 初期化されたC / C ++ローカル変数のこれら2つの定義の違いは何ですか?
初期化されたC / C ++ローカル変数のこれら2つの定義の違いは何ですか?
char buffer[32] = { 0 }; char buffer[32] = {};
1つの違いは、1つ目はCおよびC ++で有効であり、2つ目はC ++でのみ有効であることです。
それでは、C ++に注目しましょう。 これら2つの定義は何を意味しますか?
1つ目は、コンパイラーが配列の最初の要素の値をゼロに設定し、(大まかに言って)配列の残りの要素をゼロで初期化する必要があるということです。 2番目は、コンパイラーが配列全体をゼロで初期化する必要があることを意味します。
これらの定義はわずかに異なりますが、実際には1つの結果しかありません。配列全体をゼロで初期化する必要があります。 したがって、C ++の「as-if」ルールに従って、それらは同じです。 つまり、十分に最新のオプティマイザは、これらの各フラグメントに対して同一のコードを生成する必要があります。 そう?
しかし、これらの定義の違いが重要な場合もあります。 (仮に)コンパイラーがこれらの定義を非常に文字通りに取る場合、最初のケースでは次のコードが生成されます:
1: buffer[0] = 0; memset(buffer + 1, 0, 31);
一方、2番目の場合、コードは次のようになります。
2: memset(buffer, 0, 32);
また、オプティマイザーがこれら2つのステートメントを結合できることに気付かない場合、コンパイラーは、2番目の定義よりも最初の定義に対して効率の低いコードを生成できます。
コンパイラーが文字通りアルゴリズム1を実装した場合、データの最初のバイトにゼロ値が割り当てられ、(プロセッサーが64ビットの場合)8バイトの3つの書き込み操作が実行されます。 残りの7バイトを埋めるには、さらに3回の書き込み操作が必要になる場合があります。最初に4バイトを書き込み、次に2バイト、さらに1バイトを書き込みます。
まあ、これは仮説です。 これはまさに、VC ++の仕組みです。 64ビットアセンブリの場合、「= {0}」に対して生成される一般的なコードは次のようになります。
xor eax, eax mov BYTE PTR buffer$[rsp+0], 0 mov QWORD PTR buffer$[rsp+1], rax mov QWORD PTR buffer$[rsp+9], rax mov QWORD PTR buffer$[rsp+17], rax mov DWORD PTR buffer$[rsp+25], eax mov WORD PTR buffer$[rsp+29], ax mov BYTE PTR buffer$[rsp+31], al
グラフィカルに、これは次のようになります(ほとんどすべての書き込み操作は調整されていません)。

ただし、ゼロを省略すると、VC ++は次のコードを生成します。
xor eax, eax mov QWORD PTR buffer$[rsp], rax mov QWORD PTR buffer$[rsp+8], rax mov QWORD PTR buffer$[rsp+16], rax mov QWORD PTR buffer$[rsp+24], rax
これは次のようになります。

コマンドの2番目のシーケンスはより短く、より高速です。 通常、速度の違いを測定することは困難ですが、いずれにしても、よりコンパクトで高速なコードを優先する必要があります。 コードのサイズは、すべてのレベル(ネットワーク、ディスク、キャッシュ)のパフォーマンスに影響するため、余分なコードバイトは望ましくありません。
通常、これは重要ではありません。おそらく、実際のプログラムのサイズに目立った影響はありません。 しかし、個人的には、「= {0};」に対して生成されたコードは非常に面白いと思います。 人前で話すときの「eee」の絶え間ない使用に相当します。
私はこの動作に最初に気づき、6年前に報告しましたが、最近この問題がVC ++ 2015 Update 3にまだ存在することを発見しました。私は興味があり、さまざまなx86およびx64プラットフォームの配列サイズとさまざまな最適化オプション:
void ZeroArray1() { char buffer[BUF_SIZE] = { 0 }; printf(“ .%s\n”, buffer); } void ZeroArray2() { char buffer[BUF_SIZE] = {}; printf(“ .%s\n”, buffer); }
以下のグラフは、1つの特定のプラットフォーム構成でのこれら2つの関数のサイズを示しています-64ビットビルドのサイズ最適化-1〜32の範囲のBUF_SIZE値と比較して(BUF_SIZE値が32を超える場合、コードバリアントのサイズは同じです):

