、実際にすべてを試して、開発中にテストする機会があります。 さらに、支払いは実際に使用された容量のみに依存します(使用した分だけ支払います)。特に、アプリケーションにユーザーがさらに少ない初期段階では、サービスを使用するための料金はゼロまたは非常に小さくなります。 大きな初期投資は必要ないため、コストはすぐに回収できます。 したがって、機械学習と人工知能の使用を含むビジネスアイデアがある場合、APIを使用することはそれを実装する絶好の機会です!