BUF_SIZEの値が4、8、および32の場合、メモリの節約は見事です。コードサイズはそれぞれ23.8%、17.6%、20.5%削減されます。 節約されるメモリの平均量は5.4%であり、これらの関数にはすべて共通のエピローグ、プロローグ、およびprintfコードがあるため、これは非常に重要です。
ここでは、構造と配列を初期化するときに、すべてのC ++プログラマーに、=“ = {0};”ではなく“ = {};”を優先させることをお勧めします。 私の意見では、それは審美的な観点からはより良く、ほとんど常に短いコードを生成するようです。
しかし、ほとんどです。 上記の結果は、「= {0};」がより最適なコードを生成するいくつかのケースがあることを示しています。 シングルおよびダブルバイトフォーマットの場合、「= {0};」は直ちに(コマンドに従って)配列にゼロを書き込みますが、「= {};」はレジスタをゼロにしてから、そのようなレコードを作成します。 16バイト形式の場合、「= {0};」はSSEレジスタを使用してすべてのバイトを一度にリセットします。この方法がコンパイラで頻繁に使用されない理由はわかりません。
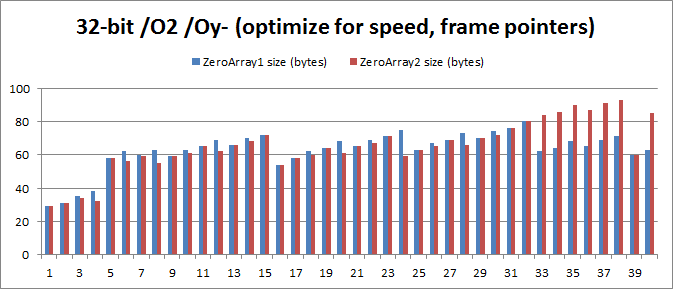
そのため、何かを推奨する前に、32ビットシステムと64ビットシステムのさまざまな最適化設定をテストすることが私の義務であると考えました。 主な結果:
/ O1 / Oy-付きの32ビット:1から32までの平均メモリ節約量は3.125バイト、5.42%です。
32ビットs / O2 / Ou:1〜40の平均メモリ節約量は2.075バイト、3.29%です。
32ビットs / O2:1〜40の平均メモリ節約量は1,150バイト、1.79%です。
64ビットs / O1:1〜32の平均メモリ節約量は3.844バイト、5.45%
64ビットs / O2:1〜32の平均メモリ節約量は3.688バイト、5.21%です。
問題は、32ビット/ O2 / Ouの結果で、「= {};」は「= {0};」よりも平均で2.075バイト多いことです。 これは、コード「= {};」が通常22バイト大きい32〜40の値に当てはまります。 その理由は、コード「= {};」が「movups」ではなく「movaps」コマンドを使用して配列を無効にするためです。 これは、スタックが16バイトに揃えられるようにするためだけに、多くのコマンドを使用する必要があることを意味します。 これは不運です。
結論
それでも、C ++プログラマは「= {};」を優先することをお勧めしますが、多少矛盾する結果は、このオプションが提供する利点が無視できることを示しています。
VC ++オプティマイザーがこれらの2つのコンポーネントに対して同一のコードを生成した場合は素晴らしいことであり 、このコードが常に完璧であれば素晴らしいことです。 いつかそうなるでしょうか?
VC ++オプティマイザーがメモリのゼロ化に16バイトSSEレジスタを使用するタイミングを決定する際に一貫性がない理由を知りたいと思います。 64ビットシステムでは、このレジスタは「= {0};」で初期化された16バイトバッファにのみ使用されますが、通常、よりコンパクトなコードがSSEで生成されます。
これらのコード生成の難しさは、隣接する集約イニシャライザが結合されていないという事実に関連するより深刻な問題の特徴でもあると思います。 しかし、私はすでにこの問題にかなりの時間を割いてきましたので、理論的なレベルのままにします。
ここで私はこのバグを報告しました。Pythonスクリプトはこちらにあります 。
以下のコードも同等である必要がありますが、いずれの場合もZeroArray1およびZeroArray2よりもさらに悪いコードを生成することに注意してください。
char buffer[32] = “”;
私は自分自身をテストしませんでしたが、gccおよびclangコンパイラーは 「= {0};」のintoには入らないと聞きました 。
VC ++ 2010の以前のバージョンでは、問題はより深刻でした。 場合によっては、memset呼び出しが使用され、どのような状況でも「= {0};」が間違ったアドレスアライメントを保証しました。 VC ++ 2010 CRTの以前のバージョンでは、不整列により、最後の128バイトのデータが4倍遅く書き込まれました(stosdではなくstosbコマンド)。 これはすぐに修正されました。
ABBYY LSによる翻訳